Think Like SEO: How to Scrape Films for Your Summer Watch List
Use Cases
Summer has come, and it means that new watch and read lists that you have to take over before you die are about to burst the banks of all social media. Not to lag behind, I’ve hastily written this blog post to show you the ways of using the scraping feature in Netpeak Spider for mundane human purposes.
You can test scraping absolutely for free → Netpeak Spider crawler has a free version that is not limited by the term of use and the number of analyzed URLs. This and other basic features are also available in the Freemium version of the program.
To get access to free Netpeak Spider, you just need to sign up, download and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the one most suitable for you.
To make it effective, I wickedly appeal to the overarching foibles of SEO specialists who are bind to:
- spreadsheet addiction
- itching desire to put everything in order
- nerve-racking commitment to automate nearly everything
You’ll get insights on how to make your summer watch list that you can braggingly send to your friends in a spreadsheet with stunning descriptions, ratings, genre, etc.
To make that happen, you'll need the Netpeak Spider tool, the Amazon website, and a few minutes of spare time.
1. Comprehensive Guide: How to Scrape Data from Online Stores With a Crawler.
2. How to Scrape Prices from Online Stores with Netpeak Spider.
3. Web Scraping for Marketing and Sales: Market Analysis with Netpeak Spider and Netpeak Checker.
- 1. CSS Selector Is Your Type
- 2. Elements to Select
- 3. Connect the Dots in Netpeak Spider
- To Recap
1. CSS Selector Is Your Type
If you haven’t used the scraping feature in Netpeak Spider before you should get familiar with the four search types:
- CSS selectors and XPath help to extract the tag content or attribute in the source code of an HTML page – they carry out similar tasks but differ in syntax.
- Regexp stands for a regular expression and describes a pattern of characters. It determines what type of string you want to find on the page.
- Contains counts the number of search expression matches.
CSS selectors will perfectly fit our noble goal.
2. Elements to Select
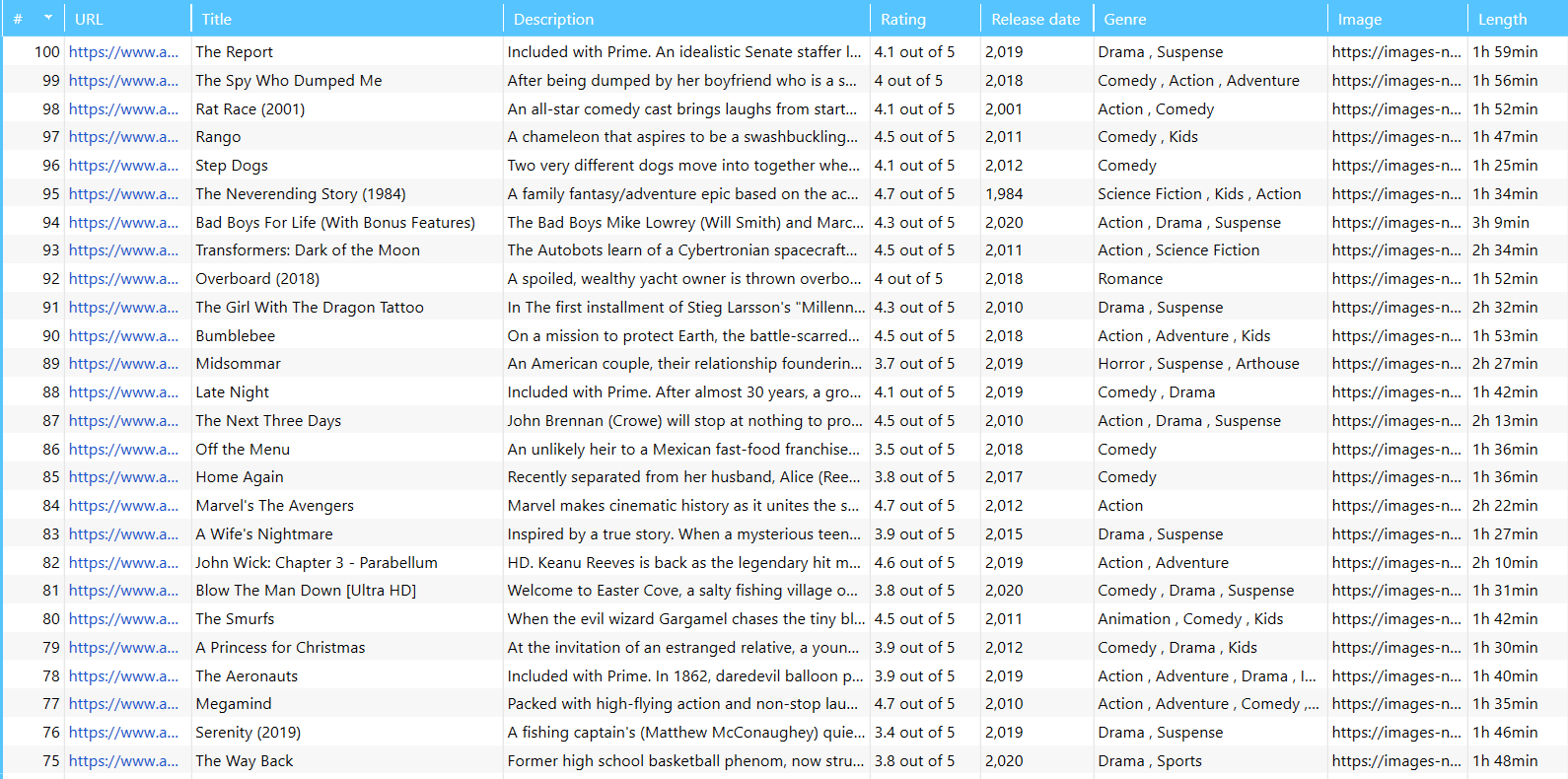
So these elements will help you compile a full-fledged list of TV shows:
- Film title
- Film description
- Rating
- Release date
- Genre
- Image
- Length
To find them, you need to go to the website and collect tag attributes. These are often the class id attributes because their values are mostly unique within the page (with a few exceptions).
Now let’s see where to look for these elements and how to cut the fluff.
2.1. Title
