Как парсить различные данные из интернет-магазина с помощью Netpeak Spider
Кейсы

Парсинг сайта — это извлечение текстовых данных с HTML-страниц. К сожалению, не всегда понятно, как правильно парсить данные с сайтов, и что делать в тех или иных ситуациях. Этот пост наглядно продемонстрирует различные аспекты, которые вам надо учесть для парсинга сайтов. Я отвечу на часто задаваемые вопросы и поделюсь лайфхаками.
1. Типы специальных выражений для парсинга
Для парсинга сайтов применяются специальные выражения. Они позволяют программе искать тот или иной тип данных для извлечения. В зависимости от сложности задачи применяют такие паттерны:
- CSS-селекторы — паттерны, позволяющие выбрать нужные элементы разметки, как правило, для их последующей стилизации (но не в случае с парсингом).
- XPath — специальный язык запросов, с помощью которого можно извлечь содержимое какого-либо тега или атрибута по его адресу в исходном коде HTML-страницы.
- Regexp — язык, с помощью которого задаётся последовательность символов (паттерн), которая определяет, какой тип строки необходимо искать на странице.
Парсинг с помощью CSS-селекторов — самый простой и наиболее удобный метод парсинга. С их помощью можно решить примерно 95% всех задач, связанных с парсингом данных. Я вкратце расскажу о том, как их использовать.
2. Как искать элементы и подбирать специальные выражения для парсинга сайтов
Чтобы найти какой-либо элемент при парсинге, необходимо указать в настройках свойство, которое однозначно его определяет. Если просто указать название тега, который требуется парсить, то помимо искомого значения вы получите много мусора, так как в коде тег может встречаться слишком часто, и каждый экземпляр, скорее всего, будет содержать разную информацию.
В качестве особенности выступают атрибуты тегов, чаще всего — атрибуты class, id или itemprop (микроразметка), так как в большинстве случаев их значения уникальны в пределах страницы.
Чтобы парсить элемент по его атрибуту, достаточно указать этот атрибут в квадратных скобках:
Если просто наличия атрибута недостаточно, то можно указать поиск по значению внутри него:
С точным соответствиемНапример, если необходимо извлечь элемент с уникальным значением «product_price» в атрибуте class, то необходимо использовать следующее условие:
Содержит
