How to Parse Prices from Online Stores Using Netpeak Spider
Use Cases

Price scrapping and other forms of parsing data is time-consuming and labor-intensive. Yet, no large-scale competitive analysis can work out well without it. With Netpeak Spider, you can simplify and automate this process by extracting and exporting all the necessary information using the "Custom Search" feature.
In this article, we will show you how to collect, filter, and export competitors' prices on the case of parsing prices from the skay.ua online store.
In fact, custom search possibilities aren't limited to scraping prices. You can parse a lot of other data, except those protected or closed in the site's code.
How does custom search work
Custom Search is a feature available in Netpeak Spider that allows you to search a website and retrieve the necessary data from web pages, including fare scraping opportunities. A total of 4 types of searches are available in the program:
- Contains ("search only");
- RegExp ("search and extract");
- CSS selector ("search and extract");
- XPath ("search and extract").
We will use XPath, which is usually suitable for parsing data from online stores. However, other types of search can also be used depending on the site's structure.
How to determine the required element to search
To start parsing and scraping prices, you should first determine the code of the element of the searched data (in our case - prices).
To get the element code, you need to:
- Open the product page;
- Highlight the price;
- Right-click on it and click "Show element code" (or "Inspect" if you are using the English interface);
- In the opened window, find the element responsible for the price (it will be highlighted);
- Right-click on it and select "Copy" → "Copy XPath."
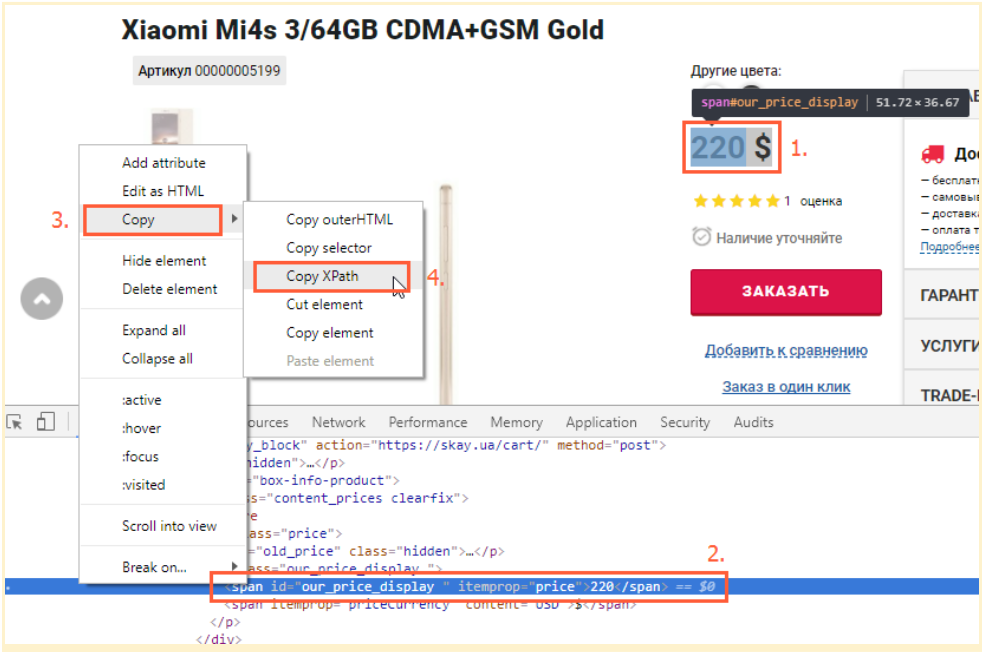
Usually, it is enough to copy XPath from the code of one product page to sparse prices of the whole store or a certain category, but only if all cards have the same template.
How to launch price scanning with Netpeak Spider

Now, let's find out how Netpeak Spider enables scraping prices from websites. Follow the steps below and learn how to do it.
