How to Find Expired Domains Using Netpeak Spider & Checker
Use Cases

Tsup! In this post, I want to explain how to set up a process of expired domain search using our tools – Netpeak Spider & Netpeak Checker. Step-by-step, I'll go through each stage to find ‘my precious’ expired domains.
In the end, I’ll share a spreadsheet with available domains that I’ve found. Plus, all of them have links from high-authority websites. You better take a cup of your fav drink now and close your Facebook so nothing can distract you from catching those domains first 😜
- 1. Where to Find Expired Domains
- 2. Check if Sites Are Available for Purchase
- 3. Expired Domains for Free
- 4. What You’ll Read in Mouseprint
Read more → How to find dropped domain
1. Where to Find Expired Domains
What did I have at the beginning? This is my starter pack:
- Netpeak Spider и Checker Pro subscriptions to solve every task, but
You can search for expired domains even in the free versions of Netpeak Spider and Checker that are limited by the number of analyzed URLs. Other basic features are also available in the Freemium version of the program.
To get access to free Netpeak Spider, you just need to sign up, download and launch the programs 😉
- MacBook Pro 16GB RAM running BootCamp with Windows
- Sparkling eyes ✨
That was enough to find 500+ expired domains, although the quality of many is dubious. I'll share the full list because the purpose of searching for expired domains doesn’t always shrink to the links. What if you like the design or content? 😃
So here’s my drill: I crawled as many pages from the trusted websites as possible, fished out external links, and found available domains. I call this method ‘cheap and cheerful,’ and I’ll share a step-by-step algorithm.
1.1. Choose Sites for Expired Domains Search
I selected the top news and media websites according to the website rating in SimilarWeb and Ahrefs:
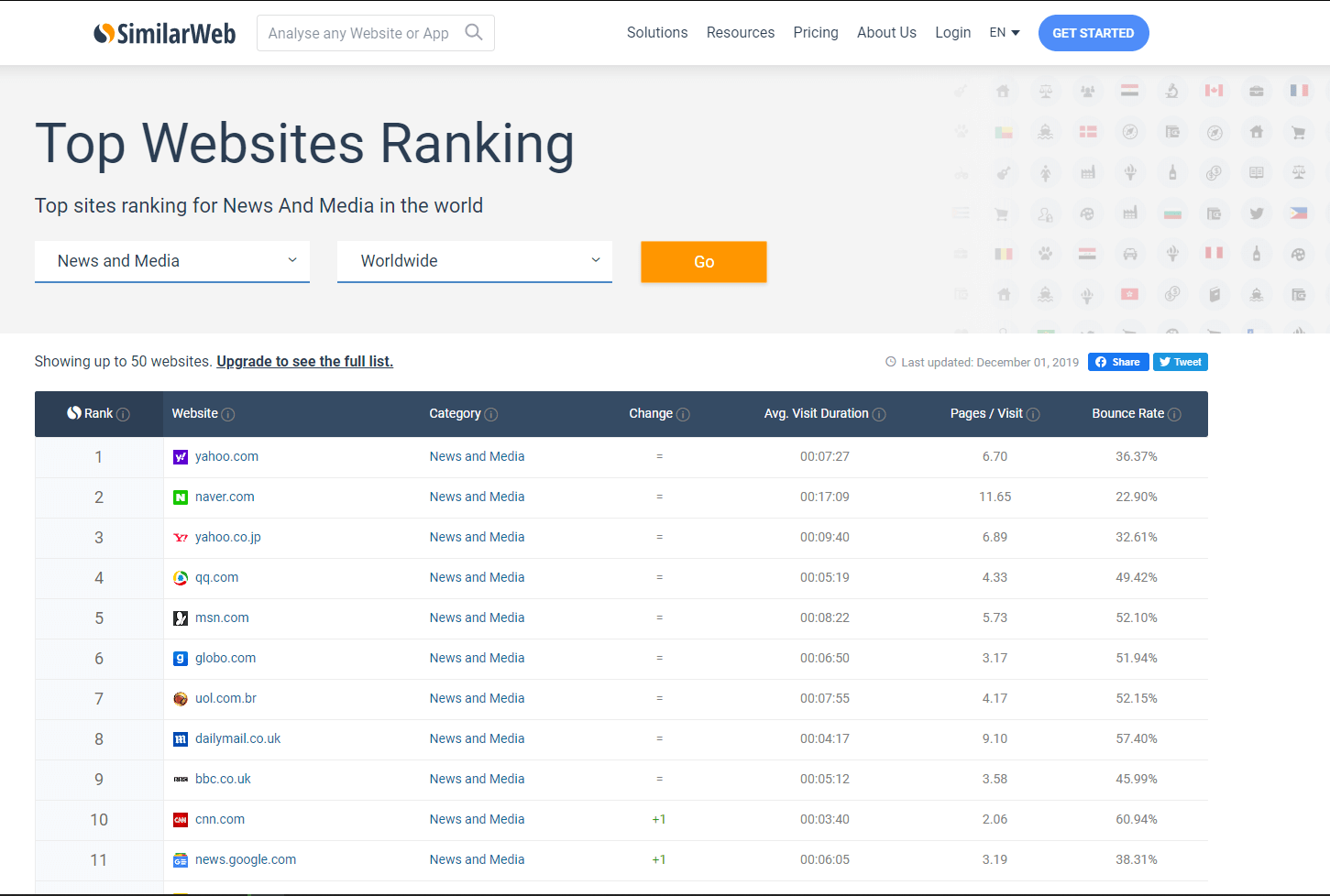
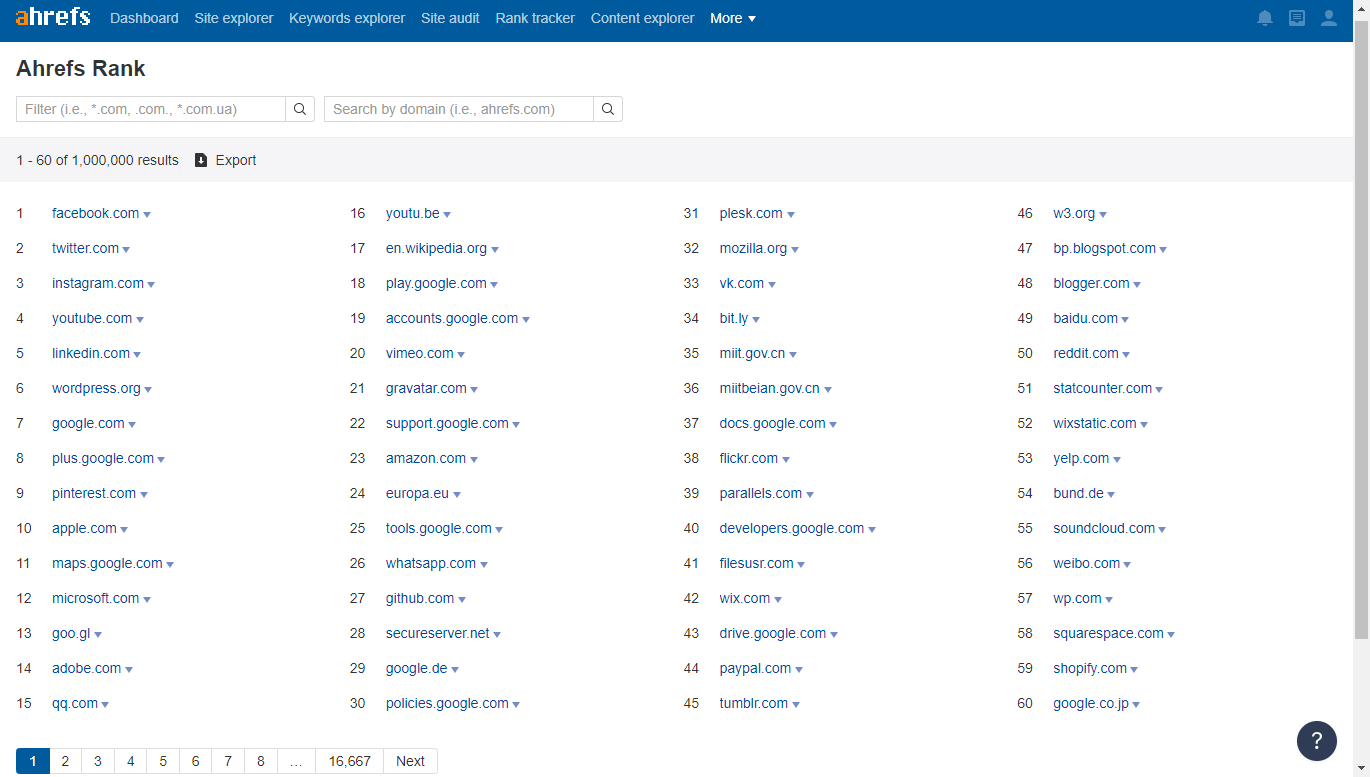
Manually go through the list of sites to select those that may have a lot of external links. These include: wikipedia, wikihow, bbc.co.uk, foxnews.com, and the like.
Also, in Netpeak Spider, check server response content for these values:
- Status code = 200 OK
- Useful content in the source code, not just a plug against the robots
For this purpose, I use the ‘Source code and HTTP headers analysis’ tool, in which I check status code and approach data in the ‘Extracted text’ tab → it helps grok if the source code is correct.
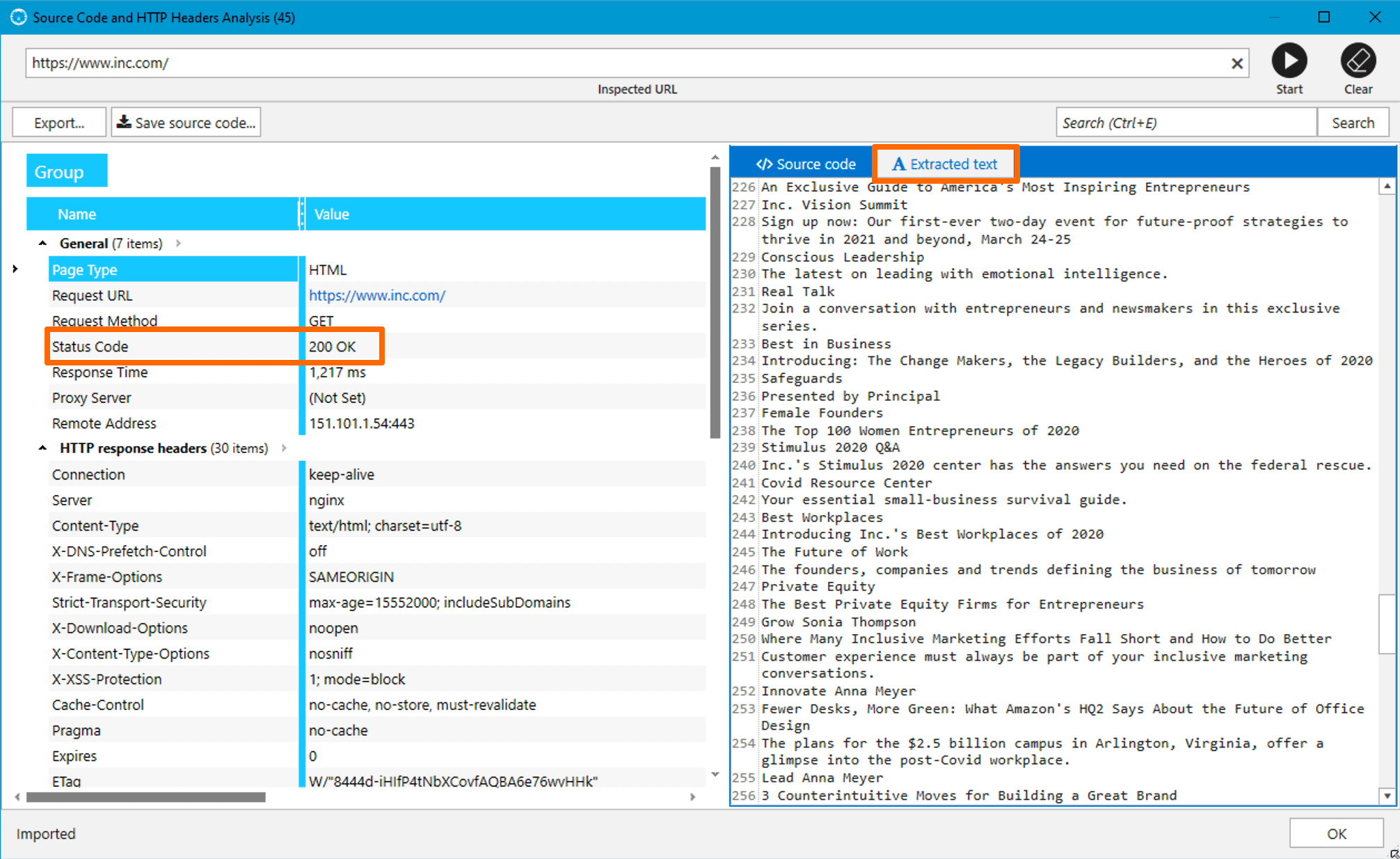
If there’s meaningful content on the page, I add this domain in the Netpeak Spider table.
