How Netpeak Spider Boosts Automated QA-testing and Finds Bugs and Errors. Case of Depositphotos
Use Cases

The bigger the website, the more problems with internal optimization you might encounter, even in the basic stuff.
When working with projects that have quite a long legacy like Depositphotos, which has millions of pages, it becomes difficult to manage and check it. We’re positive about that because Netpeak Spider helps us find the bugs that popped up despite constant automated QA-testing.
The case will be beneficial for those people who want to monitor issues regularly, especially when the Product Department dramatically increases the amount of vulnerabilities.
Choose the List of Pages You Are Going to Track
At this stage, it is critical to focus on the type and category templates of pages, not their quantity. For example, your website contains the following page types:
- landing pages,
- categories,
- subcategories,
- webpages with portfolio,
- product pages
Then, most likely, you had experience with the bulk release of these pages for indexing or doing it right after the product team are done from their side. Often it happens on Friday at about 6-7 pm (for some mysterious reason), just so that the SEO specialist are not going to relax too much on Monday. And how could he notice the ranking dropping, if the ranking drop alert delivered to his inbox on the weekend?
If your website is multilingual, when choosing web pages for tracking, it is good to understand that you also need to include the pages of different top-priority languages.
For instance, we are tracking landing pages, product pages, categories, and subcategories in different languages: SP, FR, PT, EN. You might extend the list, but the processing of the pages will slow down, so better to keep only the most important groups.
Use Simultaneous Crawls in Multi-window Mode of Netpeak Spider
Inevitably, you will reach a point when bugs may spread out of your list of pages. Then it is advisable to open another window in Netpeak Spider and perform the casual slow website crawl using 2-10 threads. You can run more threads if your project can take the load.
During regular crawls, mostly we encounter issues with hreflangs:
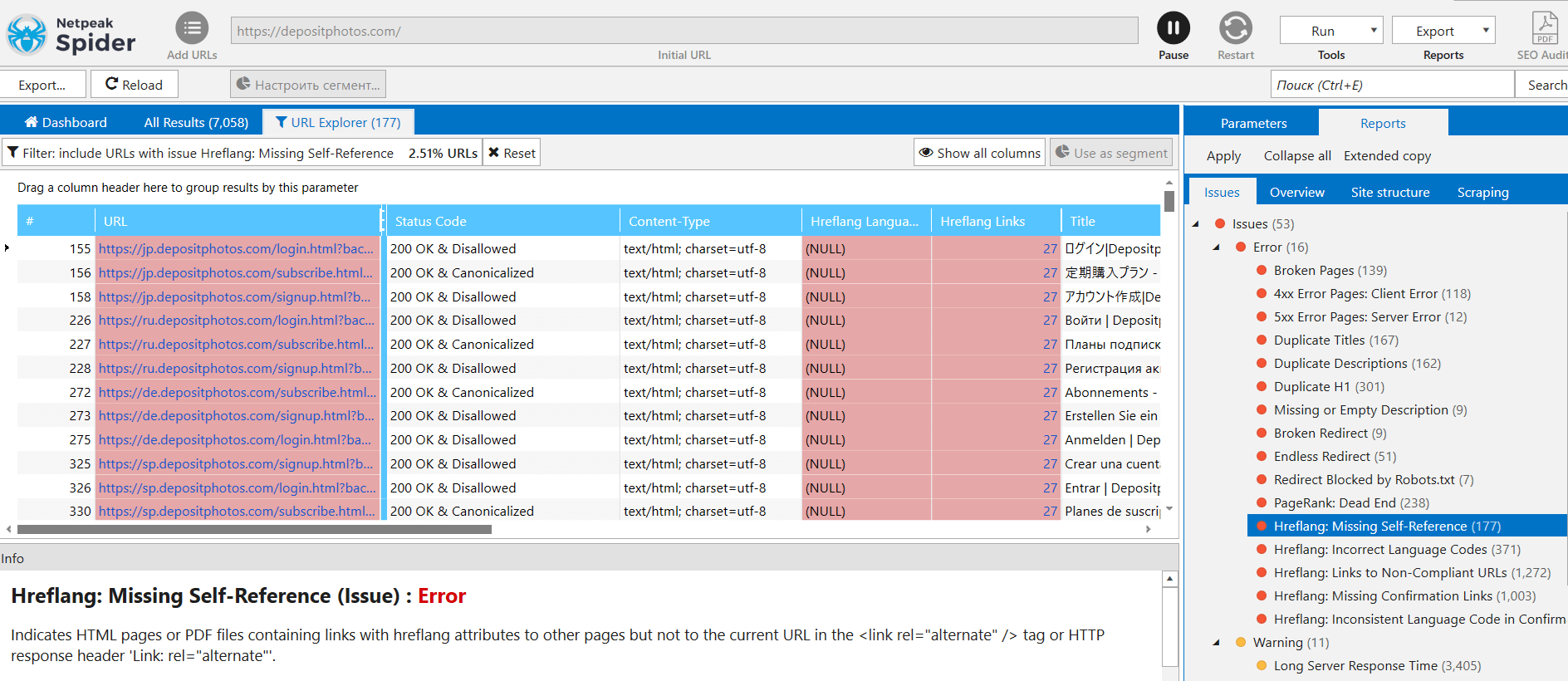
Indeed, as we can see, hreflangs are missing.
