Regular Expressions for SEOs and Digital Marketers [with Use Cases]
How to
![Regular Expressions for SEOs and Digital Marketers [with Use Cases]](https://static.netpeaksoftware.com/media/en/image/blog/post/eb4962cf/900x300/regular-expressions-for-seos-and-digital-marketers.jpeg)
When I saw regular expressions for the first time, I thought 'this must be used by very experienced SEOs, so maybe it's not the best topic for a post since I'm not an experienced SEO or a developer'. But the time goes on and I've been seeing a lot of use cases for regexps for all kinds of marketing tasks including our scraping feature in Netpeak Spider. So let's dive into them and sort them out.
You can scrape website data even in the free version of Netpeak Spider crawler that is not limited by the term of use and the number of analyzed URLs. Other basic features are also available in the Freemium version of the program.
To get access to free Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
- What is regular expression and where it is used
- Regular expression syntax
- How to study regular expressions (with examples)
- Use cases
- Resources to continue studying
1. What Is Regular Expression and Where It Is Used
Regular expression is a set of characters used to search text strings that match required conditions. The result of applying a regular expression is a data range selected according to the logic you've applied to the expression. Regular expressions are used in any search tasks when it is necessary to obtain data according to certain rules.
Without an understanding of regular expressions, it's hard to imagine a filters customization and user segments in Google Analytics, or rules in GTM, or RewriteRule in .htaccess. Also, it's widely used by SEOs to solve different tasks. You'll see the examples a little further on.
2. Regular Expression Syntax
If you know how to use regexps, you can scroll this and the next part of this post and check out use cases.
Most characters in regular expressions represent themselves, except this special group:
[] \ / ^ $. | ? * + () {}
If these characters are used as text characters, you should escape them with a backslash '\'.
It means that regular expressions include some symbols to indicate different parts of the pattern. However, if you need to find one of these characters in a string, simply as a character, that's another case, and it can trip some specialists up. A dot '.', for example, in a regular expression stands for 'any character other than a line break'. If you need to find a dot in a string, you can't just use '.' If you do so, this will lead to finding just everything. So this dot should be considered as a common dot, not 'any symbol'. It can be done with escape character.
The escape character placed before dot makes crawler (parser, etc.) ignore its function and treat it as a common character: \.
There are several characters that require this kind of escaping in most templates and languages. If these special characters occur without a backslash, they have a special meaning in regular expressions:
^ – anchor. The beginning of the line
$ – anchor. The end of the line
. – any character except new line
* – any number of previous characters
+ – 1 or more characters
? – 0 or 1 of the characters
( ) – grouping of structures
| - OR operator
[ ] – any of the listed characters. If the first character in this construction is '^', it works the other way around – the symbol being checked should not coincide with what is listed in brackets
{} – repeat the symbol several times
\ – escape character
And vice versa there are special characters that must be escaped. Otherwise, they'll be considered common characters. For example, \n (means new line) or \t (tabulation). Use this cheat sheet so that you won't mix them up.
Quantifiers
Quantifiers in regular expressions allow you to define a part of a template that should be repeated several times in a row. The 'greedy' quantifier tries to capture the text as much as it can. A 'lazy' version (the modifier '?' is added) looks for the smallest possible piece of the text.
So here you can see that a greedy quantifier (*) captures everything from the first quotes to the last:
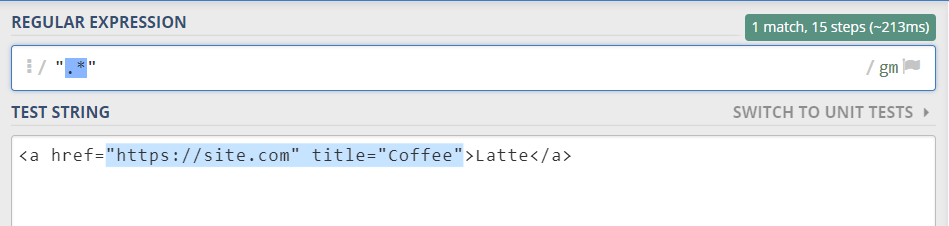
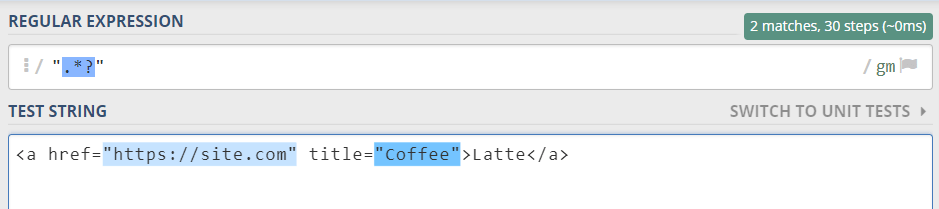
The lazy version of the quantifier (*?) searches for the smallest match, so it finds each substring separately:
3. How to Study Regular Expressions
Practice makes perfect, it's about regexps. The more you practice, the faster you start building necessary structures and solving tasks.
