Comprehensive Guide: How to Scrape Data from Online Stores With a Crawler
Use Cases

Read more → Web scraping for marketing
To scrape data we always use special expressions. They allow the program to find a particular type of data and then to extract it. Depending on the task, the following patterns are used:
- CSS selectors help to choose the needed markup elements.
- XPath expressions help to extract the tag content or attribute at its address in the source code of an HTML page.
- Regexp (or regular expressions) is an object that describes a pattern of characters. It determines what type of string you want to find on the page.
Scraping with CSS selectors is the most convenient and simple way to extract data. You can solve almost 95% of your scraping tasks using them. That’s why I’ll describe you how to use them in the crawler and show you a use case with a bunch of different hacks.
To get access to Netpeak Spider, you just need to sign up, download and launch the program 😉
Sign Up and Download Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
1. Web Scraping from Online Store: How to Select Elements and Write Expressions for Scraping
To extract an element, it is necessary to find something that uniquely defines it. If you simply specify the tag name you want to scrape, you’ll get a lot of garbage with the desired value. It happens because the tag can occur too often in the code and each one will most likely contain different information. So it’s preferable to specify tags attributes, often the class, id or itemprop attributes (markup), because in most cases, their values are unique within the page.
To scrape the element using its attribute, you need to specify this attribute in square brackets:
If it’s not enough to specify an attribute, you can specify it by the value in it:
With exact match
Contains
Begins with
Ends with
Let's look at the example to make everything clear. One of the tasks where you need to apply scraping is comparing the products characteristics with competitors'. In this case, it is convenient to export the necessary info about all available competitor products from a specific section of the site into a table and scraping is a good way to automate this process.
Follow these steps:
- Open any product page.
- Highlight the element you need to extract and inspect it in the source code.
- Find its ‘peculiarity’ and write the corresponding expression.
I’ve decided to scrape iPhone characteristics to illustrate the process.
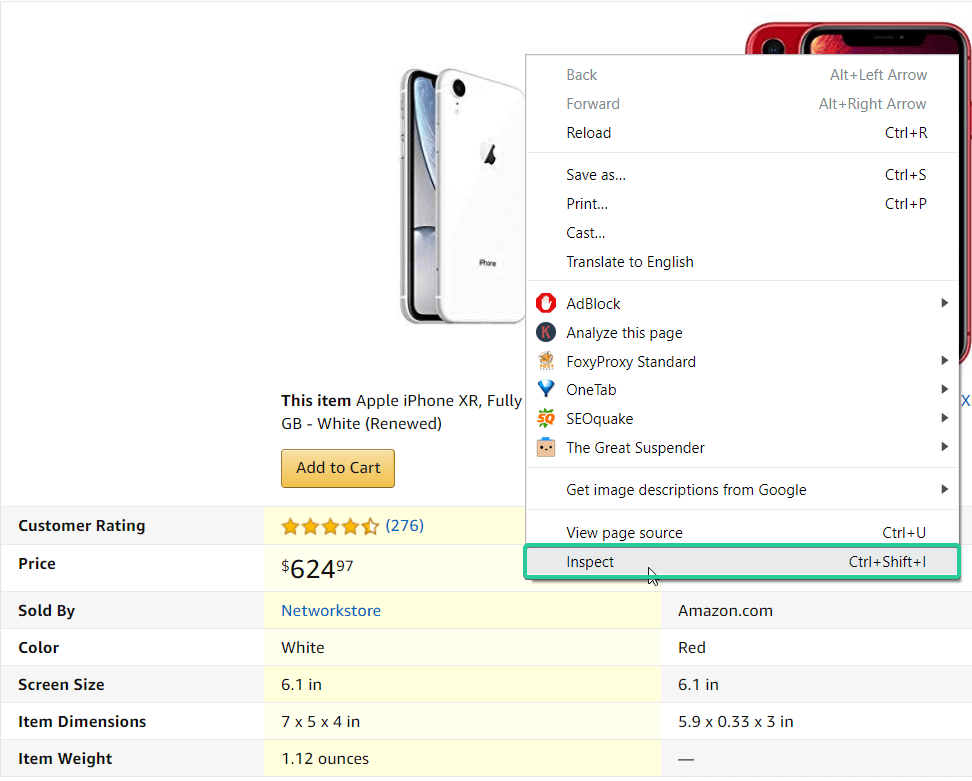
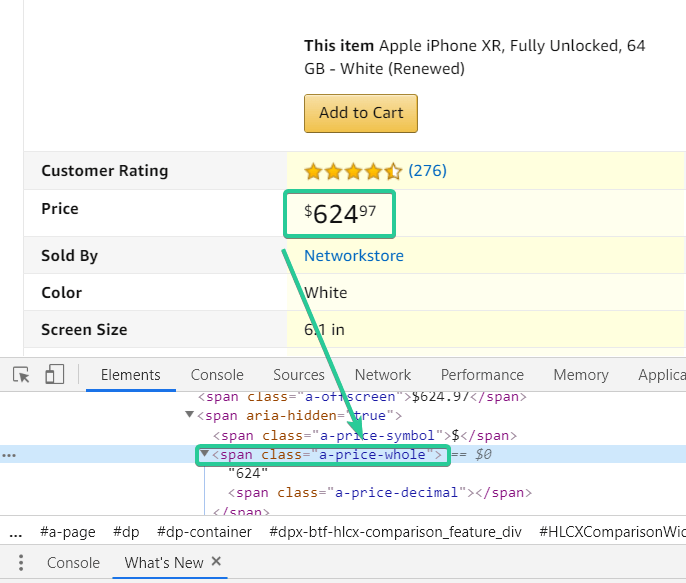
The price is enclosed in a <span> tag, but it doesn’t have any distinguishing feature, so it doesn’t fit. But it is easy to notice that it is enclosed in another <span> tag, which has a unique class – a-price-whole. We can use it. You can search by the value of the class tag in two ways:
For classics lovers:
For pros:
Just the price is not enough. So we need to scrape the product title, a link to the photo and some characteristics. Fortunately, the name scraping is the simplest thing that can be. In most cases, it is contained in the <h1> tag, and it is always used once in the source code. So just specify the tag name without specifying attributes and other things.
Meanwhile, photo link and characteristics can give you the run-around.
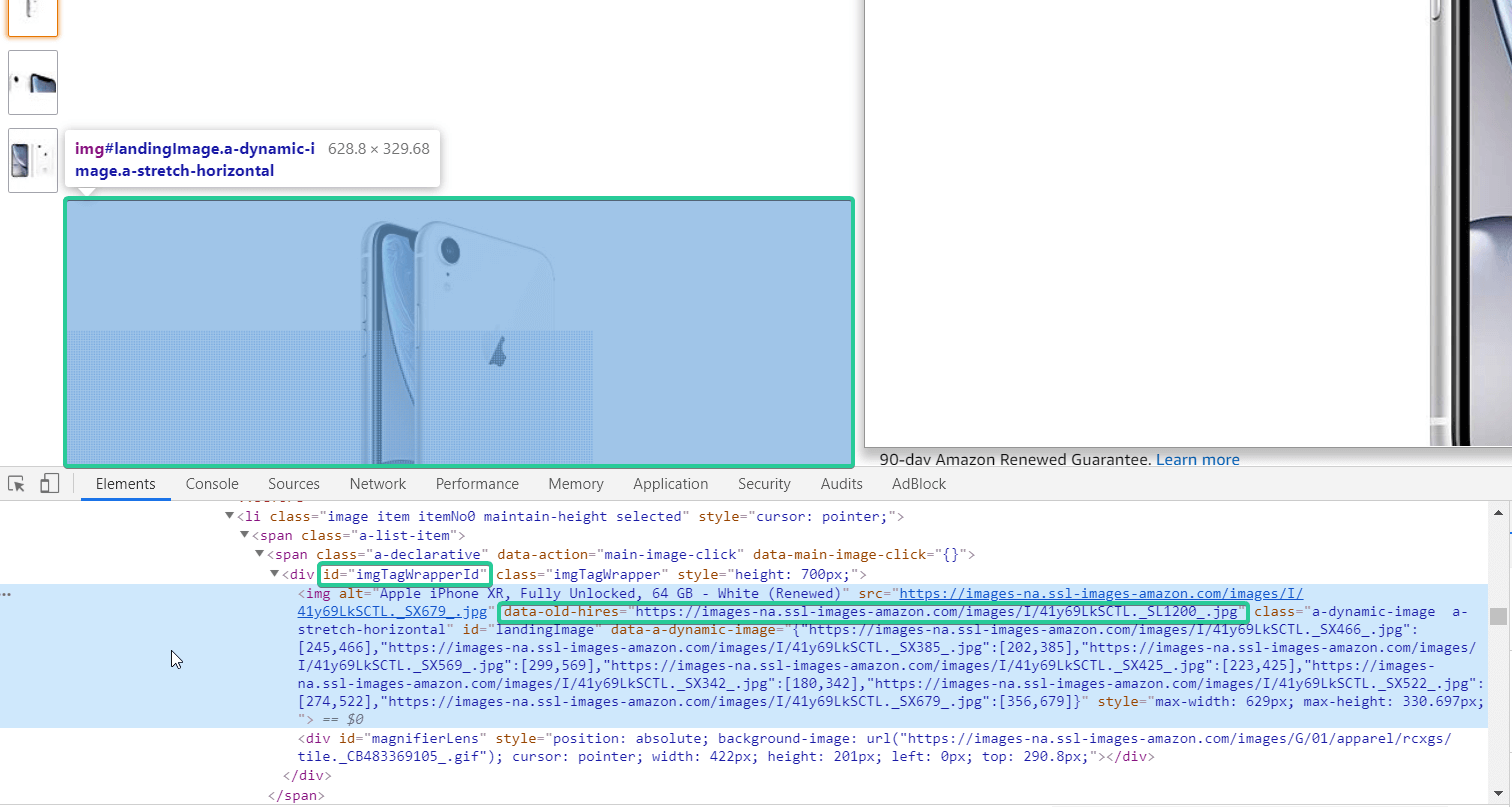
In this case, you can use the value of the class, itemprop or id attribute, since they are unique. In the example above, we found a unique id for the image. There is one peculiarity – you do not need to scrape the internal text, but the value of the src attribute, because it contains the needed link. Here is the necessary expression → [id="imgTagWrapperId"]>img
So now we know how to scrape a photo link, time to extract characteristics. We don’t need to scrape all characteristics. For example, I need product dimensions, item weight, and shipping weight.
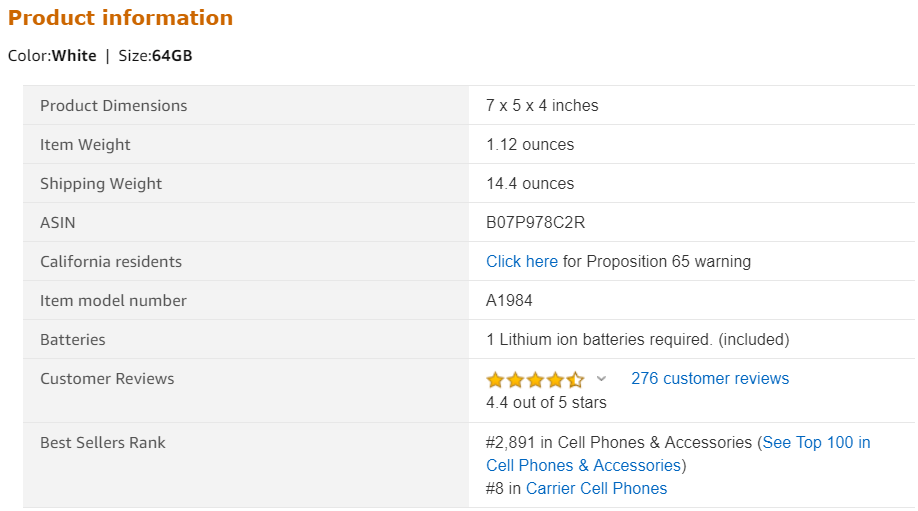
You see that they are placed into the table. There are many options for how to scrape values from a table. However, the problem is that all the values in the table will be extracted, including those that I do not need. It happens because the elements in the table have the same markup and the same values in the class attribute. So what to do? This is where XPath expressions come to the rescue!
