Netpeak Spider: Внутренний PageRank от А до Я
Кейсы

Пост ответит на главные вопросы, которые задаёт множество наших пользователей, а именно:
- Что такое внутренний PageRank? Зачем он нужен?
- Какую пользу можно получить, если оптимизировать распределение внутреннего веса внутри сайта?
- Как выполняются расчёты?
- Какие ссылки учитываются при расчёте, а какие — нет? Учитываются ли дубли ссылок?
- 1. Введение в понятие PageRank
- 2. Математическая составляющая PageRank
- 3. Инструмент «Расчёт внутреннего PageRank» в Netpeak Spider: какие ошибки перелинковки он определяет
- 4. Работа с основной таблицей инструмента
- 5. Динамика сумм PR
- Коротко о главном
1. Введение в понятие PageRank
Когда интернет ещё не был столь развит, как сейчас, считалось, что база данных со сведениями обо всех доступных ресурсах сети, т.е. «поисковый индекс», позволит быстро и легко найти любую интересующую нас информацию. Как вскоре выяснилось, появилась необходимость внедрить некий механизм, позволяющий не только найти результаты по определённым поисковым запросам, но и оценить качество этих результатов. Сергей Брин и Ларри Пейдж разработали один из таких механизмов — PageRank.
Разработчики вдохновились тем, как учёные оценивают «важность» научных работ — по количеству других научных статей, которые на них ссылаются. Сергей и Ларри взяли эту концепцию и применили её в сети, отслеживая ссылки между веб-страницами. Если представить, что ссылки — это рекомендации, то чем больше ссылок получает страница, тем она качественнее. Это позволило определить приоритетность одних страниц над другими и выстроить результаты по запросам пользователей от наиболее до менее релевантных. Данная концепция была настолько эффективной, что стала основой поисковой системы, которую мы теперь называем Google.
Netpeak Spider использует тот же принцип при подсчёте PageRank. Однако в отличие от Google, PageRank анализируется только внутри сайта и не выходит за его пределы. Именно поэтому PageRank называется внутренним.
Внутренний PageRank — это оценка значимости или «популярности» страницы исключительно в пределах одного сайта в зависимости от количества и качества ссылающихся на неё внутренних страниц.
Оценку PageRank также принято называть ссылочным весом. Когда страница ссылается на другую, она передаёт часть своего ссылочного веса при условии, что ссылка находится в блоке
и не содержит в себе инструкций, запрещающих переходить по ссылке роботам поисковых систем. Чем больше у страницы ссылочного веса, тем «популярнее» она становится внутри сайта. Следовательно, роботы поисковых систем будут чаще обращать на неё внимание.Особенно это актуально для крупных сайтов. Сосредотачивая ссылочный вес на определённых страницах, вы показываете роботам поисковых систем, что они наиболее важны для вас, так как именно от них зависит трафик сайта.
2. Математическая составляющая PageRank
Чтобы понять, сколько ссылочного веса получает страница А, необходимо применить некоторые математические расчёты, которые выполняются поэтапно, и каждый такой этап называется итерацией.
Все итерации, за исключением нулевой, применяют одну и ту же формулу в расчётах. Но перед тем как перейти к разбору формулы, ответим на вполне логичный вопрос: «Почему расчёт выполняется несколько раз, и сколько итераций необходимо?».
Дело в том, что значение PR может быть рассчитано только рекурсивно. То есть чтобы рассчитать PR определённой страницы, необходимо вычислить его для входящих ссылок, входящих ссылок на входящие и т.д. На первый взгляд алгоритм кажется бесконечным, но это не так. На нулевой итерации, представляющей собой нерекурсивную ветвь, каждая страница имеет тот же PR равный 1/N, где N — количество страниц, участвующих в расчёте.
Таким образом, получается очень грубое приближение, где каждая страница условно имеет одинаковую важность без учёта их действительной взаимосвязи.
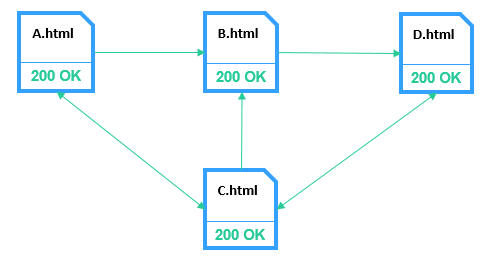
Начиная с первой итерации алгоритм просчитывает реальные взаимосвязи между страницами.