В случае, когда значение атрибута слишком длинное, но в нём есть какое-либо уникальное выражение или слово, например «flower», то можно использовать такое условие:
Начинается на
Если же выражение присутствует вначале, то можно использовать условие, которое будет искать необходимый элемент по выражению вначале значения атрибута. Например, необходимо найти и извлечь все ссылки с протоколом HTTP:
Заканчивается на
А это условие будет искать элемент по выражению в конце значения атрибута. Предположим, необходимо найти все ссылки на странице, заканчивающиеся на .html, используем следующее условие:
Теперь перейдём к примерам.
Одна из задач, где выручает парсинг — сравнение характеристик товаров на вашем сайте и сайтах конкурентов. В этом случае удобно выгрузить все имеющиеся товары конкурента из определённого раздела сайта в таблицу.
Алгоритм подбора паттерна для парсинга следующий:
- Откройте любую карточку товара.
- Выделите элемент, который требуется извлечь и найдите его в исходном коде.
- Найдите его «особенность» и составьте соответствующее выражение.
В качестве примера я решил парсить характеристики велосипедов.
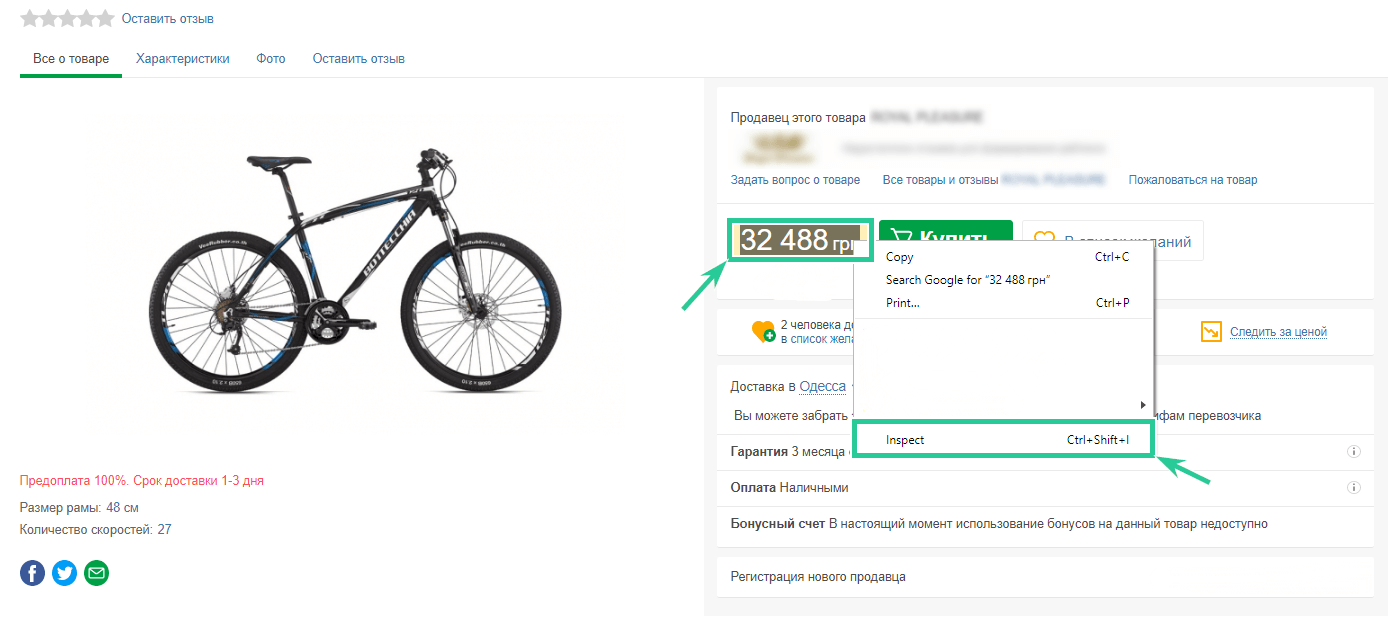
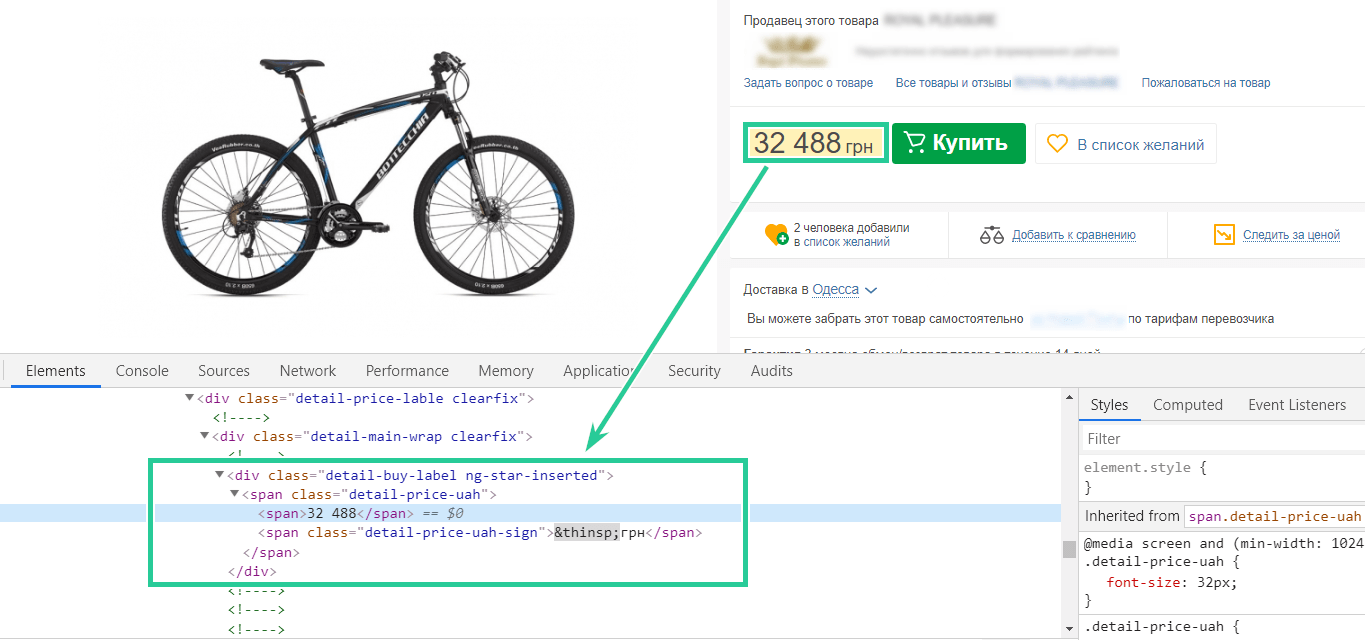
Цена указана в теге <span>, но у него нет какой-либо отличительной особенности, поэтому он не подходит. Но мы видим, что он заключён внутри другого тега <span>, который имеет уникальный класс — detail-price-uah. Его значение как раз и будем использовать. Задать поиск по значению тега class можно двумя способами:
Для любителей классики:
Для профи:
Только одной цены недостаточно. Необходимо также извлечь название товара, ссылку на фото и некоторые характеристики. К счастью, парсинг названия — это самое простое, что может быть. Зачастую оно содержится в теге <h1>, и его принято использовать один раз в исходном коде, так что достаточно просто указать название тега без указаний атрибутов и прочего.
А вот со ссылкой на фото и характеристиками порой нужно повозиться.
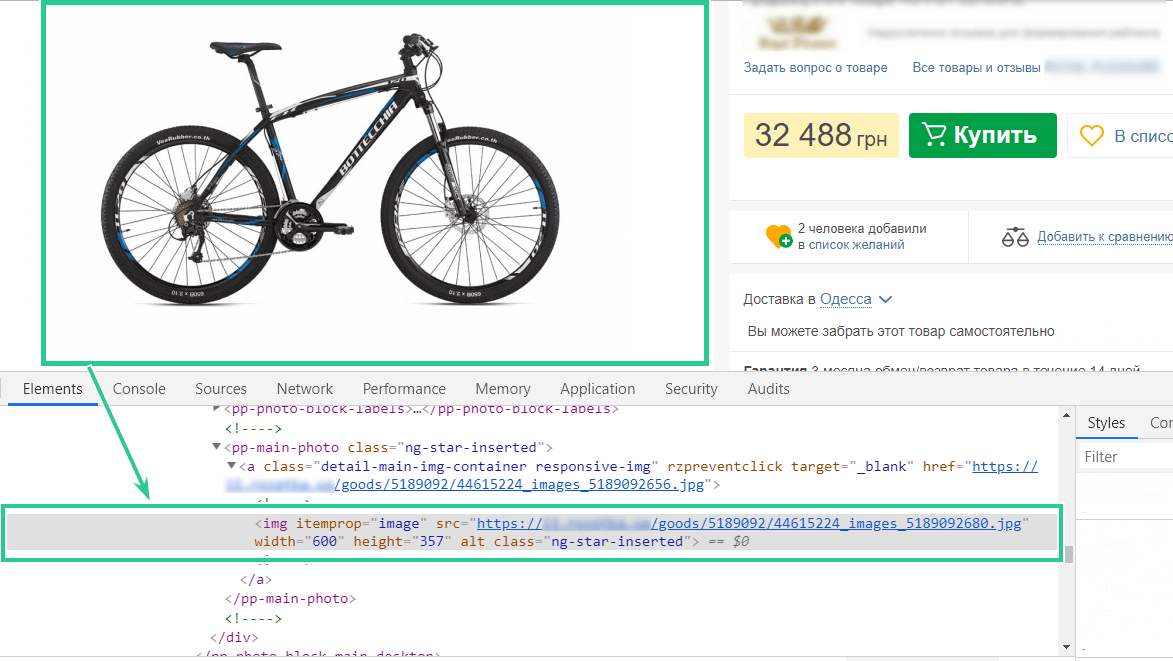
В данном случае можно использовать значения атрибута class или itemprop, так как они уникальны. Только парсить нужно не внутренний текст, а значение атрибута src, ведь именно он содержит искомую ссылку.
Способ 1
Способ 2
Фото собрали, теперь соберём характеристики. В парсинге всех характеристик нет необходимости, мне важно знать размер рамы и количество скоростей.