To get the data from the pages, we first need to upload the list of them. I prefer doing it manually:
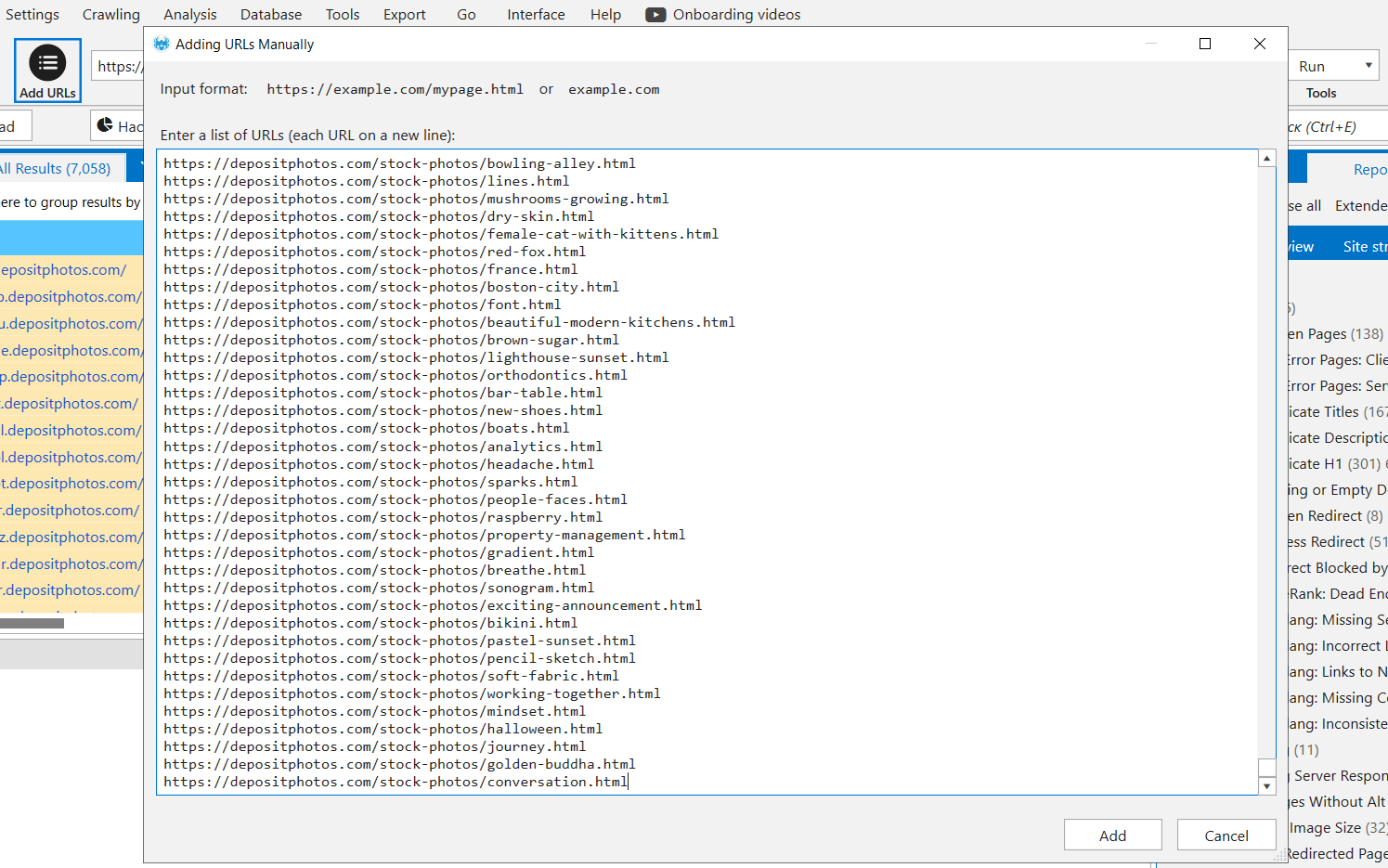
Next, I configure a specific User Agent settings, allowed for crawling by the website protection system. Then I decrease the number of threads so that the server has time to prepare responds. Otherwise, we will receive 503 codes.
What can be found when crawling the list of URLs?
