X-Robots-Tag in SEO Optimization
How to

Occasionally, you need some parts of your website to be seen neither by search robots nor by visitors. The reasons are various, so are the ways of implementation. You’re free to choose the tools that can help you manage the indexing process: meta robots tag, X-Robots-Tag, robots.txt file, sitemap. In this blog post, I’m going to approach the peculiarities of X-Robots-Tag use, its main hazards, and benefits.
- 1. X-Robots-Tag and Its Fellows
- 2. When to Use X-Robots-Tag?
- 3. How to Implement X-Robots-Tag on Website
- 4. How to Check X-Robots-Tag for Possible Issues
- Let’s Recap
1. X-Robots-Tag and Its Fellows
X-Robots-Tag is considered to be an integral part of REP – Robots Exclusion Protocol. The REP (or robots exclusion standard) is a sort of merge of different criteria that determines the way search robots behave on your website, what data they crawl and index. The so-called ‘directives’ come into play while regulating the way of displaying the content on your web page. In fact, there are several directives that all together tell search engine robots what specific pages and content to crawl and, evidently, index. The most popular ones are robot.txt files that go hand-by-hand with meta robots tag. Though being a couple, they exist in a self-sufficient way.
The robots.txt file is placed in the root directory of the website. It provides search robots with the information that specifies what parts of the website should be crawled. It may be a page, a subfolder, and other site components. Generally, it helps you signal Google robots what sections of your website should be crawled preferably and which of them are to be less promoted or even ignored. In robots.txt, ‘allow’ and ‘disallow’ directives take action. However, don’t forget that these bots are not obliged to follow the rules you set. In July 2019, Google officially discredited directives in robots.txt file.
If you deal with page content and want to manage the way of showing it, you’d better come up with meta robots tag. The meta robots tag is placed in the <head> section of a web page and has a bunch of valuable instructions.
If you’re eager to learn more about directives in meta robots and robots.txt, visit these blog posts:
'What Is Robots.txt, and How to Create It'.Nevertheless, there is another means of noindex and nofollow directives management that is worth mentioning. This is X-Robots-Tag, and it has some distinctive features compared to the previous fellows.
Unlike the meta robots tag, which is placed in the HTML of the page, X-Robots-Tag is a part of an HTTP header sent from a web server designed to control the indexing process of the overall page including specific file types. Checking X-Robots-Tag is a tad more complicated, but thanks to the built-in tools in Netpeak Spider it’s far easier.
- Go to the ‘Run’ dropdown menu in the upper right corner → ‘Source code and HTTP header analysis’.
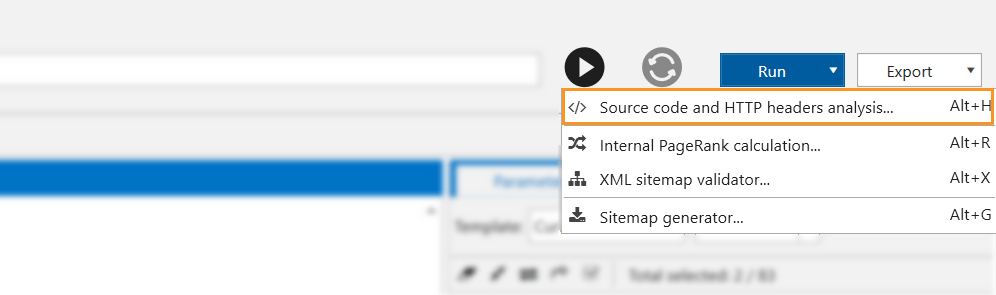
- Enter the URL you’re going to inspect, hit the ‘Start’ button, and in a few seconds, you’ll see all HTTP headers on the right. This is how X-Robots-Tag looks like in HTTP response header:
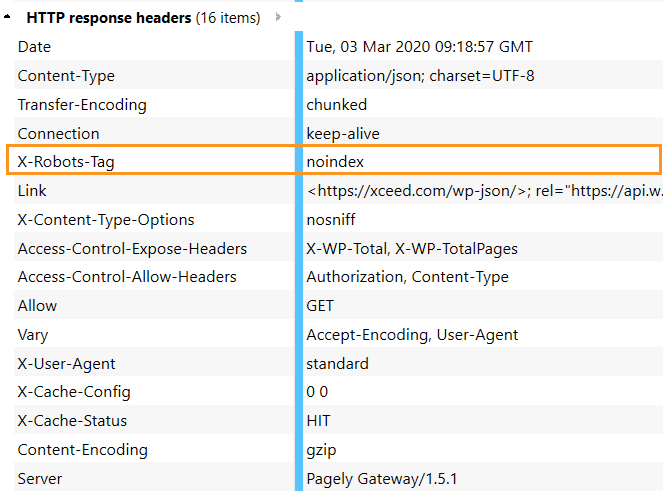
To get access to free Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
2. When to Use X-Robots-Tag?
Of course, you may handle the majority of questions concerning website crawling with the help of robots.txt files and meta robots tag. But there are a few cases where X-Robots-Tag will seem to be a better fit:
- You want certain video, image file types, or PDF not to get indexed. Or let’s imagine that you want to set a selected URL to be invisible for a specific period of time.
