Internal PageRank from A to Z
Use Cases

This article answers common questions from our users:
- What is the internal PageRank? What is it for?
- What benefit can be obtained from the optimized internal link equity distribution?
- How is it calculated?
- Which type of links are considered? Are duplicate links taken into account?
- 1. Intro to PageRank Сoncept
- 2. Math Component of PageRank
- 3. Why Did Google Remove The Public PR Score And Is There A Replacement For It?
- 4. What Do SEO Specialists Tell Us About PR?
- 5. The ‘Internal PageRank Calculation‘ Tool in Netpeak Spider: What Internal Linking Issues It Spots
- 6. Working With the Main Table
- 7. Dynamics of PR Amounts
- In a Nutshell
To get access to Netpeak Spider, you just need to sign up, download and launch the program 😉
Sign Up and Download Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the one most suitable for you.
1. Intro to PageRank Сoncept
When the Internet wasn’t as it is now, people believed that a database, containing information about all available resources of the network, i.e. ‘Search Index’, would be able to easily and rapidly find any necessary information. They were right. However, it wasn’t enough to get qualitative results that would be relevant to users’ queries.
So it was necessary to implement such an algorithm that would allow not only finding results according to users’ queries but also assessing the quality of the obtained results. Larry Page and Sergey Brin created such an algorithm, and it is called PageRank.
They were inspired by the way how scientists assess the ‘importance’ of scientific works according to the number of other scientific articles referring to them. So they took this concept and applied it to web documents, tracking links between pages. If we imagine that links represent recommendations, then the more links a page gets, the more important it is considered. It helped to learn the priority of some page over the others and arrange the list of results from most relevant to less relevant. This concept was so effective than eventually became a base for search engine known as Google.
Of course, now Google uses more complicated ranking factors and nobody knows them exactly. Specialists can only guess and follow Google guidance to rank better. If you want to dig deeper, check out a fresh survey by Rand Fishkin who asked specialists about their opinion on ranking factors.
Netpeak Spider uses the same concept when calculating the PageRank, but, unlike Google, the PageRank is calculating inside a website. That is why it is called internal PageRank.
Internal PageRank represents the significance or ‘popularity’ of any page within a certain site depending on the number and quality of internal pages linked to it. This estimation is also known as link weight (or link equity). When a page links to a different one, it passes part of its link weight to that page. Of course, the link should be placed inside the <body> block and not contain any disallowing directives. The more link weight a page gets, the more important it becomes. So search engine robots will visit them more frequently than pages with less link weight. In a nutshell, the concentration of link weight on certain pages show robots the most important ones that deserve more attention because website traffic depends mostly on them.
2. Math Component of PageRank
To find out how many link weight the page A gets, it is necessary to apply some math calculations. They are carried out step by step and each step is called an iteration.
Each iteration, except the zero one, applies the same formula. But before moving on to the formula analysis, let's answer the quite logical question: ‘Why the calculation is carried out several times and how many iterations are necessary?’.
The point is, the PR value can be calculated only recursively. It means, to calculate PR of a certain page, it is necessary to calculate it for its incoming links, incoming links of incoming links, and so on. It seems like an endless algorithm at first glance, but it’s not. On the zero iteration, representing a non-recursive branch, each page has the same PR that equals 1/N where N is the number of pages that take part in the calculation.
Thus, we get extremely rough approximation where pages are equally important to each other without taking into account their actual relations.
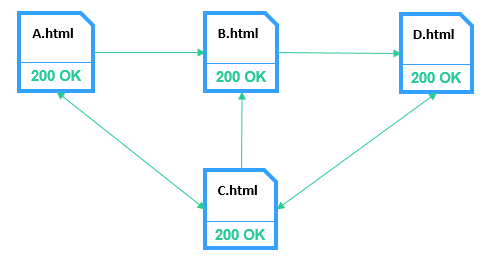
Starting from the first iteration, the algorithm takes into account the real relations between the pages.
To make it possible, the following formula is applied:
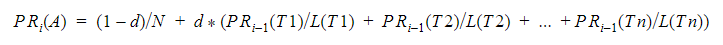
The value of PR calculated by this formula can be interpreted as a probability that a random user will visit this page. It follows that PageRank can be considered as a model of user behavior. It is assumed that there is a ‘random user’ who visits a web page and continues clicking on links without clicking back. This is the concept presented in the original scientific article about PageRank.
