Как оптимизировать краулинговый бюджет
Мануалы

Поисковые системы считаются одним из лучших источников бесплатного трафика. Вы создаёте оптимизированный контент, его сканируют поисковые системы, и он начинает ранжироваться. На первый взгляд весь процесс прост, и большинству не стоит беспокоиться о нюансах, связанных со сканированием сайта.
В этом посте я расскажу, что такое краулинговый бюджет, когда и почему он важен, а также поделюсь способами его оптимизировать, чтобы проиндексировать нужные страницы.
1. Что такое краулинговый бюджет?
Краулинговый бюджет — это количество URL-адресов на вашем сайте, которое может просканировать Googlebot. Есть два фактора, которые необходимо учитывать при попытке оценить краулинговый бюджет вашего сайта:
- Ограничение скорости сканирования — это скорость, с которой Google может сканировать ваш сайт.
- Спрос на поиск — показывает, насколько важными Google считает ваши URL-адреса.
Эти два фактора и составляют ваш краулинговый бюджет. Важно отметить, что если ваш сайт имеет менее 1 000 URL, доступных для просмотра, вы можете не переживать о краулинговом бюджете.
Краулинговый бюджет становится важным, если у вас есть большой сайт или сайт, который генерирует много URL-адресов, например интернет-магазин с функцией фильтрации поиска.
2. Способы оптимизировать краулинговый бюджет
Вы не можете контролировать Googlebot, но вы можете контролировать то, как он взаимодействует с вашим сайтом. Существует ряд факторов, которые влияют на ваш бюджет. Когда они оптимизированы, вы можете улучшить свой общий бюджет на просмотр и убедиться, что нужные страницы проиндексированы.
2.1. Ускорьте работу вашего сайта
Это то, что вы должны делать независимо от краулингового бюджета. Чем быстрее сайт, тем лучше ваши посетители будут воспринимать его. Googlebot старается делать свою работу как можно быстрее, не потребляя слишком много ресурсов сервера. Если он замечает замедление работы сайта, то это уменьшает процесс его просмотра или останавливает его полностью. В этом случае важные страницы могут быть полностью пропущены.
Есть несколько быстрых исправлений для медленного сайта:
- Внедрить CDN, которая поможет Googlebot быстрее получить доступ к ресурсам, обслуживая их из ближайшего к нему места.
- Сжимайте файлы и изображения, чтобы уменьшить размер страниц и загрузить их быстрее.
- Инвестируйте в лучший хостинг.
- Настройка кэширования браузера.
2.2. Сделать важные страницы более глубокими
Google отдаёт предпочтение более глубокому контенту. Его задача — показать пользователю страницу, которая даст максимально релевантный ответ на запрос.
Вероятнее, что контент удовлетворит пользователя, в случае если он содержит изображения и другие медиафайлы.
Чем выше количество слов на странице, тем больше вероятность того, что эта страница будет сканироваться и индексироваться. Страницы с малым содержанием контента (менее 300 слов) индексируются в 20% случаев. Основная рекомендация: наполнять ваши страницы хорошим и качественным контентом и постараться избавиться от страниц, на которых контента недостаточно.
2.3. Удалить бесконечное пространство адресов
Бесконечные пространства адресов — это места на вашем сайте, которые, технически, могут быть бесконечными. Например, если у вас есть страница бронирования с календарём, посетитель может нажимать на следующую кнопку столько, сколько захочет. Это тратит ваш краулинговый бюджет на сканирование роботом ненужных страниц или контента.
Чтобы этого не произошло, используйте файл robots.txt для устранения динамических бесконечных категорий. Следуйте инструкциям календаря и используйте инструмент URL Parameters Tool, предоставляемый Google для форматирования ссылок, чтобы Googlebot мог правильно игнорировать несущественные ссылки.
2.4. Устранить 404 ошибки
404 ошибка появляется, когда сервер использует код ответа 200 OK для несуществующей страницы.
Проблема с 404 ошибками заключается в том, что Googlebot пытается просмотреть и проиндексировать несуществующую страницу вместо страниц с уникальным контентом. В конце концов, Googlebot перейдёт на другой сайт, и ваши страницы могут быть проиндексированы сильно позже.
Просканируйте ваш сайт с помощью Netpeak Spider, чтобы обнаружить 404 ошибки. Если они присутствуют, установите редиректы на нужные страницы или исправьте код ответа сервера. По завершении поиска просмотрите страницу в строке поиска Google, чтобы убедиться, что изменения вступили в силу.
Как найти битые ссылки на вашем сайте с помощью сканирования в Netpeak Spider:
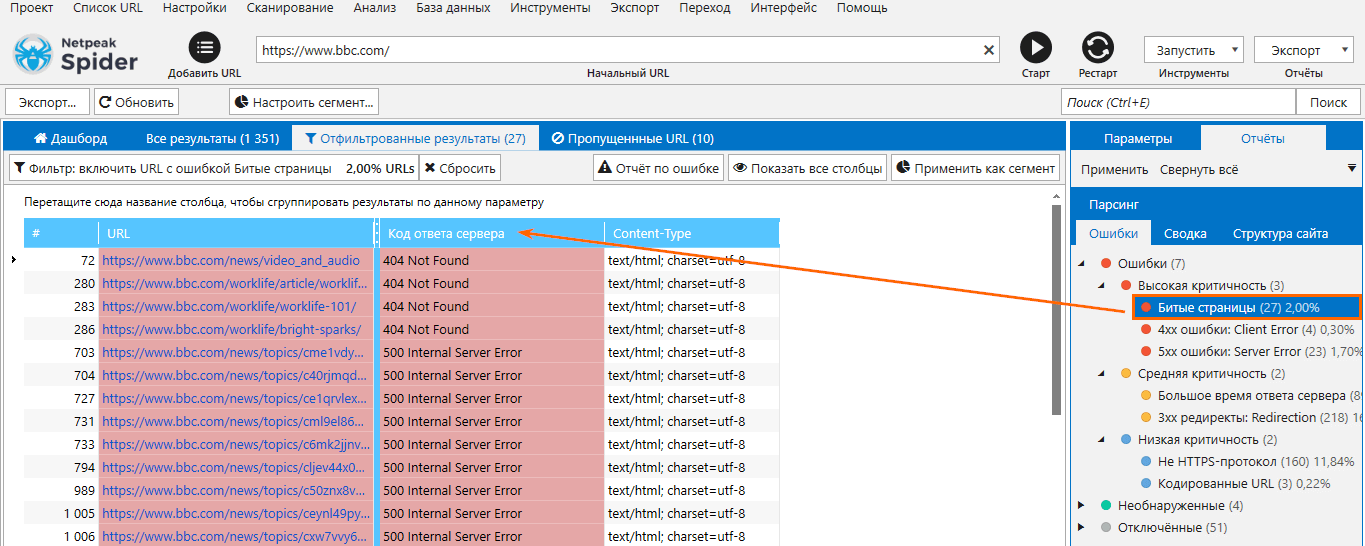
Находить битые ссылки вы можете даже в бесплатной версии Netpeak Spider без ограничений по времени, в которой также доступно много других базовых функций программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Подводим итоги
Краулинговый бюджет является важным фактором в общей стратегии вашего бизнеса. Учтите это при создании больших сайтов или интернет-магазинов. Реализуйте стратегии, описанные в этом посте, чтобы улучшить свой краулинговый бюджет и обеспечить индексацию наиболее важных страниц Googlebot.


