Why Search Robots and Netpeak Spider Don’t Crawl Your Website
Use Cases

Lots of bots scurry around the web and you can let them in or keep away from your website. For instance, Google has a lot of crawlers to discover and scan websites. Also, there are such famous web crawlers as Bingbot, Slurp Bot, DuckDuckBot, Baiduspider, Sogou Spider, Exabot and much more. To make it completely clear, according to Google:
These robots directly determine if your website will be indexed, because they include websites to search engine’s database. And sometimes website’s owner or developer can keep website from crawling, deliberately or not. When you run Netpeak Spider, the same problems can occur because it’s also a crawler ;) The first thing that comes to mind is that there is something wrong with the program. That’s why this question is among the most frequent to our customer care specialists. And we would like to explain why this ocсassion can happen both with search engines bots and Netpeak Spider.
Let’s dig further!
Read more → How to fix orphan pages
1. Indexation Instructions
In most cases crawlers check and follow instructions in robots.txt, HTTP headers and meta tags. Let’s take a glance at each case in turn.
Robots.txt and Sitemap.xml
Robots.txt is a text file placed in the website root directory. This file shows which search robots can crawl website and which parts of it can be crawled and indexed. These instructions are specified by ‘disallow’ or ‘allow’ and determine the behavior of certain (or all) user agents.
Also, your robots.txt file should include XML Sitemap associated with this website. It will help bots crawl all necessary URLs of your website.
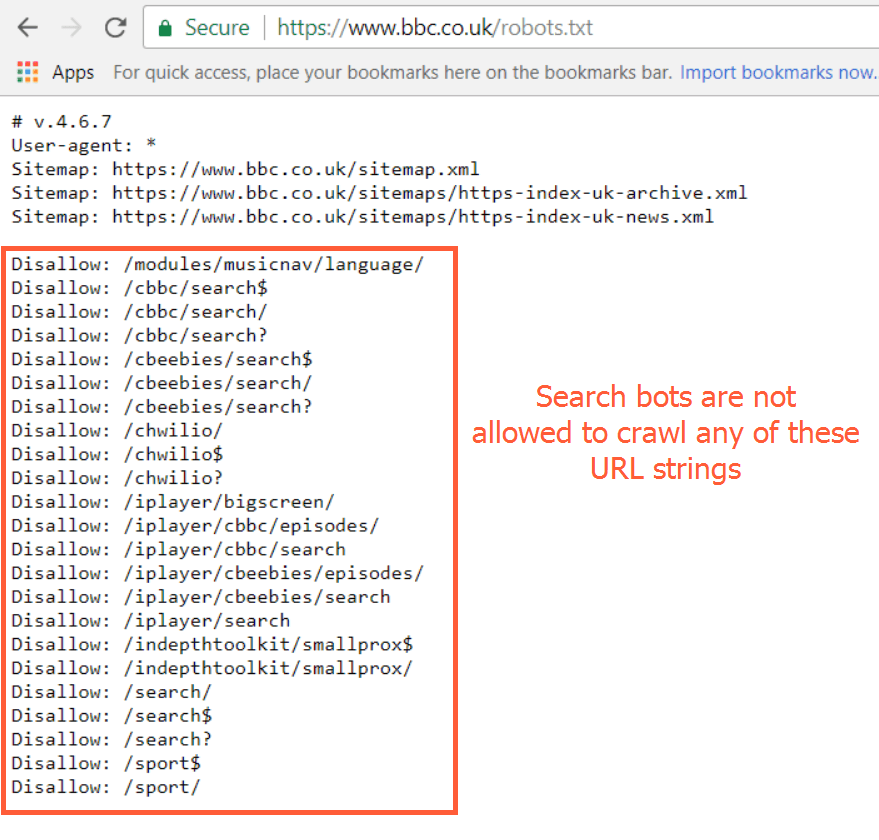
You can find out a detailed guide on how to create robots.txt file and even test it before implementing on your website using ‘Virtual robots.txt’ feature in Netpeak Spider.
