How to Improve Your Crawl Budget
How to

Search traffic is commonly referred to as the best free traffic source available. You create great, optimized content, it gets crawled by search engines and eventually starts to rank. The entire process is straightforward, and most people don't need to worry about the nuances of crawling a website. The question is, when should you start worrying about the way Google crawls your website?
That’s a good question. In this article, we'll explain the crawl budget basics, when and why it matters, and show you a few ways to improve it so it always indexes the right pages.
What is a crawl budget?
The crawl budget is the number of URLs on your website that Googlebot can crawl. There are two factors to consider when trying to understand your website’s crawl budget:
- The crawl rate limit, which is how quickly Google can crawl your website.
- The crawl demand, which is a measure of how important Google thinks your URLs are.
These factors, taken together, make up your crawl budget. If the crawl rate limit is set extremely high and the crawl demand is also high, then you may run into issues with server resource allocation. Intense Googlebot activity can create a poor user experience for your website visitors. It’s important to note that this shouldn’t be an issue if your website has less than 1,000 URLs available for crawling.
The crawl budget becomes important when you have a large website or one that generates a lot of URLs, such as an E-commerce store with a filtering search function.
Can crawl budget affect SEO?
Crawl budget isn’t a ranking factor for technical SEO.
However, if Googlebot stumbles upon crawl errors that prevent it from accessing and indexing your content, your pages will have trouble showing up in SERPs. At the same time, you don’t want Googlebots unstoppably crawling your site.
If you exceed the allocated crawling budget for your website, you may face slowdowns or system errors. This can lead to late or no page indexing at all, giving you lower rankings in return.
Google relies on many signals to realize where your page should be placed. Crawling helps direct whether your page shows up and has nothing to do with quality content.
How Google determines your site's crawl budget
Every website has a unique crawl budget managed by crawl demand and crawl limit. So, it’s essential to understand how they work. That said, let's unpack both parameters.
Crawl demand

Crawl demand shows how much Google wants to crawl your site. Two factors affect this demand: your site's popularity and staleness.
Popularity
Google prioritizes pages containing more backlinks or the ones driving more traffic. If users visit your website or link to it, Google will see that a website deserves more frequent crawls.
Backlinks help Google detect pages worth crawling. If Google detects that people are talking about your site, it would want to crawl it more to see why. The number of backlinks doesn’t matter — they only need to be relevant and come from trusted sources.
Staleness
Googlebot will not crawl your page if it has not been updated for a long time. However, if Google's algorithm detects a general site update, bots will increase the crawl budget for a limited period.
For example, a news website gets frequently crawled since it posts new content multiple times a day, meaning it has a high crawl demand.
There are also other actions that can send a about the changes to Google:
- Domain name change. When you change a website’s domain name, Google needs to update its index to be able to reflect the new URL. Thus, it'll crawl the website to understand the nature of a change and pass the ranking signals to the updated domain.
- URL structure changes. If you alter your site URL structure (e.g., by changing the directory hierarchy or removing / adding subdomains), Google’s bots will need to recrawl the pages to properly index the new URLs.
- Content updates. Significant changes to the website's content (e.g., rewriting most of your pages or adding new ones, removing outdated content, etc.) can draw the algorithm’s attention and make it recrawl your website.
- XML sitemap submission. Updating and resubmitting your XML sitemap to Google Search Console can inform the search engine of changes it needs to crawl. This can come in handy if you want to make sure Google promptly indexes new or updated pages.