3.1. Study Regular Expressions in a Text Editor
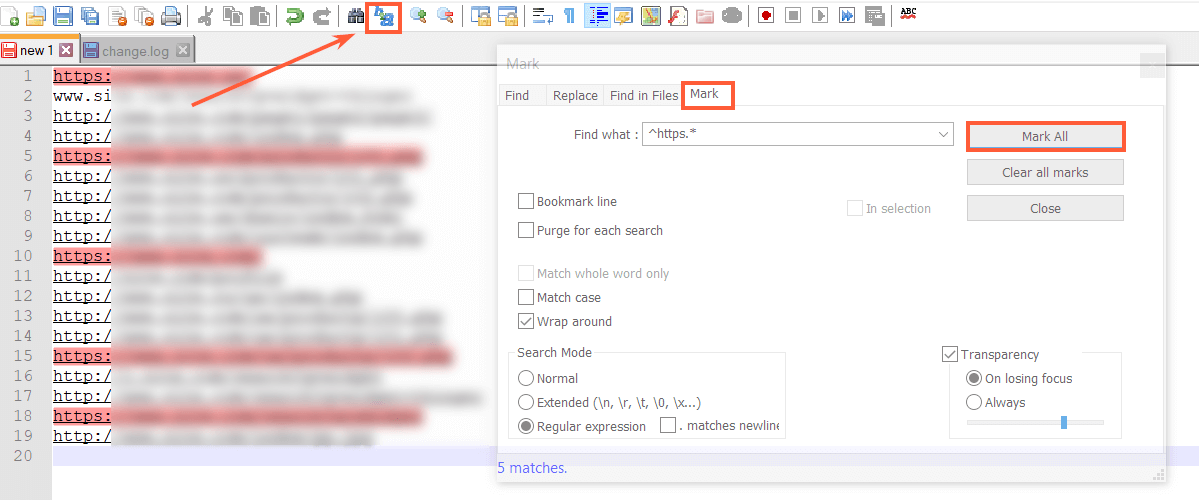
Almost all newcomers start practicing regexps in the text editor Notepad ++. Why? Because in most cases special characters do not need to be escaped, and Notepad ++ saves the constructions of previous queries.
Also, the 'Mark' tab shows search results in your data and allows you to make edits quickly:
3.2. Check Your Knowledge in Regex
Online service regex101.com allows you to enter a data set and a regular expression. After that, the needed data will be highlighted. Also, regular expression is explained piece by piece in a special 'Explanation' window.

3.3. Check Your Skills Using Google Analytics
The fastest way to test your knowledge about regular expressions in Google Analytics is to use filters in standard reports. Log into your account and try to select any data set in any report where filters are available.