Set up various configurations of robots.txt in the free version of Netpeak Spider crawler that is not limited by the term of use and the number of analyzed URLs. Other basic features are also available in the Freemium version of the program.
To get access to free Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
Robots Meta Directives
Here we are talking about the Robots meta tag and X-Robots-Tag. These instructions can easily prevent your website from being spotted by search robots.
Robots meta tag. If you have noindex meta tags on the page, search robots are unlikely to visit and crawl your website. This tag is placed in the <head> section of a given page and can forbid indexation for selected crawlers or for all of them.
Here is an example of how this tag should be written for all robots:
Here is an example just for ‘googlebot’ user agent:
X-Robots-Tag. The X-Robots-Tag can be used as an element of the HTTP header response for a given URL. To use the X-Robots-Tag, you’ll need to have access to your website’s header .php, .htaccess, or server access file.
Here is an example of an HTTP response with an X-Robots-Tag instructing crawlers not to index a page:
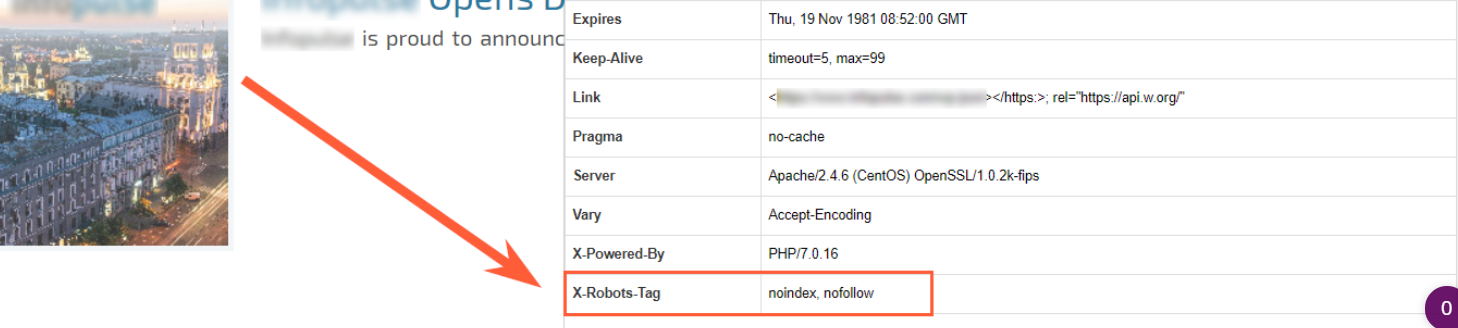
If your website or its parts are closed via some of the ways mentioned above and Netpeak Spider doesn’t crawl your website (but you want it to), you can easily change some settings and enjoy the crawling ;)
To do that, just go to the ‘Advanced’ tab in ‘Settings’ and untick everything below ‘Consider indexation instructions’.