Crawl rate limit
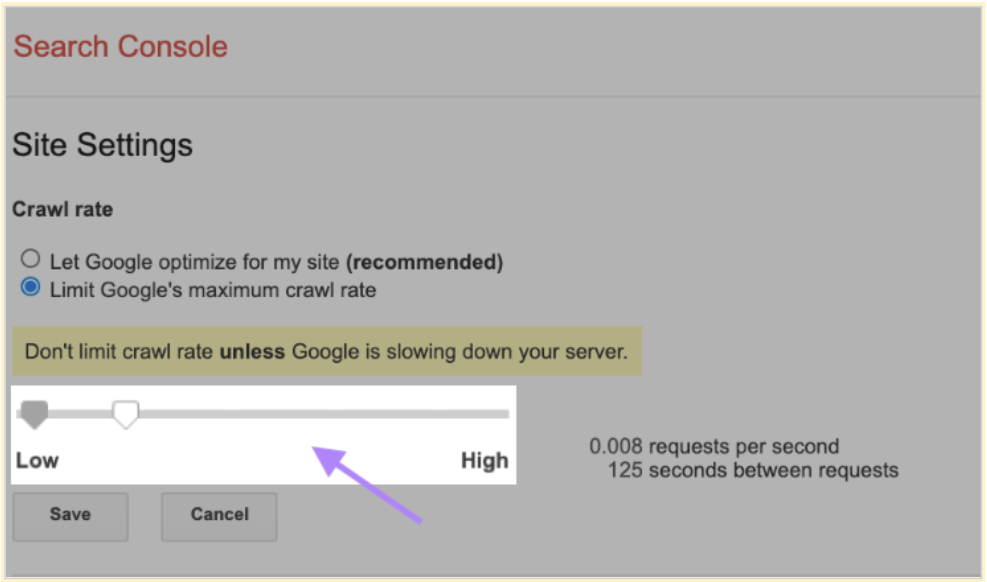
This metric determines how fast it takes the bot to access and download pages from your website to prepare the content for showing up in search results. This is how Google makes sure the crawling process doesn’t overload your servers.
If Google receives a quick response from your site, it will be able to increase the limit, giving it more crawling budget. However, if Google experiences server errors or if your site slows down, the limit will decrease, making it crawl your website less frequently.
How the crawling process works
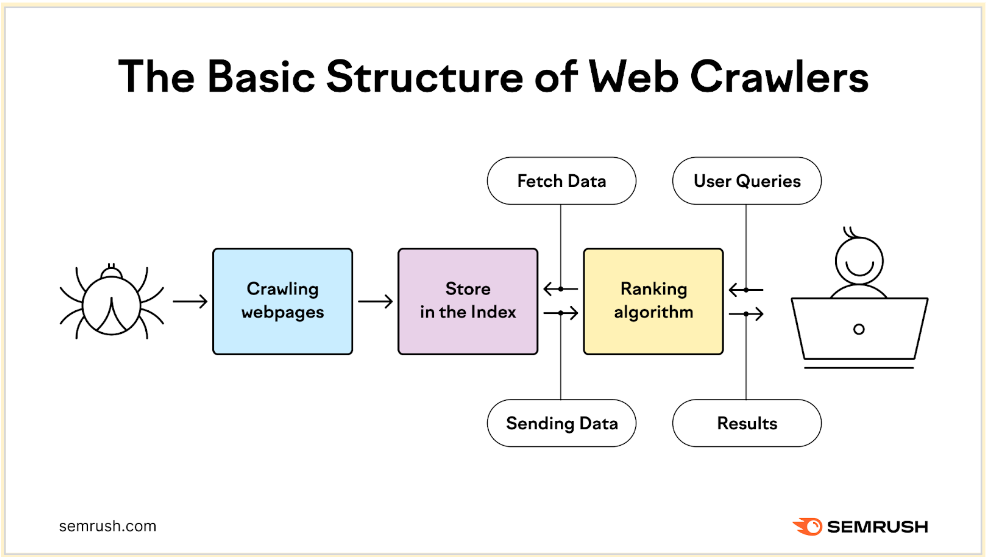
Website crawling utilizes bots to detect, crawl, analyze, and index web pages. This process is important as it helps provide users with the most relevant, high-quality search results.