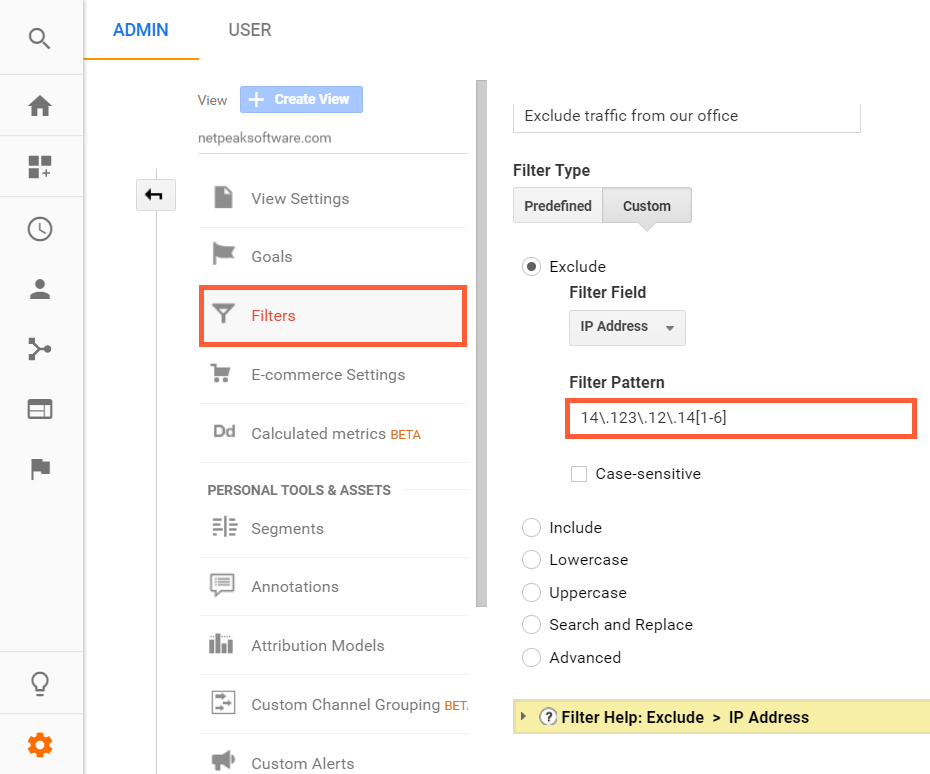
Here is an example of how to use regular expression to filter traffic from your office IP addresses.
Most likely, you know that you need to exclude traffic from your IP addresses using filters in Google Analytics. What for? Just to keep statistics about your audience clear.
Let's say, some project gets traffic from IP-addresses from 14.123.12.141 to 14.123.12.146. The regular expression to filter them will look as follows:
14\.123\.12\.14[1-6]
In this case, we've created a template for searching IP addresses that differ from each other only by the last number. All that's left to do is to transfer this expression to the filter field with appropriate settings.
And what if your IP addresses will differ not by one number, but by two? For example, you have to filter IP-addresses from 14.123.12.141 to 14.123.12.152. Then we need to set the logic for changing already two characters:
14\.123\.12\.1(4[1-9]|5[0-2])
So we've changed two last numbers and added one more symbol – round brackets. They are used for grouping elements.
If you remove the parentheses in this expression, special character | will influence the whole expression and it will correspond to the lines '50', '51', '52'. The parentheses in this case allow you to limit the scope of the last two characters leaving the preceding part unchanged for all the options that fit the expression.
To sum up this part I want to wish you good luck in studying and suggest some entertaining ways to hone your skills → crossword and regex golf ;)
4. Use Cases
Here you'll see a few other cases of using regular expressions and I hope you'll totally understand that regexps should not be underestimated.
4.1. Getting Rid of Some Depth Levels in URLs
As an example I'll describe the following case. You've scraped search results for some queries, copied top 15 results and now you want to get rid of the latest URL depth levels. You can highlight and then delete the last depth level using this regular expression:
/[^/]+/$
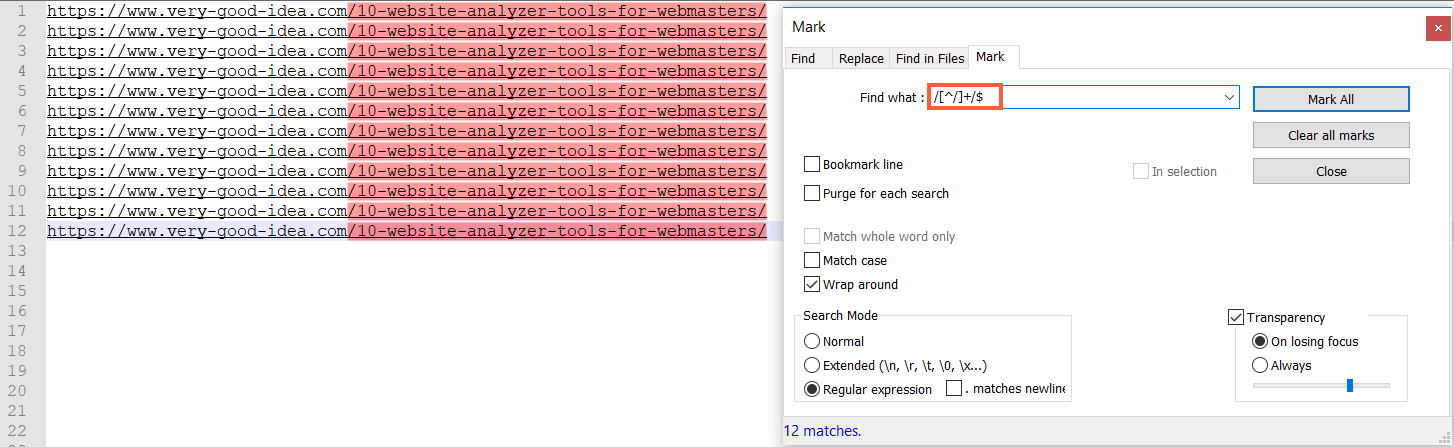
Or two last depth levels using this:
/[^/]+/[^/]+/$
4.2. Searching for Words with Peculiarities
Now let's check out examples of using regular expressions with the crawler (Netpeak Spider). So you can set scraping rules. The point is to find repeated pattern and compose appropriate regular expression.