Для этого применяется формула:
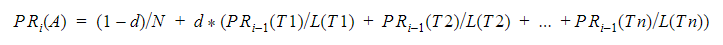
Значение PR, рассчитанное по данной формуле, можно трактовать как вероятность того, что случайный пользователь посетит эту страницу. Из этого следует вывод, что PageRank можно рассматривать как модель поведения пользователя. Предполагается, что есть «случайный пользователь», который переходит на веб-страницу и продолжает нажимать на ссылки, никогда не нажимая «назад». Именно такая концепция представлена в оригинальной научной статье о PageRank.
В формуле фигурируют следующие слагаемые:
- A — узел (страница), рассчитываемый в данный момент.
- i — номер итерации, который принимает значения от 0 до N (общее количество активных узлов, участвующих в расчёте).
- T1, T2, …, Tn — уникальные входящие ссылки узла А
- L(T1), L(T2),...,L(Tn) — количество уникальных исходящих ссылок узлов T1, T2, …, Tn.
- d – коэффициент затухания, который показывает вероятность того, что пользователь запросит другую случайную страницу во время «прогулки» по сайту. Принято считать коэффициентом затухания значение 0.85 согласно рекомендациям разработчиков данного алгоритма. А оставшаяся вероятность в 0.15 — это вероятность того, что пользователь не перейдёт по ссылке дальше, а закроет вкладку браузера.
На каждой итерации получается более точное приближение к итоговому значению. PR рассчитывается до тех пор, пока результат между итерациями будет практически схожим. Согласно нашим наблюдениям, 15 итераций вполне достаточно, чтобы получить точный результат — поэтому такое значение итераций задано в инструменте по умолчанию.
Netpeak Spider, начиная с версии 3.0, учитывает ещё одну формулу, которая была опубликована в этой статье:
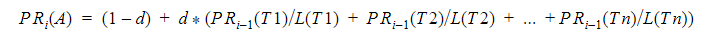
Теперь в инструменте «Расчёт внутреннего PageRank» можно анализировать как первый, так и второй вариант PR. Далее в статье значение PR по первой формуле будет обозначаться как PR1, а по второй — PR2 во избежание путаницы между двумя формулами.
Вторая формула позволяет узнать немного больше деталей о странице, чем первая, в частности:
- если PR2 > 1,0 → страница получает больше ссылочного веса, чем передаёт (оптимально для посадочных страниц);
- если PR2 = 1,0 → страница отдаёт примерно столько же веса, сколько и получает;
- если PR2< 1,0 → страница отдаёт больше ссылочного веса, чем получает (оптимально для менее важных страниц).
Расчёт PR удобно представлять в виде таблицы.
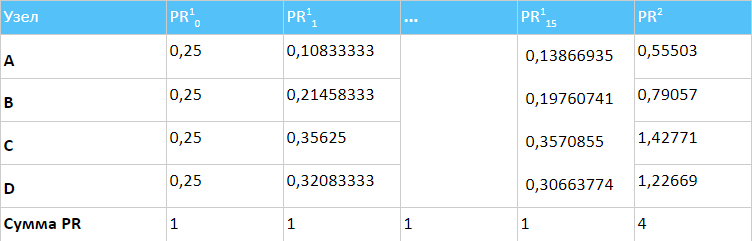
Исходя из представленных данных, видно, что страница С получает наибольшее количество ссылочного веса, а страница A — наименьшее.
В идеальном случае сумма весов всех страниц на каждой итерации одинакова и для PR1 равняется 1, а для PR2 равняется N. Однако в случае с реальным сайтом ситуация несколько другая: сумма весов на нулевой итерации может не сходиться с суммой на последней итерации, так как почти всегда присутствуют ссылки на внешние ресурсы или же на страницы, которые не передают ссылочный вес далее — висячие узлы. И если ссылки на внешние страницы — это вполне нормально, то висячие узлы могут нести вред, поэтому им рекомендуется уделить больше внимания.
3. Инструмент «Расчёт внутреннего PageRank» в Netpeak Spider: какие ошибки перелинковки он определяет
С помощью инструмента «Расчёт внутреннего PageRank» можно понять:
- как ссылочный вес распределяется по сайту;
- какие страницы получают избыточный ссылочный вес;
- какие страницы получают меньше веса или вообще его «сжигают».
Чтобы открыть меню инструмента, перейдите в «Инструменты» → «Расчёт внутреннего PageRank» или нажмите «Запустить» → «Расчёт внутреннего PageRank».