1.2. Ideal Crawling Settings and Parameters to Find the Links you Need
After adding the list of domains to the table, you need to configure the crawler properly. We’ll be using two control elements: crawling settings and crawling parameters. First, I’ll show how to enable the right crawling settings.
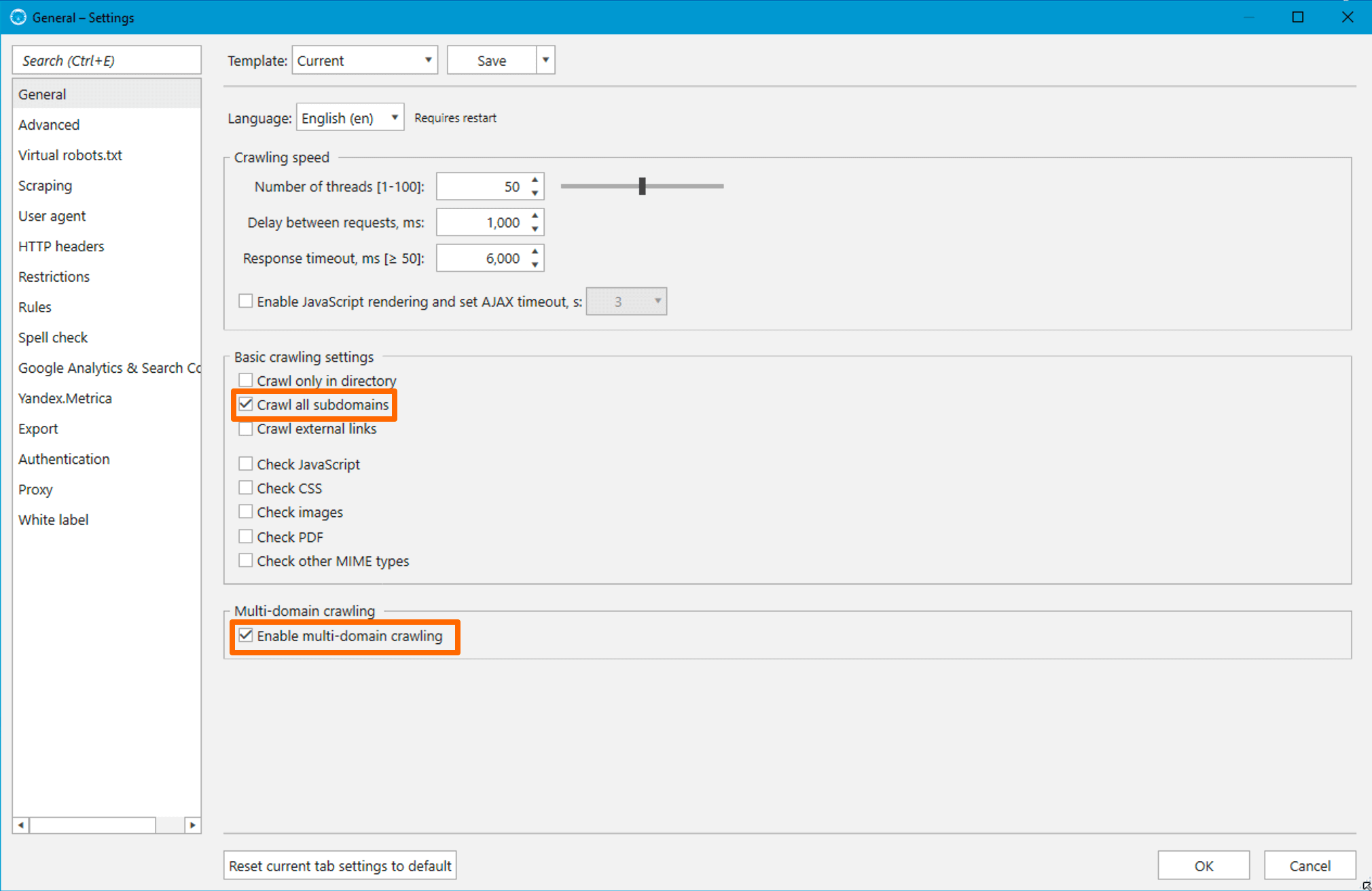
First necessary settings dwell on the ‘General’ settings. Let’s tick the checkboxes:
- Enable multi-domain crawling. We use this feature to make the crawler go deep into multiple sites simultaneously. It’s included in the Pro plan, which is available to users with a purchased license for this plan 💓 If you have a Standard plan, you need to crawl each site separately, specifying it in the initial URL field, and then join all reports manually. Harder, time-consuming, still manageable 👌
- Crawl all subdomains. When we finish crawling and export the report on external links, all subdomains of the crawled sites will be considered internal, and they won’t take up extra space.
Some details that may come in handy:
- No need to add pages blocked from crawling and / or indexing to the table. So that links from such pages couldn’t slip to reports, on the ‘Advanced’ settings tab, check the items as shown in the screenshot below.