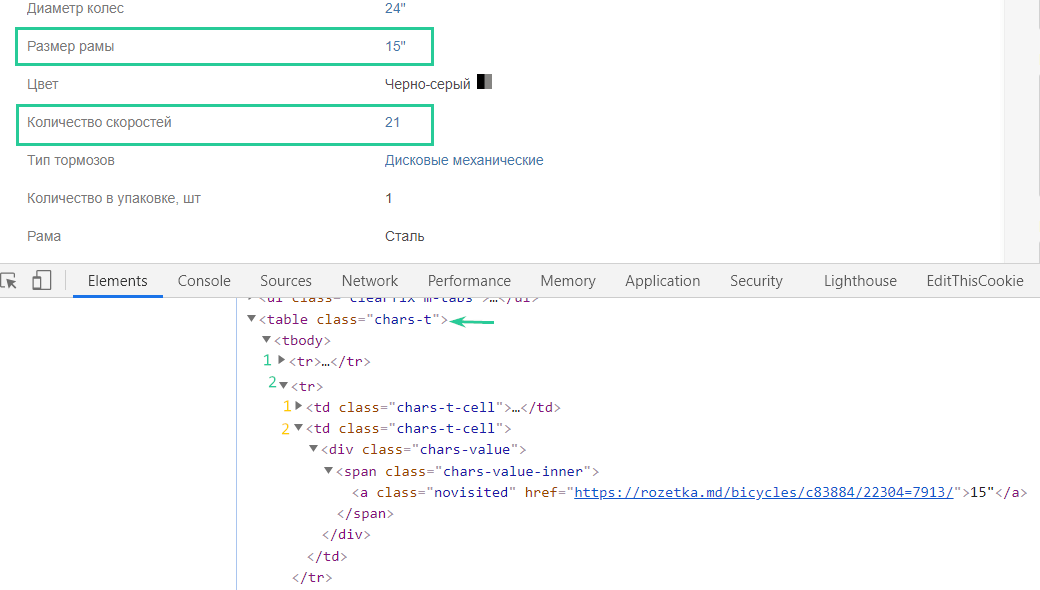
Есть множество вариантов, чтобы спарсить значения из таблицы. Но проблема заключается в том, что будут извлечены все значения в таблице, включая те, которые мне не нужны в отчёте: элементы в таблице имеют одинаковую разметку и одинаковые значения в атрибуте class.
В таком случае нужно использовать XPath. Он позволяет задать порядковый номер элемента. Чтобы спарсить размер рамы и количество скоростей, необходимо задать такие выражения:
Размер рамы
Количество скоростей
Нетрудно заметить, что меняться будет только порядковый номер строки в таблице. В большинстве случаев формула парсинга значений из таблицы остаётся неизменной:
где:
- attribute — любой атрибут тега <table>;
- attributeValue — значение атрибута, по которому можно идентифицировать таблицу;
- i — порядковый номер строки в таблице;
- j — порядковый номер столбца в таблице.
2. Как получить нужные данные с помощью функции парсинга в Netpeak Spider
Итак, все выражения для парсинга подобраны. Теперь необходимо проделать следующие действия:
- Откройте Netpeak Spider.
- Зайдите в настройки, откройте вкладку «Парсинг» и задайте подобранные условия.
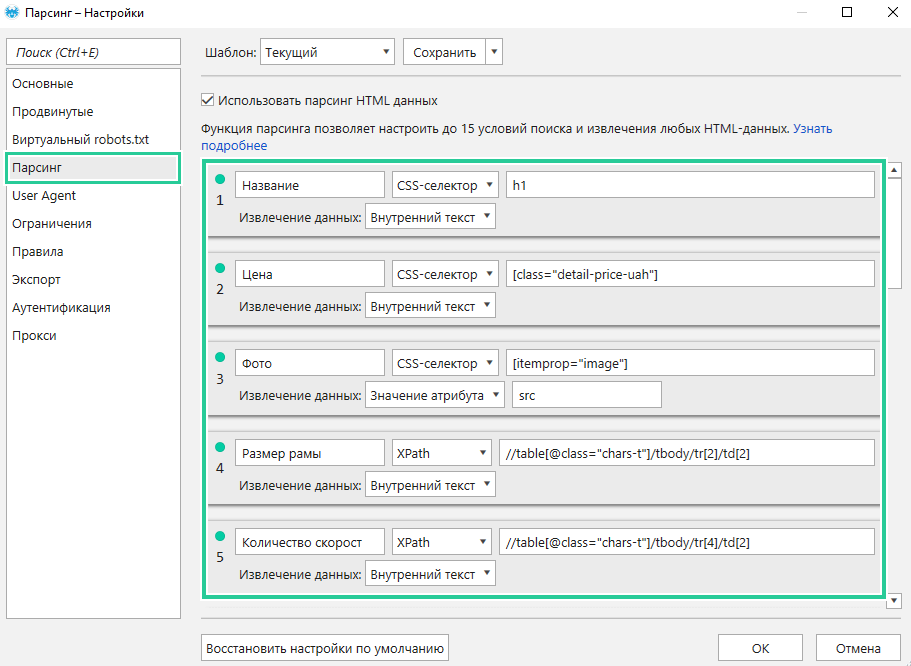
Перед запуском сканирования хочу поделиться небольшим лайфхаком.
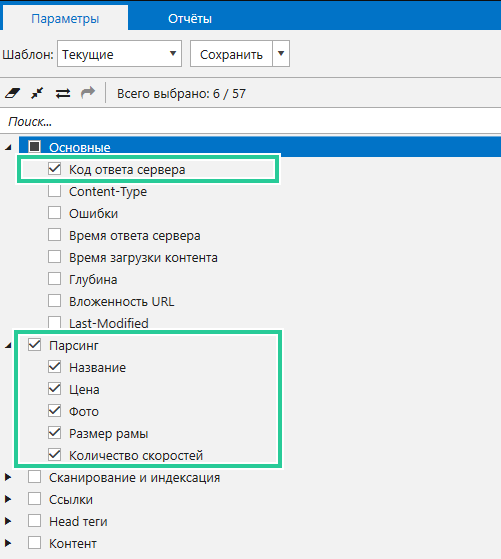
Программа по умолчанию анализирует много On-Page параметров, так как они необходимы для SEO-аудита. Для парсинга всё это не нужно. Разработчики позаботились о возможности включить только те параметры, которые вы считаете нужными для своей задачи. Перейдите на вкладку «Параметры», включите параметры парсинга и параметр «Код ответа сервера», а остальное отключите.