Данные, представленные внутри инструмента, можно условно поделить на следующие блоки:
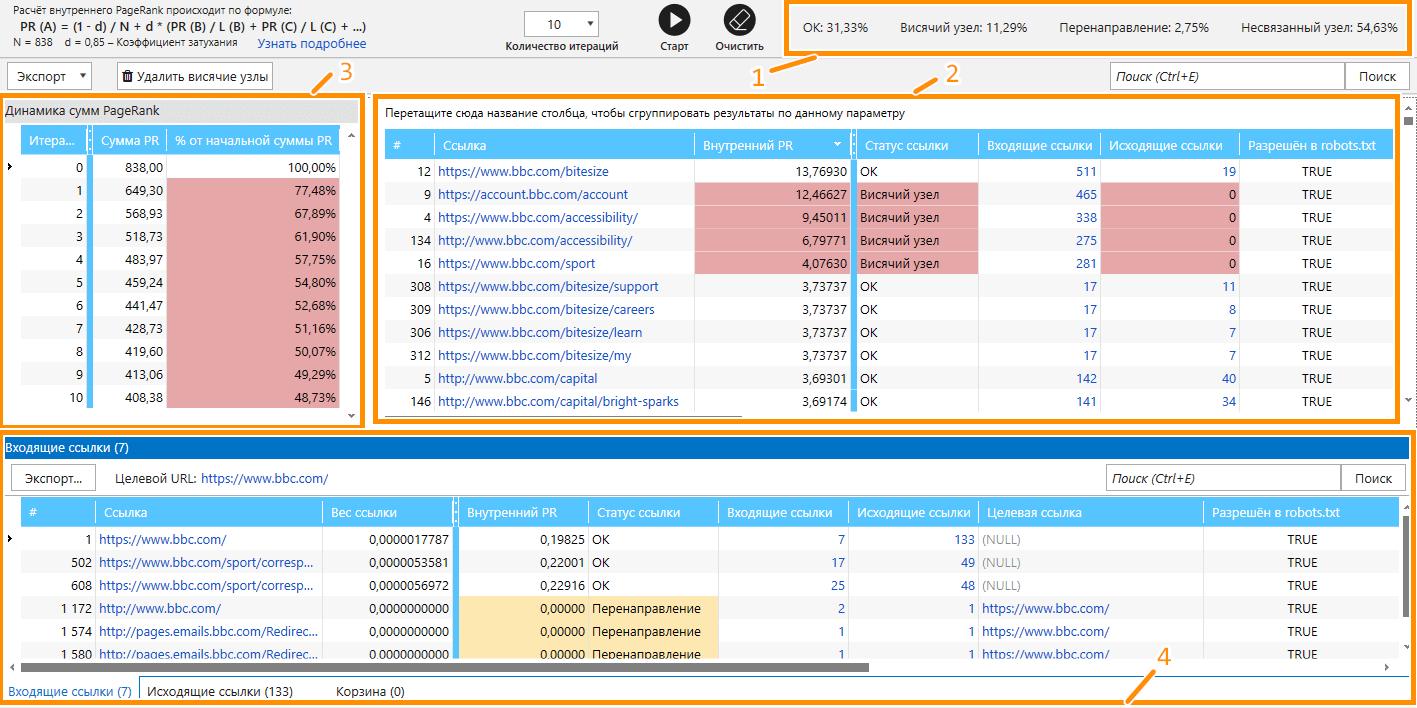
- Статистические данные по статусам ссылок, выраженные в процентном соотношении.
- Основная таблица показывает всю информацию по страницам, включая их вес, код ответа сервера, данные об индексируемости, количество входящих и исходящих ссылок и т.д.
- Динамика сумм PageRank.
- Таблицы с информацией о ссылках.
- Корзина.
Обратите внимание, что представленные отчёты по ссылкам содержат исключительно уникальные ссылки. Если страница получает несколько ссылок от одной и той же страницы, то учитываться будет лишь одна из них, а внешние ссылки в расчёт внутреннего PageRank не берутся вовсе.
Чтобы начать пользоваться Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить программу
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.3.1. Статусы ссылок
- OK
- Висячий узел
- Несвязный узел
- Перенаправление
3.1.1. OK
Это HTML-страницы с кодом ответа сервера «200 OK», которые содержат исходящие ссылки и могут быть:
- неиндексируемыми страницами с тегом noindex;
- страницами с тегом Canonical, указанным на себя;
- страницами с тегом Refresh, указанным на себя.