Now we need them because they allow to set the element number. So to scrape the product dimensions, item weight, and shipping weight, it is necessary to specify the following expressions:
Product dimensions
Item weight
Shipping weight
Notice that only the sequence number of the row in the table is changed. In most cases, the XPath expression for scraping values from the table remains unchanged:
where:
- attribute – any attribute in the <table> tag
- attributeValue – attribute value that helps to identify the table
- i – number of the row in the table
- j – column number in the table
Read more → Web scraping examples
2. Web Scraping With a Crawler
So we wrote all expressions for scraping. Let’s add them to the crawler (in our case it’s Netpeak Spider) and start scraping. Open the program, go to the settings, open the ‘Scraping’ tab and set the selected conditions:
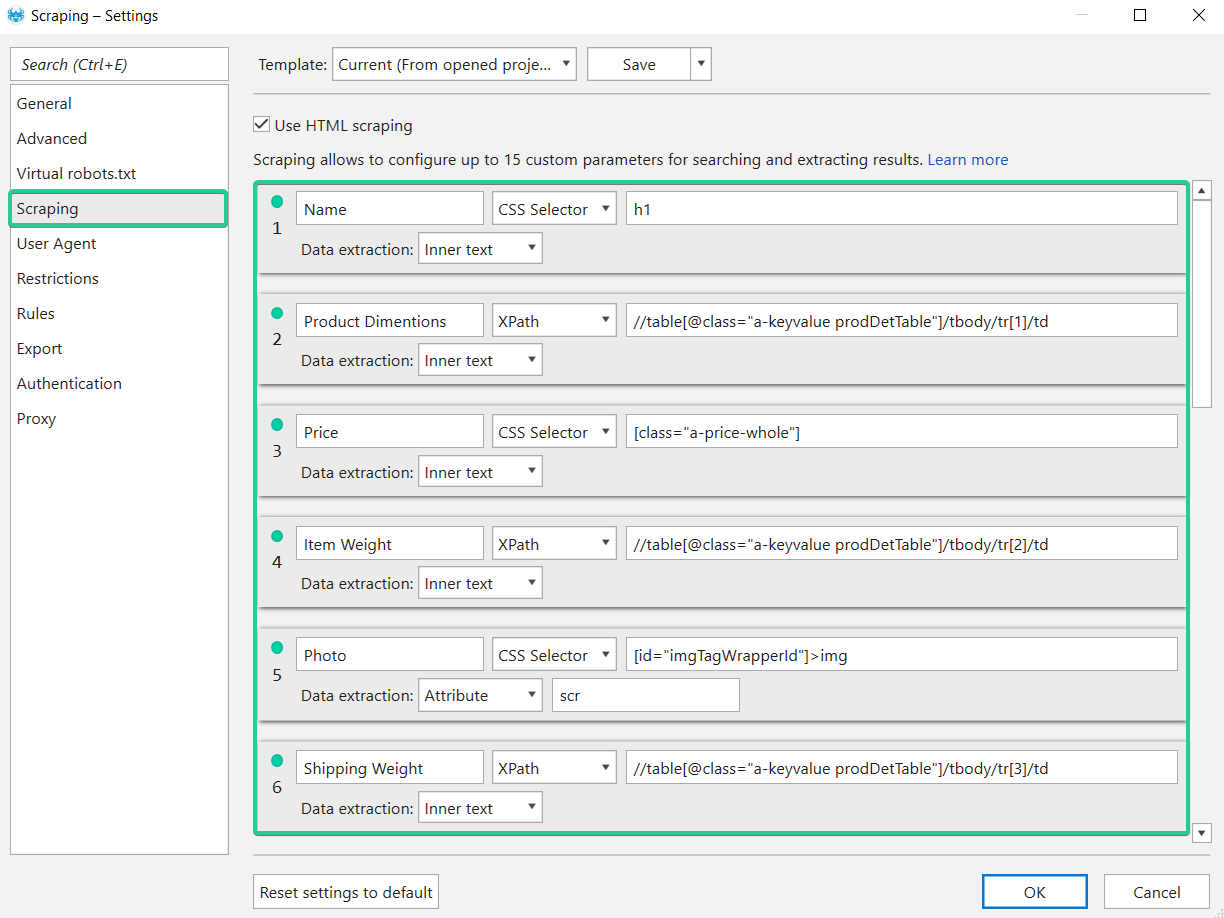
Now let's check if they work (spoiler: they will).