Как только сканирование будет завершено, в основной таблице вы найдёте значения найденных данных по заданным условиям.

При нажатии на число откроется окно с найденным значением. Полный отчёт по парсингу можно открыть несколькими способами:
- Через пункт меню «База данных» → «Сводка по парсингу».
- Через вкладку «Парсинг» на боковой панели → «Все результаты».
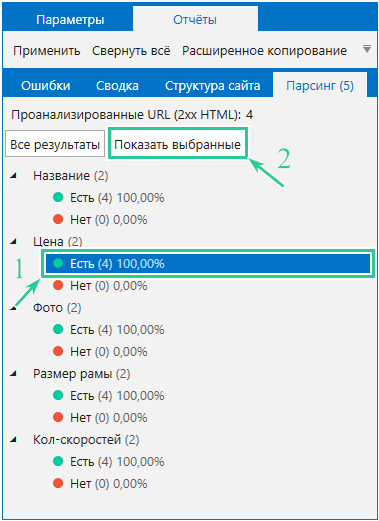
Дополнительно можно открыть отчёт по конкретному параметру на вкладке «Парсинг» боковой панели программы.
Кстати, в программе есть удобная функция, позволяющая буквально в два клика фильтровать данные, — сегментация.
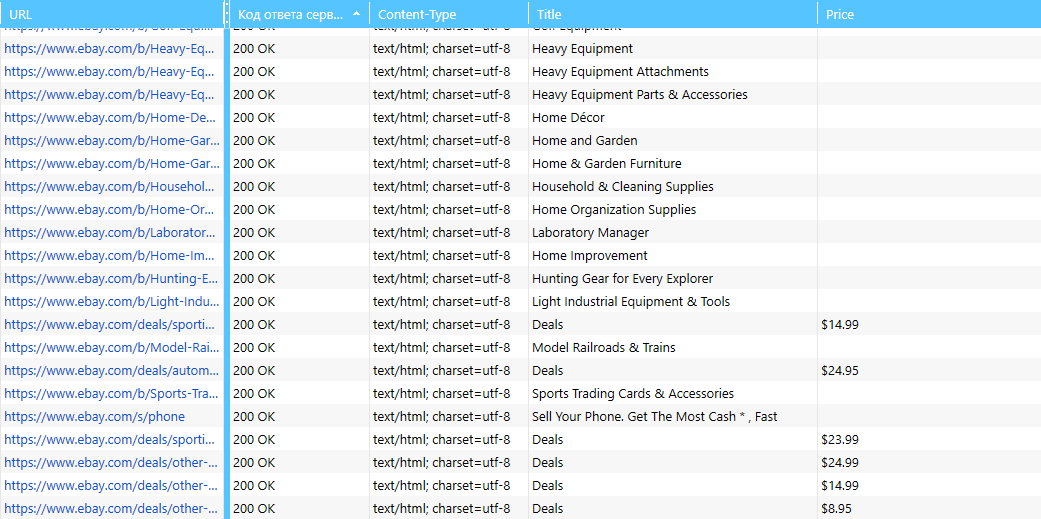
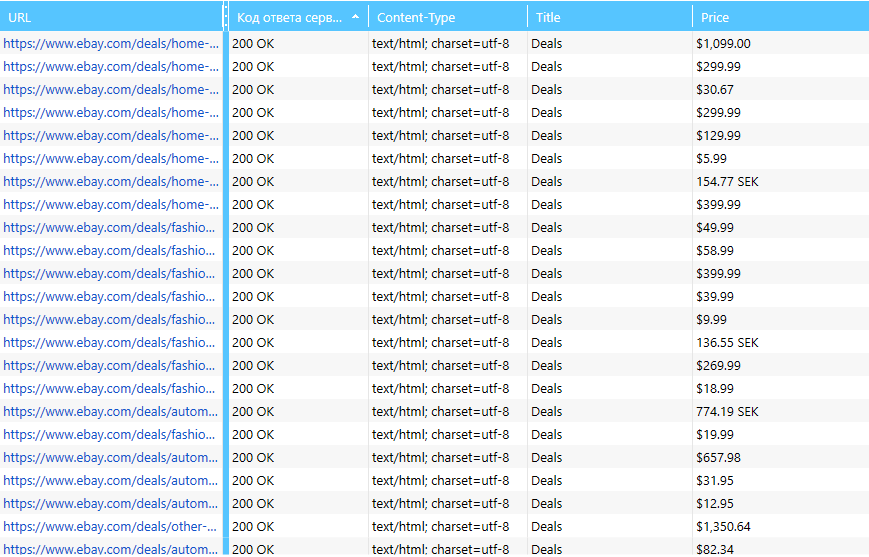
Представим, что после парсинга цен из какого-либо раздела на сайте была найдена 291 страница с ценой и 197 страниц без цены. Получается, в отчёте по парсингу будет много пустых ячеек в колонке «Цена», которые будут мешать. Однако если выбрать группу страниц, содержащих цену, и применить её как сегмент, то программа исключит все страницы без цен и покажет отчёт только по выбранной группе.