In 99% of cases, the <h1> tag of the page contains the title, so don’t shy away from easier options and use the h1 expression in the scraping settings.

If you get the report with empty tags or multiple tags on the pages, feel free to contact your SEO colleagues who work on this website to report an error on their side.
2.2. Description
It’s not only the title of the movie that matters, so the next step will be to scrape description. The chain of actions is similar to the previous – you find the right place on the page, hover over it, and right-click to inspect its code elements. The description is enclosed in the <div> tag, so you have to copy the squared value:
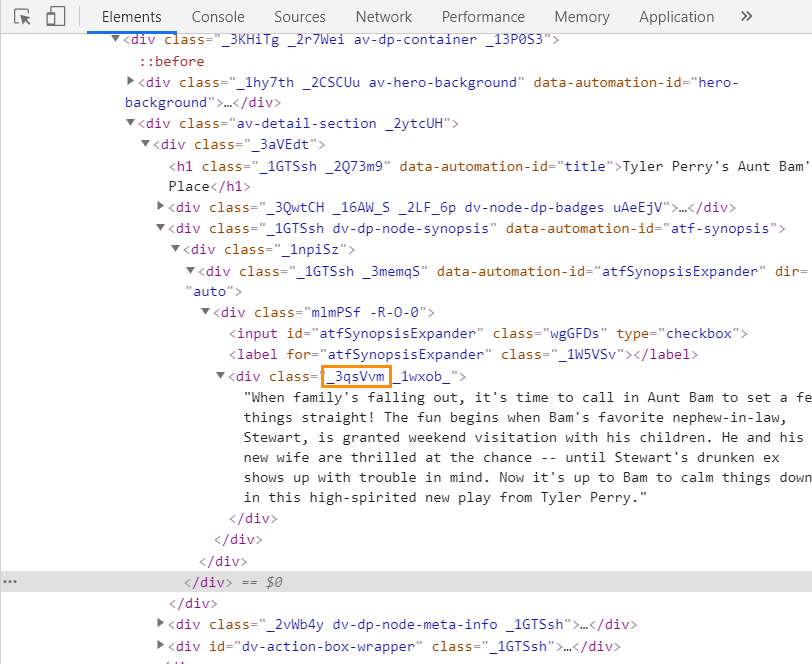
And again, use a dot to craft a working regexp:
2.3. Rating
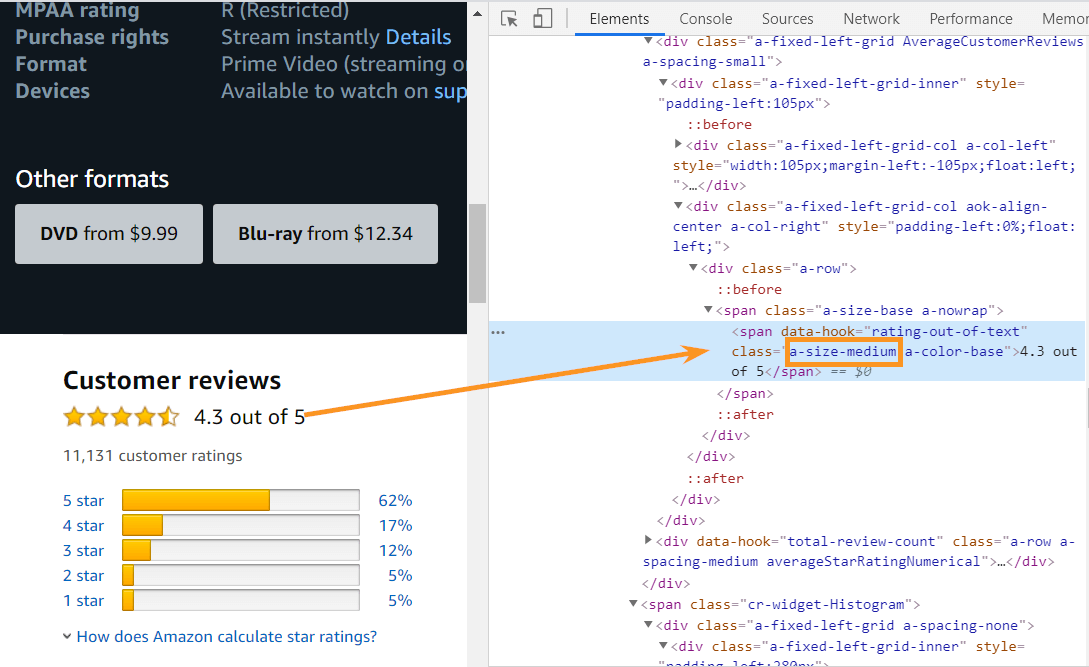
Some people treat this rating factor as real proof of watch-worthiness, so we’ll keep up with the Joneses and add this element to our comparison table. To copy the value that describes rating, find a rating box on the page, click and find the <span> tag, where this value is confined. Here's the selector in action that you need to copy paste into Netpeak Spider scraping settings:
2.4. Release Date
Let’s say you’re determined to watch French movies of the 60s. Or are you a 90s American comedy buff? Whoever you are, you can scrape the release dates to tailor your watch list to your particular needs.