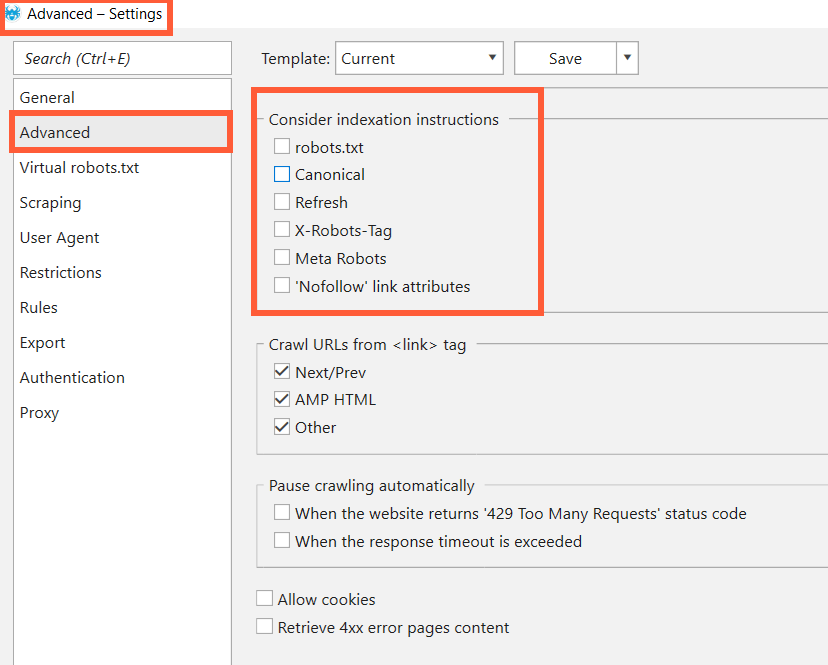
Learn more about instructions:
1. In robots.txt: 'What Is Robots.txt, and How to Create It'.
2. In X-Robots-Tag: 'X-Robots-Tag in SEO Optimization'.
2. Canonical
Website owners can undeliberately set up rel=canonical on the website and it leads to the web page with redirect to the page with canonical. It reminds redirect loops, doesn’t it?
Here is the most frequent example of this issue. Website meow.com has moved from HTTP protocol to HTTPS. Of course, all pages with HTTP were redirected to the relevant ones with HTTPS, but the website with HTTPS has rel=canonical to the HTTP version.

This is a serious issue because you don’t give crawler a chance to reach your website! To solve this problem for search bots, set up rel=canonical to the website itself. To permit Netpeak Spider crawl despite this disaster, untick ‘Canonical’ under ‘Consider indexation instructions’ in ‘Advanced’ tab in settings (as shown on the screenshot above).
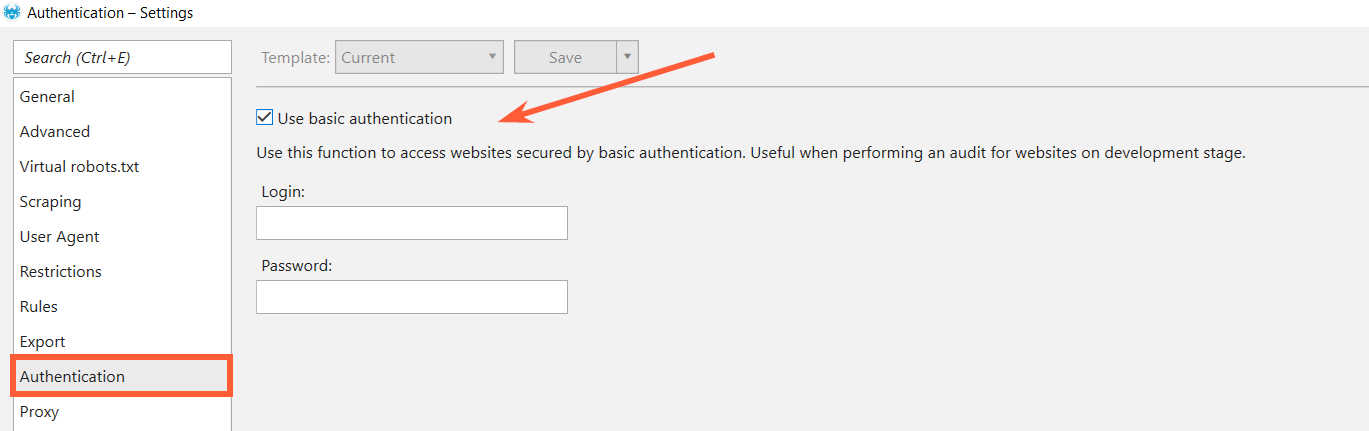
3. Authorization

If privacy settings are enabled on your website, crawlers can’t reach and index it. Maybe it’s your website’s test version and you don’t want to see it in SERP, but want to check it before release, for instance. It’s no problem for Netpeak Spider. Choose ‘Authentication’ tab in crawling settings, tick ‘Use basic authentication’, enter your login and password, and crawl your website :)
4. Blocked by .htaccess
Accidentally or not, you could block crawlers in your .htaccess file. This file is located in the website root directory (your public_html directory). You can open it using File Manager in your cPanel or using FTP Client (FileZilla, for example). Here is an example of blocking some search engine bots in your .htaccess file with RewriteEngine function by User Agent string:
So you can save the .htaccess file and upload it to your server, overwriting the original one. If you want to change rules, you can revert it by using the original .htaccess file or just deleting the rules.