I have created a 404 error pages filter and discovered that the Product Manager has deleted the landing page /crello.html, but the SEO department found out about it on the weekend.
Down the road, we have many other mistakes coming up.
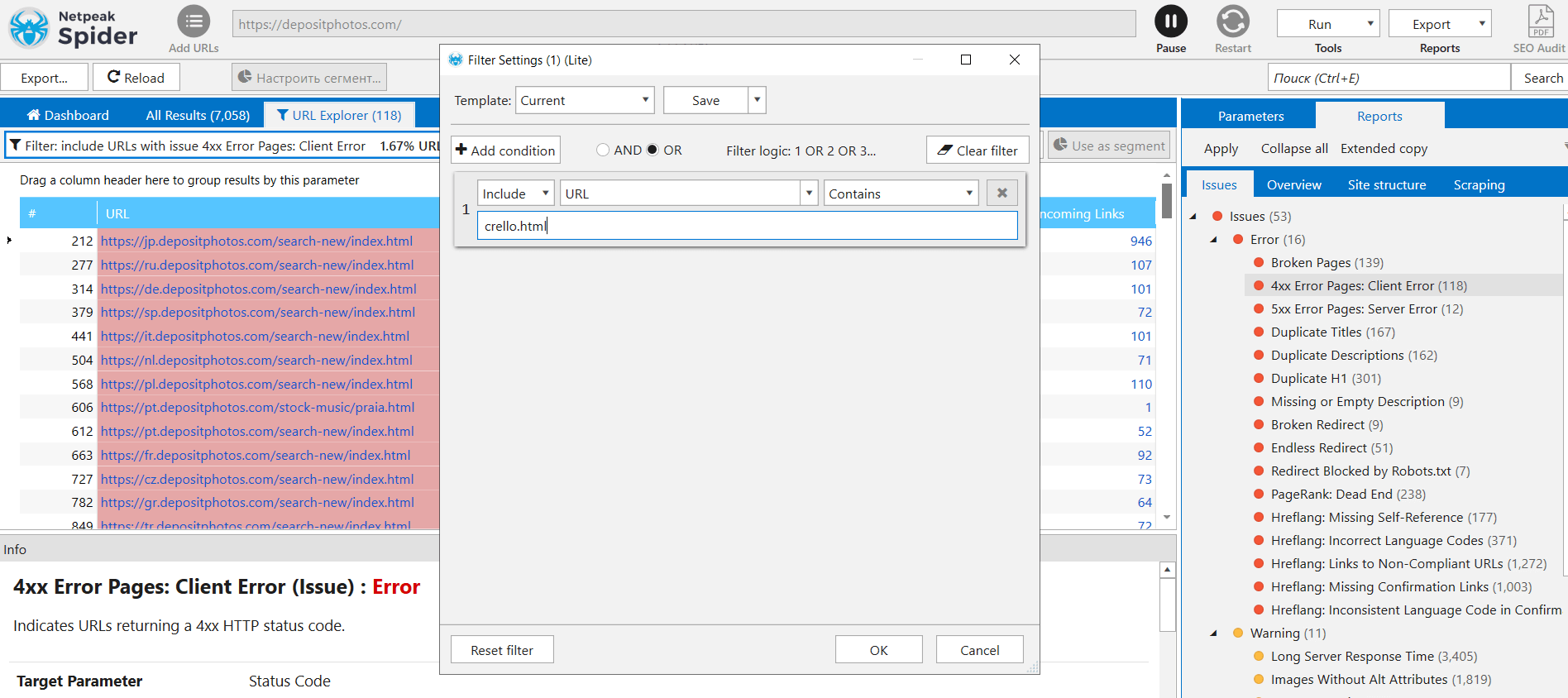
I choose to focus on the missing hreflangs. It is interesting to run an analysis mixed with Netpeak Checker to monitor the time when Googlebot cached a page and whether it indexed the changes.
