What Is Robots.txt, and How to Create It
How to

Every search engine has a bunch of bots for indexing sites. Their main job is to crawl the web and index content to further serve it up to the users. As a rule, they start crawling from the robots.txt file, which is an important tidbit of the website. In this blog post, you’ll find out what robots.txt file is, how to create it, and get some tips on how to check this file for possible issues.
- 1. What Is Robots.txt
- 2. Why Do You Need Robots.txt?
- 3. Syntax in Robots.txt
- 4. How to Create Robots.txt
- 5. How to Check Robots.txt
- Key Takeaways
1. What Is Robots.txt
The robots.txt file is a text file in the root directory of the website that contains a set of directives that manage search robots access to the content on the website. The text comprises at least of two lines (it can have several groups) – their number solely depends on the need to allow or disallow the indexing of pages. One line includes one directive. It usually describes a certain directory, subdirectory, or page.
Robots.txt is part of Robots Exclusion Protocol. The REP also includes directives in meta robots and X-Robots-Tag.
But don’t be too ditzy with robots.txt file and don’t pin all your hopes on it. It’s not a magic wand that wards off all nasties. In July 2019, Google officially announced that directives in robots.txt are approached as slight ‘hints’ for indexing, not as strict rules, which means that even disallows in robots.txt won’t refrain search robots from indexing pages if they are determined to do so.
2. Why Do You Need Robots.txt?
Having roots.txt is not a must. Either way, search robots will find and index primary pages. There are many traces on the web (in the form of links or mentions) that can be tracked by search robots and labeled as indexing-worthy. However, it’s better to have roots.txt file than not. Let me elaborate on the reasons:
- If there’s no robots.txt file, all pages will be randomly indexed, which is not the best thing you can do for website optimization. As a webmaster, you know which pages of your website are desired to get indexed, which are supposed to private, and which come through their staging period. You also may choose to hide such pages as login or checkout, which deserve to exist, but not for arbitrary visitors.
- You can manage the crawl budget search engines pay to your website, thus maximizing it for the pages that need to be indexed.
- You can use robots.txt file as an additional opportunity to point out the main mirror of the site (your website replica) and show the path to the sitemap that applies to your domain.
If robots.txt is such a boon, do all sites need a robots.txt file? Yes and no. If the use of robots.txt implies the exclusion of pages from the search, then for small sites with a simple structure and static pages, such blocks may be too much.
3. Syntax in Robots.txt
As I already mentioned, robots.txt file dwells in the root of the domain. Let’s imagine I have a site www.saymeow.com, so my robots.txt lives after the slash www.saymeow.com/robots.txt., and it can be seen publicly via these address. To avoid common syntax mistakes, bear in mind these clear rules:
- the robots.txt file is case sensitive
- one line – one directive
- no spaces in between the lines or at the beginning of the lines
- the ‘/’ is used before each directory. Example: /category
- one parameter per directive: Allow or Disallow
- Allow without description means the same as Disallow: / – it blocks indexing of all pages
A correctly composed file will help limit access to particular pages of the site or set priority for bots. Any mistake can shatter the stability of your website and lead to gross indexing issues. The most common mistakes are:
- the file size exceeds 35 KB
- typos in the directives or links
- non-TXT format or unacceptable symbols
- the file is inaccessible in the HTTP request header
3.1. User-Agent
User-agent is a key directive which stands for the name of the search robot for which the file was created. To address a specific robot, mention his name in the User-agent line. To open access to all possible search robots that get to the site leave the * mark. Here how it looks in action:
3.2. Disallow
The robots.txt disallow directive blocks indexing of the site pages. For the entire site to be blocked for indexing, add a ‘/’ mark in the end. And to block a separate page or folder, you need to mention the path of this directory after the slash.
3.3. Allow
This directive prescribes pages and files for first-hand crawling. But if you use a ‘slash’ sign (/), it means that you allow indexing of the whole website. An example:
It is also important to specify each path to each folder / subfolder separately in the order the robot passes through the site directories.
3.4. Noindex
Apart from robots.txt file, there are multiple ways to manage page indexing (remember REP?). Such directives as noindex are set at the code level and are called meta robots tag:
3.5. Crawl-Delay
This directive defines the minimum period between crawls. For instance:
3.6. Host
Host points to the main mirror of the site (replica site).
3.7. Sitemap
You can leave the links to sitemaps to ease the robot’s navigation across your website, immediately pointing out the essential parts.