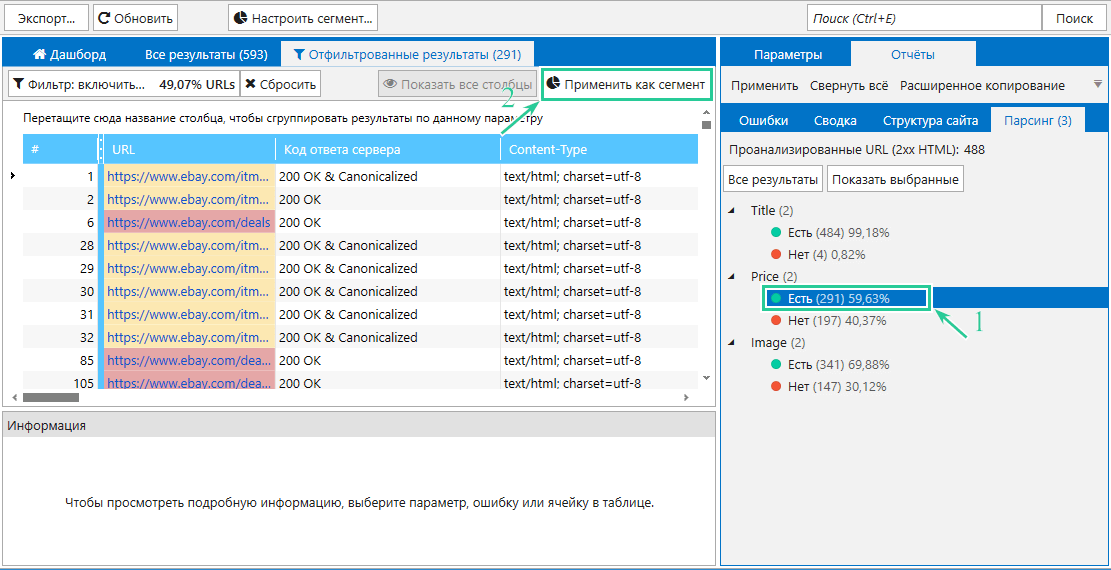
Читайте подробнее в посте → «Что такое сегментация в Netpeak Spider, и как её использовать».
Отчёт перед использованием сегментации:
И после:
Чтобы начать пользоваться Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить программу
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.3. FAQ
1. Все настройки парсинга заданы верно, но всё равно данные не парсятся. Почему?
1.1. Код ответа сервера — не 200 OK
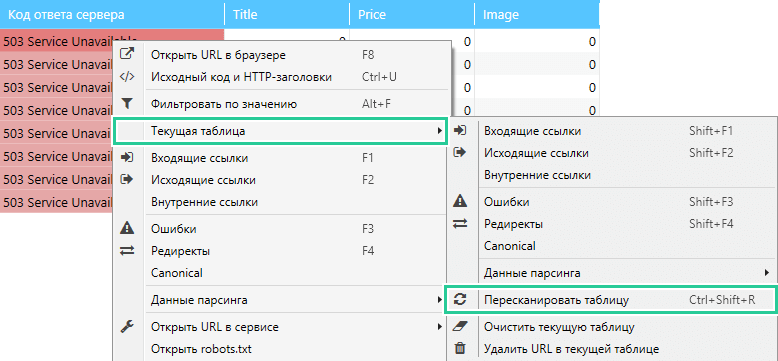
Данные не будут парситься, если страница вернула не 200 код ответа сервера, а, например, 503. Поэтому рекомендуется всегда оставлять этот параметр включённым. Как видно на скриншоте, количество найденных цен у страниц с 503 кодом ответа равно нулю, хотя если открыть их в браузере, то цены будут на страницах.
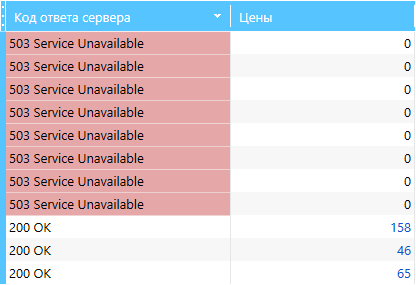
Решение: снизьте скорость сканирования и пересканируйте часть результатов. Это снизит нагрузку на сервер, а вероятность появления такой ситуации будет минимальна.
Алгоритм:
- Задайте один-два потока сканирования («Настройки» → «Основные» → «Скорость сканирования»).
- Выберите URL с некорректным кодом ответа сервера и примените функцию «Фильтровать по значению».
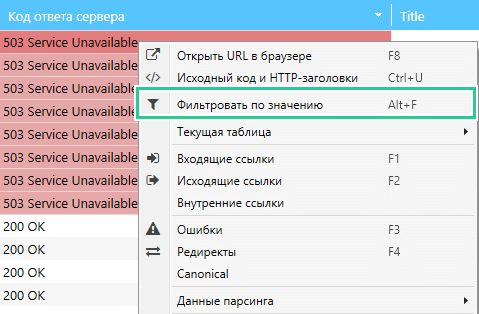
- Пересканируйте все URL с некорректным кодом ответа сервера.
1.2. Исходный код, который передаётся программе, отличается от исходного кода в браузере
Причиной может быть User Agent. Очевидно, что, например, разметка страницы для десктопного браузера Google Chrome и мобильного Safari будет разной.
Решение: изменить User Agent в настройках или открыть исходный код в инструменте «Анализ исходного кода и HTTP-заголовков» — это позволит посмотреть исходный код страницы в том виде, как его видит Netpeak Spider.
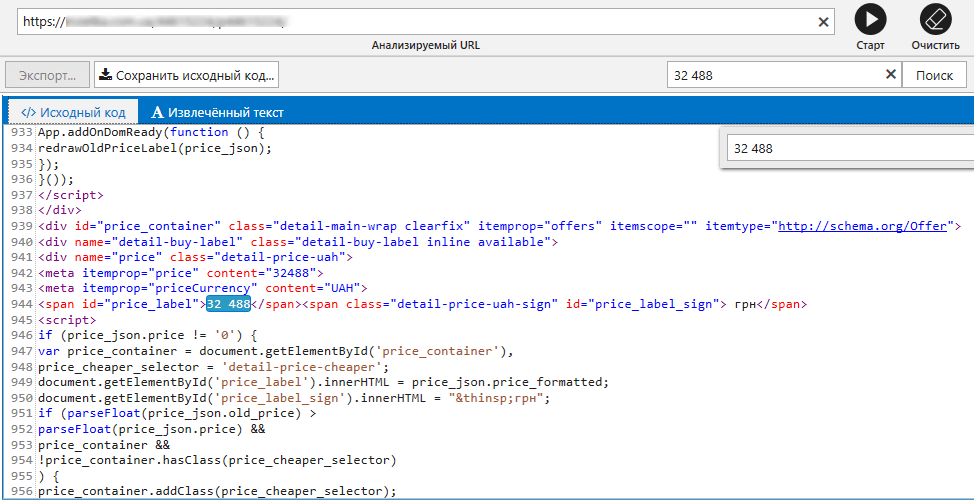
Примечание: иногда в исходном коде не находятся нужные данные. Это может произойти из-за того, что сайт использует JavaScript для отображения части своего контента. По умолчанию рендеринг JS отключён в программе. Включить его можно в настройках на вкладке «Основные».