The formula contains the following components:
- A – a node (page), calculated at the moment
- i – an iteration number getting values from 0 to N
- T1, T2, …, Tn – unique incoming links of the A page
- L(T1), L(T2),..., L(Tn) — number of unique outgoing links of pages T1, T2, …, Tn
- d – damping coefficient representing the probability for each page that the ‘random surfer’ will get bored and request another random page. It is accepted to consider as damping coefficient value 0.85 according to recommendations from developers of the given algorithm. The remained value in 0.15 is a probability that the user will not follow the links further and will close a tab of a browser.
Each iteration gives more accurate value, and PR is calculated until the discrepancy between iterations will be almost unnoticeable. According to our research, 15 iterations are enough to get a quite precise result, and that’s why this number of iterations is set by default in the program.
Since version 3.0, Netpeak Spider takes into account another formula that was published in this article:
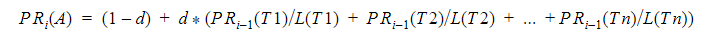
Now in the ‘Internal PageRank calculation’ tool, you can analyze both the first and the second variant of PR. To avoid confusion between the two formulas, I’ll denote the value of PR according to the first formula as PR1, and according to the second formula – PR2.
The second formula allows you to learn a bit more details about the page than the first one:
- if PR2 > 1,0 → a page gets more link equity than receives (optimal for landing pages)
- if PR2 = 1,0 → a page gets approximately the same amount of link equity as it receives
- if PR2 < 1,0 → a page gives more link equity than receives (optimal for less necessary pages)
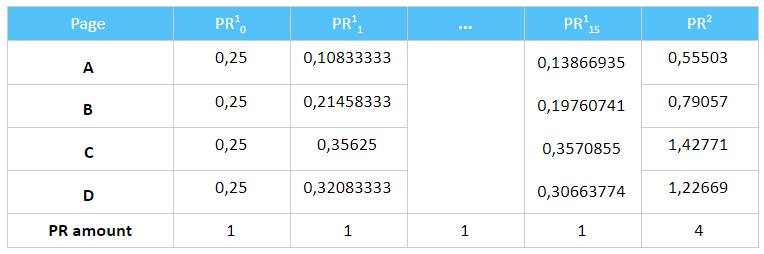
According to the results from the table, we can see that the page С gets more link weight than other pages and page A gets the least.
In the ideal case, the PR amount for all pages on each iteration has the same value and equals to 1 if it’s PR1 and equals to N if it’s PR2.
However, in the case of a real site, the situation is different. The sum of weights on the zero iteration may not coincide with the sum on the last iteration, because there are always links to external resources or pages that do not pass the link weight further – dead ends. Having links to external pages is an absolutely normal situation, but the dead ends are harmful, so pay more attention to them.
3. Why Did Google Remove The Public PR Score And Is There A Replacement For It?
At some point, Google began telling website creators that they could ‘boost’ their PageRank by buying links. This resulted in the market flooding with bogus buys and people trying to spam other sites with their links at every turn. This didn’t reflect very well on Google, as you can imagine.
So Google got rid of this ability, and it was eventually removed from the Google toolbar sometime around 2010. This official removal meant that other people didn’t have access to Google’s PageRank scores, although Google itself still ranks and uses these scores, along with other qualitative and quantitative data.
There’s no other numerical indicator that could replace PageRank, but many modern services calculate their own scores for website quality.
4. What Do SEO Specialists Tell Us About PR?
Plenty of Internet ‘experts’ out there claimed that PageRank was Google’s secret weapon. Not everyone agreed, though, and plenty of industry leaders took a different approach.
Jonathan Tang, a search engineer and Google patent inventor, was one of the dissenters. He said, ‘The [comments] about the search and click-through data being important are closer [to being true], but I suspect that if you made that public, you still wouldn’t have an effective Google competitor.’ In other words, Google has plenty of other tricks up its sleeve besides PageRank, searching, and link-clicking, although its ranking system is still one to model.
When Google’s patent for PageRank wasn’t renewed, many were taken aback. There was a new patent on the horizon, though. Bill Slawski analyzed the new patent, which dealt with seed sites in seed sets. These seed sites had to be reliable as well as diverse. They required connection to other sites and several valid links to other sources. These seed sites would serve as hubs from which other sites would form.
In The Anatomy of a Large-Scale Hypertextual Web Search Engine, Brin and Page mention how Google specifically produces high-quality results. They say, ‘…it makes use of the link structure of the Web to calculate a quality ranking for each web page… The citation graph of the Web is an important resource that has largely gone unused in existing web search engines.’ PageRank is what made Google special.
Read more → Pagerank Calculator
5. The ‘Internal PageRank Calculation‘ Tool in Netpeak Spider: What Internal Linking Issues It Spots
Using the ‘Internal PageRank Calculation‘ tool, you can learn how the link weight is distributed within the website, which pages get an excessive amount of link weight, and which ones get the least or even ‘burn’ the link weight.