4. How to Create Robots.txt
It’s a text file. You can create it in the Windows Notepad or automatically generate it in online services (such as Robots Text Generator Tool). As soon as you open a notepad, you have already started creating robots.txt. It remains only to compile its contents, depending on your requirements, and save it as a .txt file. Everything is simple, and creating a robots.txt file should not cause problems even for beginners. Here’s the robots.txt example:
In directives, you may also leave comments for webmasters, which are put after the # sign, each from a new line. They won’t make sense for robots, only for humans. Here’s the example of how we leave perks in Netpeak Software:
5. How to Check Robots.txt
To check the validity of robots.txt, use the Google Search Console robots testing tool. To do this, just enter the contents of the text file, specify the site, and you will see a report on the accuracy of the file. The check is only possible when the final version was submitted into the top-level directory. If it’s not, the service will display an error and the reason for it with detailed instructions.
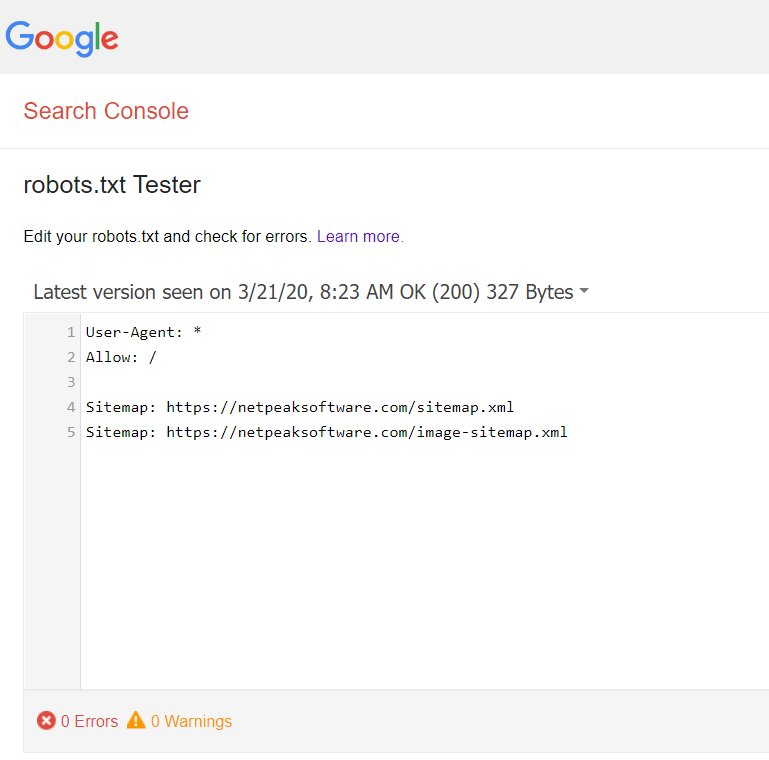
Besides, you can test robots.txt file for possible issues in Netpeak Spider even before placing it on your website. Spider bot will crawl your website following these instructions.
To get access to Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