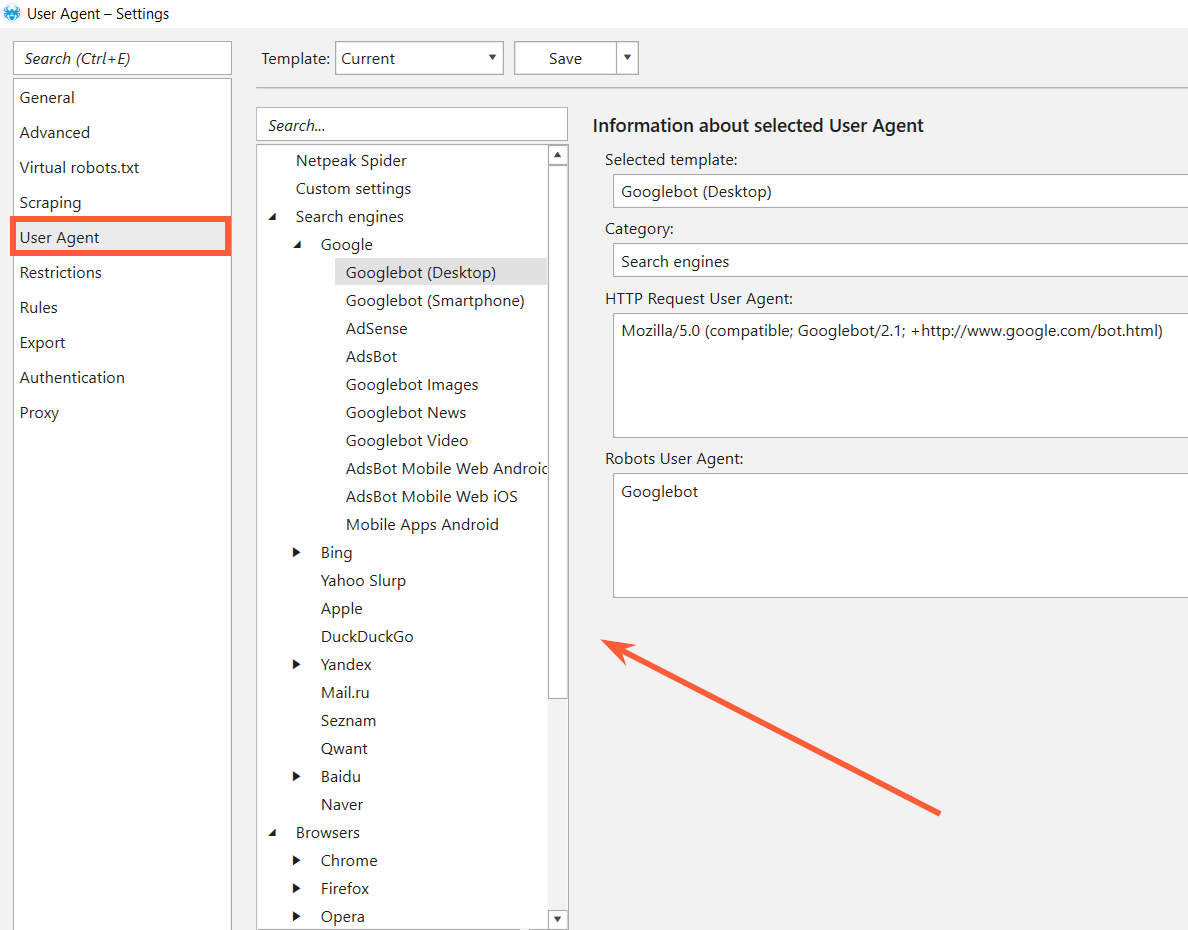
If you don’t want to change rules in your .htaccess file but want to crawl your website with Netpeak Spider, choose the User Agent which is not blocked in your .htaccess file in the ‘Settings’ of our crawler.
