How to Do Technical SEO Audit
Use Cases

Technical audit seeks to look ‘under the hood’ of a website to spot the bugs that pull the website's ranking down and fix them before they can bring havoc. In this blog post, we’ll surface what aspects of technical SEO audit should be reviewed in the first place, what issues you're likely to face if any breaches with these aspects occur, and how to check if everything goes in the right direction.
- 1. What is Technical SEO?
- 2. What Aspects to Check during the Technical SEO Audit
- 2.1. Ensure Your Pages Can Be Crawled and Indexed
- 2.2. Status Codes
- 2.3. Duplicate Content
- 2.4. Canonical
- 2.5. Redirects
- 2.6. Server Response Time
- 2.7. Website Structure
- 2.8. Internal Links
- 2.9. XML Sitemap
- 2.10. HTTP / HTTPS protocols
- 3. How to Do Technical Audit with Netpeak Spider
- Recap
1. What is Technical SEO?
SEO technical audit is a set of activities aimed to identify the problem areas and the development of technical specifications for their further fixing. It helps eliminate issues that appear to be an obstacle to user navigation, indexing, speed of content loading, access to different directories, etc. Detection of technical problems helps you form the list of things that can improve website performance. As a result, you improve behavioral factors and website chances to rank higher on Google.
Technical SEO audits should be carried out at all stages of website lifespan:
- website launching
- relocation to a new domain
- redesign and any website structure changes
- routine weekly / quarterly crawls to spot random issues timely
Depending on the type and size of a website, you decide how frequently SEO audits should be conducted: weekly, monthly, or quarterly. In other cases, website auditing is a must.
Automate site audits with specialized tools – Netpeak Spider and Netpeak Checker, together with analytics services such as Google Search Console and Google Analytics, and work through the list of errors and warnings flagged out during the crawling. It makes it possible to look at the site as search engines actually see it. So I’m going to list the basic factors for the initial and / regular website audit and explain how to find and fix those bugs.
Netpeak Spider crawler has a free version that is not limited by the term of use and the number of analyzed URLs → you can test many features and approach the results in the program built-in table. Other basic features are also available in the Freemium version of the program.
To get access to free Netpeak Spider, you just need to sign up, download and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the one most suitable for you.
2. What Aspects to Check during the Technical SEO Audit
This is the list of factors you need to mark with the highest priority. The issues with these factors are likely to result in ranking drops, indexing problems, and impaired user experience on your website.
Read more → SEO conversions
2.1. Ensure Your Pages Can Be Crawled and Indexed
First and foremost, make sure your pages CAN be crawled and indexed. For example, you have a high-quality page from the SEO point of view, but it’s still not on Google's index. The reasons may be trite:
- the robots are blocked in robots.txt file or meta robots tag from crawling certain content
- the robots are allowed to crawl a page, but disallowed to index it
- the links on the page are closed with no-follow tag
In fact, many scenarios are possible. Ideally, all pages on your website must be open for indexing (I stress ideally). The XML sitemap should have links to the website's essential pages, and the internal infrastructure of your website should be clear and logical.
Check your index status in Google Search Console to see the number of pages Google has on its index. To take a glance, go to the ‘Coverage’ tab.