You can find the tool on the ‘Tools → Internal PageRank Calculation‘ or ‘Run → Internal PageRank Calculation‘ tabs.
The data inside the tool can be divided into the following blocks:
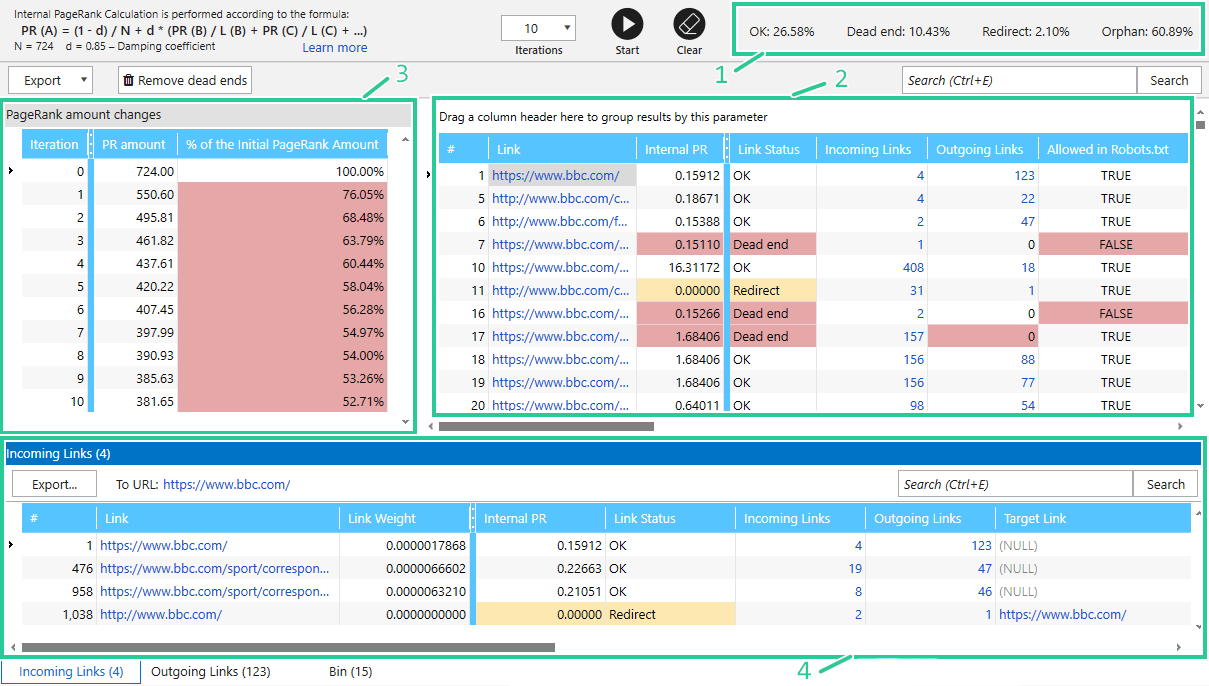
- Statistics on the link statuses
- The main table – shows all basic information on pages, including their weight, server response code, indexability data, number of incoming and outgoing links, etc.
- PR amount changes
- Tables with information about links + Bin
Please note that the reports provided on the links contain only unique links. If a page gets several links from the same page, only one of them will be taken into account, and external links are not taken into account in the calculation of the internal PageRank.
5.1. Link Status
Based on calculations, logically all links fall into 4 categories:
- OK
- Dead End
- Orphan Page
- Redirection
Let’s take a closer look at each category.
5.1.1. OK
HTML-pages with the ‘200 OK’ status code that contain outgoing links and can have:
- a noindex tag
- a canonical tag pointing to itself
- a refresh tag pointing to itself
5.1.2. Dead End
A Dead End is a page that gets link equity but does not pass it to other pages. So this page has some amount of incoming link weight but it goes nowhere. Why does it happen? How to find the root of the cause and fix the problem? Dead Ends might be caused due to a variety of reasons and I’ll tell about some of them.
5.1.2.1. Broken Pages
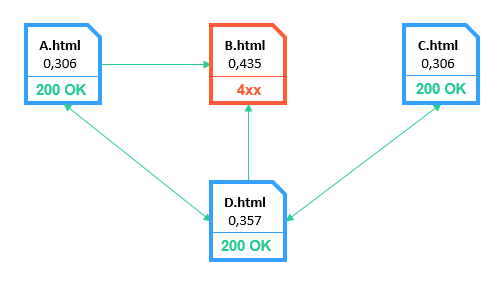
PR2 amount → 1,4
Link weight loss → 65%
This type is the most severe. Broken Pages negatively affect not only user experience, but also the indexing and ranking of the site.