Before starting the scraping, I want to share a hack
The program, by default, analyzes a lot of On-Page parameters, because they are necessary for SEO-audit. But they aren’t necessary for scraping. So you can enable only ‘Scraping’ and ‘Status code’ parameters and disable the rest.
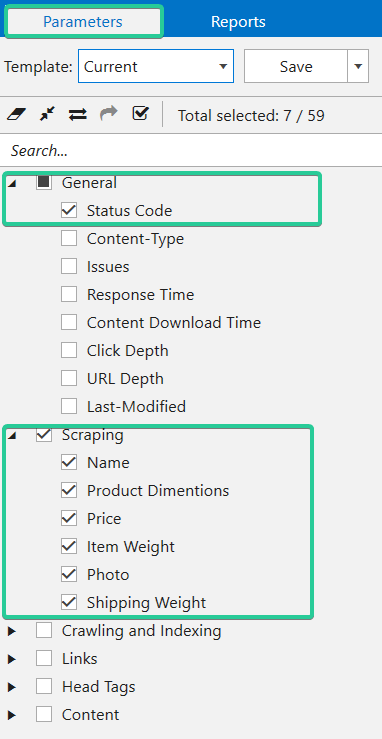
Once the crawling is completed, the main table will show the values indicating the data found.
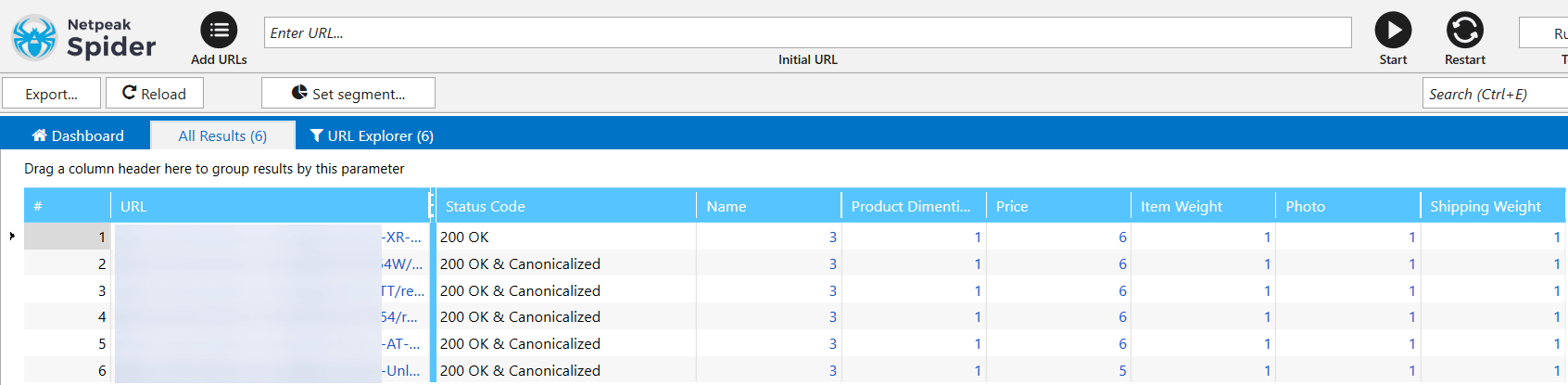
When you click on a number, you’ll see all corresponding results. A full scraping report can be opened in several ways:
- Open ‘Database’ → ‘Scraping overview’
- Open ‘Scraping’ tab on the ‘Reports’ tab on the sidebar
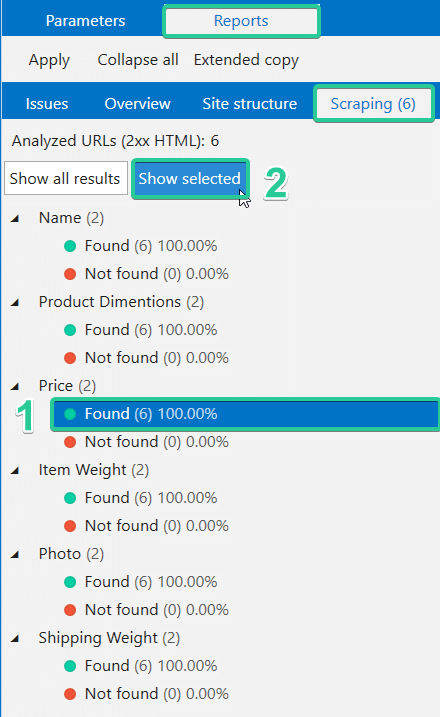
Moreover, you can quickly filter obtained data. Let’s imagine that after scraping prices, there were 291 pages containing the price, and 197 pages that did not contain the price. So the scraping report will contain many empty cells in the ‘Price’ column and it can distract you. However, if you select a group of pages containing a price and apply it as a segment, the program excludes all pages without prices and displays a report only for the selected group.
3. FAQ
In this section, I gathered all frequently asked questions about scraping from our users.
I. All scraping settings are set correctly but data isn’t extracted. Why?
