What Is a Crawling Budget, and How Can You Optimize Website Scans?
How to

Search engines use certain resources to find websites and crawl their content. These resources are limited, so if you consider that there are more than a billion websites on the Internet, then the vast majority of them are only partially crawled by search engines, each using just a small part of the resources.
What Is a Crawling Budget?
A crawl budget is the number of a website’s HTML pages and files that Google's search bot can crawl when visiting it. Based on its budget, Google might crawl 50 pages per day on one website and over 1,000 on another. When we talk about crawling budgets, we often mean the number of pages crawled by a search bot, but these budgets also include the crawling of other files, including:
- audio and video files
- photos
- PDF files, etc.
Therefore, a search engine will need a different amount of resources to scan a page with one photo compared to a page with 30 photos.
Read more → What are orphan pages
How Does the Google Crawler Work?
When it visits a website, the search engine bot scans the robots.txt file, which is located at the root of the website, in order to understand which sections it can scan and which are forbidden. If there is no robots.txt file, the search robot will crawl the entire site and therefore may spend part of its resources on pages of the website that don’t need to be crawled. Next, the search bot will scan the pages from the XML sitemap file. After the bot has crawled and analyzed the content of the pages it found, it will add all the pages linked by each previously crawled website page to the crawl queue. It continues in this way until the scanner has analyzed all the website’s files that are available for scanning.
Why Is a Crawling Budget Important?
The size of a crawling budget depends on:
- how many pages of the website will be scanned and for how long
- how quickly new content will enter the search engine’s index and start receiving organic traffic
If a website has trouble with its crawling budget, it will struggle to get much organic traffic.
Read more → How to increase crawl budget
When Do Scanning Budget Issues Arise?
Most websites can be crawled without issue, but such issues can occur if the daily number of new pages exceeds the number that the crawler can crawl. For example, if your website has 500,000 pages and the search engine only crawls about 1,000 pages on average every day, it will take a year and a half for the entire website to be crawled (and that's not counting any new pages that appear). However, if a search engine crawls 50,000 pages every day, your website will be crawled in a month and a half, or even faster.