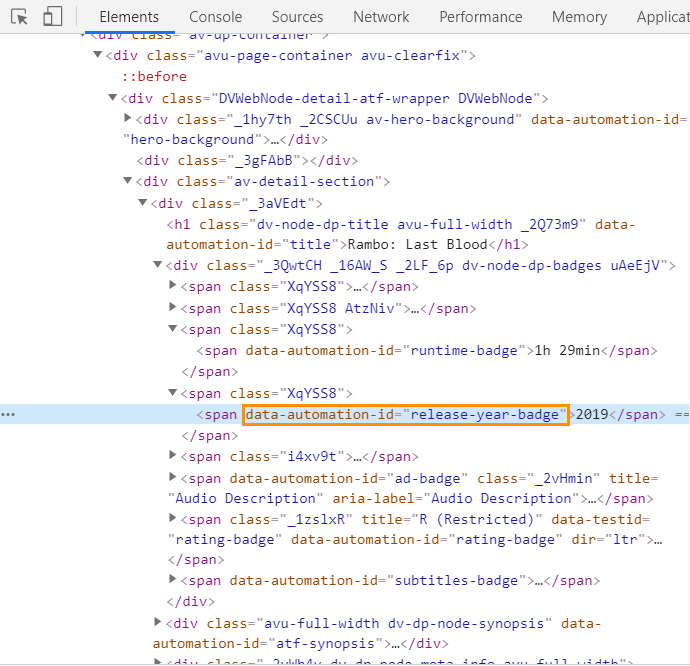
See, here is another <span> tag in the picture, which has a unique attribute – data-automation-id="release-year-badge”. We’re going to ingrain this attribute into the square brackets to find the characters that match only these characters:
2.5. Genre
This stage shouldn’t be ignored if you don’t like watching just random films and prefer to stick to a specific genre. It’s just a tad more complicated than with previous cases, and it requires additional fuss. But if you handle it, you’ll never be daunted by the size of the problem 😎
In this case, you have to work with a :nth-child() pseudo-class selector that allows you to select elements based on the source order inside its container. To assign a child to its parent, you have to specify an index value in the