The on-demand crawl begins with a list of web addresses from previous crawls and XML sitemaps provided by site owners. Then, Google makes crawlers visit these pages to read the information and follow links there. During this, the bot prioritizes the content based on crawl demand. At the same time, it needs to ensure the website can handle its server requests.
After that, it processes and passes the successfully crawled pages to Google for further indexing. Smaller websites are usually crawled more efficiently. For larger websites containing hundreds of URLs, Google has to prioritize when and what to crawl and decide on the amount of resources to dedicate.
How to check up on your crawling activity
You can track your crawl activity in Google Search Console, where you can see all the details regarding the crawl errors and crawl rate. All the data is gathered in the Crawl Stats Report.
This report helps you ensure Google can access and index your content, identify any known issues, and fix them before your website’s visibility declines. To access the Crawl Stats Report, log in to GSC and go to Settings.
There, you'll find the Summary page, where you should pay attention to the following elements:
- Over-time charts that reflect the crawl data in the past 90 days;
- Grouped crawl data that shows you information regarding the crawl requests;
- Host status that shows your site’s general availability and if Google can freely access it.
Best ways to improve your crawl budget
You don’t have control over Googlebot but you do have control over how it interacts with your website. A number of factors affect your SEO crawl budget. When they’re well-optimized, you can improve your overall crawl budget and make sure you've got the right pages indexed.
Speed up your website

This is something you should be doing regardless of the crawl budget. A faster website produces a better user experience for your visitors. Googlebot tries to do its work as quickly as possible without taking up too much server resources. If it notices a website is slowing down, it reduces the crawling process or stops it altogether. If that's the case, Googlebot can entirely skip essential pages.
There are a few quick ways to fix a slow website:

- Implement a CDN that will help Googlebot access resources faster by serving them from a location close to it.
- Compress files and images to make pages smaller and make them load more quickly.
- Invest in better hosting. It’s possible to make all the optimizations in the world but not see significant gains because of subpar hosting.
- Set up browser caching.
Make more in-depth content for important pages

It’s almost common knowledge by now that Google gives preference to more in-depth content. Its job is to show searchers the best content possible.
A longer piece of content containing images and other rich media is more likely to satisfy a searcher. Of course, it still needs to be good.
The higher the word count on a page, the more likely it is to be crawled and indexed. Thin pages, under 300 words, are indexed less than 20% of the time. There are many fixes for thin content, but a viable option is to no-index them entirely — especially when they’re not essential. For important content, make it longer and more detailed.
Remove infinite spaces

Infinite spaces are the elements on your website that can, technically, go on forever. For example, if you have a booking page with a calendar, a visitor can click the next button for as long as they want. With Googlebot, this is detrimental and consumes your crawl budget on unimportant pages or content.
To prevent this from occurring, use the robot.txt file to eliminate dynamic categories that can go on forever. Nofollow assets like a calendar and use the URL Parameters Tool provided by Google to format links so Googlebot can ignore unimportant ones properly.
Eliminate 404 errors
A 404 (broken page) error occurs when a server uses the 200 OK response code for a page that no longer exists. In reality, it’s supposed to send back a 404 Not Found response code.
The problem with 404 errors is that Googlebot attempts to crawl and index the page instead of portions of your website with unique content. Eventually, Googlebot will move on to another website, and your pages may not be indexed in a timely manner.
You can crawl your website with Netpeak Spider to detect soft 404 errors. If the tool detects them, you should either redirect them to the correct page or fix the response code the server returns. When finished, fetch the page as Google through search to make sure the changes have propagated.