2. В выгруженном отчёте данные склеиваются
Это происходит при парсинге элемента, который внутри себя содержит другие элементы HTML. Например, если парсить всю строку в таблице (тег <tr>), этот элемент будет содержать в себе несколько тегов
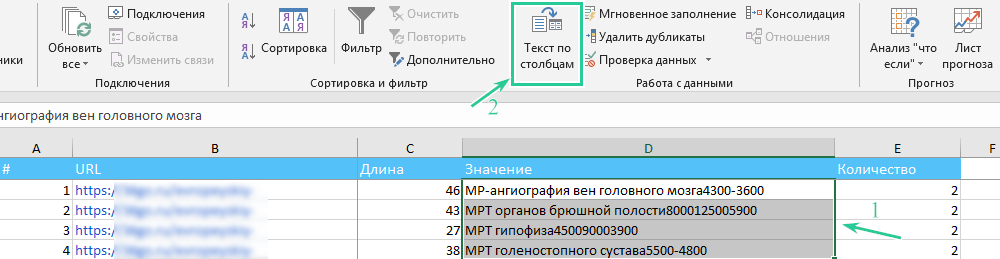
Решение: тут пригодится MS Excel. Между значениями записан символ переноса строки, и по нему можно разделить значения и перенести их по отдельным столбцам.
Алгоритм следующий:
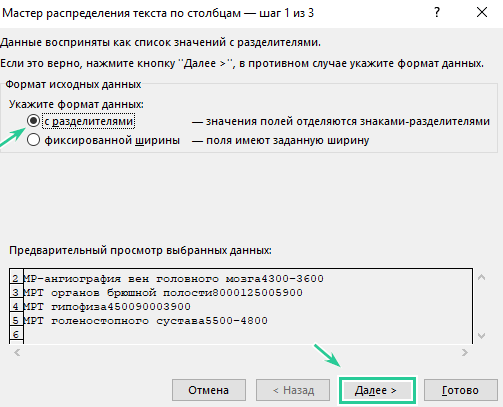
Шаг 1. Выберите столбец со значениями и нажмите «Текст по столбцам».
Шаг 2.
Шаг 3.
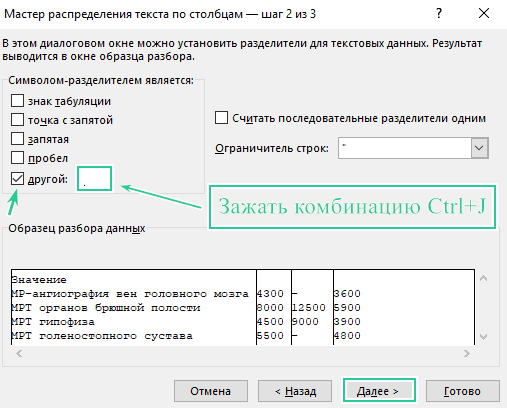
Шаг 4. Наслаждаемся результатом :)

- Как парсить цены из интернет-магазинов с помощью Netpeak Spider.
- Как спарсить нужные характеристики товаров из интернет-магазина с помощью Netpeak Spider.
- Как создать фид динамического ремаркетинга Adwords с помощью Netpeak Spider.
- Как проверить сайт на наличие смешанного контента с помощью Netpeak Spider.
- Как провести анализ SEO-стратегии конкурентов.
- Netpeak Spider 2.1.1.4: Пользовательский поиск и извлечение данных.
Подводим итоги
Надеюсь, данный пост помог вам разобраться с парсингом в Netpeak Spider и ответил на вопросы, которые у вас могли возникнуть в процессе. Буду рад поддержке лайками и репостами.
Если у вас есть какие-либо вопросы, задавайте их в комментариях или пишите мне в Telegram :)
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider

Отличный мануал по парсингу данных с помощью Netpeak Spider, спасибо за материал!
Отличный мануал по парсингу данных с помощью Netpeak Spider, спасибо за материал!
Большое спасибо, Михаил! Рад, что вам понравилась статья ;)
Марк, пост просто бомба! Ты крут!
Марк, пост просто бомба! Ты крут!
Большое спасибо! Стараюсь :)
Каждому инструменту своё назначение. parsehub делает это без всех этих танцев с бубном и ковыряния в коде страниц, с настройкой через интуитивно понятном пошаговом интерфейсе... С обходом каждой карточки товара, если это нужно и обходом страниц и при этом условно бесплатно.
Каждому инструменту своё назначение. parsehub делает это без всех этих танцев с бубном и ковыряния в коде страниц, с настройкой через интуитивно понятном пошаговом интерфейсе... С обходом каждой карточки товара, если это нужно и обходом страниц и при этом условно бесплатно.
Вы правы, программа ParseHub специализируется именно под эту задачу. Поэтому неудивительно, что там много разных инструментов, которые делают практически всю работу автоматически. В Netpeak Spider парсинг — одна из многочисленных функций, которая предоставляет возможность извлекать различные данные в процессе аудита сайта. Это удобно, так как парсинг может применяться и для SEO-задач. Мы сделали так, чтобы пользователям было удобно проводить аудит, парсить данные и решать многие другие задачи в одной программе — Netpeak Spider :)
Это невероятно) Я обожаю вас!) <3 Спасибо за крутой парсер и такие подробные полезные статьи!
Это невероятно) Я обожаю вас!) <3 Спасибо за крутой парсер и такие подробные полезные статьи!
Ирина, спасибо за тёплые слова) они мотивируют меня стараться ещё больше)
Делал по инструкции в итоге не проучилось спросить никакие данные. Слишком сложно организовано для обычного пользователя.
Делал по инструкции в итоге не проучилось спросить никакие данные. Слишком сложно организовано для обычного пользователя.
Руслан, многое зависит ещё и от сайта, который вы парсите. Здесь важно смотреть, какой код ответа у страниц, и отображаются ли в программе данные, которые вы хотите парсить. Иногда нужно менять настройки, к примеру: user-agent, прокси, рендеринг JS. Рекомендую вам написать в чат техподдержки и показать, какие настройки парсинга вы используете и для какого сайта. Но отмечу, что мы занимаемся подбором условий для парсинга начиная с тарифа Pro.