To understand which pages contain links to broken ones, you need to use the report on incoming links in Netpeak Spider.
Learn more in the article → How to Find Broken Links with Netpeak Spider.
5.1.2.2. A Page is Hidden from Indexing by Certain Instructions or Rules
A page might be hidden from indexing in one of the ways:
- by a directive in robots.txt
- by the nofollow directive in X-Robots-Tag
- by the nofollow directive in Meta Robots
Learn more about directives:
1. In robots.txt: 'What Is Robots.txt, and How to Create It'.
2. In X-Robots-Tag: 'X-Robots-Tag in SEO Optimization'.
This type of dead ends is not critical and may occur at most sites. To find out if a page is compliant or not, check out such parameters as:
- Status Code
- Allowed in Robots.txt
- Meta Robots
- Canonical URL
- X-Robots-Tag
- Refresh
Pages that are hidden from indexing, except those with noindex, follow attributes, do not pass the link weight to the pages they refer to, and that causes the dead ends. Previously, to solve this problem, the rel=nofollow attribute was used. And such links were not taken into account by the algorithm. Now the weight is still passed despite the rel=nofollow attribute, but the recipient does not get it. So, in this case, the link weight is wasted.
If the dead end appears because of the non-indexability of the page, the most acceptable solution is to refer to non-indexed pages as little as possible or hide the links from search engines. This technique is called SEOhide.
5.1.2.3. 3xx Pages Hidden by Directives in robots.txt
Now I’ll talk about the pages that return 3xx server response code. It means that the requested page redirects to another one and it’s hidden for robots via directives in the robots.txt file. In this case, a search engine robot follows the link and gets to the blocked address. So we waste such resources as crawling budget and link weight. There are several solutions:
- Specify a direct link to the page without using a redirect
- Hide the initial redirect URL in the robots.txt file
5.1.2.4. Pages with 503 and 429 Response Codes
Although pages with 4xx and 5xx response codes belong to the same category of pages called ‘broken pages’. They may have different roots of cause.
Codes 5xx may appear in cases of unsuccessful requests caused by the server fault. It means that the page exists but, for any reason, a server has failed to show it or the special algorithm preventing DDoS-attack on a server has worked.
Crawling site on the big speed is perceived by servers as DDoS-attack, therefore corresponding protection on a server may be turned on. In such cases, the requested page often returns either 503 or 429 response codes and considered a dead end.
It is recommended to recrawl pages after some time using 1 thread. Sometimes, you have to use a proxy, because the site may temporarily put your IP in its blacklist and not return any information about the pages.
5.1.3. Orphan
An orphan page does not receive any link weight at all due to the lack of incoming links passing it.
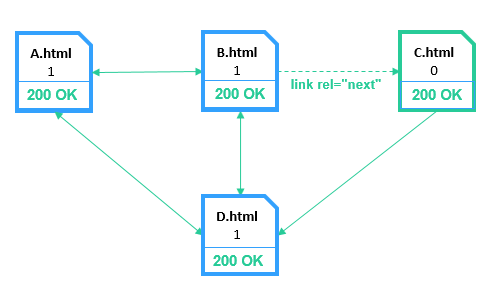
Such a page may appear when:
- All pages link to the current one via the ‘link‘ tag (except Canonical and Refresh). This type of link does not pass the link weight of the page as it is a service link.
- The program has not found any links between the analyzed pages. This situation occurs when crawling your own list of URLs or downloaded from the sitemap.
- The page receives links only from incompliant pages when crawling a website without obeying the indexation instructions (robots.txt, canonical, refresh, X-Robots-Tag, meta robots, and nofollow link attribute).
Keep in mind that orphans do not always mean an error. The program only notifies the user that such pages are on the site. An orphan page may be a service page, which should not be in the index. However, if this is not the case, it is necessary to correct this situation immediately and create at least 10 internal links to it to pass some link weight. Otherwise, the search robot will consider it unimportant and it will not reach high positions.
5.1.4. Redirect
A page with the ‘Redirect’ status is any page that returns a 3xx server response code that redirects a user or a search robot to another page with a 200 OK server response code and passes its full link weight to it.