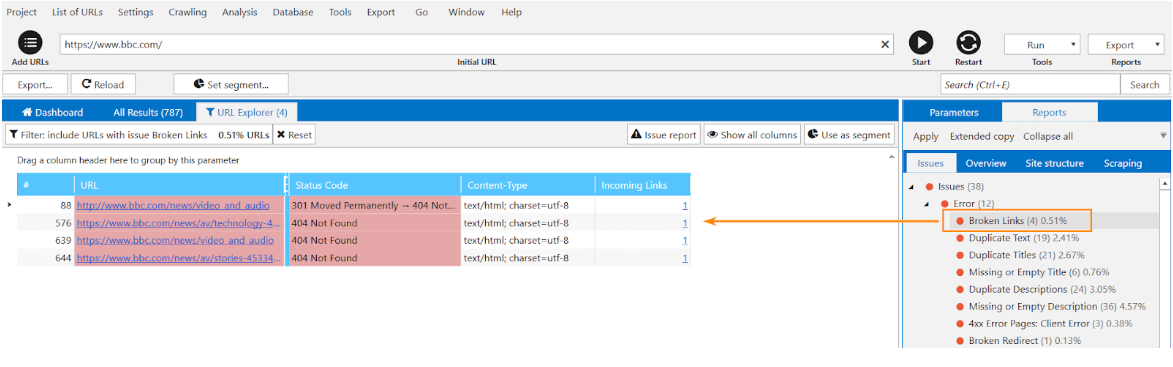
Even in the free version of Netpeak Spider crawler, you can check your website for broken pages and use other basic features, which are not limited by the term of use or the number of URLs that need to be analyzed.
To get access to free Netpeak Spider, you just need to sign up, download, and launch the program. 😉
Check URLs for SEO parameters with Netpeak Checker
Website checkups are essential to ensure your website's high performance. To help you achieve that, you should find a high-quality, powerful SEO tool that will cover your optimization needs. One of these apps is Netpeak Checker.
It offers a wide range of features and enables multiple integrations with other helpful services. Take a look at what this handy tool can offer you and sign up for a free trial to experience it all yourself:
Integration with 25 other services to analyze 450+ parameters
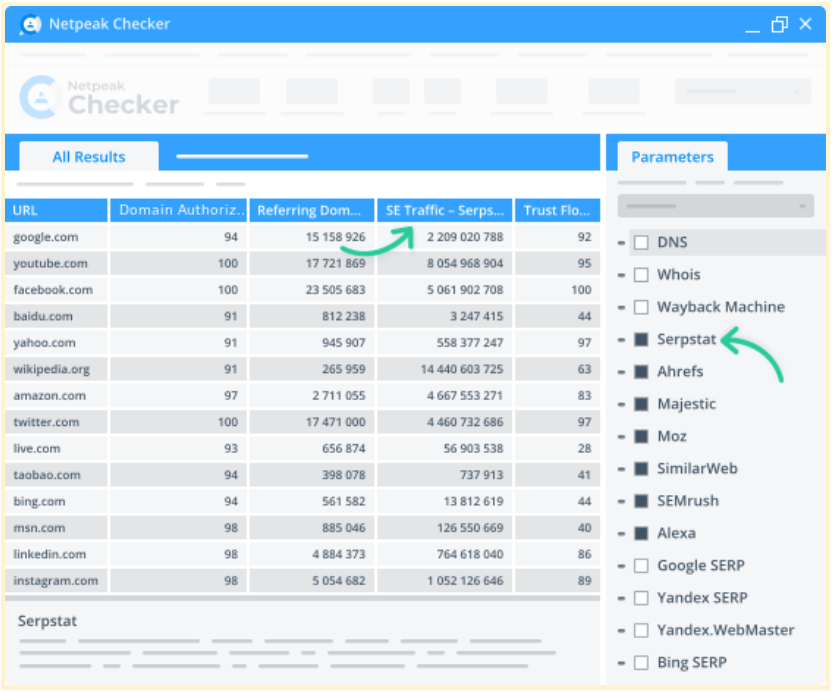
Netpeak Checker lets you integrate 25+ SEO-related services to gather more insights about the requested parameters. You can find Moz, SimilarWeb, Ahrefs, Serpstat, Google Analytics, and others among these services.