Custom search setup
You can run a custom search in a few quick steps:
- In the quick settings next to the address bar, select the "Site-wide" scanning mode.
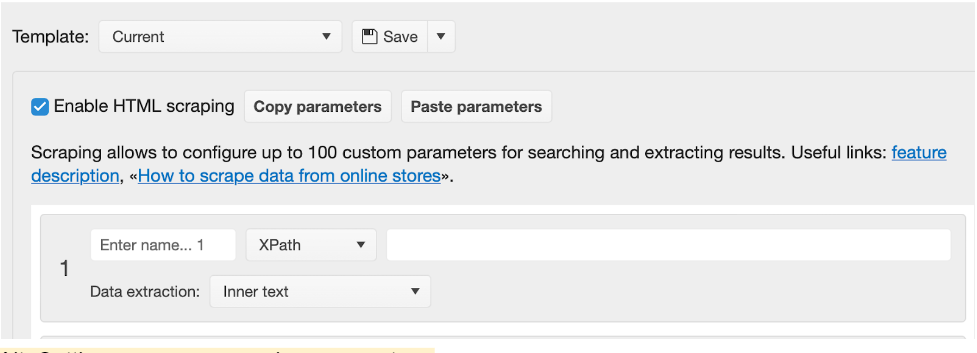
- In the scraping settings, go to the "Search" section.
- Turn on "Use Custom Search."
- Select the "XPath" search mode and insert the code of the element we found earlier. The data extraction mode is "Internal Text." If you need to sparse several different types of data besides the main price (old price, discount amount, article, quantity, etc.), you can add one more parallel search thread. The maximum number of concurrent search threads is 15.
- Give a name to each of the searches to avoid confusion in the final parsing results. We have only one search thread, and it is responsible for extracting price data.
- Go to the "Rules" tab.
Configuring rules and crawling
When we need all the products on a given site or simply can't select a particular category from them (some specific feature does not characterize the addresses of the product pages we need and do not include a single element for all of them), we set the parameters of the custom search described in section 3.1 and start crawling the entire site with the program's default settings.
If the URLs on the scanned site are site.com/category/goods or site.com/category/goods, we can use a set of custom rules.
In the current search, we are interested in Xiaomi products, all addresses of which begin with skay.ua/xiaomi/.

"Rules" in "Scan Settings" allow us to add to the table of scanning results only those pages that meet the specified conditions (in our case - a certain format: skay.ua/xiaomi/article-goods).
This can be done in two ways: including only pages of a certain type or, on the contrary, excluding a certain type of goods that we are not interested in. Here's how to set it up:
- Choose "Include" or "Exclude".
- Choose the match type (in our case, "begins with").
- Insert the part of the URL repeated in all products of the category we are interested in (or, on the contrary, unwanted).