В той части, где вы указываете ссылки для получения характеристик, явно потерян скриншот с кодом. В результате совершенно не понятно почему поисковая строка постоена именно таким образом.
В той части, где вы указываете ссылки для получения характеристик, явно потерян скриншот с кодом. В результате совершенно не понятно почему поисковая строка постоена именно таким образом.
Действительно, нет исходного кода. Мы обязательно исправим в ближайшее время. Большое вам спасибо, что заметили! :)
В той части, где вы указываете ссылки для получения характеристик, явно потерян скриншот с кодом. В результате совершенно не понятно почему поисковая строка постоена именно таким образом.
Уже заменили :)
Селекторы Непонятна целевая группа статьи. Если она для тех кто ориентируется в том, что такое селекторы, то объяснять им что такое совершенно не нужно. Тем более когда сам в этом вопросе плаваешь. Если это статья для людей которые НЕ понимают и НЕ знают что такое DOM дерево, то научить их языку в рамках такой статьи невозможно, можно только напугать. Что Автору прекрасно удалось сделать. А нужно было всего лишь подсказать СПОСОБ как любой человек без каких бы то ни было специальных знаний может получить нужный адрес, не вспоминая детали языка который им не нужен. СПОСОБ ПОЛУЧЕНИЯ НУЖНОГО СЕЛЕКТОРА: Найдя нужный вам элемент в dev tools нажмите на нем правую кнопку мыши, в открывшемся подменю выберете опцию Copy ➊ в подменю меню выберете тот формат селектора который вам удобнее: ➋ для CSS селектора и ➌ для XPath. В буфер обмена будет скопирован готовый селектор для доступа к этому узлу. Скрин: https://drive.google.com/file/d/1wY2qEScQSmCXyVxqMrCcrW-RfStkNLqX/view Разница между CSS и XPath в рамках работы спайдера мне не известна. Если они используют webkit для парсинга страницы, то лучше выбирать CSS - будет работать быстрее. Ну и по сути предмета: >В таком случае нужно использовать XPath. Он позволяет задать порядковый номер элемента. XPath тут не нужен. Тут нужно знать предмет - а именно CSS чтобы не городить огороды. Селекторы позволяют нумеровать конкретные ноды ровно так же как и XPath. Xpath: //table[@class="chars-t"]/tbody/tr[2]/td[2] CSS: table.chars-t tbody tr:nth-child(1) td:nth-child(3) XPath нужен только в случае, когда вам нужно адресовать узел, который идентифицировать можно исключительно при реверсивном обходе дерева. То есть то чего CSS делать не умеет.
Селекторы Непонятна целевая группа статьи. Если она для тех кто ориентируется в том, что такое селекторы, то объяснять им что такое совершенно не нужно. Тем более когда сам в этом вопросе плаваешь. Если это статья для людей которые НЕ понимают и НЕ знают что такое DOM дерево, то научить их языку в рамках такой статьи невозможно, можно только напугать. Что Автору прекрасно удалось сделать. А нужно было всего лишь подсказать СПОСОБ как любой человек без каких бы то ни было специальных знаний может получить нужный адрес, не вспоминая детали языка который им не нужен. СПОСОБ ПОЛУЧЕНИЯ НУЖНОГО СЕЛЕКТОРА: Найдя нужный вам элемент в dev tools нажмите на нем правую кнопку мыши, в открывшемся подменю выберете опцию Copy ➊ в подменю меню выберете тот формат селектора который вам удобнее: ➋ для CSS селектора и ➌ для XPath. В буфер обмена будет скопирован готовый селектор для доступа к этому узлу. Скрин: https://drive.google.com/file/d/1wY2qEScQSmCXyVxqMrCcrW-RfStkNLqX/view Разница между CSS и XPath в рамках работы спайдера мне не известна. Если они используют webkit для парсинга страницы, то лучше выбирать CSS - будет работать быстрее. Ну и по сути предмета: >В таком случае нужно использовать XPath. Он позволяет задать порядковый номер элемента. XPath тут не нужен. Тут нужно знать предмет - а именно CSS чтобы не городить огороды. Селекторы позволяют нумеровать конкретные ноды ровно так же как и XPath. Xpath: //table[@class="chars-t"]/tbody/tr[2]/td[2] CSS: table.chars-t tbody tr:nth-child(1) td:nth-child(3) XPath нужен только в случае, когда вам нужно адресовать узел, который идентифицировать можно исключительно при реверсивном обходе дерева. То есть то чего CSS делать не умеет.
в CSS селекторе опечатки в цифре. Не CSS: table.chars-t tbody tr:nth-child(1) td:nth-child(3) а CSS: table.chars-t tbody tr:nth-child(2) td:nth-child(2)
Селекторы Непонятна целевая группа статьи. Если она для тех кто ориентируется в том, что такое селекторы, то объяснять им что такое совершенно не нужно. Тем более когда сам в этом вопросе плаваешь. Если это статья для людей которые НЕ понимают и НЕ знают что такое DOM дерево, то научить их языку в рамках такой статьи невозможно, можно только напугать. Что Автору прекрасно удалось сделать. А нужно было всего лишь подсказать СПОСОБ как любой человек без каких бы то ни было специальных знаний может получить нужный адрес, не вспоминая детали языка который им не нужен. СПОСОБ ПОЛУЧЕНИЯ НУЖНОГО СЕЛЕКТОРА: Найдя нужный вам элемент в dev tools нажмите на нем правую кнопку мыши, в открывшемся подменю выберете опцию Copy ➊ в подменю меню выберете тот формат селектора который вам удобнее: ➋ для CSS селектора и ➌ для XPath. В буфер обмена будет скопирован готовый селектор для доступа к этому узлу. Скрин: https://drive.google.com/file/d/1wY2qEScQSmCXyVxqMrCcrW-RfStkNLqX/view Разница между CSS и XPath в рамках работы спайдера мне не известна. Если они используют webkit для парсинга страницы, то лучше выбирать CSS - будет работать быстрее. Ну и по сути предмета: >В таком случае нужно использовать XPath. Он позволяет задать порядковый номер элемента. XPath тут не нужен. Тут нужно знать предмет - а именно CSS чтобы не городить огороды. Селекторы позволяют нумеровать конкретные ноды ровно так же как и XPath. Xpath: //table[@class="chars-t"]/tbody/tr[2]/td[2] CSS: table.chars-t tbody tr:nth-child(1) td:nth-child(3) XPath нужен только в случае, когда вам нужно адресовать узел, который идентифицировать можно исключительно при реверсивном обходе дерева. То есть то чего CSS делать не умеет.