50+ on-page parameters
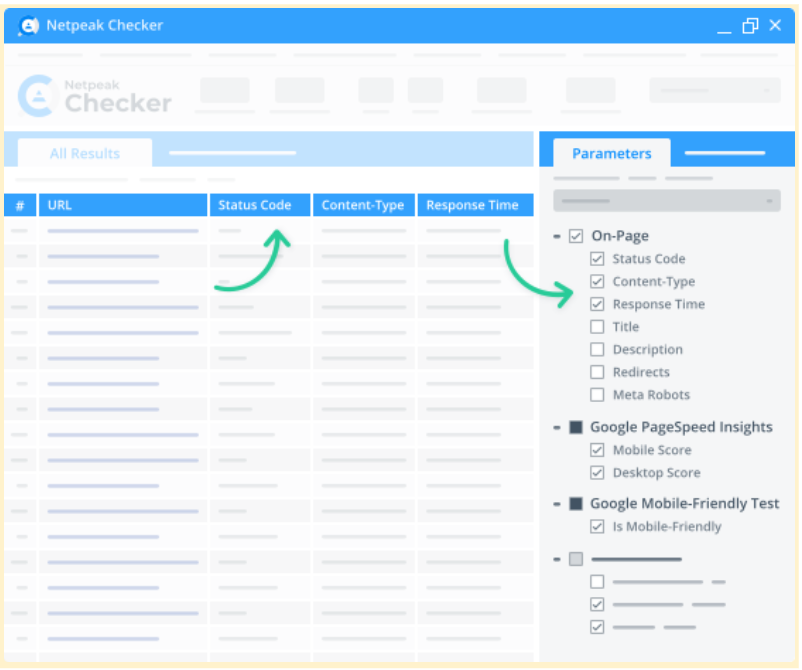
This app lists the essential on-page parameters in a convenient dashboard. These parameters include redirects, titles, response time, status codes, mobile-friendliness, and many others — just select the required ones and click "Start."
Contact data search
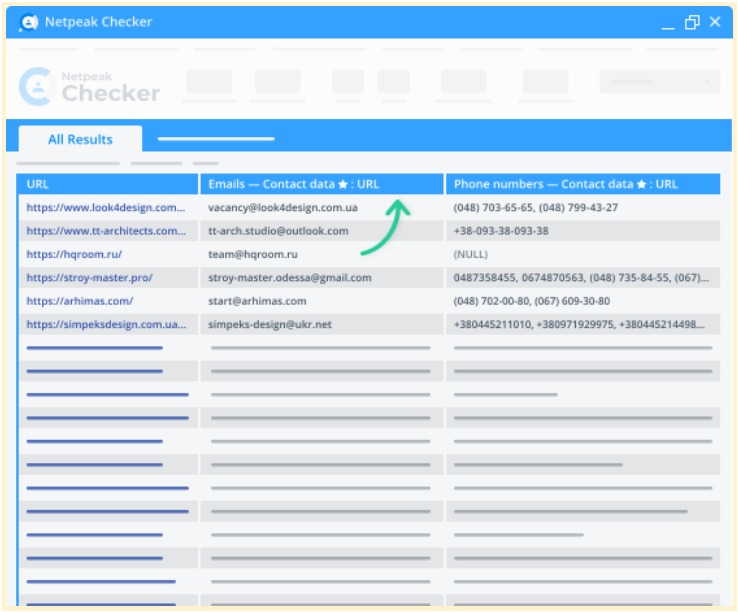
Our tool allows you to collect contact information from any website you need and use it as part of your SEO link-building strategy. Netpeak Checker will quickly show any available phone numbers or email addresses on a given website.