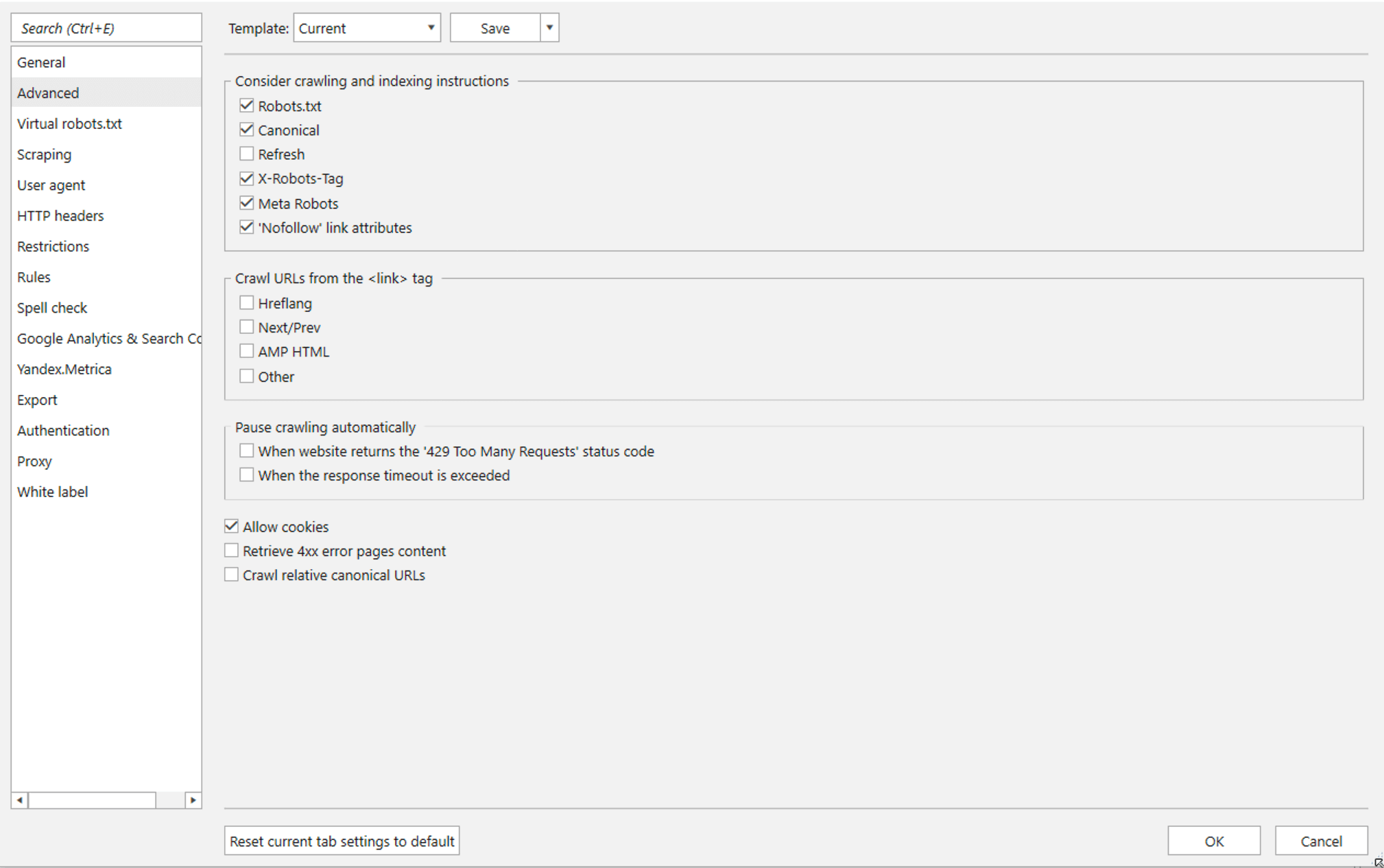
- Some sites are protected against robots, so it’s better to use a proxy and no more than 10 crawling threads → this will reduce the chance of being blocked. Though in my case, there were no problems with 50 threads either.
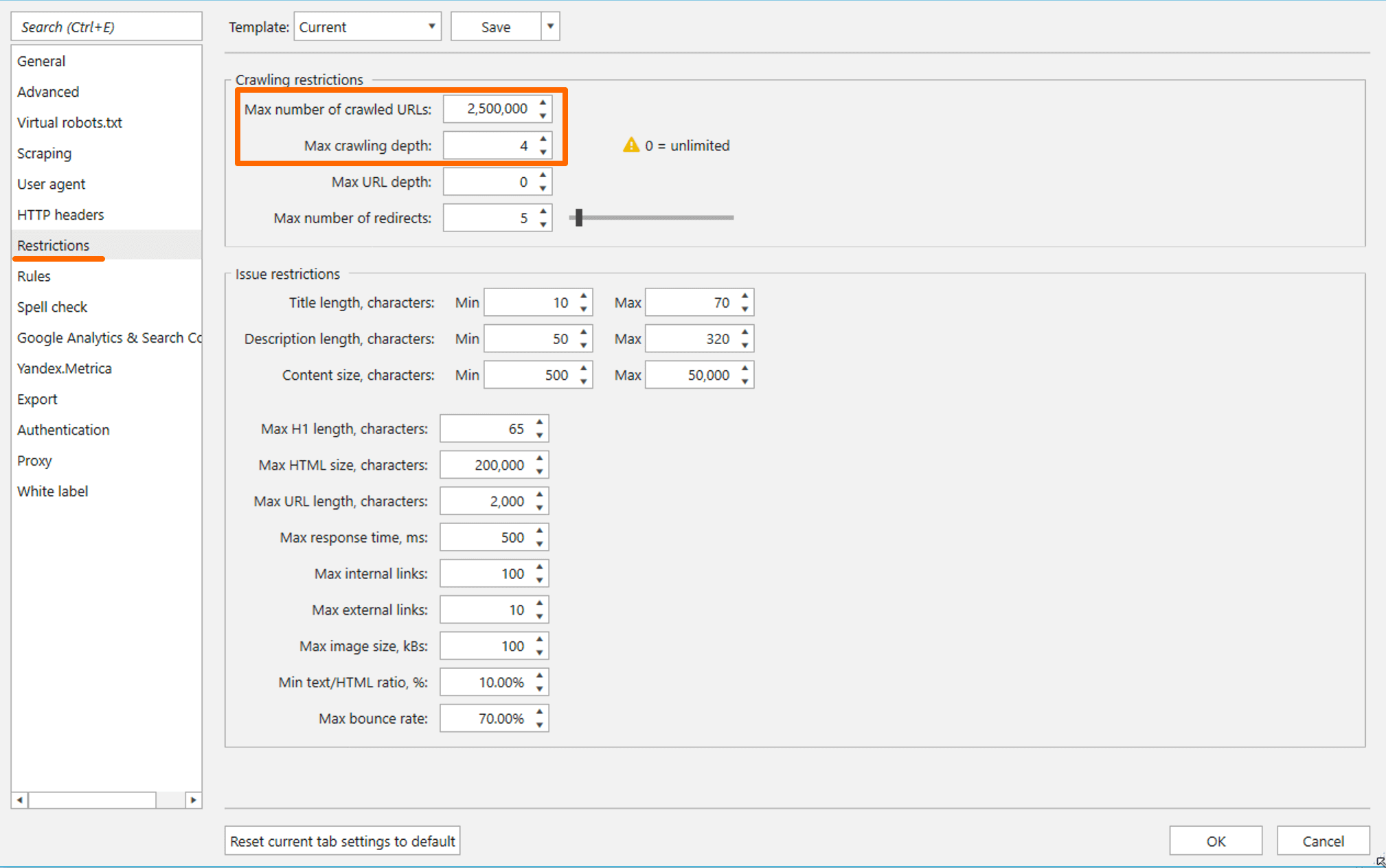
- I advise you to limit the number of crawled pages on the ‘Restrictions’ tab. If you have a computer with 16 GB of free RAM, set 100 thousand first. When the program finishes crawling them, save the project, increase the limit to 500 thousand pages and click on the ‘Start’ button. Iterate crawling in such chunks until you have enough free RAM not to lose data in case of a sudden blackout or other troubles.