Спасибо за комментарий! Цели научить пользователей обходить DOM-дерево у меня не было. Для этого, полагаю, уже существует масса других статей в интернете на эту тему, авторы которых способны описать это и получше чем я. Да и это не совсем формат нашего блога :) Я написал эту статью в первую очередь с целью помочь пользователям разобраться с парсингом в нашей программе Netpeak Spider, а также с основами CSS-селекторов и / или Xpath. Такое решение было принято из-за многочисленных тикетов в чате по поводу парсинга данных из сайтов. Я обратил внимание, что в 95% случаев это достаточно простые кейсы, потому решил продемонстрировать их в рамках этой статьи + постарался описать и нюансы работы с Netpeak Spider. И, судя по отзывам, она действительно помогает ввести в курс дела наших пользователей, которые ранее с парсингом не сталкивались. Касаемо копирования селекторов через Dev Tools в браузере — соглашусь, этот способ самый простой и не требует каких-либо специальных знаний. И мы даже его показывали в более раней статье по парсингу [https://netpeaksoftware.com/blog/kak-parsit-tseny-iz-internet-magazinov-s-pomoschyu-netpeak-spider]. Но как показывала практика, этот способ работает не очень хорошо по двум причинам: 1. Полученный таким образом путь достаточно часто не работает или парсит не совсем то, что нужно пользователю. Нам приходило очень много обращений, что таким путём ничего не получается спарсить. 2. В большинстве случаев путь получается громоздким, и чтобы разобраться, почему не работает, необходимо потратить много времени. Проще собрать путь самостоятельно, особенно для таких кейсов, которые я описал в статье. И также по поводу нумерации в CSS-селекторах — об этом я знал изначально, но мне показалось, что для новичка XPath будет выглядеть проще в этом случае. Но твёрдо соглашусь, что мне не следовало писать «В таком случае нужно использовать XPath» → это вводит в заблуждение, будто Xpath — это единственный вариант. Думаю, что мы исправим это в посте.
Селекторы Непонятна целевая группа статьи. Если она для тех кто ориентируется в том, что такое селекторы, то объяснять им что такое совершенно не нужно. Тем более когда сам в этом вопросе плаваешь. Если это статья для людей которые НЕ понимают и НЕ знают что такое DOM дерево, то научить их языку в рамках такой статьи невозможно, можно только напугать. Что Автору прекрасно удалось сделать. А нужно было всего лишь подсказать СПОСОБ как любой человек без каких бы то ни было специальных знаний может получить нужный адрес, не вспоминая детали языка который им не нужен. СПОСОБ ПОЛУЧЕНИЯ НУЖНОГО СЕЛЕКТОРА: Найдя нужный вам элемент в dev tools нажмите на нем правую кнопку мыши, в открывшемся подменю выберете опцию Copy ➊ в подменю меню выберете тот формат селектора который вам удобнее: ➋ для CSS селектора и ➌ для XPath. В буфер обмена будет скопирован готовый селектор для доступа к этому узлу. Скрин: https://drive.google.com/file/d/1wY2qEScQSmCXyVxqMrCcrW-RfStkNLqX/view Разница между CSS и XPath в рамках работы спайдера мне не известна. Если они используют webkit для парсинга страницы, то лучше выбирать CSS - будет работать быстрее. Ну и по сути предмета: >В таком случае нужно использовать XPath. Он позволяет задать порядковый номер элемента. XPath тут не нужен. Тут нужно знать предмет - а именно CSS чтобы не городить огороды. Селекторы позволяют нумеровать конкретные ноды ровно так же как и XPath. Xpath: //table[@class="chars-t"]/tbody/tr[2]/td[2] CSS: table.chars-t tbody tr:nth-child(1) td:nth-child(3) XPath нужен только в случае, когда вам нужно адресовать узел, который идентифицировать можно исключительно при реверсивном обходе дерева. То есть то чего CSS делать не умеет.
1. Целевая аудитория этой статьи — наши пользователи. И им сочувствующие))) 2. Спасибо за комментарий и советы.) 3. Никто из нас не идеален и не знает всех нюансов в любом деле в мире — и вы тоже. Но мы стараемся каждый день становиться лучше: думаю, что подобные комментарии помогут нам в этом!)
1. Целевая аудитория этой статьи — наши пользователи. И им сочувствующие))) 2. Спасибо за комментарий и советы.) 3. Никто из нас не идеален и не знает всех нюансов в любом деле в мире — и вы тоже. Но мы стараемся каждый день становиться лучше: думаю, что подобные комментарии помогут нам в этом!)
"Если это статья для людей которые НЕ понимают и НЕ знают что такое DOM дерево, то научить их языку в рамках такой статьи невозможно, можно только напугать. Что Автору прекрасно удалось сделать." - это в точку))) Удалось меня напугать((( - непонятно для кого снимали и писали.
Чогось така конструкція не працює: <a href="(/companies/[^"]*?/jobs/[^"]*?)">(.*?)</a> Для посилань типу таких: <a href="/companies/swif-ai/jobs/9H1KM0B-full-cycle-account-executive">Full-Cycle Account Executive</a> <a href="/companies/swif-ai/jobs/9H1KM0B-1full-cycle-account-executive">Full-Cycle Account Executive 2</a> <a href="/companies/swif-a/9H1KM0B-1full-cycle-account-executive">Full-Cycle Account Executive 2</a>
Чогось така конструкція не працює: <a href="(/companies/[^"]*?/jobs/[^"]*?)">(.*?)</a> Для посилань типу таких: <a href="/companies/swif-ai/jobs/9H1KM0B-full-cycle-account-executive">Full-Cycle Account Executive</a> <a href="/companies/swif-ai/jobs/9H1KM0B-1full-cycle-account-executive">Full-Cycle Account Executive 2</a> <a href="/companies/swif-a/9H1KM0B-1full-cycle-account-executive">Full-Cycle Account Executive 2</a>
При цьому просто дістати посилання виходить ось так href="(/companies/[^"]*?/jobs/[^"]*?)"