Website traffic estimation
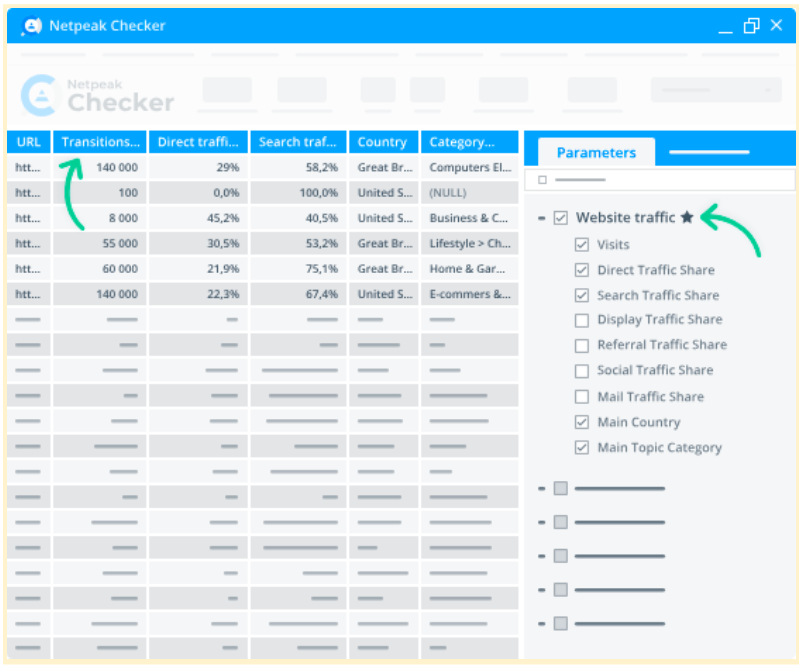
Netpeak Checker calculates the traffic on your and competitors' pages, potential link-building donors’ share ratios, and traffic by location, as well as shows critical category data. Moreover, you'll see what types of traffic prevail on your pages (search, organic, direct, mail, social, etc.).
Batch Core Web Vitals checkup
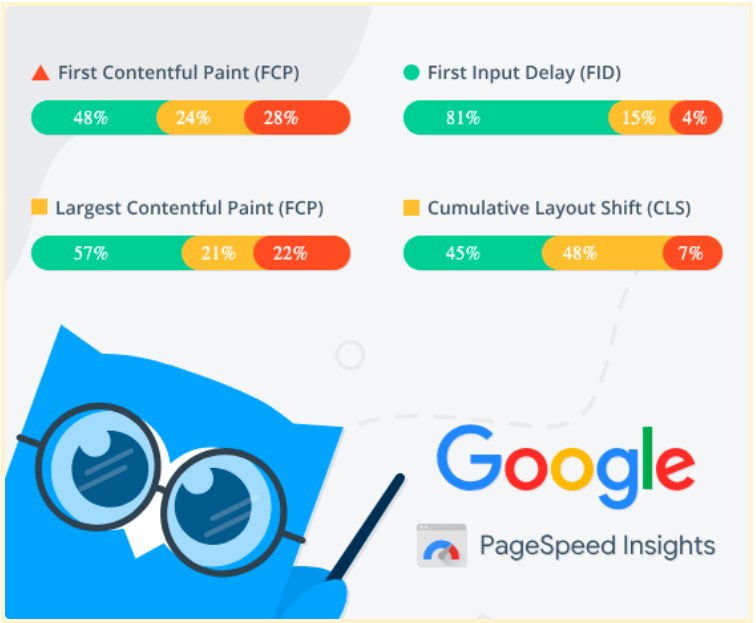
Netpeak Checker lets you retrieve data from Google PageSpeed Insights to quickly check your website's speed, responsiveness, and visual stability.
Integration with Google Drive & Sheets

Connect your Google Drive account to Netpeak Checker, quickly export the required reports to Google Sheets, and easily share them with colleagues or partners in just a few clicks.
Conclusion
Crawl budget is an important factor in your overall business strategy, but it’s not something to lose sleep over early on. Take it into consideration when you’ve gathered a large URL collection or when your website generates dynamic content during the normal course of operation. If that’s about your website, then implement the strategies outlined in this post to improve your crawl budget and ensure Googlebot indexes the most important pages.