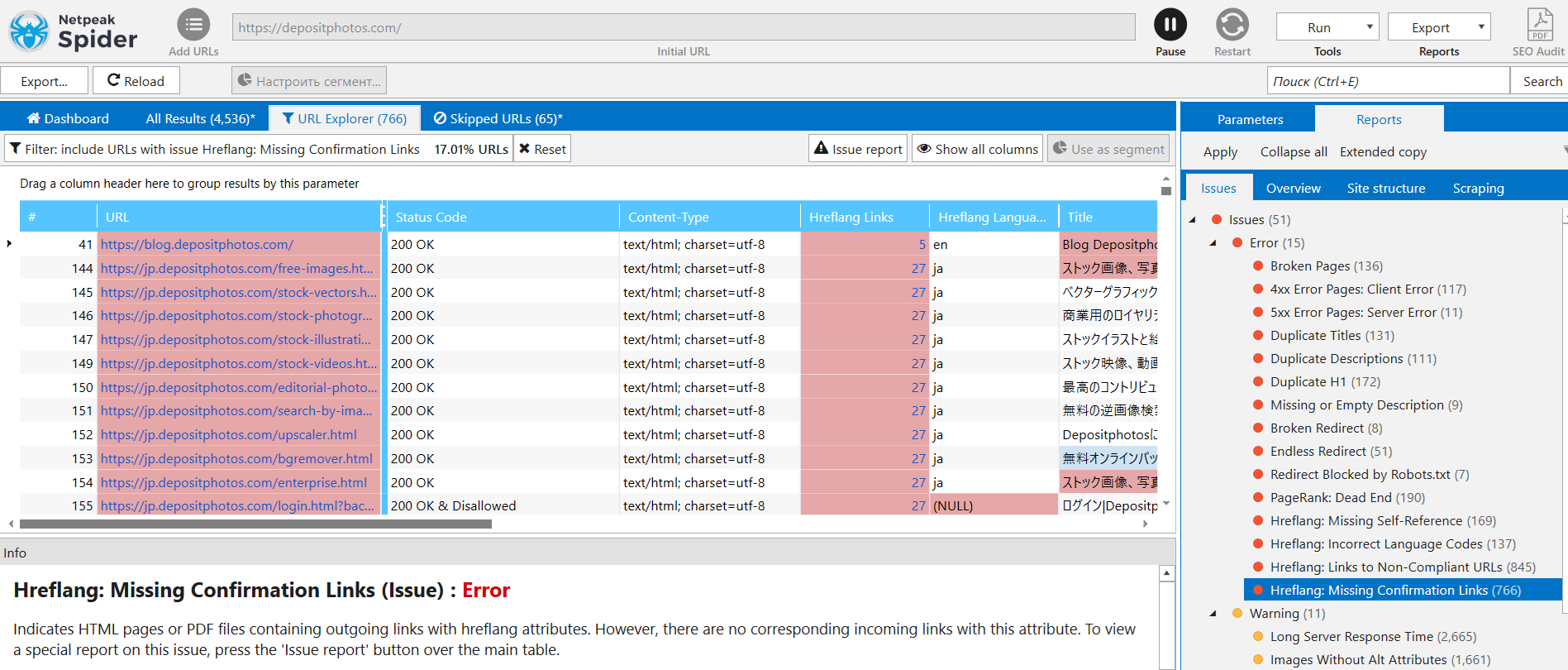
We take the list of the URLs from Netpeak Spider and launch retrieving of their indexing parameters and cache. Here are the results:
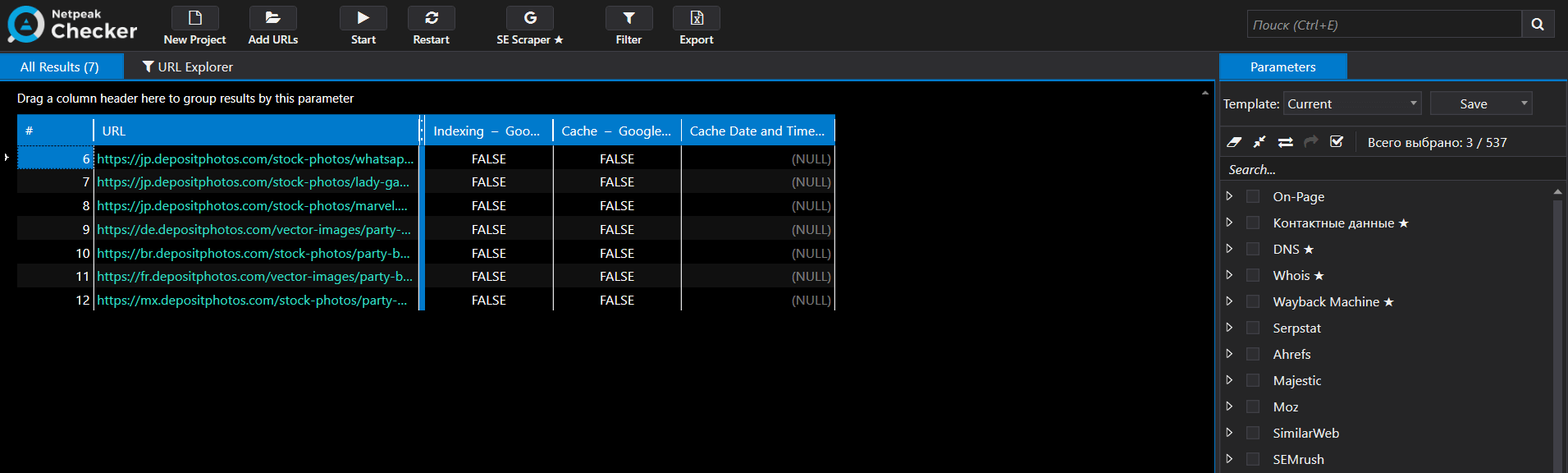
Without seeing the final results, I had already realized that there were troubles with indexing. Googlebot visited and cached the page, but it didn’t appear in the index.