For example, you want to find all words in text with one common letter, let it be 'q'.
\b\S*q\S*\b
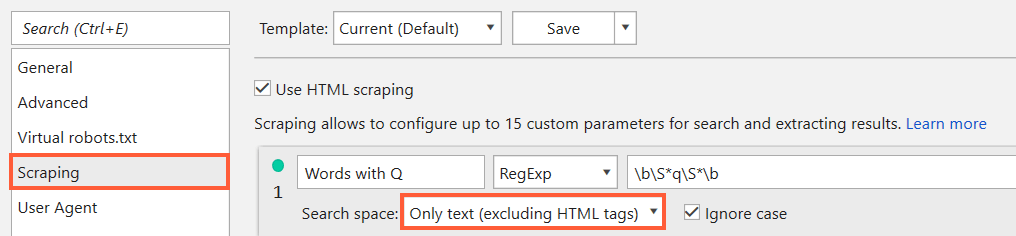
And here we are:
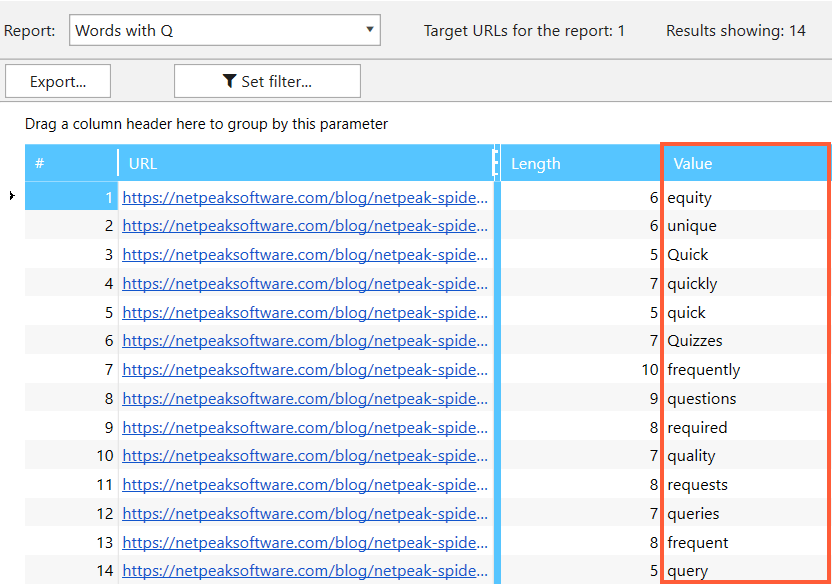
You can ask why I didn't use old faithful CTRL+F combination here. My answer is that it's much easier to find and upload all necessary words that correspond to the URLs as in the example.
4.3. Checking Webpages for Misspelled Words
The same logic can be implemented if you want to check your name after changing it. Or, for example, you want to check correctness of spelling your company name.
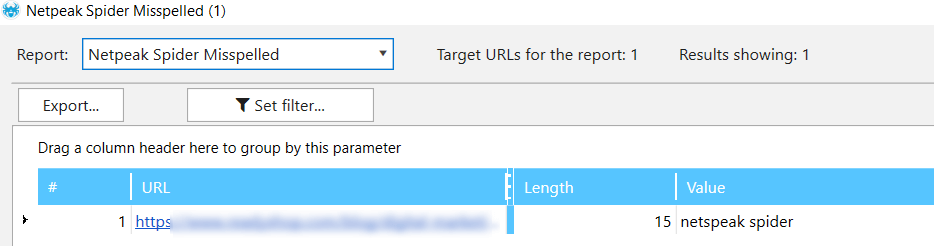
Also, it's quite easy to find some frequently misspelled words. For example, name of our crawler is Netpeak Spider but we often stumble upon different misspelled variations such as netspeak spider, netpic spider, netpac spider, neatpeak spider, netpeack spider. Let's suppose that we have URLs with mentions of our tool and we want to check if crawler's name is spelled correctly.