1. Server response code is not 200 OK. Data will not be extracted if the page returned not 200 OK server response code, but for example 503. So it is recommended to keep ‘Status Code’ parameter enabled.
2. The source code that is passed to the program is different from the source code in the browser.
The User Agent can be the reason. For example, it is obvious that the page layout for the desktop browser Google Chrome and mobile Safari will be different.
Solution: change the User Agent in the settings or open the source code in the ‘Analysis of the source code and HTTP headers’ tool (this will allow you to see how Netpeak Spider sees the source code of the page).
Note: sometimes, in the source code the necessary data may not be found. This may happen because the site uses JavaScript to display part of its content. By default, JS rendering is disabled in the program. You can enable it in the settings, on the ‘General’ tab.
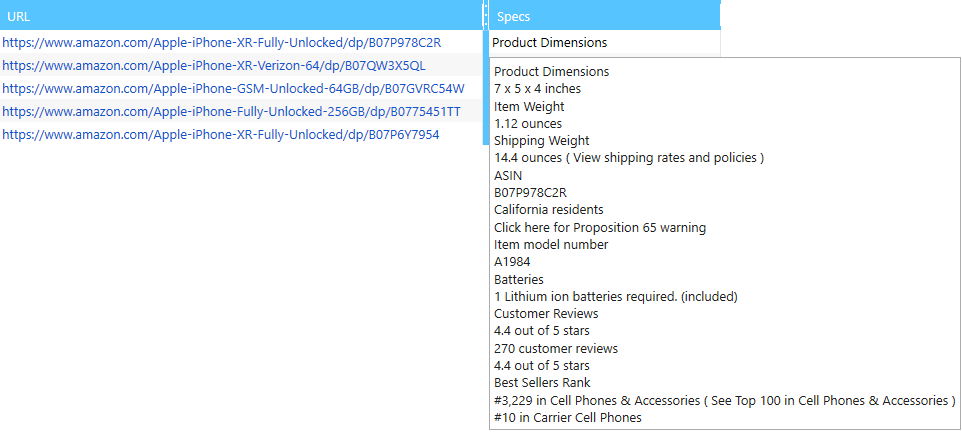
II. Data is stuck together in the report
This happens when you scrape an element that contains other HTML elements. For example, if you scrape the entire row in the table, i.e. <tr> tag, as we know, this element contains several <td> tags and all the data contained in these tags will be extracted into one cell of the result table and stuck together.