brackets, which will select a certain number from the list item. Let me clear this up with an example, which is better than any wordy explanation.
- With the same page open, inspect the code of the genre.
- Select the _1ONDJH class in the <div> tag.
- In the second row, copy dl.
- Then go for dd.
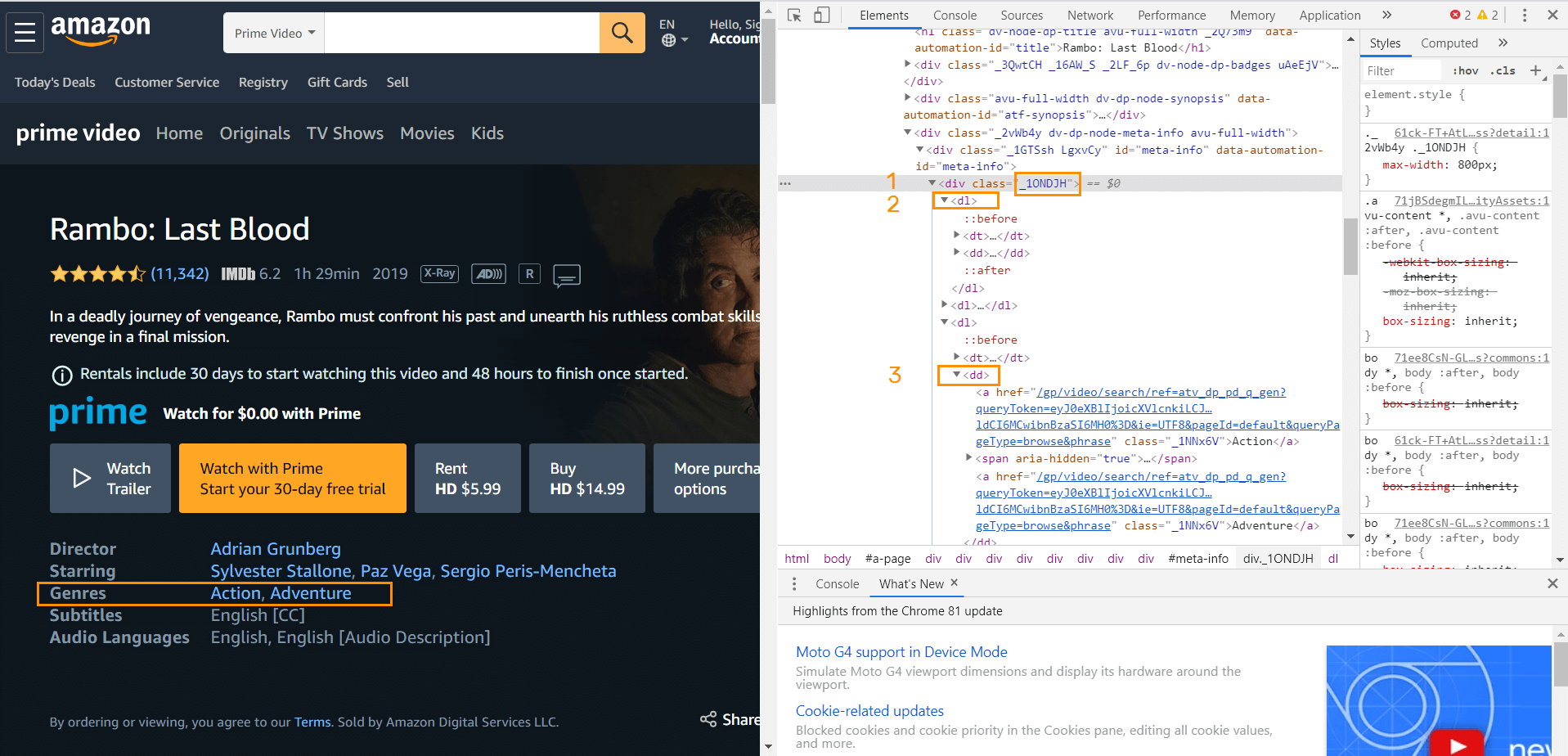
Sounds like a quest, doesn’t it? To scrape these dimensions, specify in the scraping settings mentioning the pseudo-class selector:
2.6. Image
As a true film buff you probably wrote film reviews once or twice in a lifetime. Movie banners can be handy in this respect.
Scraping images from a website is terribly easy. You just have to click on the movie banner and extract from the code src attribute value of <img> tag inside <div> with class value '_3fd5l'. Check it out:
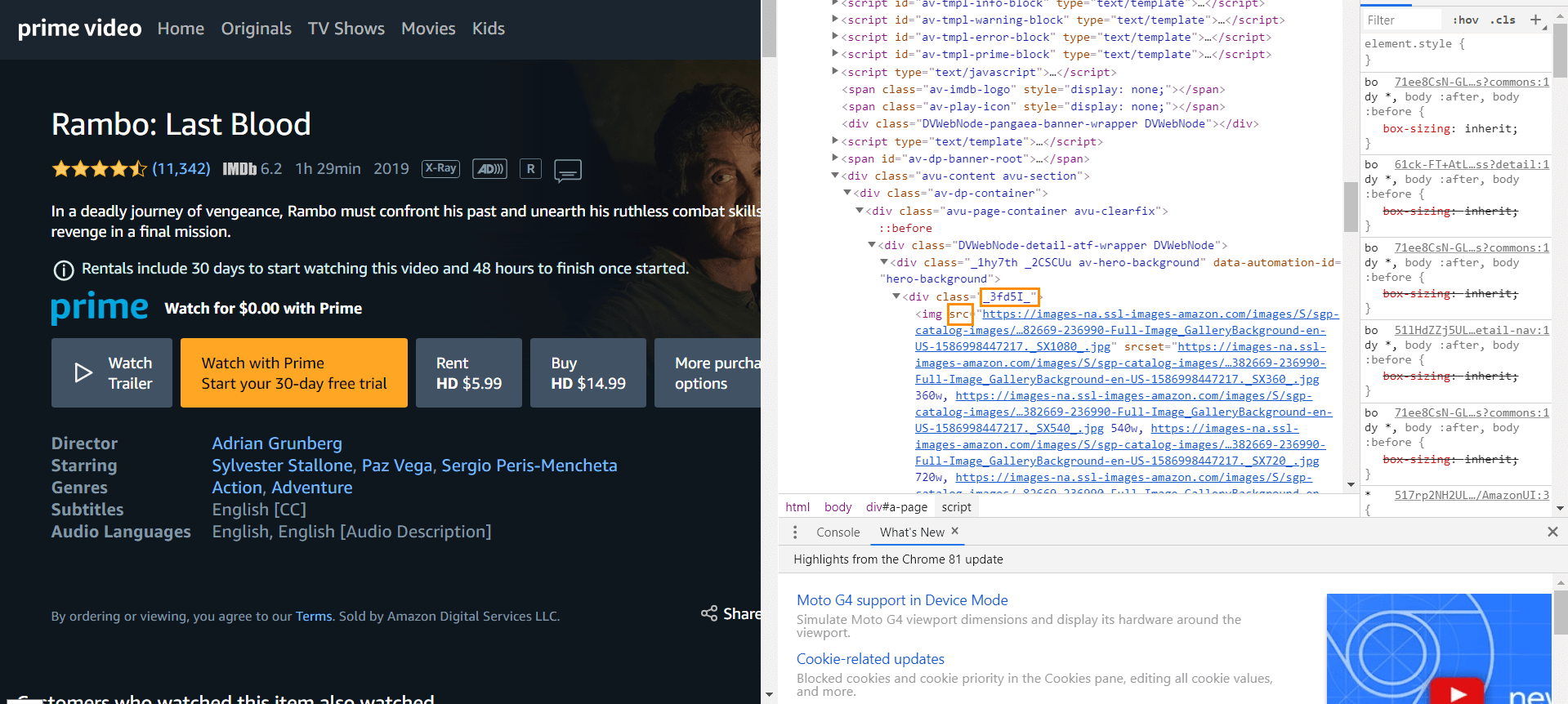
And here we go:
When you set data extraction type ‘Inner text’ for all values, for image extraction, you have to specify the ‘Attribute’ value, i.e. scr since it’s the place where a link to the image is located.
2.7. Runtime
It’s the case for those who don’t like watching movies that are longer than two hours.
So you know what to do now. Find a place on the page, mentioning the runtime, inspect its code, copy the data-automation-id="runtime-badge" value, and enclose it in brackets in scraping settings, like this:
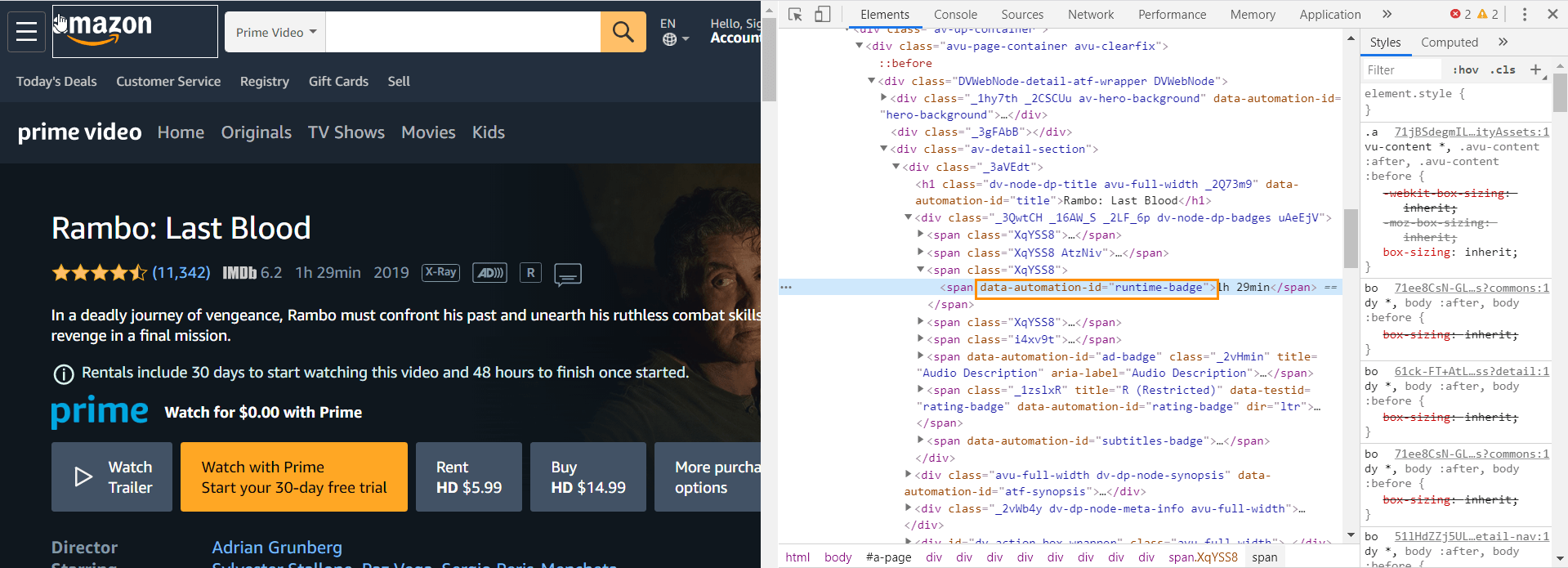
3. Connect the Dots in Netpeak Spider
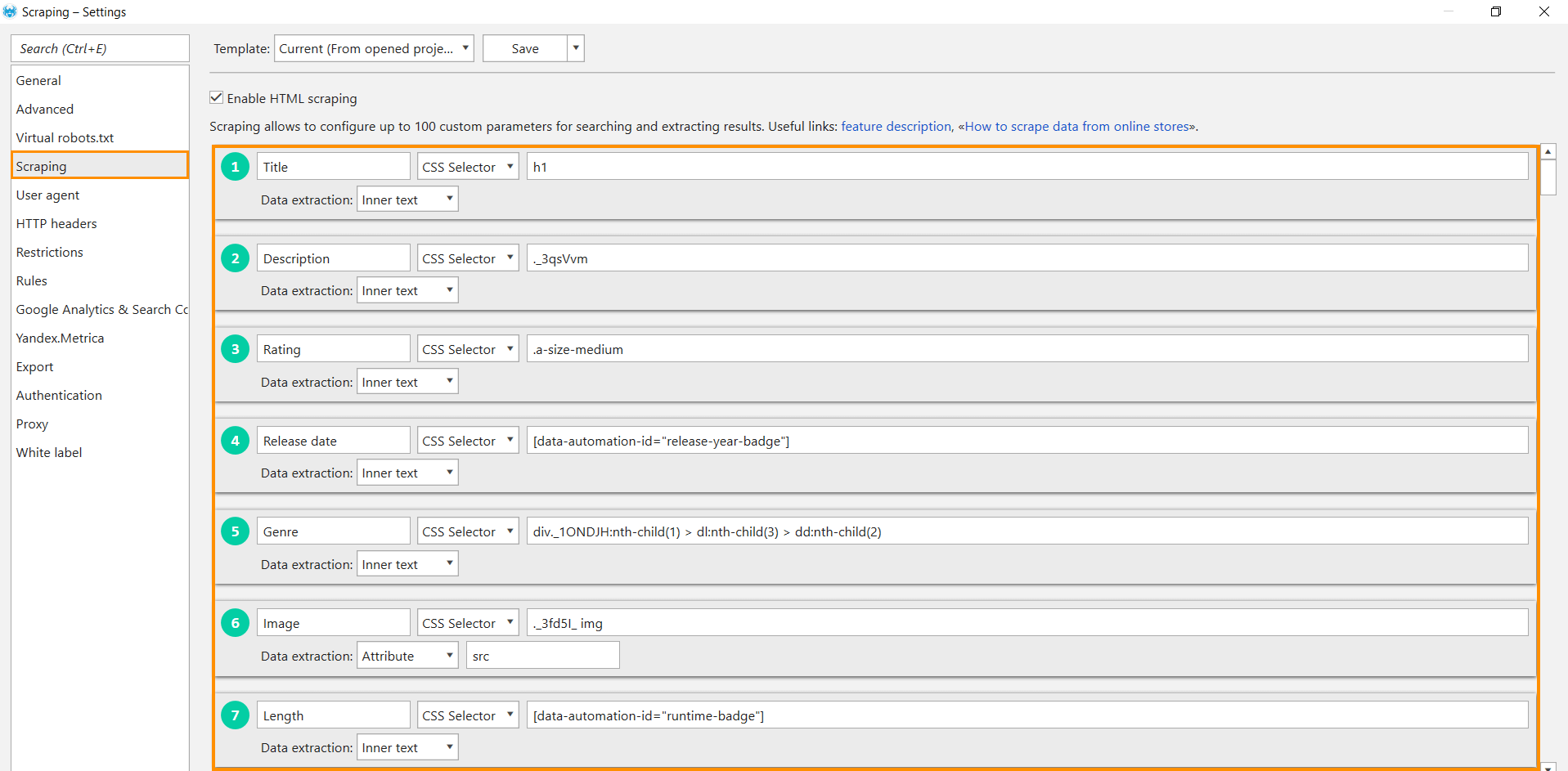
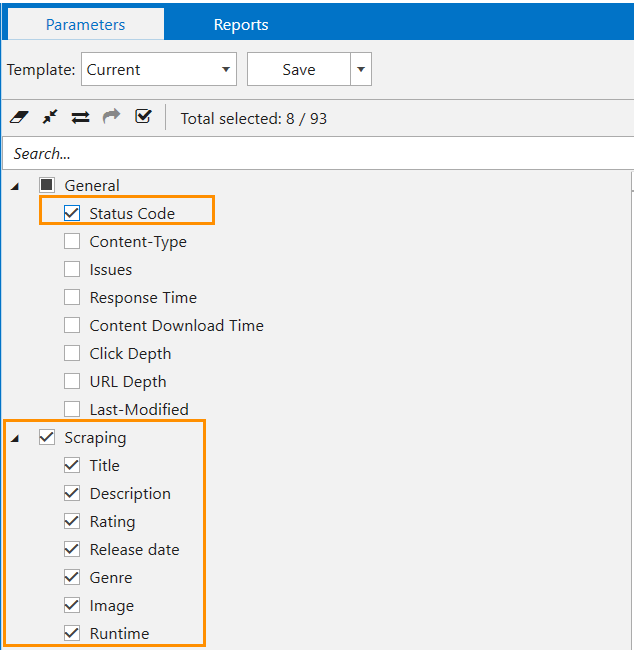