Bear in mind that our paid plans have a backup feature for such a case 😎 Every 5 minutes, the program automatically creates a temporary copy of the project to not lose data due to the ‘miseries of the world’. But you also don’t hope and pray for your computer. There are different situations, so I advise you to save the project manually from time to time, as I said.
- Additionally, you can specify the maximum crawling depth for each site. I set the value of ‘4’ to keep Netpeak Spider from going deep inside each site.
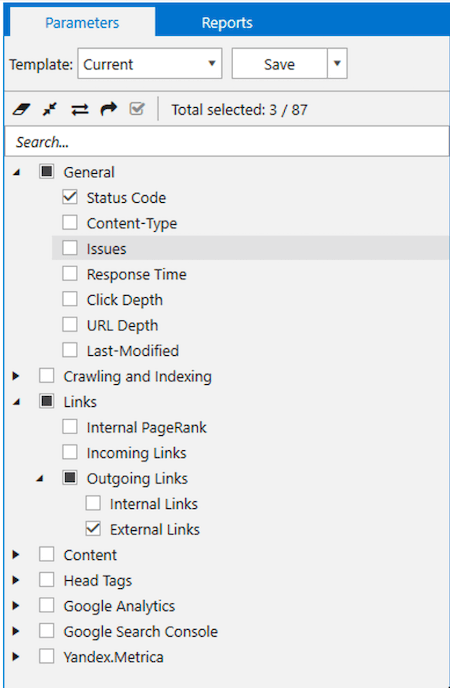
Let’s look at the crawling parameters. This task requires a lot of RAM, so you need to collect only the most necessary data. I selected three parameters:
- ‘Status Code’. It’ll help save time on exporting a massive report on ‘All internal and external links (XL)’, since I use the segment to single out only compliant pages.
- ‘External Links’. This parameter will collect all the necessary links to external websites, the expiration date of which I check.
- ‘Outgoing Links’. The parameter is enabled automatically when you want to collect external links.
This is how the selection of the necessary parameters looks like:
1.3. Search for Domains that Need to Be Checked
After the crawling was all set up, hit the ‘Start’ button. Since crawling a million or more pages takes a lot of time, you can read other articles in our blog and watch the video on our YouTube channel to kill time with benefits.
If you see that there is not enough free RAM left, I advise you not to open many tabs in the browser and shut down all resource-intensive processes during crawling. Otherwise, it can lead to a blue screen, computer hiccups, or the opening of a new black hole.
After the crawling is completed, I created a segment for compliant pages to slightly reduce the volume of the exported links. So this is how I cut off more than 500 thousand pages. To apply it on your side, choose the 'Compliant' option in a sidebar and on the ‘Use as segment’ button as shown in the screenshot below:
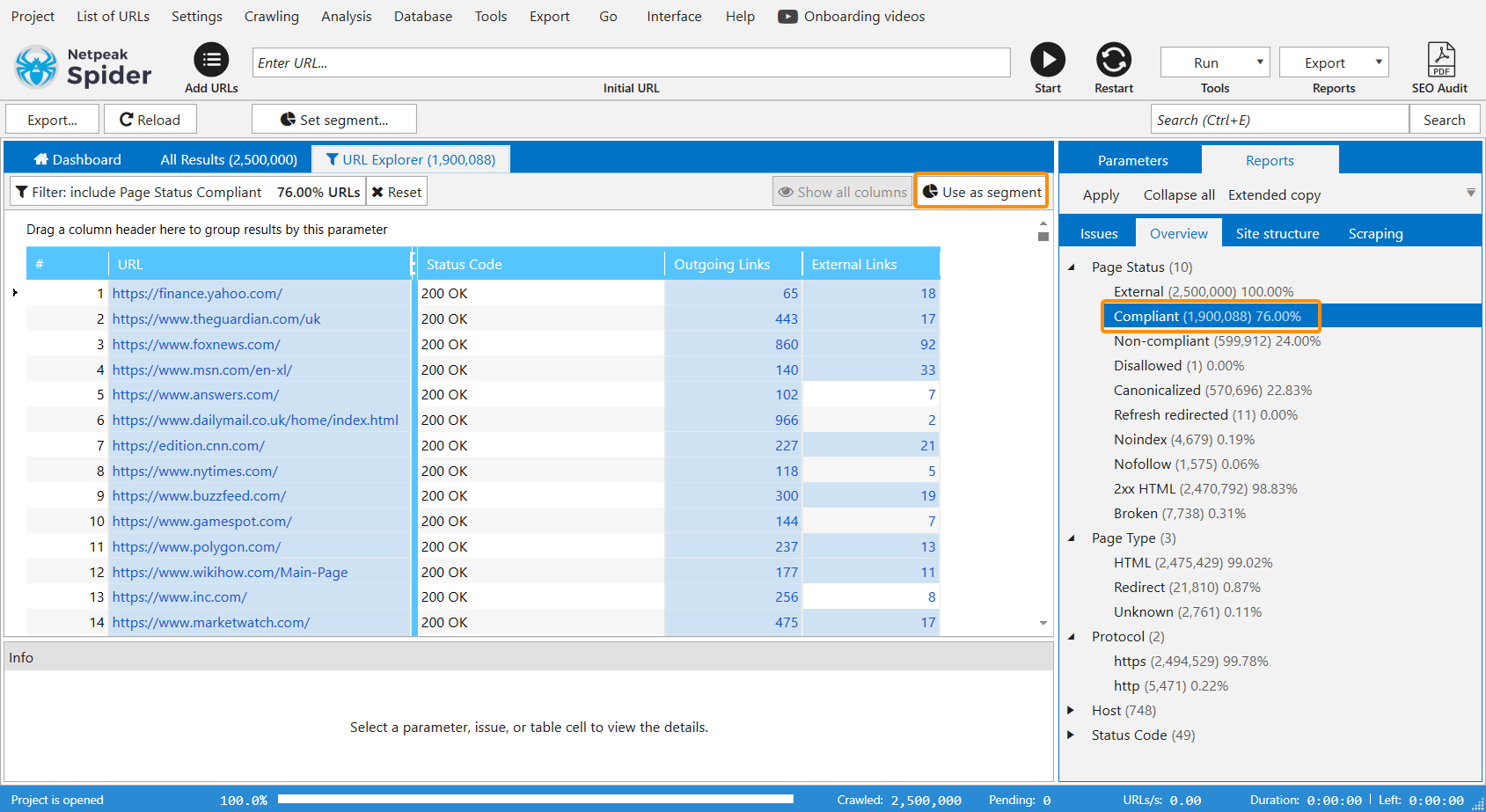
Then I started exporting all external links → selected the ‘External links (XL)’ item in the export menu.