Let’s open the webpage source code:
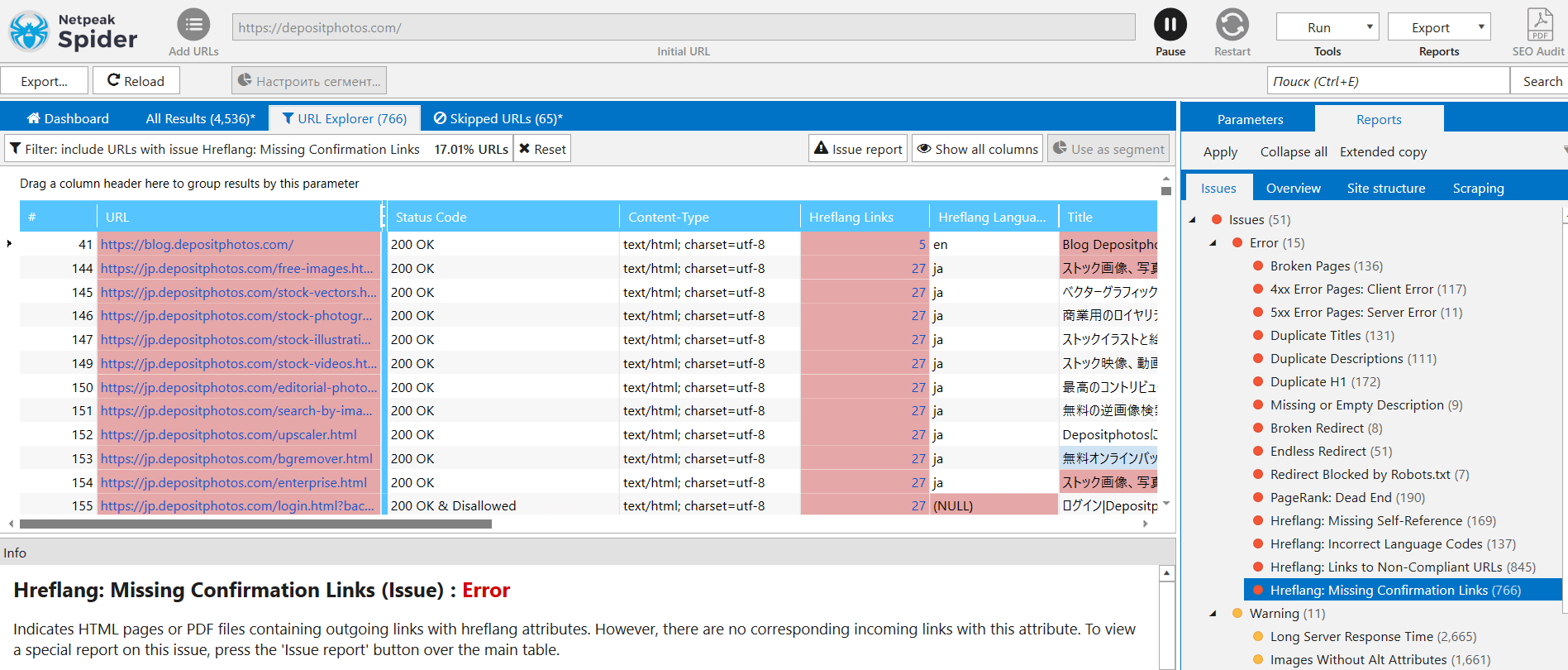
Hreflang contains a pt-br subdomain (which is not supposed to exist; there are separate PT and BR ones). Then we will check hreflang of each page:
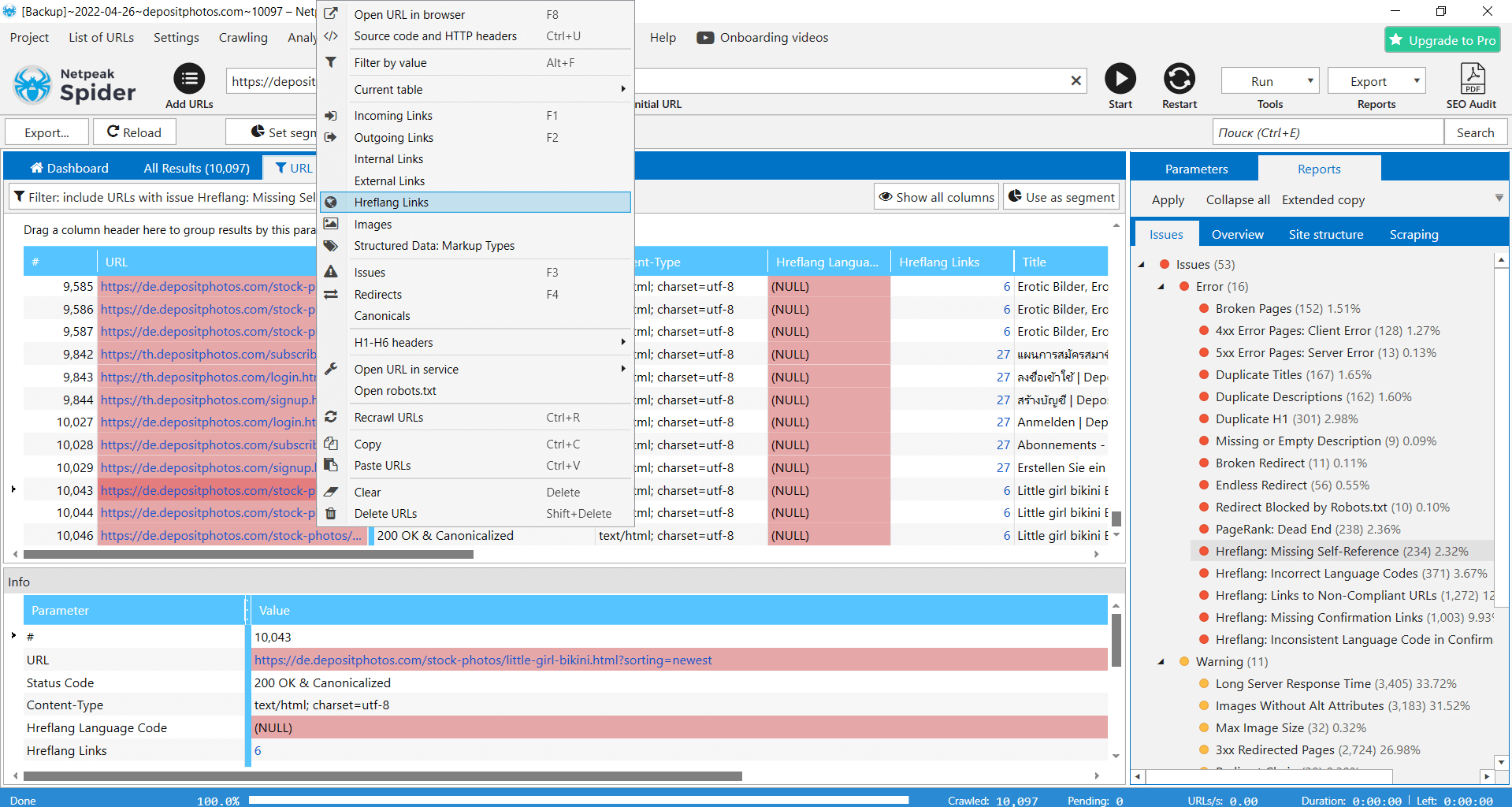
