Почему поисковые роботы и Netpeak Spider не сканируют ваш сайт
Кейсы

Сайты попадают в результат выдачи поисковых систем только после того, как поисковые роботы просканируют их и внесут в свою базу данных. С этим процессом могут возникнуть сложности, если владелец сайта непреднамеренно закрыл страницы от индексации. В таком случае роботы просто не будут сканировать сайт и добавлять его в индекс.
В рамках данного поста я подробно расскажу о причинах, по которым ваш сайт может не сканироваться поисковыми роботами и Netpeak Spider.
1. Инструкции индексации
В большинстве случаев поисковые роботы следуют инструкциям, указанным в robots.txt, HTTP заголовках ответа сервера и метатегах. Давайте рассмотрим каждый случай подробно :)
1.1. Robots.txt и XML Sitemap
Robots.txt — это текстовый файл, помещённый в корневой каталог сайта. Он показывает, какие поисковые роботы могут сканировать сайт, а также какие страницы открыты для сканирования и индексирования.
Кроме того, файл robots.txt должен содержать XML-карту данного сайта. Это поможет ботам сканировать все необходимые страницы, особенно если сайт большой.
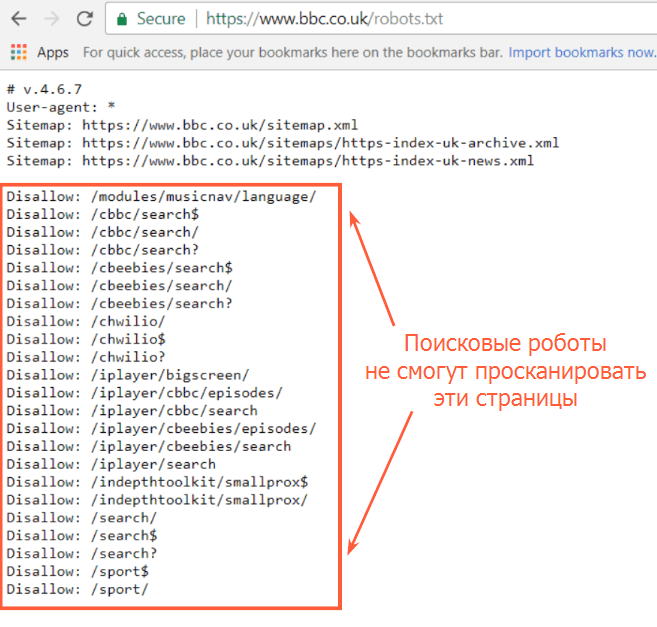
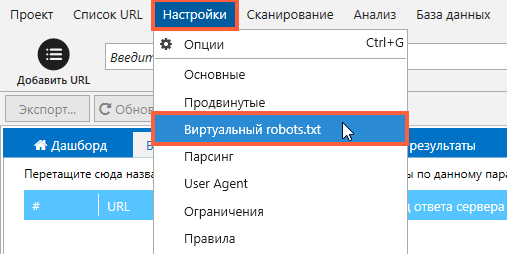
Вы можете протестировать файл robots.txt перед внедрением на свой сайт с помощью функции «Виртуальный robots.txt» в Netpeak Spider.
1.2. Мета-директивы Robots
Здесь расскажу о метатеге Robots и X-Robots-Tag. Эти директивы могут запретить поисковикам обнаруживать ваш сайт.
1.2.1. Meta Robots
Метатег Robots поможет задать настройки индексации и отображения в результатах поиска отдельно для каждой страницы. Его следует расположить в области head HTML страницы. Если на странице есть метатеги noindex, поисковые роботы скорее всего не будут посещать ваш сайт и сканировать его.
Вот пример того, как этот тег должен быть написан для всех роботов:
Вот пример только для поискового бота Googlebot:
1.2.2. X-Robots-Tag
X-Robots-Tag может использоваться как элемент HTTP-заголовка ответа сервера для заданного URL-адреса. Чтобы использовать X-Robots-Tag, вам необходимо получить доступ к файлу заголовка .php, .htaccess или сервера.