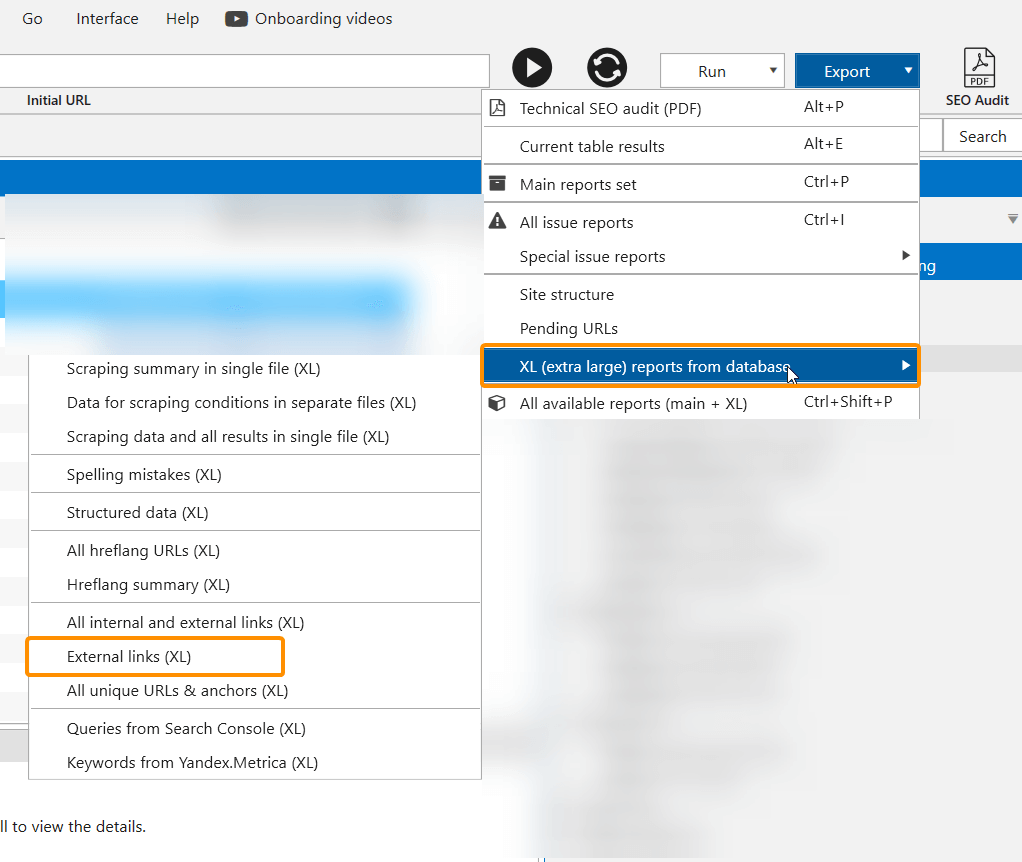
It took an hour to export the reports, I got 53 files – million lines each. Exported files contain data on the link source, its anchor text, etc. This is how a standard export looks like:
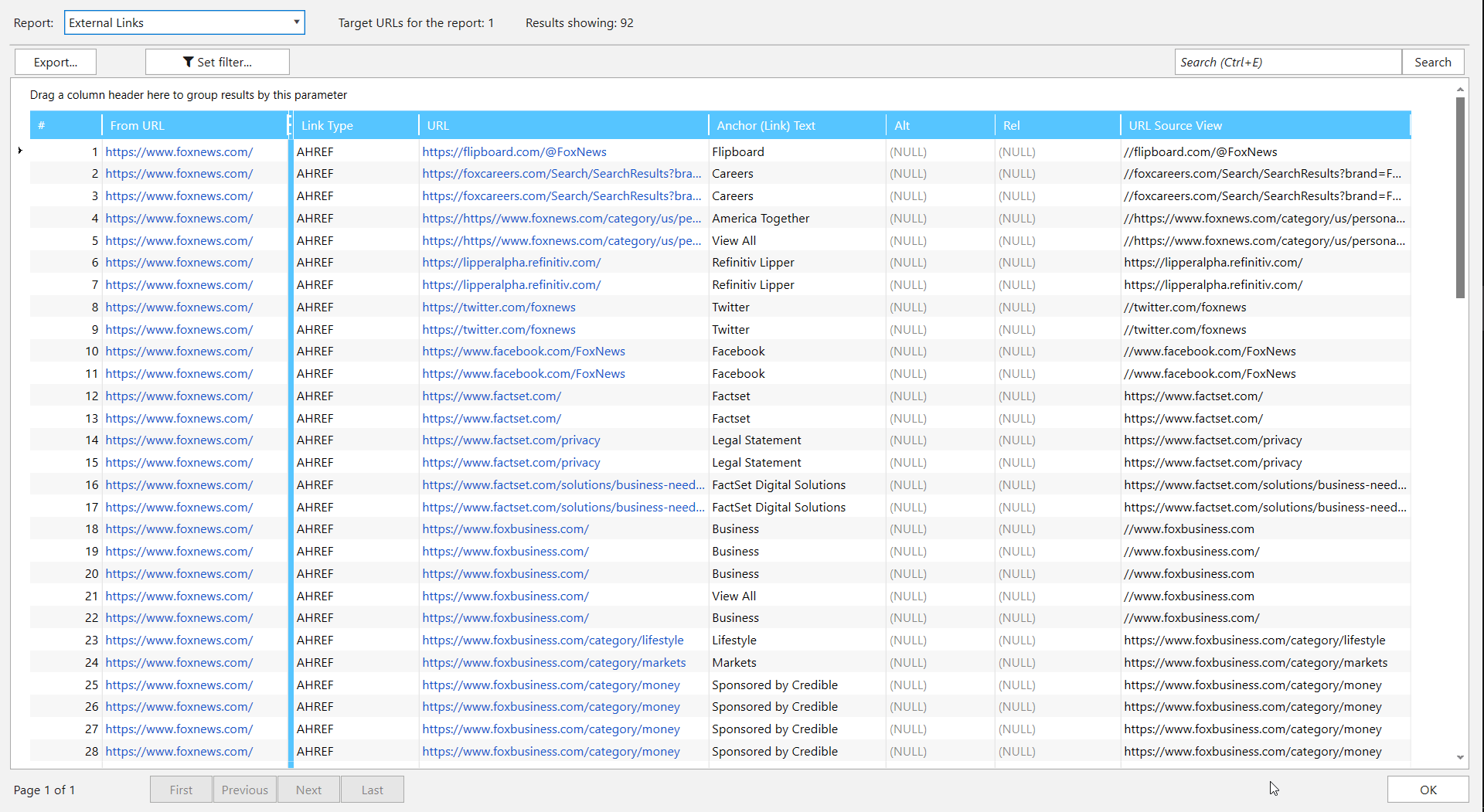
For a check, you need to get unique links from the ‘URL’ column. There are two ways of extracting them:
- To use the script, which will raffle through all files and collect unique pages. It’s a fast but complicated method. And if you have no idea how to write such a script, you have to hire a person and pay them.