Now, when you found all the needed selectors, we will put these incidental findings in the right order. So open the tool, go to the settings, open the ‘Scraping’ tab, and set all conditions. Here’s what you should add:
- Set a search expression, each in a separate row.
- Title → h1
- Description → ._3qsVvm
- Rating → .a-size-medium
- Release Date → [data-automation-id="release-year-badge"]
- Genre → div._1ONDJH:nth-child(1) > dl:nth-child(3) > dd:nth-child(2)
- Image → ._3fd5I_ img
- Runtime → [data-automation-id="runtime-badge"]
- For all conditions, tick the ‘CSS selector’ search type.
- Choose what data you want to extract. For all conditions except ‘Image,’ select ‘Inner text’ → only text will be extracted, leaving HTML tags aside.
- For ‘Image,’ select ‘Attribute’ and specify what attribute you want to extract. In our case, it’s src – the place where the image dwells.
- Now back to the parameters in a sidebar. Since scraping works only for legit pages – pages that return 200 OK – tick the ‘Status Code’ parameter in the ‘General’ group.
- Scraping will be automatically ticked, including the names of conditions you set.
- Start crawling.
- When the crawling is completed, approach the ‘Scraping Overview’ in the ‘Database’ tab.
To Recap
So that’s how the scraping path looks like – with many twists and turns. It's yet another way to automate your work wisely and scrape any data from any website you want. Here’s the main takeaway:
- Determine what type of data you need and stick to the right search type.
- Copy items with unique values.
- For image scraping, select ‘Attribute’ and specify scr.
- Set the minimum crawling threads to prevent captchas or blocks (or use proxies).