5. Loading Time
According to Google, your server response time should be under 200ms. If your website is loading for ages, crawlers will not wait for it. As for Netpeak Spider, you can get Timeout error in the ‘Status Code’ column. FYI, the maximum response timeout in Netpeak Spider is 90,000 ms and you can adjust it in General settings.
6. Blocked Because of Too Many Requests
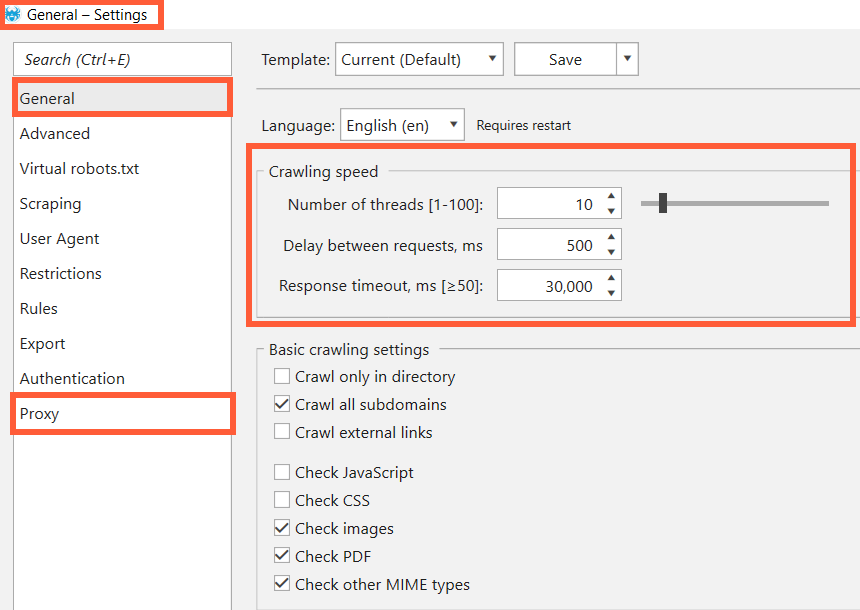
This reason, to a large extent, relates to Netpeak Spider. Some websites have ‘protection’ – the HTTP 429 response status code. It appears when the user has sent too many requests in a given amount of time (‘rate limiting’). Also, some websites have a very poor architecture and can crash even when there are just a few visitors on them. You can determine the crawling speed in Netpeak Spider. Just go to ‘Settings’, choose ‘General’ tab and set the minimum number of threads or even delay between requests or you can use list of proxy ↓
In a Nutshell
Before occupying SERP’s top, your website must be crawled and indexed by search robots. And sometimes it’s impossible because of such reasons as:
- indexation instructions (robots.txt, robots meta directives)
- canonical loop
- authorization settings
- blocking by .htaccess file
- excessive loading time
- blocking because of too many requests
Netpeak Spider as a crawler can face the same problems during the scanning of your website. Fortunately, they are very easy to solve → a few ticks in the ’Settings’ and you can see your website as search engine bots before opening it to the real ones.
Do you know more reasons why websites cannot be crawled by crawlers? Share your experience in the comments below :)
Digging This Use Case? Let's Discuss Netpeak Spider Perks in Person