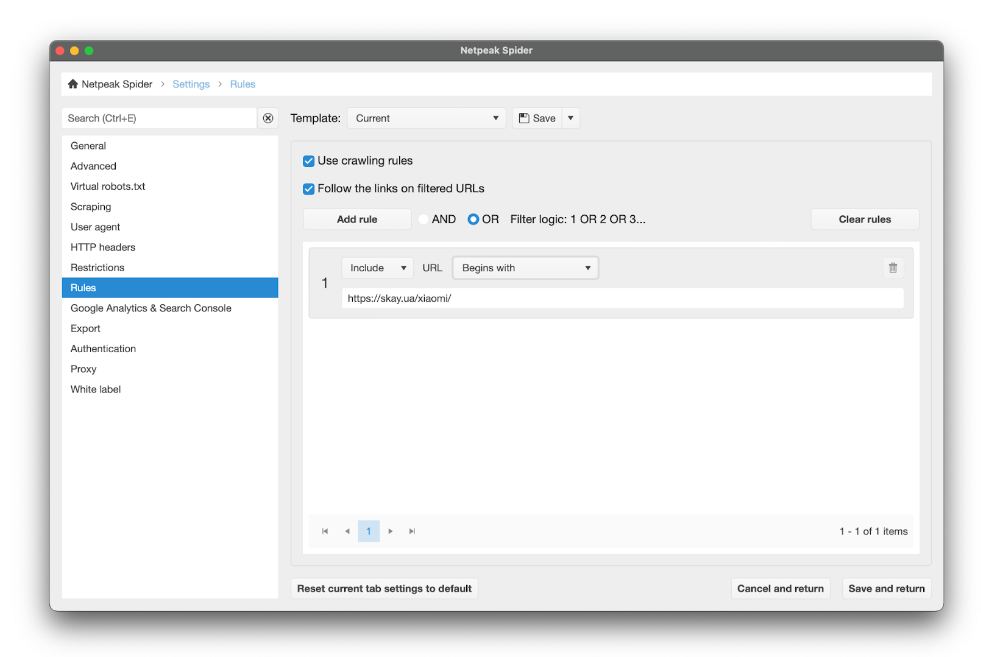
If you specify several rules at once, you can choose the "and"/"or" logic so that the crawler filters pages by one of the rules or by all of them at once.
- Apply the settings and launch our price scrapper.
If you have set a number of rules for crawling, Netpeak Spider will display only those pages that meet the specified conditions in the search results.
The scan results' far right column (it's called XPath by default, but we named it "Price") contains the search data for the specified data. This column displays the number of values of the searched item on each individual URL (1 product = 1 value). The total number of prices found is in the sidebar → "Search" tab.
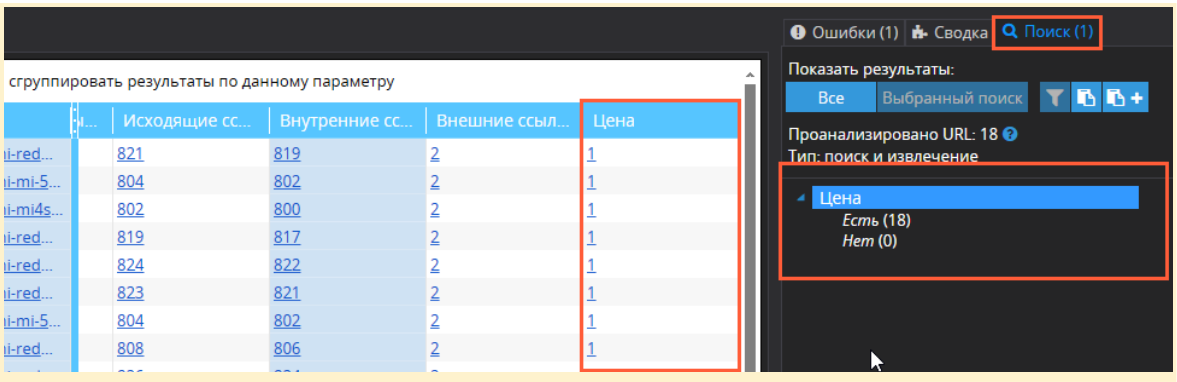
Separately, we would like to draw your attention to the fact that disabling image analysis in the main scan settings will be better. Sometimes, image addresses and names are the same as product addresses, so that they can get caught in your filter, and the list of pages will have to be cleaned.
Netpeak Spider has a free version with no time limit. This version lets you parse sites using up to 100 parsing and price-scrapping conditions! Many other basic features of the program are also available in the Freemium version.
To start using the free version of Netpeak Spider, simply sign up, download the app, and you're good to go! 😉
Also, right after registration, you can test all paid functionality, compare all our tariffs, and choose the right one for you.