- Manually flick through all documents. It’s this method that I want to show, since it doesn’t require additional money spendings, but it’ll take a lot of time, so if you’re ready you have to bite the bullet.

1.4. Extract Domains that Need to Be Checked
I failed to find a single and all-purpose way to extract hosts manually. I’ll share the one which turned out to work for me:
- Open Netpeak Checker.
- Start adding links from 53 documents (it’s better to take about 4-5 at a time).
- When the pages appeared in the table, I applied a long regexp as a filter. The regex is the most popular domains and a list of initially crawled websites separated by a dividing line ‘|’. The final filtering condition is shown in the screenshot.
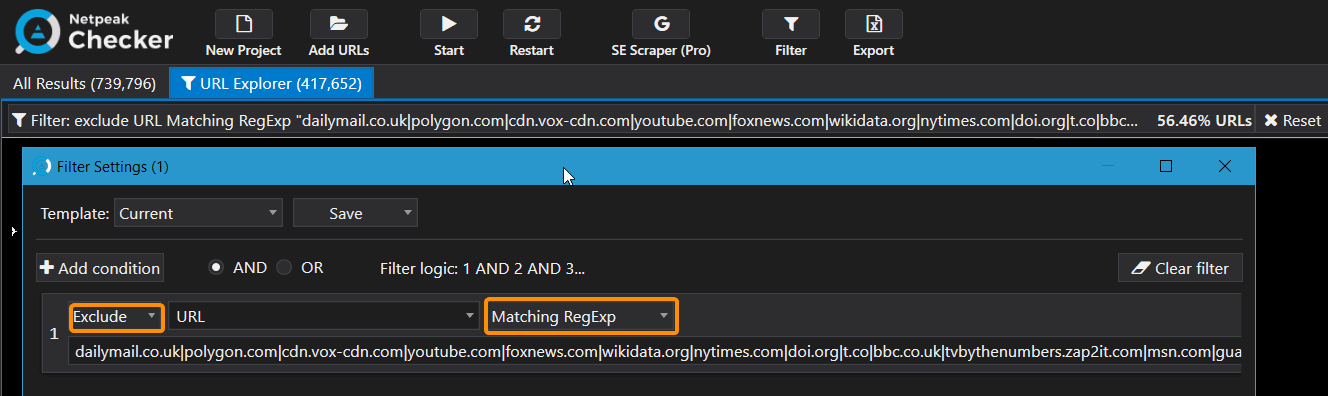
Here’s a regexp:
dailymail.co.uk|polygon.com|cdn.vox-cdn.com|youtube.com|foxnews.com|wikidata.org|nytimes.com|doi.org|t.co|bbc.co.uk|tvbythenumbers.zap2it.com|msn.com|guardian.co.uk|awin1.com|worldcat.org|asos.com|news.bbc.co.uk|archive.org|washingtonpost.com|pubmed.ncbi.nlm.nih.gov|deadline.com|imdb.com|telegraph.co.uk|fave.co|hollywoodreporter.com|instagram.com|jstor.org|amzn.to|variety.com|independent.co.uk|amazon.co.uk|net-a-porter.com|wiki|farfetch.com|marvel.com|wikipedia|facebook.com|twitter.com|wikimedia|google.com|pinterest.com|amazon.com|linkedin.com|guardian.co|yahoo.com|youtube.com|bbc.co.uk|imdb.com|cnn.com|kotaku.co.uk|en.wikiquote.org|ncbi.nlm.nih.gov|microsoft.com|kotaku.com|comicbookresources.com|guardianbookshop.co.uk|cbsnews.com|thesun.co.uk|id.loc.gov|usatoday.com|huffingtonpost.com|viaf.org|tools.wmflabs.org|comicbookdb.com|ign.com|thefutoncritic.com|reuters.com|comics.org|marvel.com|a.msn.com|people.com|d-nb.info|tvline.com|npr.org|isni.org|latimes.com|bbc.com|es.wikihow.com|articles.latimes.com|newsarama.com|digitalspy.co.uk|interactive.guim.co.uk|tmz.com|wsj.com|abcnews.go.com|politico.com|marvunapp.com|nydailynews.com|en.wiktionary.org|tvshowsondvd.com|forbes.com|de.wikihow.com|nbcnews.com|cbr.com|abc.net.au|edition.cnn.com|pt.wikihow.com|abcmedianet.com|smh.com.au|ew.com|tvguide.com|reddit.com|ui.adsabs.harvard.edu|nypost.com|time.com|radio.foxnews.com|fr.wikihow.com|bloomberg.com|cbc.ca|matchesfashion.com|mediawiki.org|wikisource.orgAs a result, several million pages turned into 20-100 thousand after being filtered.
When you add pages to the program or apply filters, the program will most likely go into a ‘Not responding’ state. Don’t worry, leave it for 5-15 minutes. Netpeak Checker will perform all the necessary operations in the background and return to the working state. This doesn’t happen to ordinary projects. In case of several million, it’s a consequence of huge calculations, so you have to wait for a while.
- After the filters were applied, I exported tables with 20-100 thousand pages from the program to xlsx files, which I saved in a separate folder.