To do so:
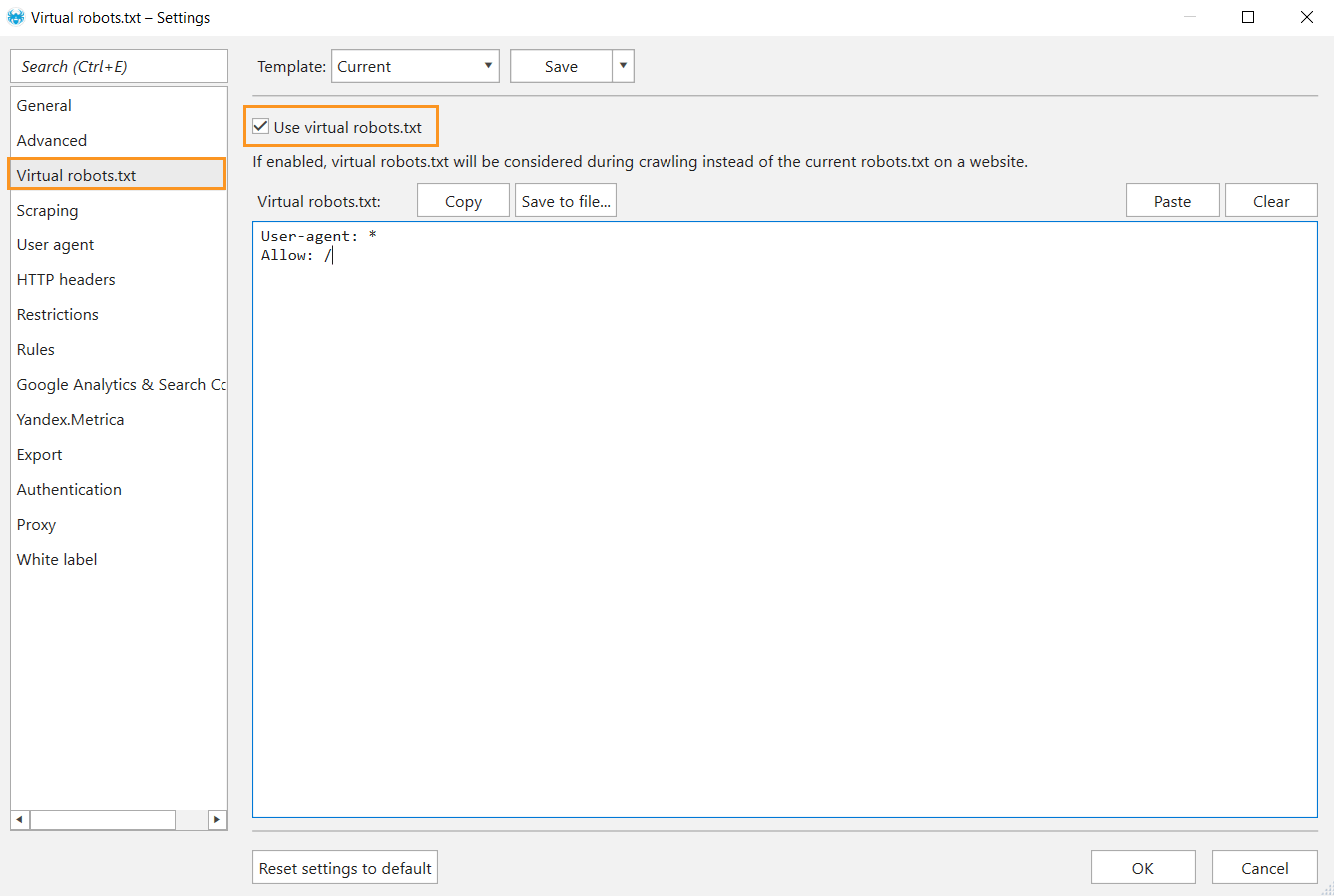
- Open ‘Settings’ → ‘Virtual robots.txt’, tick the checkbox ‘Use virtual robots.txt.’
- Type directions into the open window and save changes.
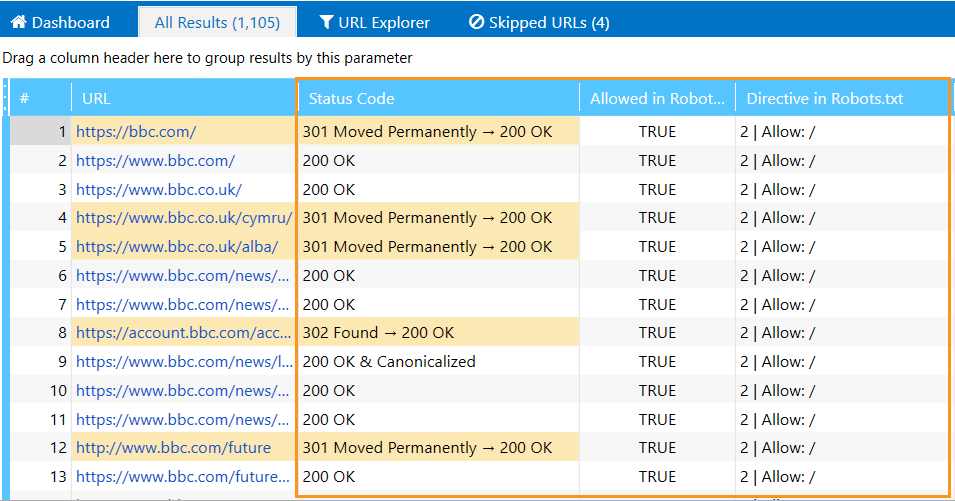
- In the ‘Initial URL’ field, enter the domain address, tick the ‘Allowed in Robots.txt’ and ‘Directive in Robots.txt’ parameters in a sidebar, and start crawling.
- You’ll see the data related to the given instructions in the main table.
Key Takeaways
The robots.txt file is a text file that lives in the root directory of the domain. It is used to manage the indexing of pages, directories, subdirectories, etc. Additionally, you can add the mirror site and the link to the sitemap associated with the domain. Indexing instructions may relate to all robots or particular ones, like Googlebot or Bingbot. Unique directions can be set for any search robot, each from a new line.
You have to follow a standard set of syntax rules to create a file, and check it in Google webmaster tool or desktop crawler, like Netpeak Spider. Eventually, when no errors are detected, you can submit the robots.txt file to your website.
It is important to remember that the robots.txt file is only a recommendation for a search robot, not a remedy to all. As practice shows, search engines can index hidden pages, as well as various files, and code that relates to the front-end part of the site.