3.1.2. Висячий узел
Висячий узел — это страница, которая получает ссылочный вес, но не передаёт его другим страницам. Таким образом, страница имеет определённое количество ссылающихся на неё страниц, но полученный ссылочный вес от входящих ссылок в результате «сжигается». Почему же так происходит, и как понять причину возникновения висячего узла и устранить его? Висячий узел может возникнуть из-за множества различных причин, о которых пойдёт речь далее.
3.1.2.1. Битые страницы
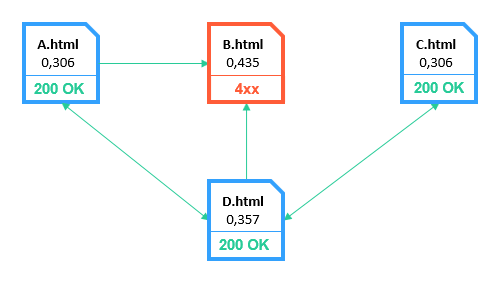
Сумма PR2 → 1,4
Потеря ссылочного веса → 65%
Данный тип является наиболее критичным. Битые ссылки не только негативно влияют на пользовательский опыт, но и на индексацию и ранжирование сайта.
Чтобы понять, какие страницы содержат ссылки на страницы с 4xx кодом ответа, вам необходимо использовать отчёт о входящих ссылках в Netpeak Spider.
Более подробную информацию о битых ссылках, и как от них избавляться, можно найти в статье → Как найти битые ссылки на сайте с помощью Netpeak Spider.
3.1.2.2. Страница скрыта от индексации определёнными инструкциями или правилами
Страница может быть скрыта от индексации одним из способов:
- robots.txt;
- nofollow в X-Robots-Tag;
- nofollow в Meta Robots.
Данный тип висячих узлов не критичен и может возникать у большинства сайтов. Информацию об индексации той или иной страницы можно узнать по её коду ответа или по параметрам индексации в таблице инструмента:
- «Код ответа сервера».
- «Разрешён в robots.txt» .
- «Meta Robots».
- «Канонический URL».
- «X-Robots-Tag».
- «Refresh».
Закрытые от индексации страницы, за исключением страниц с атрибутами noindex, follow, не передают ссылочный вес страницам, на которые ссылаются, из-за чего и возникает висячий узел. Ранее для решения подобной проблемы для Google применялся атрибут rel=nofollow, а для Яндекс — тег
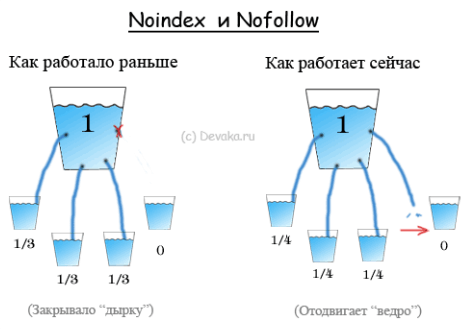
Если висячий узел возникает именно по причине неидексируемости страницы, то наиболее приемлемое решение проблемы — как можно меньше ссылаться на неиндексируемые страницы или скрывать ссылки от поисковых систем. Такой подход называется SEOhide.
3.1.2.3. 3xx страницы, скрытые директивами в файле robots.txt
3xx страницы отдают 3xx код ответа сервера. Это означает, что страница, к которой запрашивается доступ, перенаправляет на другую, причём целевая страница редиректа скрыта для роботов с помощью директив в файле robots.txt. В этом случае поисковый робот, переходя по ссылке, попадает на заблокированный для него адрес, что приводит к растрате краулингового бюджета и ссылочного веса. Существует несколько вариантов решений данной проблемы, в частности:
- Указать прямую ссылку на страницу, не используя редирект.
- Скрыть начальный URL редиректа в файле robots.txt.
3.1.2.4. Страницы с 503 или 429 кодом ответа сервера
Несмотря на то, что страницы с 4xx и 5xx кодами ответа можно отнести к категории «битые страницы», они могут иметь разное происхождение. Коды 5xx появляются в случае неудачной обработки запроса сервером. То есть страница может существовать, но в момент её запроса сервер по какой-то причине дал сбой, или же сработал специальный алгоритм, предотвращающий DDoS-атаку на сервер.