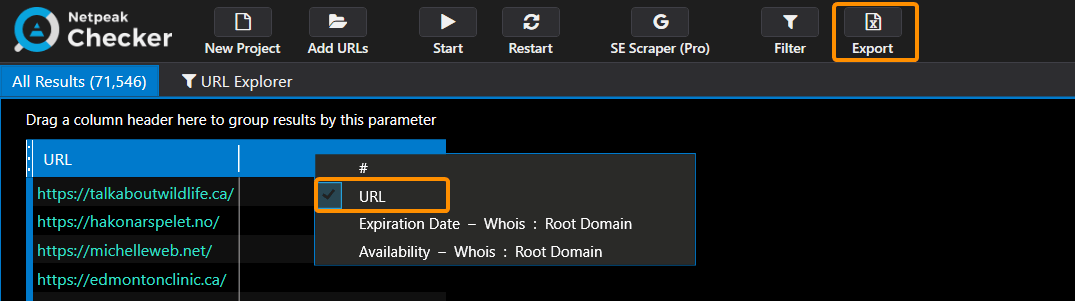
Lifehack. To reduce the file size, hide all columns in the current table except ‘URL’. The program will export only the data that is displayed in the table:
- After the monotonous first four steps, I had 46 documents with tens of thousands of URLs each. It remains only to cut off duplicate pages from these documents, which means you just need to open 16 small documents in Netpeak Checker, which is no longer as tricky as multimillion files 😅
I understand that it’s a long, menial work, that can feel like watching the grass grow. And if you want to do away with it, I recommend acquiring some basic programming skills to quickly deal with such tasks.
2. Check if Sites Are Available for Purchase
When the list of pages is already unique, you need to check which domains are available for purchase. And here we face a hard nut to crack because manually making a million checks at the domain name registrars would take a couple of years. I reduced the number of checks as much as possible and automated them. Here are several stages to follow.
2.1. Check the IP Address
One of the hallmarks of a free domain is that it doesn’t have an IP address. This parameter can be very quickly checked in Netpeak Checker, and I use it as the first filter:
- I enable only the ‘IP’ parameter in the ‘DNS’ group.
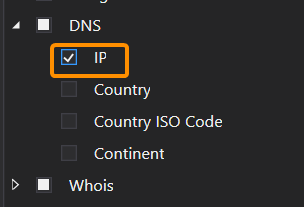
- In the ‘General’ settings tab, I set 200 threads. If you know that your computer wouldn’t manage these numbers, reduce them to the values that fit your computer capabilities.
- Lanch the analysis.
The approximate analysis speed is 200 thousand pages per hour, so you can confidently switch to other tasks while the program performs the analysis in the background.
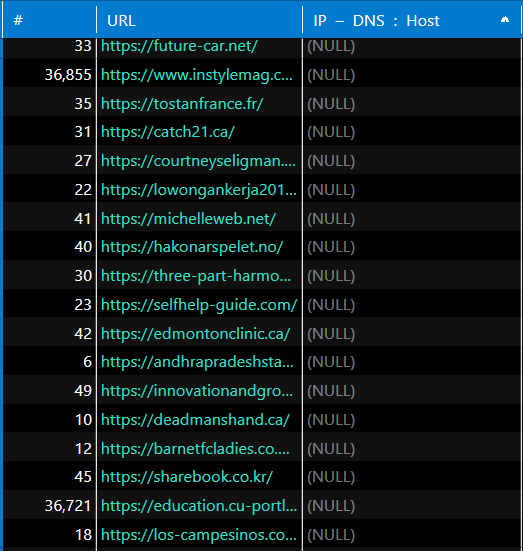
As a result, I got a little over 30 thousand hosts that didn’t have an IP address:
2.2. Whois Availability Check
Thanks to the integration of Netpeak Checker with the Whois service, we can narrow the range of searches even more. To do so, add these 30+ thousand hosts to the program, enable the ‘Availability’ and ‘Expiration Date’ parameters in the ‘Whois’ group. I also advise adding the ‘Host’ parameter from the ‘Website traffic’ group in order to then cut off a number of domain zones (.edu, .gov, .mil, .ua, .jp, .cn, .xxx). Then we start the analysis and get back to other tasks because this check will take a long time.
Several nuances in working with this service:
- Different check limits are set for different domain zones. For example, .pl, .au, .nl restrict data retrieval after the first hundred checks.
- Data for some domain zones may be false. It most frequently happens in the .ru domain zone.
To get around the first nuance, you can use Whois cloud verification services, which access the service from different locations, bypassing the blocks. It’s ideal to check them in Netpeak Checker first and then recheck the results with service errors or those that have reached the limit in cloud services. You can also use the API of the domain registrars that you use, they may have the ability to check domains in this way. But here, you should be able to work with the API, for example, using the IMPORTJSON feature in Google Spreadsheet, not to write a separate script for this purpose.
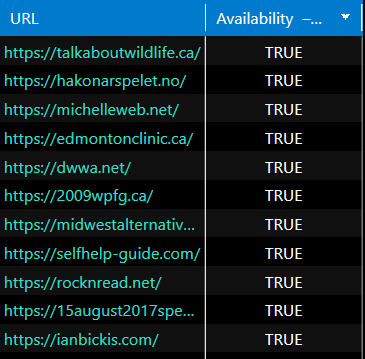
It took me 4 hours to check 30 thousand hosts. As a result, I got 2.5 thousand hosts in the table with the ‘Availability’ parameter with a value ‘TRUE’.
At this stage, I decided to go through the list of results again and purge it more carefully, because there were subdomains for which Whois showed incorrect data. There were a little more than 500 domains left. Even though there were still garbage results, their number was much less.
Moreover, you can save a list of domains that will soon expire in order to recheck them in 2-3 months.
Read more → Domain registration lookup
3. Expired Domains for Free
In Netpeak Checker, I collected several metrics from Ahrefs, Serpstat, and website traffic estimation for the received expired domains to separate the wheat from the chaff. And I’m gladly sharing the results with you. If you find yourself an expired domain or learned something new in a post, I’ll be chuffed to see comments and likes 😊
Table with the Cherished Domains
4. What You’ll Read in Mouseprint
The process I described is a long-long path. You can easily get lost, and it has downsides. But I picked it because I wanted to show all the teensy details of working with our programs and free options to do this check.
If you describe yourself as an advanced specialist, I would suggest you another algorithm:
- Export the list of external links from domains from Serpstat, Ahrefs, and others. It’ll cost significantly more, and you won’t be able to adjust the scanning as flexibly, but it’ll save you time.
- Use a script that will extract unique hosts from these exports and cut off unnecessary TLDs and subdomains.
- You can also check the IP address with a script, but our program is also good at it – the difference in speed will be slight 😎 All domains without a correct IP address go to the next step.
- I checked the availability for purchase without the external script inside Netpeak Checker. Still, you can make your own tool so that it can switch between SOCKS proxies. It’ll significantly speed up the check and increase the number of results obtained until the limit is reached.
- Additionally, double-check the availability with domain name registrars, and then look at the history of domains and metrics in the services before purchasing.

Wish you all traffic and a splendid day 😊