(?i)netspeak spider|netpic spider|netpac spider|neatpeak spider|netpeack spider
Using this regular expression, we can identify all incorrect names: 'netspeak spider', 'netpic spider', 'netpac spider', 'neatpeak spider', 'netpeack spider':
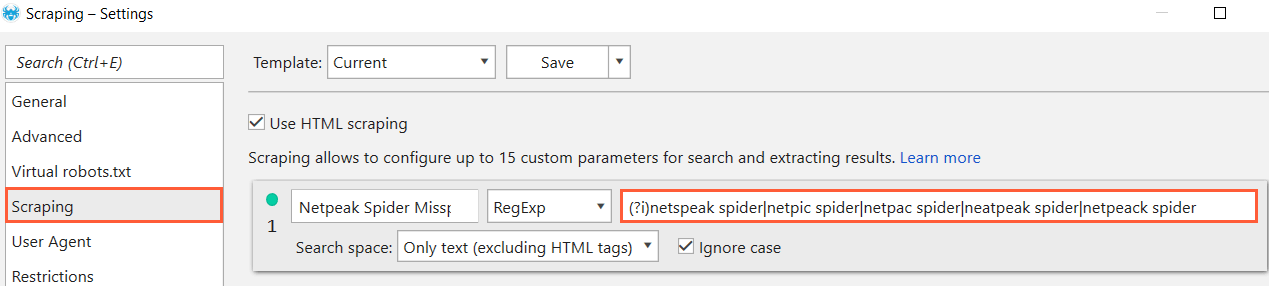
So as you can see, I've found one :(
4.4. Searching for Nofollow Links to Your Website
Let's suppose that you have the list of URLs with mentions of your company. Or you run link audit of your website and want to know if there are nofollow links to your website. You can check it using the following regular expression or using segmentation in Netpeak Spider (I'll describe this in our next posts).
<a.{0,100}href=.{0,100}?yourwebsite\.com(.{0,100}?)(nofollow)
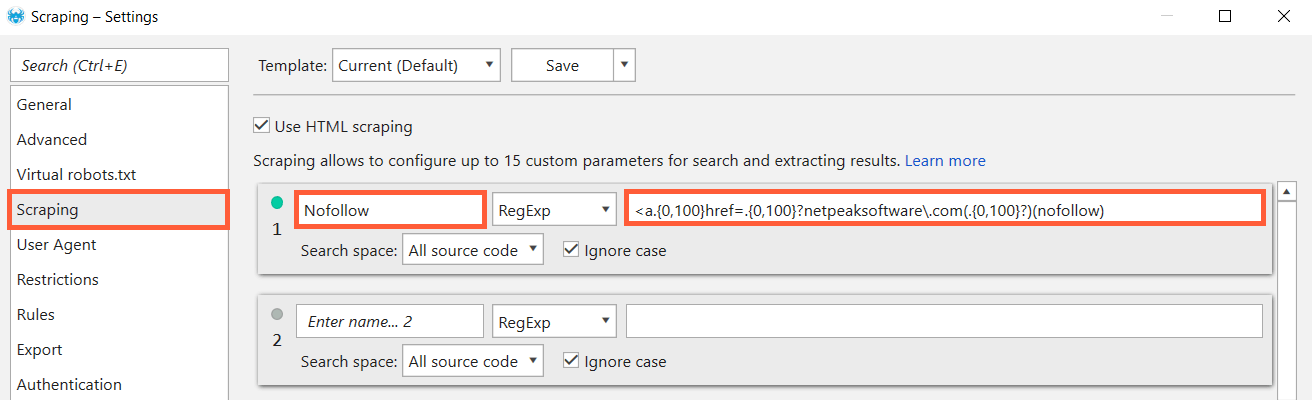
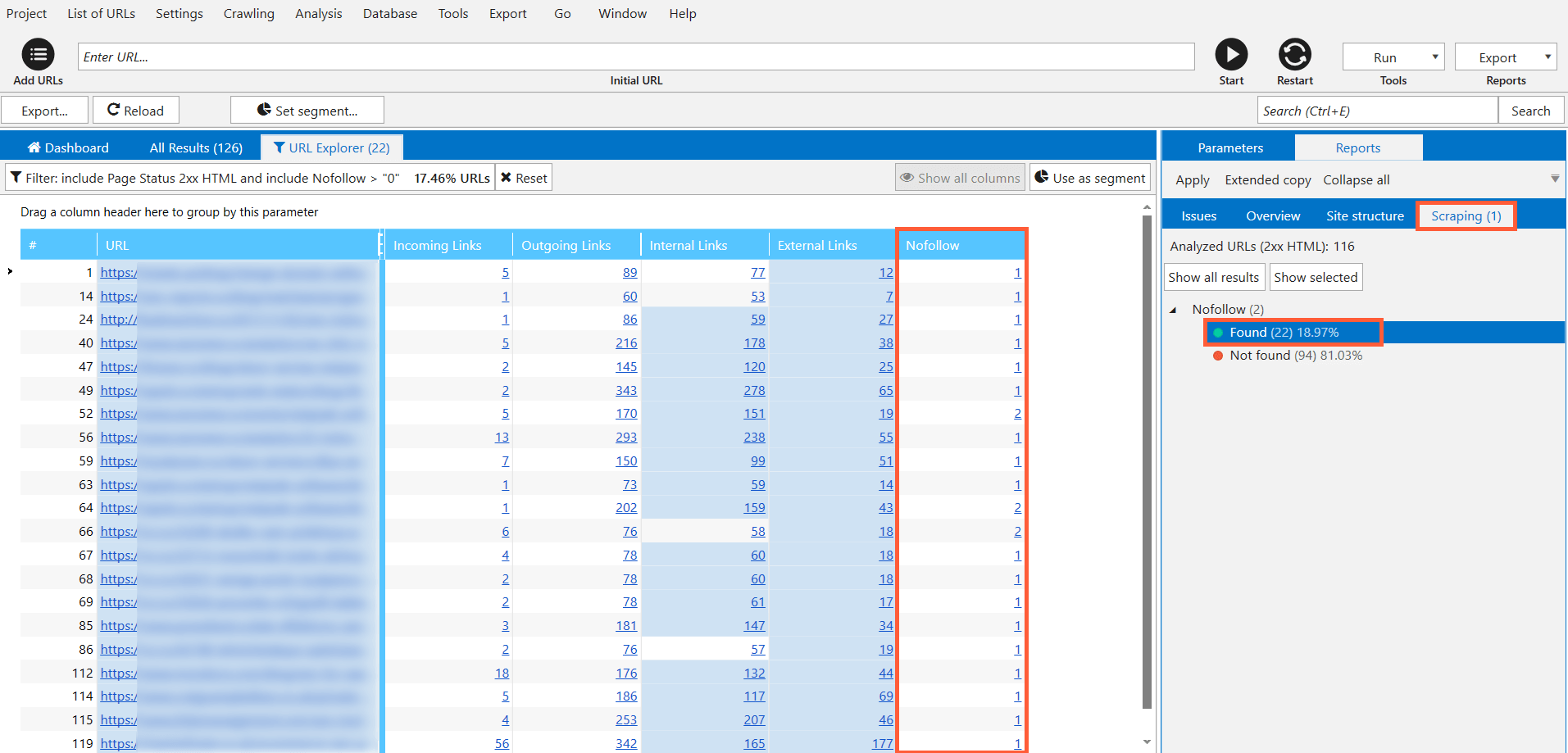
Keep in mind that {0,100} means any amount from 0 to 100 characters can appear.
4.5. Scraping Email Addresses
This use case is trite but very useful. If you need to find email contacts from a bunch of websites, use the following regular expression and just scrape them as you've seen in cases above. All data with @ character in the middle and at least a single period in the second half of the string will be found:
[a-zA-Z0-9-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+
In a Nutshell
Regular expressions can make your life easier. Moreover, they are to be used if you are working with Google Analytics, GTM or even Google Sheets. You can study them using common text editors or online service regexp101. They can be very handy in such cases as scraping emails, looking for nofollow links, misspelled words, deleting URL depth levels or setting filters in GA.
Share your own use cases with regular expressions in comments below and ask questions, we'll gladly answer ;)