In the first instance, there’s a problem with the crawling budget (unless you don’t mind only 30% of your website in the search engine’s index after a year), while there’s no problem in the second instance.
How Do I Find Out My Website’s Crawl Budget?
There are several ways to find out a website’s crawling budget.
Method #1: Crawl statistics in Google Search Console
To do this, go to your website’s Google Search Console, go to the ‘Settings’ section, and select ‘Open Repost’ in the ‘Crawling’ block:
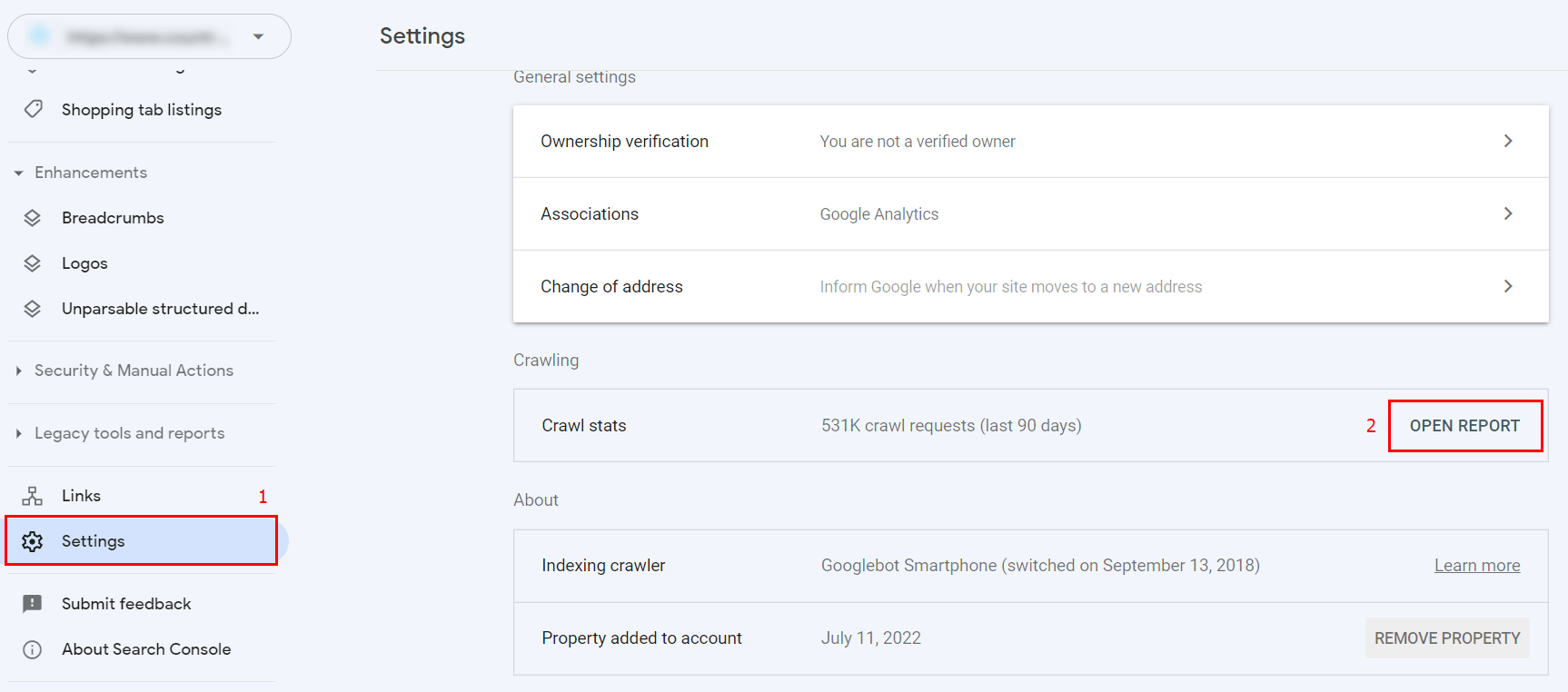
Here you can see a schedule of crawling on your website, like this:
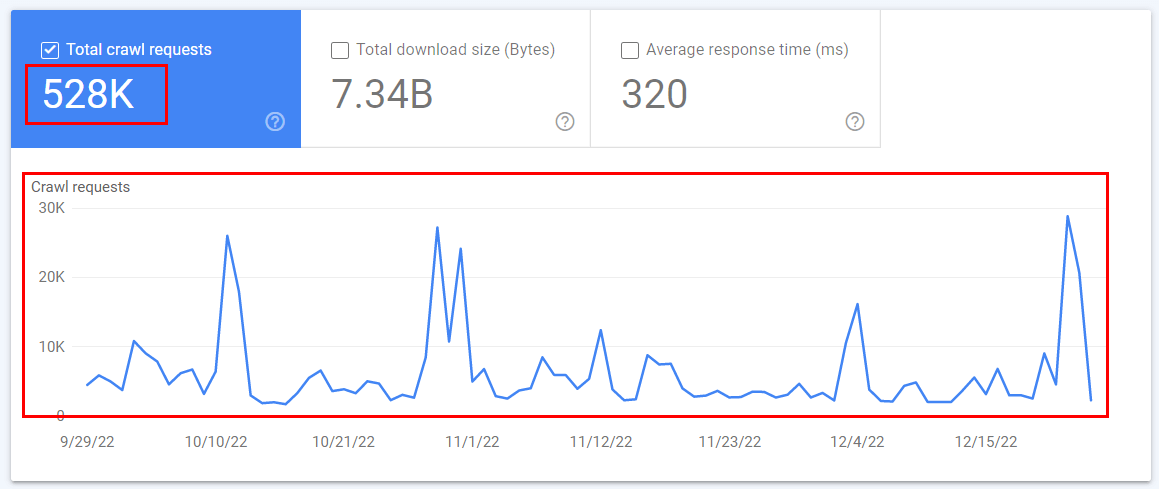
The graph shows the number of requests to crawl your website over the last 3 months, by day. Each request is a search robot scanning one file (HTML page, image, video, fonts, etc.).
Method #2: Analyze server logs
You can analyze your website’s server logs and find out how many times a search engine visits it every day. Server logs are files listing the information of each website visitor (be it human or search engine): time of visit, resources downloaded (HTML page, file, etc.), IP, User Agent, etc. You can find search robot requests in the server logs by User Agent. Each search robot has its own unique User Agent. A list of Google search robots User Agents can be found here.
How Can You Optimize a Website’s Crawling Budget?
There are many different factors that affect a website's crawl budget. If you have problems with your budget, you can try to optimize the scanning process:
- Configure the robots.txt file to limit the crawling of the parts of the website you need the least (this usually includes the entire administrative part of the site and technical pages that have no search demand, such as sorting pages and internal search pages).
- Add the website’s highest-priority pages to the XML map, so the search engine crawls them first (these are typically the pages of categories, filters, product cards, blog posts, etc.).
- Remove duplicate pages or disable their crawling via the robots.txt file.
- Remove cyclic redirects (where the same page is both the first and last link of a redirect) and redirects that consist of more than two links.
- Fix or remove broken internal links (links that lead to pages with a server response other than 200).
- Fix or remove broken images (ones that give a server response other than 200).
- Set up a link to the most relevant website pages, such as:
- new pages;
- popular pages;
- priority pages (for example, products with the largest margin);
- related pages (for example, from child pages to parent pages and vice versa).