Exporting the received data
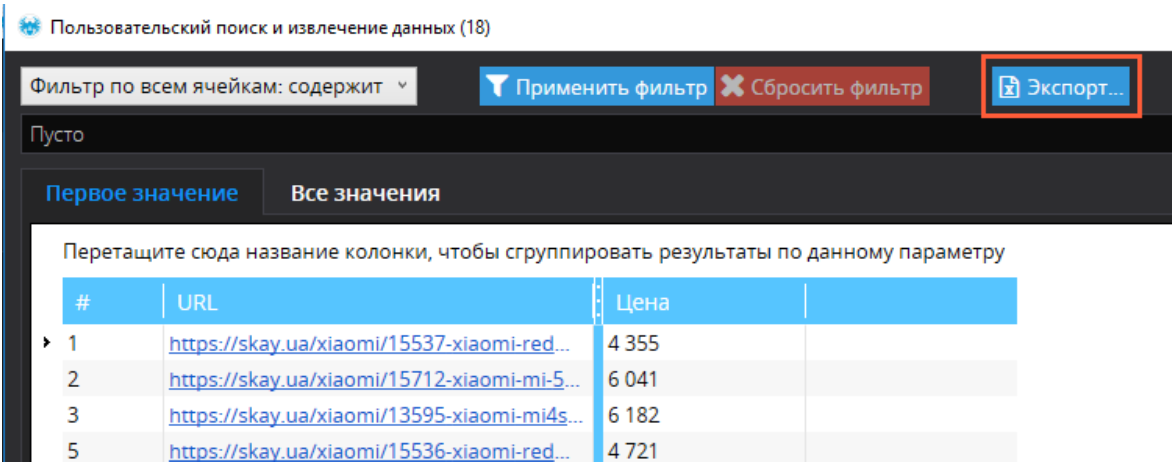
In order to get a table containing only page addresses and price data, follow the steps below:
- Open the "Search" tab in the panel on the right.
- Under the "Show results" line, select "All."
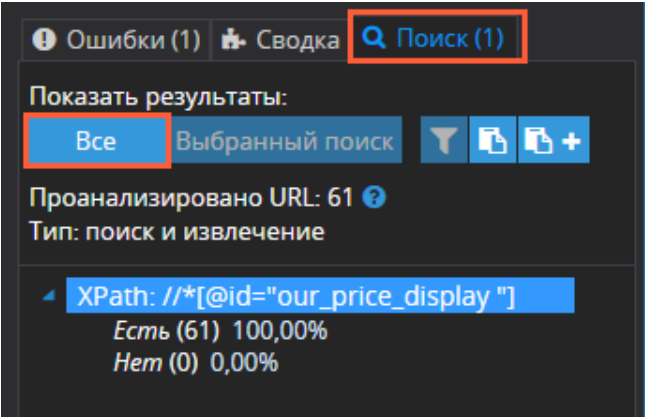
- Filter the retrieved data if necessary.
- Click "Export" to save the table.
Check URLs for SEO parameters with Netpeak Checker
Running regular website checkups can help you enhance the efficiency of any SEO-related task, including scraping prices from other pages. One of the most helpful tools in this essence is Netpeak Checker.