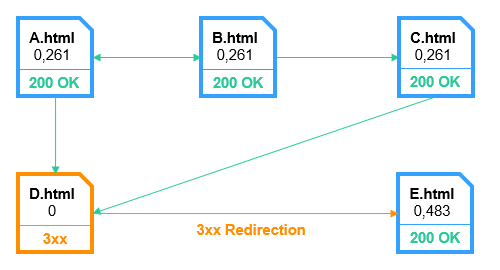
This category also includes:
- 2xx pages with a Canonical tag pointing to another page
- 2xx pages with Refresh tag pointing to another page
This is due to the fact that such pages are merged to those that are referenced by Refresh or Canonical, so the link weight is fully passed to them as in the situation with the redirection. That is why, in terms of link weight distribution, it can be considered as a redirection.
Read more → Internal pagerank checker
6. Working With the Main Table
The main table contains the information about the PR number of incoming and outgoing links, content type and indexing directives for all pages that take part in the calculation.
There are several features that can help you to simplify and make the link analysis more effective.
6.1. Ordering
The data in the table can be easily sorted both in ascending and descending order. For example, you can sort in ascending or descending order the PR value, so you can quickly determine which page gets the most weight, and which page gets the least.
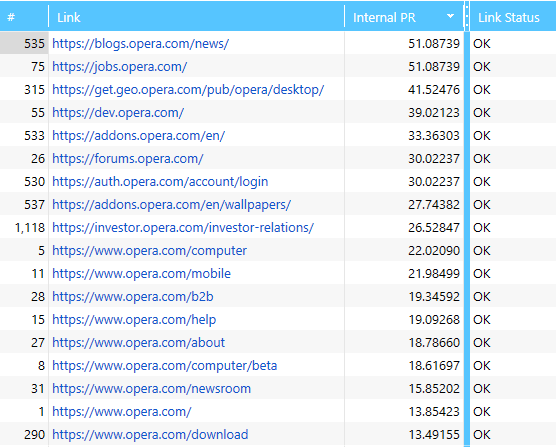
6.2. Grouping
The data can be not only sorted but also grouped by any parameter. To do this, grab the title of the necessary column and drag it up. For example, you can group the data by the status of the link:
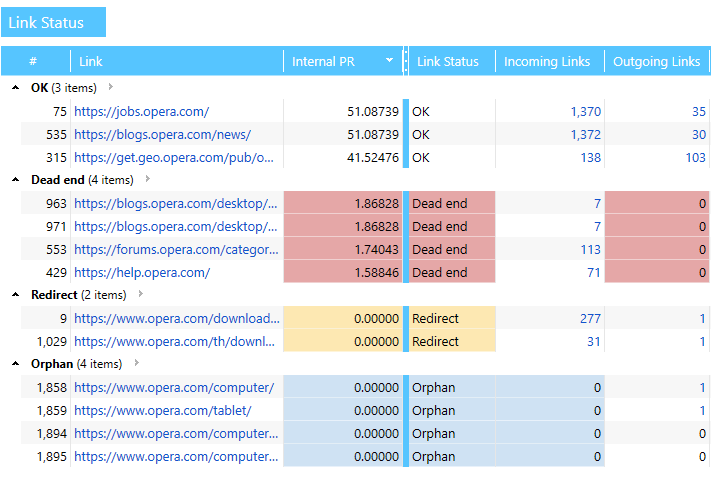
Additionally, the tool allows you to remove pages. This helps you simulate and understand how the link weight will be distributed if you implement any changes on the site, without making any real changes.
When removing, the link is automatically sent to the bin. It can be returned back to the main table if it’s necessary. But before making any change, either deleting or restoring a page, don't forget to click on ‘Start’ to recalculate the PageRank.
To sum up, the tool helps you not only analyze the link weight distribution but also simulate different situations.
7. Dynamics of PR Amounts
It is extremely important to analyze how the link juice is distributed throughout the site, whether it is lost or not, and if lost, how much. You can get this information at the ‘PageRank amount changes‘ panel.
The sum of PR is the sum of all PR2 values of pages involved in the calculation.
If the amount is rapidly decreasing, it means that the link equity is ‘burned‘ somewhere. Perhaps it is passed to external URLs, or maybe there are a lot of dead ends on the site. To understand how the weight will be distributed after they are removed, we recommend you to use the ‘Remove dead ends’ button, which will move them to the bin. Use the ‘Start‘ button to make the program recalculate the distribution of link juice after changes. So you can understand how the link juice will be distributed after fixing the problems.
In a Nutshell
Internal PageRank has no direct impact on the indexing and ranking, but if it is distributed within website pages correctly, it will allow you to:
- control the crawling budget
- focus crawlers attention on particular pages, which can potentially bring a lot of traffic
- evaluate the importance of pages within your site
Want to learn more about PageRank or other Netpeak Spider features? Sign up for a free webinar! On our webinars even the most advanced SEOs learn new cases about website promotion.
Digging This Use Case? Let's Discuss Netpeak Spider Perks in Person