You can find a website’s weak points that are wasting your crawling budget by conducting an audit with Netpeak Spider. To do this, simply enter the website’s domain in the search bar, select the standard settings template, and click ‘Start’:
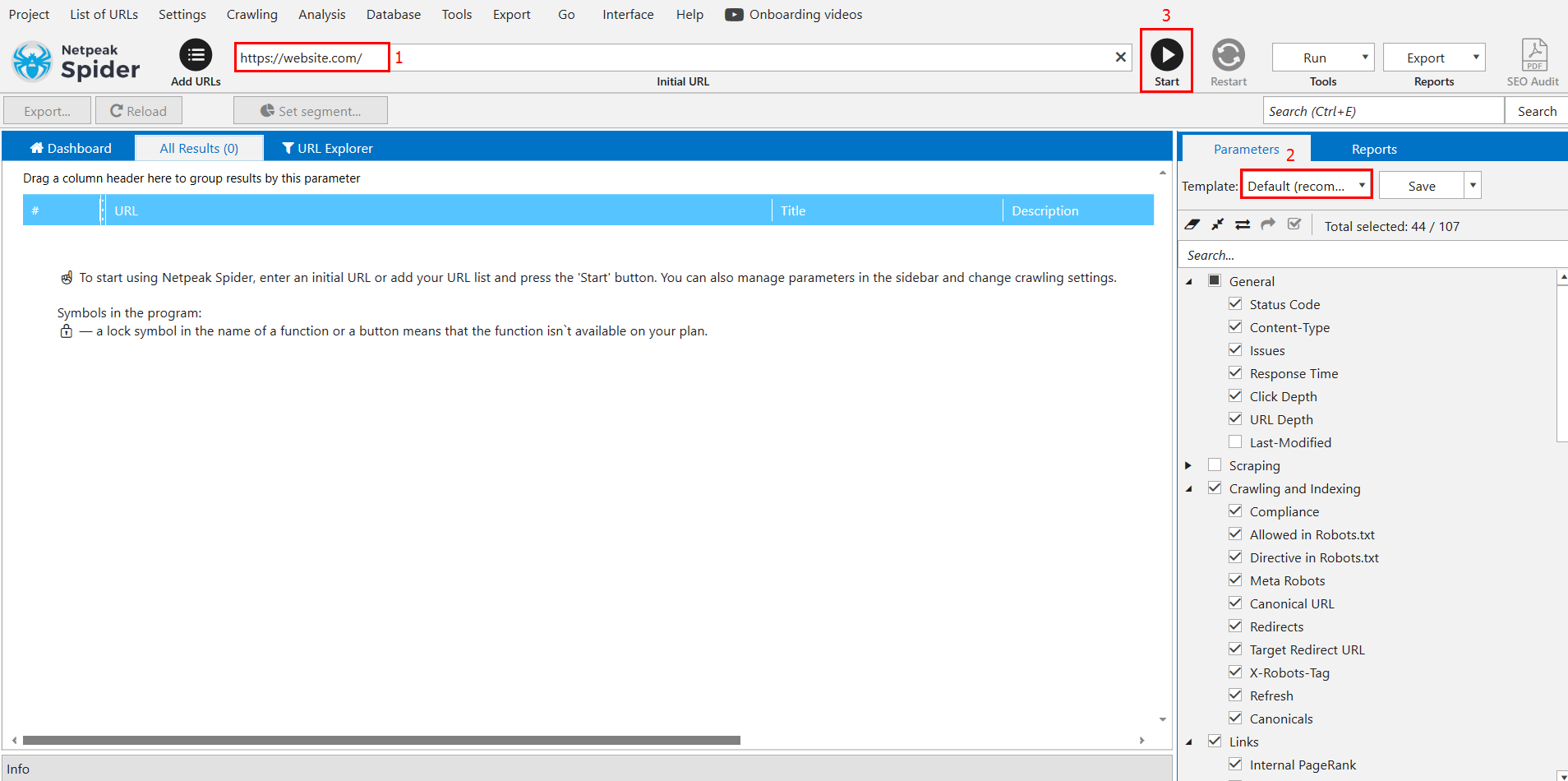
Conclusion
A website's crawling budget is an important factor that affects the speed and completeness of how its HTML pages and other objects (photos, videos, fonts, etc.) are crawled. If your website's crawling budget is too small, it won’t be crawled well, and new pages will take a long time to get included in search engines’ indexes. Most websites don’t have crawling budget issues and are crawled by search engines regularly. However, if your site does have crawling issues, you can use crawl statistics in Google Search Console to detect them. You can then use Netpeak Spider auditing to analyze and correct all the weak points that negatively affect the crawling budget.