Solution: this is where MS Excel comes in handy. In fact, a line break character is written between the values and you can divide the values using it and transfer them into separate columns.
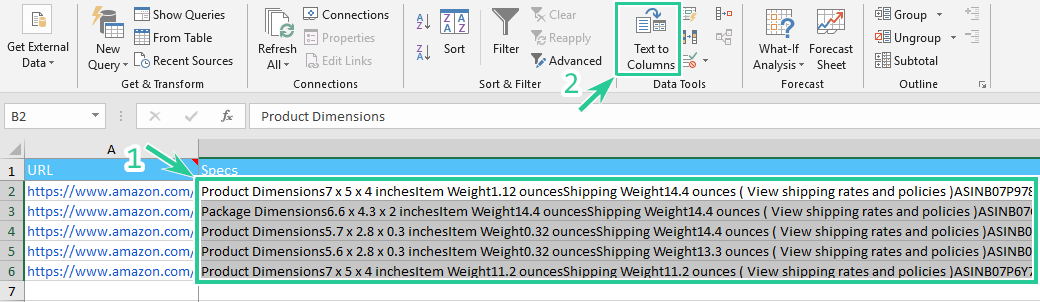
Step 1. Select the column with data and click on the ‘Text to Columns‘ on the ‘Data‘ tab.
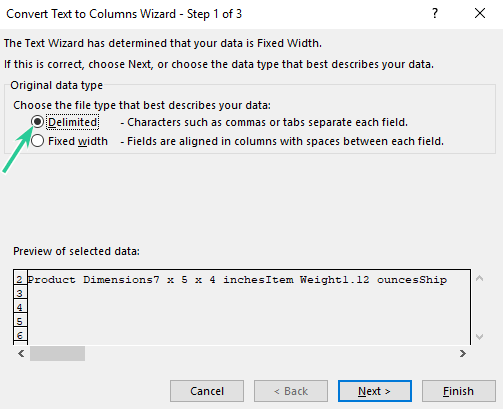
Step 2.
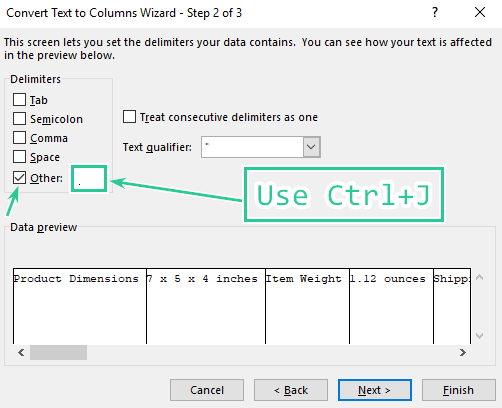
Step 3.
Step 4. Click on the ‘Next‘ and ‘Finish‘.
Step 5. Name columns correspondingly and delete unnecessary data. Enjoy the results :)

Bottom Line
At the end I want to highlight that you can scrape some sites using desktop crawlers, and some only using SAAS solutions or your own scripts. Because people increasingly protect their data and pay more attention to information security. That’s why Captcha checks from ‘Cloudflare’ or other services that provide this become popular. If you encounter too many captchas or blocks, you can try using proxies. We recommend this list of web scraping proxies by Proxyway. Just remember to always scrape responsibly so you don't damage the online store.
The bottom line is that the scraper and any script is much faster than human click. So sites can begin to block your activity, based on the fact that you take too much traffic. They suspect that you are a bot, so they offer to get captcha – this is the first option. The second option is a password protection. And another option is the text that is loaded using JavaScript, some programs can’t get it. Keep it in mind while scraping the needed information and set the crawler wisely (for example, set the minimum crawling threads).
Hope that my guide was useful for you. I’ll appreciate upvotes and shares. If you have any questions feel free to ask them in the comments below or sign up for webinar ;)
Digging This Use Case? Let's Discuss Netpeak Spider Perks in Person