- Use your crawl budget reasonably. The main aim is to steer a robot in the right direction. Robots don’t need to spend time indexing unimportant parts of the website (such as admin and thank-you pages, shopping cart, promotions, etc.). But it doesn’t mean that these parts aren’t important for users, and you don’t have to spend your optimization efforts brushing up on the quality of these pages.
- You need to noindex a whole subdomain, subdirectory, pages with specific parameters, or anything else that requires bulk editing.
3. How to Implement X-Robots-Tag on Website
X-Robots-Tag is an HTTP header that is sent from the web server (that’s why it is called response header). Remember that the only way to noindex non-HTML files such as PDF files, or image files (jpeg, png, gif, etc.) is X-Robots-Tag. The X-Robots-Tag can be added to a site’s HTTP responses in an Apache server configuration via .htaccess file.
Note that the procedure of X-Robot-Tag implementation is somewhat complicated because it takes place at the code level. Usually, X-Robot-Tags are set up by webmasters. Any mistake can result in gross issues. For example, some syntax error can result in the site breakdown. It’s also recommended to check for issues in the X-Robots-Tag regularly since it’s a vast place for different kinds of issues.
This is how X-Robots-Tag header will look if you decide the page is not to be indexed:
Compared to the meta robots tag:
If several directions are used simultaneously, it will appear the following way:
3.1. X-Robots-Tag Directives
For the most part, the directives of are the same as for the meta robots tag:
- follow – routes search robots to the page and tells them to crawl all the links available on the page
- nofollow – prevents robots from crawling of all available links on the page
- index – routes bots to the page and allows them to index the page
- noindex – prevents bots from indexing the page, having hidden it from SERP showing
- noarchive – keeps the page from Google caching
4. How to Check X-Robots-Tag for Possible Issues
Since X-Robots-Tag affects crawling and indexing of the website, you should be especially vigilant with its implementation. So it’s kind of a must to regularly check for directives settings. We’re going to check X-Robots-Tag in Netpeak Spider in two steps.
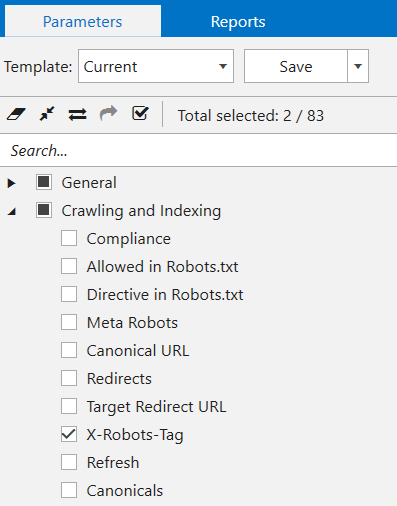
- Select ‘X-Robots-Tag’ parameter in a sidebar, and hit the ‘Start’ button to start crawling.
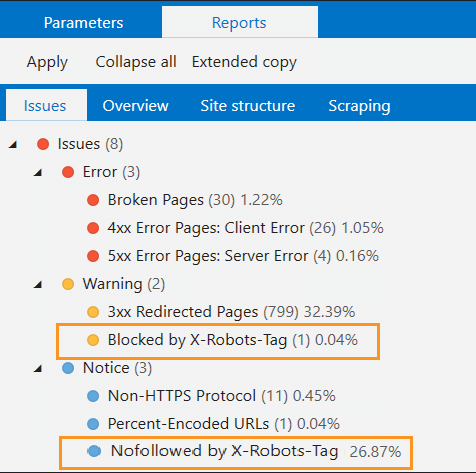
- When the crawling is completed, scrutinize the spotted issues. Yes, Spider identifies noindex in X-Robots-Tag as a warning for you to pay your attention to what data was blocked.
Let’s Recap
With that said, the range of X-Robot-Tag advantages for page indexing and crawling is rather big. X-Robots-Tag header aims to guide search engine crawlers, using their crawl budget reasonably, especially, if the website is big, full of different content. So the main takeaways are:
- X-Robots-Tag, together with robots meta tags, is used to optimize the crawl budget, steering a robot towards important for indexing pages.
- X-Robots-Tag occurs in the HTTP response header, that’s why SEOs often need webmasters’ assistance to implement it on the website.
- All directives should be regularly checked with Netpeak Spider or other SEO crawlers, since their power can affect the future indexing of the website, or even lead to ranking drops.