This powerful, multi-functional app provides dozens of helpful SEO features and enables extra integrations with various dedicated services. Here's a brief overview of what else you can do via Netpeak Checker:
Integration with 25 other services to analyze 450+ parameters
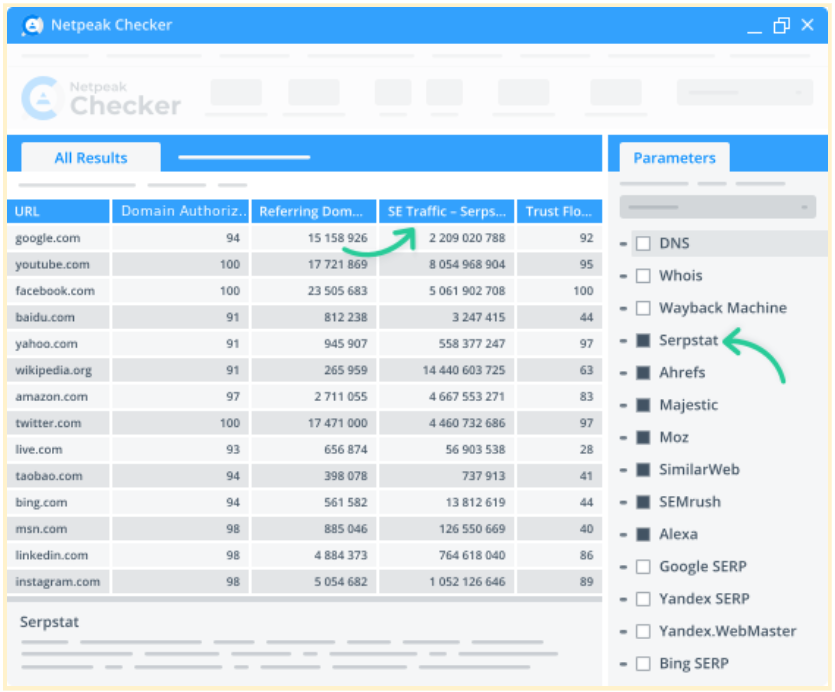
Netpeak Checker enables integrations with 25+ SEO services: Moz, SimilarWeb, Ahrefs, Serpstat, Google Analytics, Google Seach Console, etc.
50+ on-page parameters
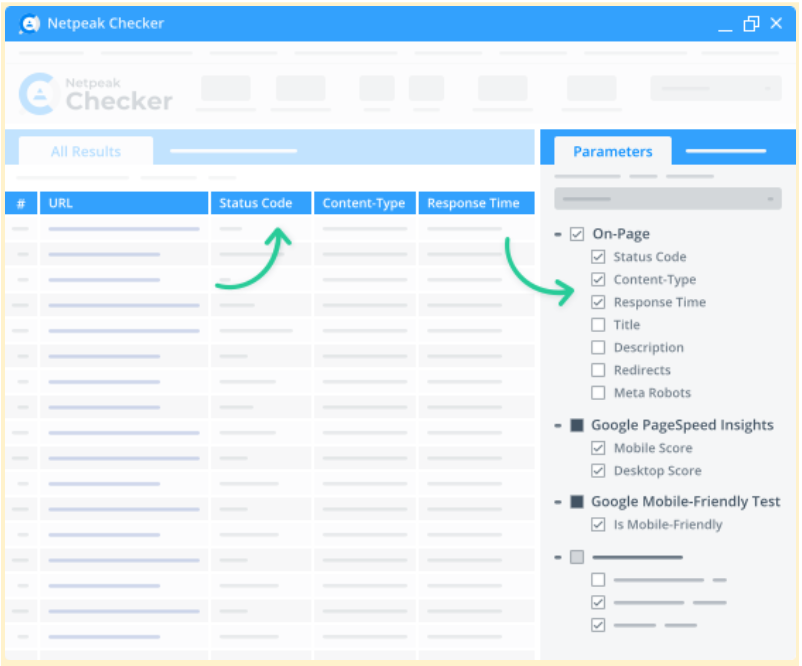
Netpeak Checker displays research results via the interactive dashboard. The metrics you can monitor include redirects, response time, status codes, title, mobile-friendliness, etc. All you have to do is choose the required stats for a target URL and hit "Start."