Apart from mysterious language versions, we also spot pages that don’t have a confirmation link, when page A has a language attribute to page B, but page B doesn’t:
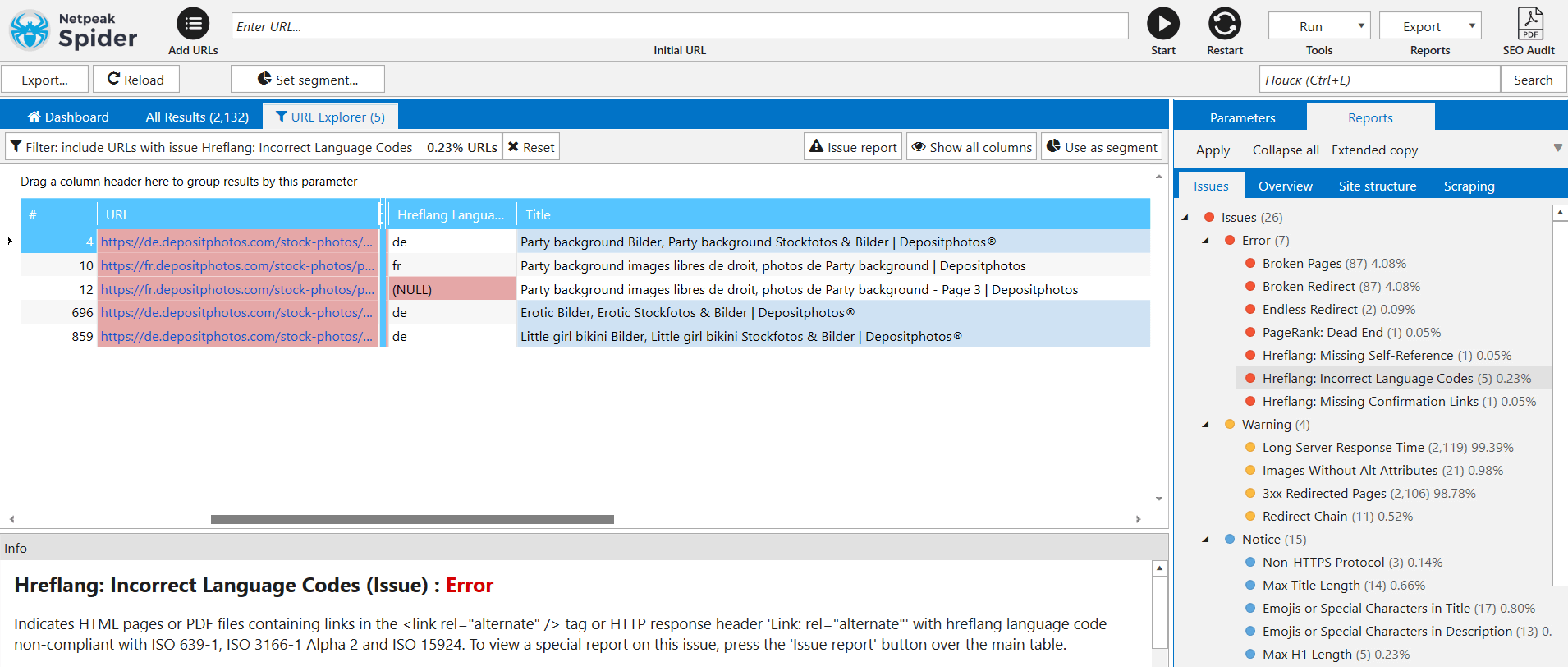
After that, select URLs of all hreflang language versions, and launch crawling for them again. But now pursue slightly different goals:
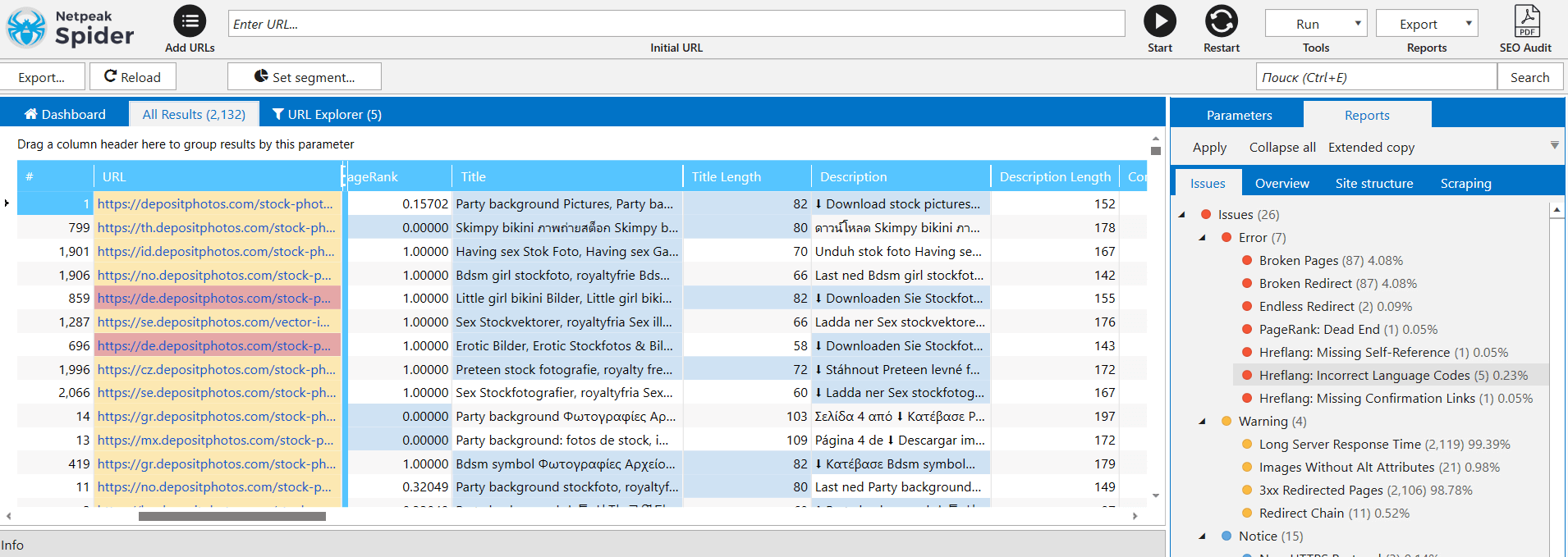
What do we see? Template for title/description tags is obviously out of whack because they differ from one another. What are the conclusions? Chances are, fixes led to database desynchronization. Probably there are some issues with the database and translation templates.
You can also notice problems with internal links. We meticulously manage them, and blank links anchors don’t do us any good:
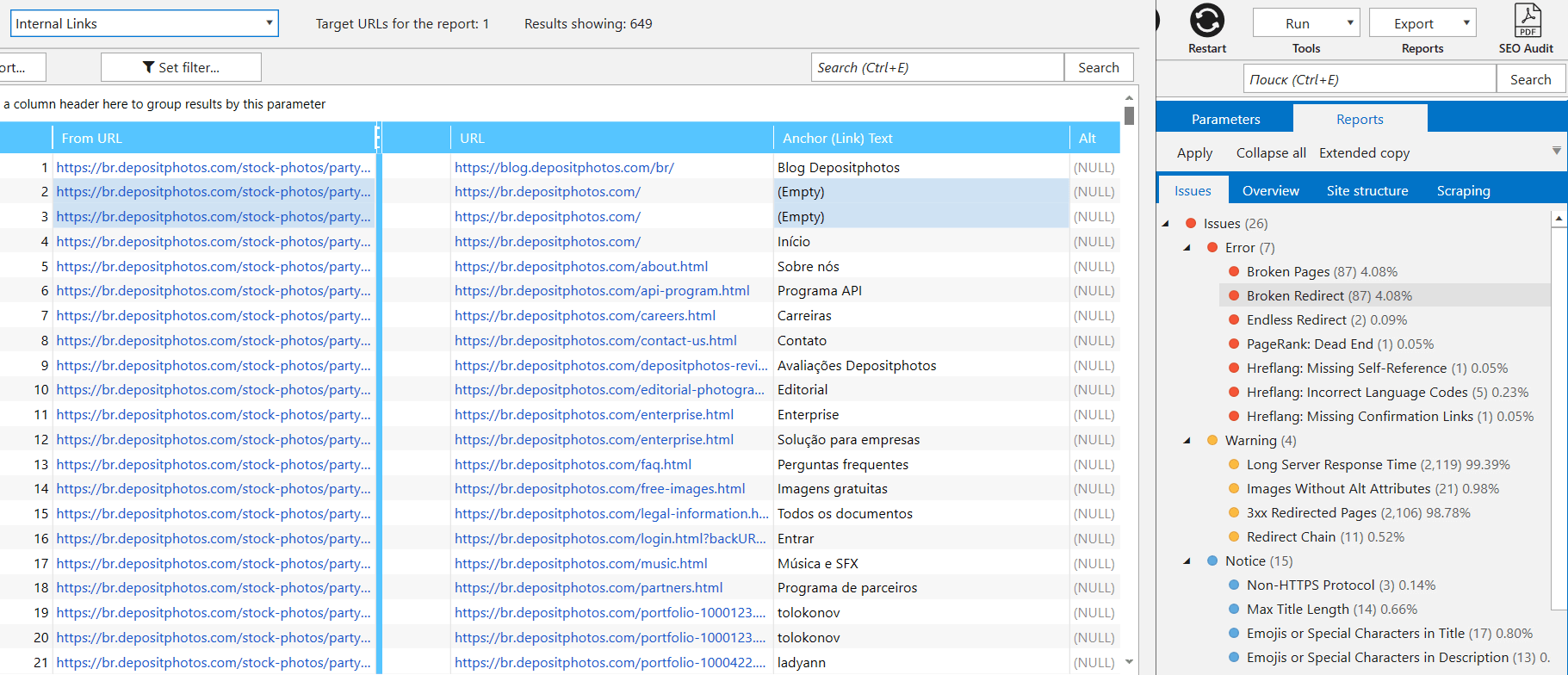
When a page has an empty anchor link, it’s either a picture or an error. That leads to a situation when a robot will start crawling it, which will pass the link weight but also will create a redundant path for the bot. As a result, the bot might waste the crawling budget.
But if we look at the matter from an internal link weight distribution point of view, then links without anchors, as the Depositphotos SEO team tested, pass the weight much less than those described with text (if a link is not a picture).
Further actions
You can analyze data from limitless perspectives. The best decision is to create hotfixes. It’s advisable to implement a habit of doing similar to described above maneuvers when working on big websites. It will help quickly identify similar bugs, and their elimination can at least secure organic traffic to your project from decreasing.
It’s crucial to understand a cause leading to specific errors and to deal with this cause. In the case of UGC, things become much more interesting, as normal registered users are way more dangerous than all the Product Managers combined. We have to check what they write and what Google ‘sees’ on a daily basis.
When handling big data sets, you shouldn’t always process millions of pages at once. Yes, it’s practical and informative. But, sometimes, the only thing you need to do to identify issues lying on the surface is launch Netpeak Spider while having a cup of coffee, then choke on it after looking at the data, and then fix them.
If Netpeak Spider could process logs, I bet that the health of SEO specialists would suffer even further damage.