Сканирование сайта на большой скорости воспринимается серверами как DDoS-атака, поэтому может сработать соответствующая защита. В таких случаях зачастую страница возвращает 503 или 429 код ответа и считается висячим узлом. Тогда рекомендуется пересканировать страницы через некоторое время, задав один поток в настройках сканирования. Иногда приходится задействовать и прокси, так как сайт может временно внести ваш IP в чёрный список и больше не возвращать ему никакой информации о страницах.
3.1.3.Несвязный узел
Несвязный узел — это страница, которая не получает ссылочного веса из-за отсутствия входящих ссылок, передающих ссылочный вес.
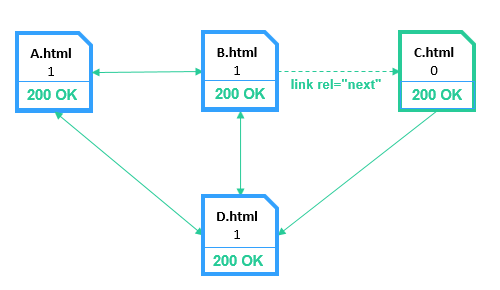
Несвязным узлом считается страница, для которой выполняется хотя бы одно из следующих условий:
- Все ссылки на страницу представлены исключительно с помощью тега (за исключением Canonical и Refresh). Данный тип ссылки не передаёт ссылочный вес странице, так как является служебной ссылкой.
- Программа не нашла связей между анализируемыми страницами. Данная ситуация возникает при сканировании собственного списка URL или выгруженного из карты сайта.
- На страницу ссылаются исключительно закрытые от индексации страницы, что происходит при сканировании сайта с выключенным учётом инструкций по индексации (Robots.txt, Canonical, Refresh, X-Robots-Tag, Meta Robots и атрибут nofollow у ссылок).
Важно понимать, что наличие несвязного узла — не всегда ошибка. Программа лишь уведомляет о том, что такие страницы присутствуют на сайте. Несвязным узлом может выступать какая-либо служебная страница, которая и не должна быть в индексе поисковой системы. Однако если это не так, необходимо немедленно исправлять ситуацию, создав хотя бы 10 внутренних ссылок на неё, которые передавали бы ссылочный вес. В противном случае поисковый робот посчитает её неважной, и она не сможет достигнуть высоких позиций.
3.1.4. Перенаправление
Страница со статусом «Перенаправление» — это любая страница, возвращающая 3xx код ответа сервера, которая перенаправляет пользователя или поискового робота на другую страницу с 200 OK кодом ответа сервера и полностью передаёт ей свой ссылочный вес.
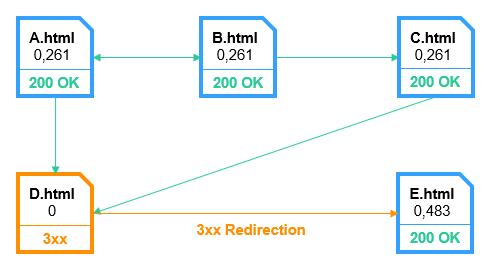
К этому типу также относятся:
- 2xx страницы с тегом Canonical, указанным на другую страницу.
- 2xx страницы с тегом Refresh, указанным на другую страницу.
Дело в том, что такие страницы «склеиваются» с теми, на которые ведут ссылки Refresh или Canonical, потому ссылочный вес полностью передаётся им, как и в ситуации с редиректом. С точки зрения распределения ссылочного веса, это можно рассматривать как перенаправление.
4. Работа с основной таблицей инструмента
Основная таблица инструмента содержит следующую информацию:
- PR1 и PR2;
- количество входящих и исходящих ссылок;
- тип контента;
- инструкции индексации узлов, которые участвуют в расчёте.
В основной таблице есть несколько встроенных функций, которые помогут вам существенно упростить и сделать более эффективным анализ узлов и использование инструмента в целом.
4.1. Упорядочивание
Данные в таблице можно легко сортировать по возрастанию и убыванию значений. Например, по значениям PR, чтобы быстро определить, какая страница получает наибольшее количество ссылочного веса, а какая — наименьшее.