Website traffic estimation
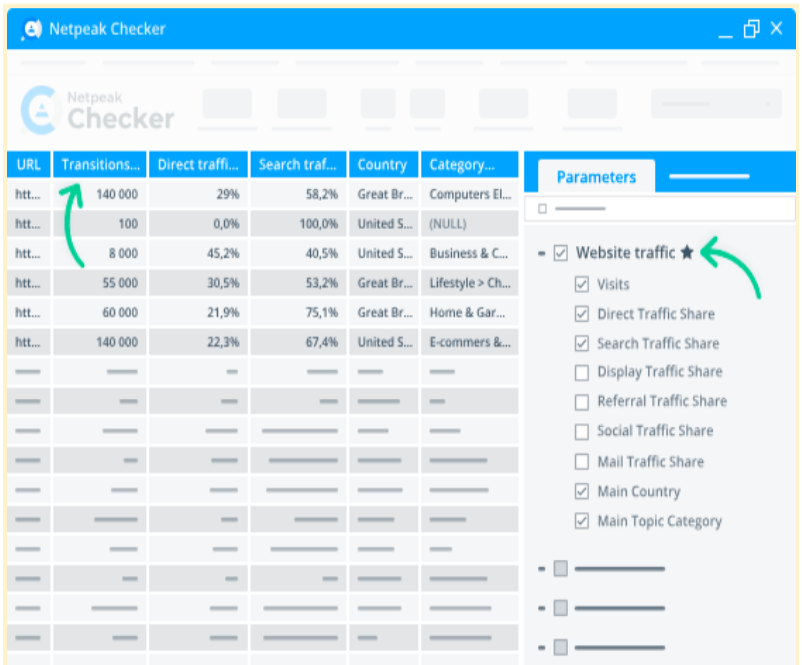
Netpeak Checker shows the traffic volumes on a target page, potential link-building donors’ share ratios, and traffic by location. It also displays what types of traffic are prevailing on a selected page (e.g., search, organic, direct, mail, social, etc.).
Batch Core Web Vitals checkup
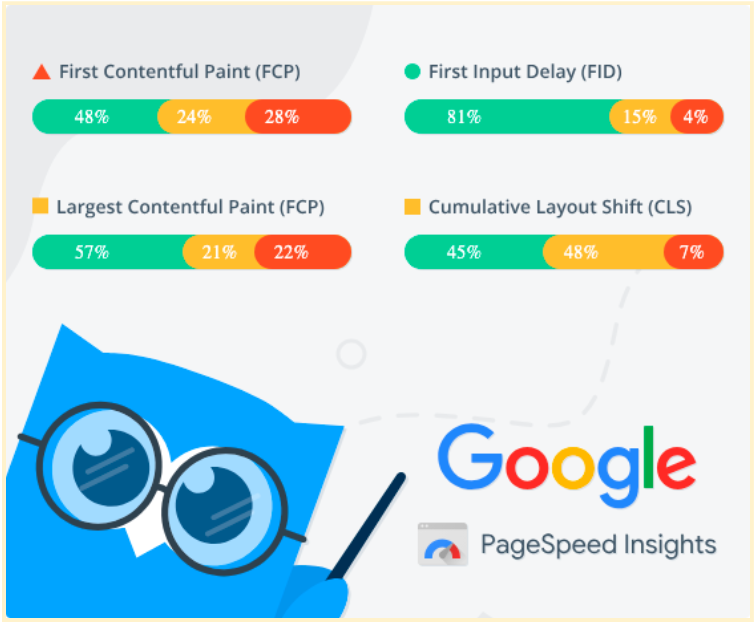
You can retrieve data from Google PageSpeed Insights to monitor your website's load speed, responsiveness, and visual stability.
Integration with Google Drive & Sheets

Connect your Google Drive account to our app to promptly export any report to Google Sheets and easily share them anytime.
Final thoughts
In order to scrape prices or other data from competitor sites, you'll have to do the following:
- Define the element to be parsed (in our case, the price).
- Copy the XPath.
- Set the custom search settings.
- Set the rules for selective scanning.
- Run the scan.
- Export the retrieved data.
The method described above can extract and export many other types of data, including prices. This functionality can be useful for Internet marketers, content specialists, SEO specialists, webmasters, sales managers, and other specialists.
Do you use this functionality in your work? If yes, for what purpose?
Share your experience in the comments and ask questions related to user search: we will be happy to answer them :)