Ниже приведен пример HTTP-заголовка ответа сервера, где запрещена индексация страницы с помощью X-Robots-Tag:
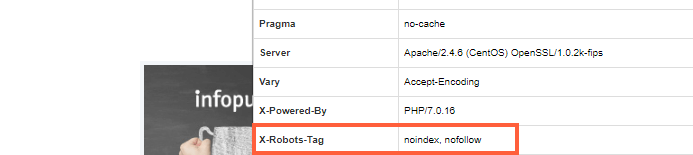
Если ваш сайт или отдельные его страницы закрыты с помощью упомянутых выше инструкций, и вопреки вашему желанию Netpeak Spider не сканирует его, вы можете легко изменить некоторые настройки и осуществить-таки сканирование ;)
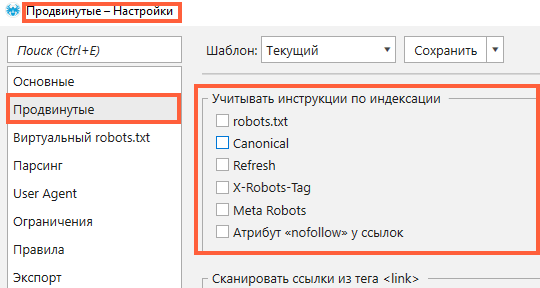
Для этого перейдите во вкладку «Продвинутые» в «Настройках» и снимите отметку для всех пунктов в разделе «Учитывать инструкции по индексации».
Подробнее о том, как разрешить роботам сканировать ваш сайт, читайте в нашем посте «Как проверить индексацию Google с Netpeak Spider и Netpeak Checker».
У Netpeak Spider есть бесплатная версия без ограничений по времени, в которой вы сможете проверять инструкции по индексации и сканированию! Также во Freemium-версии доступны и другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.2. Сanonical
Владельцы сайтов могут настроить атрибут rel = canonical, с помощью которого можно указать роботам поисковых систем предпочтительную для индексации страницу.
Приведу в пример проблему, связанную с отсутствием соответствующих настроек. Сайт tastypancakes.com переехал с протокола HTTP на HTTPS. Конечно, все страницы с HTTP были перенаправлены на соответствующие на HTTPS, но сайт на сайте HTTPS стоит rel = canonical на HTTP-версию.
Это серьезная проблема, потому что вы не даёте краулеру просканировать ваш сайт. Чтобы решить эту проблему для поисковых роботов, настройте rel = canonical на своём сайте. Чтобы разрешить сканирование в Netpeak Spider, снимите отметку «Canonical» в разделе «Учитывать инструкции по индексации», как показано на скриншоте выше.
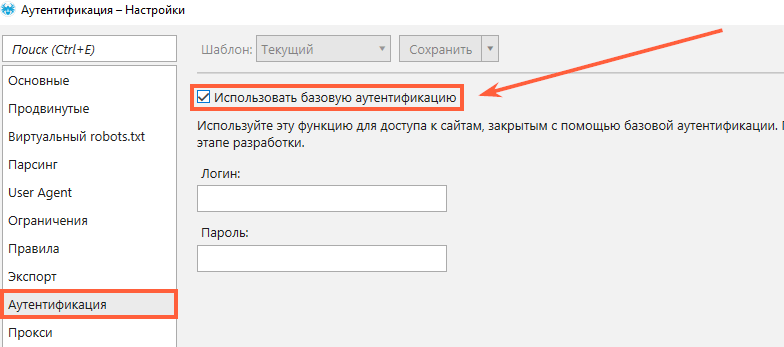
3. Авторизация
Если ваш сайт требует авторизации, краулер и поисковые роботы не смогут его проиндексировать. К примеру, это может быть тестовая версия вашего сайта, и вы не хотите видеть её в поисковой выдаче, но хотите проверить перед релизом. В таком случае всё просто. Выберите вкладку «Аутентификация» в настройках сканирования, отметьте «Использовать базовую аутентификацию», введите свой логин и пароль и проведите сканирование вашего сайта :)
4. Заблокировано в .htaccess
Вы можете закрыть доступ краулерам в вашем файле .htaccess. Этот файл находится в корневом каталоге сайта (ваш каталог public_html). Вы можете открыть его с помощью диспетчера файлов в вашей cPanel или с помощью FTP-клиента (например, FileZilla). Вот пример блокировки некоторых ботов поисковой системы в файле .htaccess с помощью функции RewriteEngine в строке User Agent:
Таким образом вы можете сохранить файл .htaccess и загрузить его на свой сервер, перезаписывая оригинал. Если вы хотите изменить инструкции, вы можете вернуть исходный файл .htaccess или удалить правила.