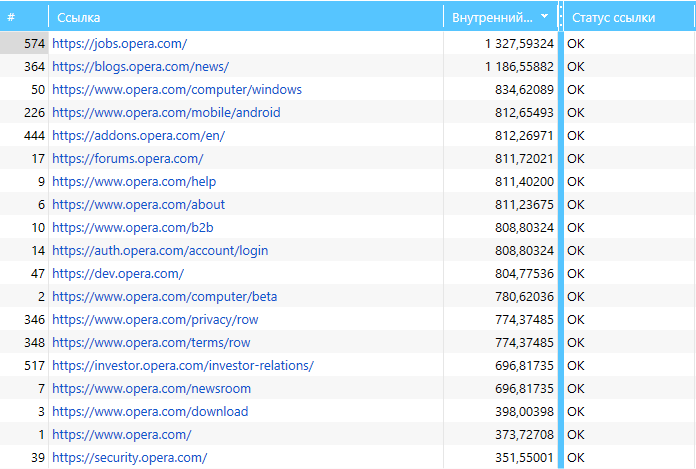
4.2. Группировка
Полученные данные в таблице можно упорядочивать и группировать по любому параметру. Для этого достаточно захватить заголовок какой-либо колонки левой кнопкой мыши и потянуть вверх. Например, можно сгруппировать данные по статусу ссылки, как представлено на скриншоте:
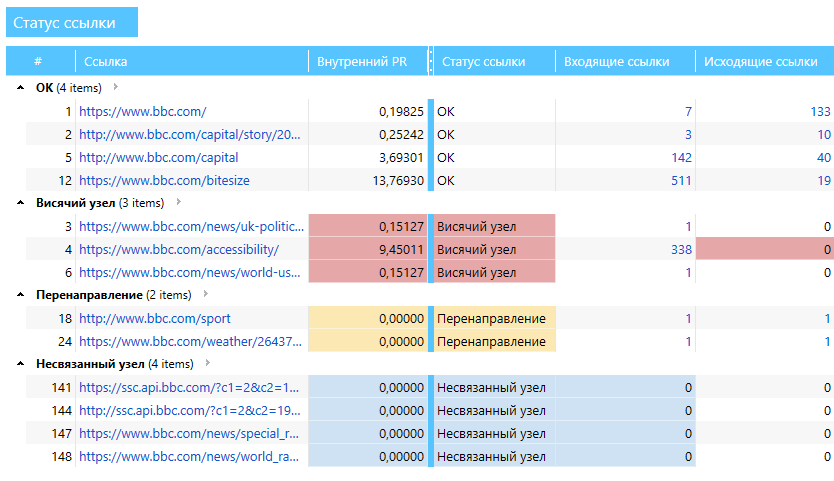
4.3. Моделирование ситуаций
Инструмент позволяет удалять целые узлы, моделируя ситуацию, которая демонстрирует, что было бы с PR каждой страницы, если бы ссылки на эти узлы отсутствовали. Это помогает понять, как будет распределяться ссылочный вес при изменениях на сайте.
При удалении ссылка автоматически попадает в корзину, откуда её можно вернуть в общую таблицу. Но перед каждым изменением, будь то удаление или восстановление узла, не забывайте нажимать «Старт», чтобы инструмент пересчитал распределение PageRank. Таким образом с помощью инструмента вы не только анализируете распределение ссылочного веса, но и моделируете различные ситуации.
5. Динамика сумм PR
Крайне важно анализировать, как ссылочный вес распределяется в пределах сайта, теряется он или нет, и если теряется, то в каких объёмах. Именно такую информацию и можно получить с помощью панели «Динамика сумм PR».
Сумма PR — это сумма всех значений PR2 страниц, участвующих в расчёте.
Если сумма стремительно уменьшается, это означает, что ссылочный вес где-то теряется. Возможно, он просто передаётся на внешние ресурсы, а может, на сайте есть большое количество висячих узлов. Чтобы понять, как будет распределяться вес в пределах вашего сайта после их устранения, рекомендую воспользоваться кнопкой «Удалить висячие узлы», которая переместит их в корзину. Нажав «Старт», вы дадите команду программе пересчитать распределение ссылочного веса с учётом изменений и сможете понять, как будет распределяется ссылочный вес после устранения проблем.
Коротко о главном
Ссылочный вес не имеет прямого влияния на индексацию и ранжирование, но грамотное его распределение между страницами позволит вам:
- Лучше распределять краулинговый бюджет.
- Акцентировать внимание краулеров на определённых страницах, которые потенциально могут принести много трафика.
- Оценивать значимость страниц внутри вашего сайта.
Хотели бы узнать больше о PageRank или других функциях Netpeak Spider? Запишитесь на бесплатную демонстрацию! А если возник какой-либо вопрос — обращайтесь в наш чат техподдержки, мы всегда рады помочь!
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider