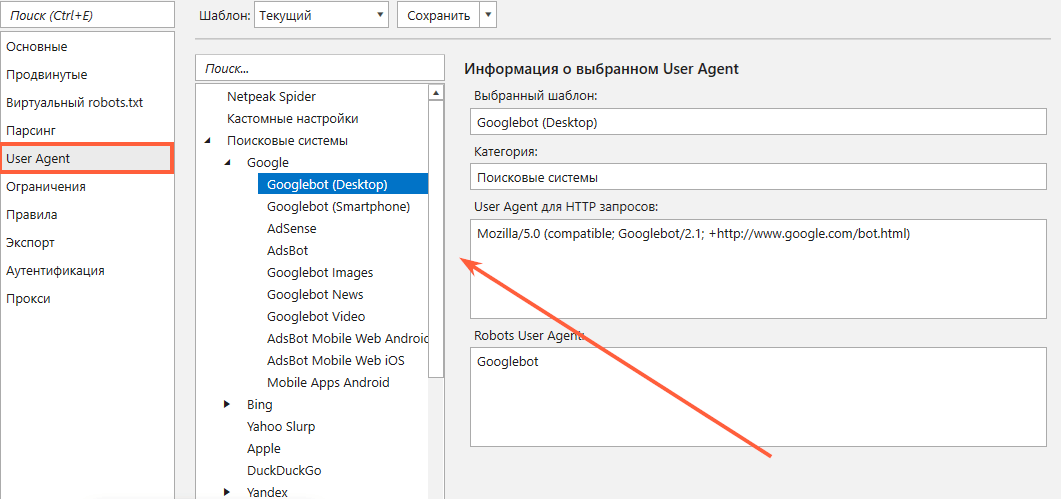
Если вы не хотите менять инструкции в своём файле .htaccess, но хотите просканировать сайт с помощью Netpeak Spider, выберите User Agent, который не заблокирован в вашем файле .htaccess в «Настройках» краулера.
5. Время загрузки
Согласно Google, время ответа сервера должно быть менее 200 мс. Если ваш сайт загружается целую вечность, поисковые роботы не будут долго ждать и просто прекратят сканирование. К вашему сведению, максимально возможное время ожидания ответа в Netpeak Spider составляет 90 000 мс, и вы можете управлять этим показателем в основных настройках программы.
Подробнее о времени ответа сервера читайте в нашем посте.
6. Заблокировано из-за ошибки 'Too Many Requests'
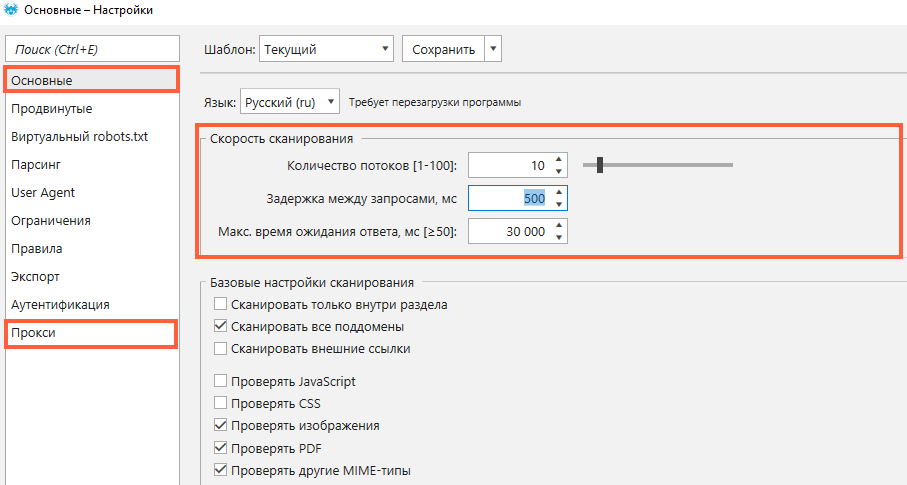
Эта причина в большей степени относится к Netpeak Spider. На некоторых сайтах есть «защита» — код ответа сервера 429. Такой код появляется, когда пользователь отправил слишком много запросов к серверу за определённый промежуток времени. Вы можете самостоятельно выставить скорость сканирования в Netpeak Spider. Просто перейдите в «Настройки», выберите вкладку «Основные» и установите минимальное количество потоков или задержку между запросами. К тому же, вы можете использовать список прокси ↓
Подводим итоги
Чтобы ваш сайт попал в поисковую выдачу, его должны просканировать поисковые роботы. Иногда это невозможно из-за:
- инструкций индексации (robots.txt, Meta Robots, X-Robots-Tag);
- неверного использования Canonical;
- настроек авторизации;
- блокировки в файле .htaccess;
- чрезмерно долгого времени загрузки сайта;
- блокировки сайта из-за слишком большого количества запросов.
Netpeak Spider может столкнуться с теми же проблемами во время сканирования вашего сайта, что и поисковые роботы. К счастью, их очень легко решить → несколько кликов в «Настройках», и вы можете увидеть свой сайт глазами поисковых роботов, перед тем как открыть его для них.
Расскажите в комментариях о проблемах, с которыми вы сталкивались при сканировании сайтов:)
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider