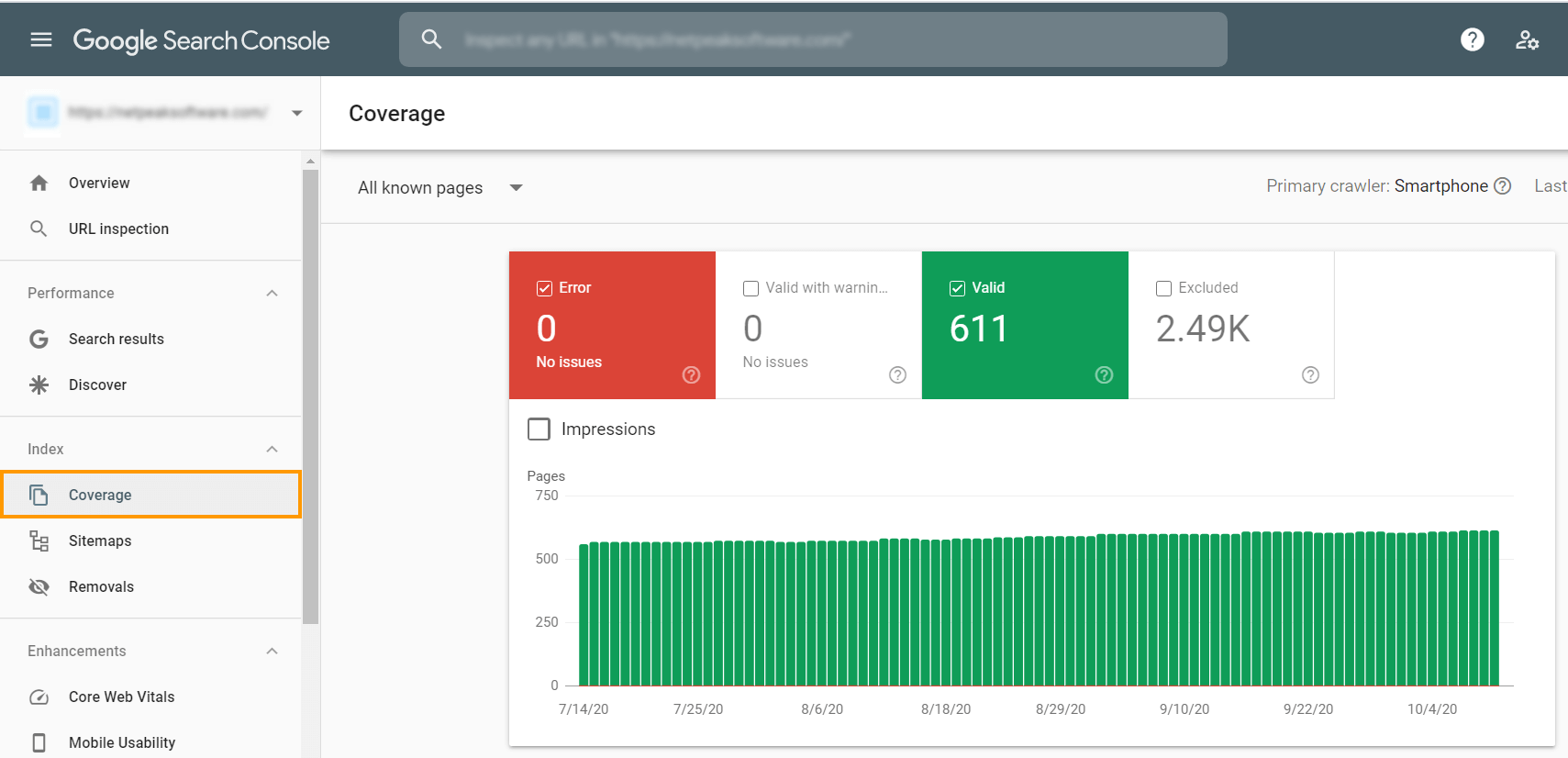
You’ll see here:
- Total clicks and total impressions
- Average CTR and average position
- Indexing errors – the pages that couldn’t be indexed for some reason
- Submitted sitemaps
- Core Web Vitals report
- Mobile Usability
- Google penalties
Since you can see only the overall number of pages on Google’s index, it’s pretty hard to guess whether particular pages are indexed or not (especially if there are thousands of pages on your website). But it’s a piece of cake to check them all in Netpeak Checker.
First, you need to gather all URLs from your website. Go to Netpeak Spider, enter your website initial URL into the tab, disable all parameters in a sidebar (leave only ‘Status Code’), start crawling. In a blip of an eye, the program will collect all URLs. On the ‘Export’ tab, choose ‘Current table results’, and you’ll get the report in the convenient table format.
And now, with all these URLs (no matter how many you have), go to Netpeak Checker. It's smooth sailing here:
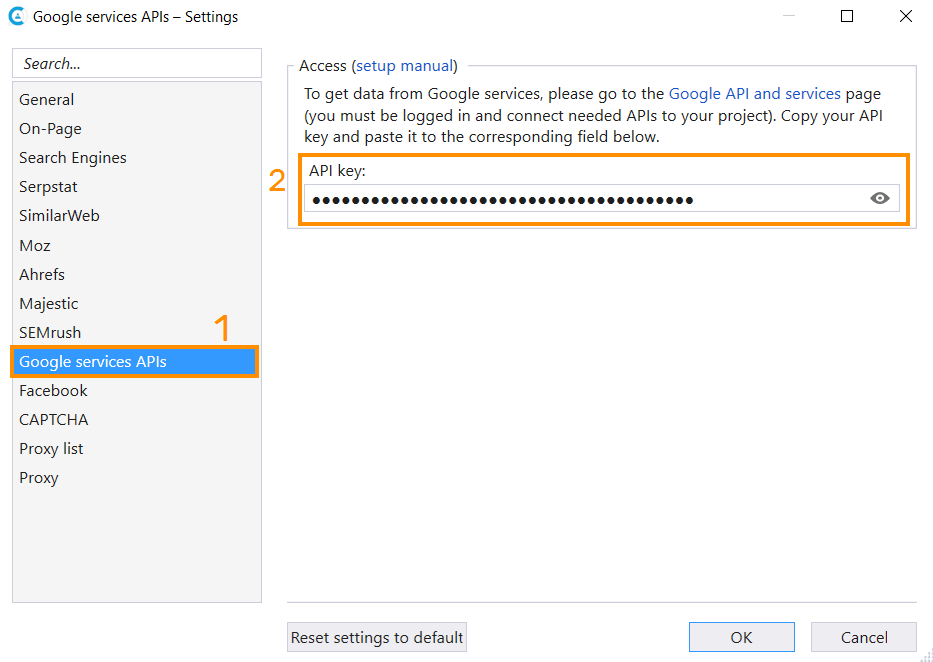
- ‘List of URLs’ settings tab → ‘Upload from a file’.
- Tick the ‘URL parameters’ in the ‘Google SERP’ group. Note that you’ll need Google API to perform this check. Go to the ‘Settings’ → ‘Services’ → ‘Google services APIs’, and you’ll be guided to the right website.
- When the links are added, parameters are enabled, and the API is added – hit the ‘Start’ button, and you’ll see the magic.
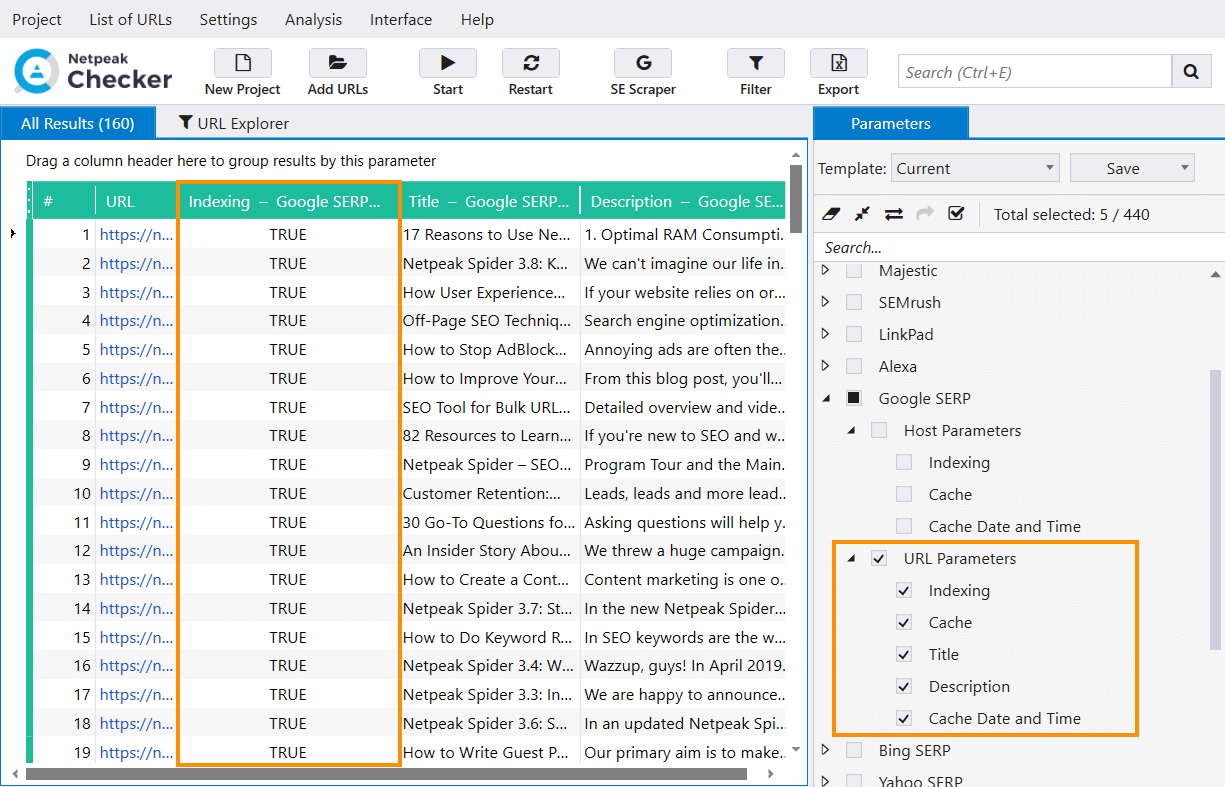
To see if the pages are compliant, i.e., available for indexing, return 200 OK status code, not disallowed in robots.txt, canonical tag, meta robots tag – you name it, you’ll need Netpeak Spider (find the example audit below).
2.2. Status Codes
HTTP response status codes indicate whether a specific HTTP request has been successfully completed. The 200 OK status code tells us about a successful request processing. 404 indicates unavailable URLs (both for users and robots), or simply broken links, 301-302 is used for redirects, and 500 for internal server error. But this is not always the case. As part of a technical audit, you need to check if the status codes display correctly after requesting the server. For example, you can enter a non-existent page into the address bar and see if the 404 code is displayed.
Why the hustle? First, when a user lands on such a page, it can discourage them from browsing other parts of your website, and they will leave it. Also, it contributes to incorrect website indexing.
3XX redirection status code may also pose a threat to user experience because each redirect means a new request to the server, thus it can take a bit longer to land on the target URL – so it increases server response time. It also drains the search robot’s crawl budget because each redirect takes a pinch of time to crawl other important pages (which can be left uncrawled due to the lack of time).
Delete or replace broken links to the links with available URLs and make it easier for visitors and search engines to find content on your site.
1. Our Product Marketing Manager Kosta Bankovski has already told everything about status codes in this blog post: ‘How to Check HTTP Status Code: Server Response Codes in Laymanʼs Terms.'
2. And check out this case, in which we explain how to deal with broken links on the website: 'How to Find Broken Links with Netpeak Spider.'2.3. Duplicate Content
Duplicates are separate pages which content fully or partially matches. These are copies of the entire page or specific parts, available at unique URLs. There are several reasons for this stumper:
- Automatic generation of duplicate pages by the CMS engine.
- Webmasters’ missteps. For example, when the same product is presented in several categories and available at different URLs.
- Any changes in website structure. For instance, when existing pages are assigned new addresses, but their duplicates with old addresses are saved.
- The pages are live and visible to search engines on both HTTP and HTTPS protocols.
- The website has two versions with www. and without (www.meow.com and meow.com), and the content is generated on both versions.
- Any URL variations, GET-parameters, and analytics codes that are assigned to track clicks, ID sessions, statistics, etc.
- Printer-friendly versions of the same URL.
- Pagination.
- AMP vs. non-AMP versions of the page.
Duplicates cause problems with indexing and ranking. The robots are muddled about what of the multiple similar versions to add to the index and what version to rank for query results. It impairs your visibility in the SERP and dilutes link equity of the pages.
Delete duplicate pages, if possible, set redirects or canonical tags.
Read more → SEO technical skills
2.4. Canonical
The canonical URL tag was created to solve the problem with duplicate pages. Canonical tags point out to search engines that this page is a full or partial copy of another one, but it should be given more priority.
Canonicals should be used in such cases:
- pagination pages
- the website contains filtering pages
- mobile website version and / or AMP pages
- pages with GET-parameters
- when we can’t use 301 redirect because we want to save pages for user interaction
Any pitfalls? Yes, double-check the implementation of canonical tags because you may face such issues:
- Non-compliant canonical URL – the link to rel="canonical" tag that may be blocked in the robots.txt. file, meta robots tag, etc.
- Canonical chain – when a canonical URL contains a page address that links to another URL in the rel="canonical" or the 'Link: rel="canonical"' HTTP response header.
- Canonicalized Pages – pages where a URL in the rel="canonical" tag or the 'Link: rel="canonical"' HTTP response header differs from the page URL.
- Identical Canonical URLs – all pages with identical canonical URLs in the rel="canonical" tags in the <head> section or 'Link: rel="canonical"' HTTP response header.
2.5. Redirects
Redirects are used to redirect site visitors from one page to another. Redirects are used in case:
- the website moved to another domain, and you want to retain ranking results
- the website transferred from HTTPS to HTTPS protocol
- you need to delete you hide certain parts of the website
- you have duplicate pages which impossible to delete
- you have a website mirror, and you want to redirect to the main mirror
So now, let’s deal with what issues stand behind incorrect redirect implementation. Here are some of them:
- Redirect to 4xx error page.
- Redirect to irrelevant pages / content. Redirect only to the content that meets users’ expectations.
- Endless redirect. It indicates all pages redirecting to themselves and thereby generating an infinite redirect loop. It can occur because of mistake in the htaccess file.
- Redirect blocked by robots.txt. In such case, the URL you are redirecting to will be missed by search engines.
- Redirect with bad URL format in the HTTP response headers.
2.6. Server Response Time
Server response time or TTFB (time to first byte) indicates the time that takes a user’s browser to receive the first byte of the content. Slow server response time is one possible cause for long page loading. Users won’t wait long until the page displays at least something meaningful or something enough for engagement.
Google has included page speed as a ranking factor for both mobile pages and ads. If your pages load slowly, it will reduce your ad quality score, and the speed of your site on mobile will affect your overall SEO ranking.
In the wake of Google’s Page Experience Update, Core Web Vitals, which include website speed and overall performance, are gaining more urgency. You can conduct checks for these metrics straight in the Netpeak Checker program. Upload URLs, tick corresponding parameters and let it roll.
1. How to Speed up Your Website with Netpeak Spider
2. How User Experience Fits into Google Page Experience Update
3. How to Improve Your Metrics in Google PageSpeed / LightHouse [Demi Murych Talk]
2.7. Website Structure
The website structure for search robots is links within the website. Search engines crawl your website by following links, internal and external. The website structure should be reflected in the navigation of your website. Also, it participates in the distribution of link equity. A website with the correct structure is more likely to get to the first positions in the search results.
The website structure basic requirements are:
- It has easy navigation: breadcrumbs on the page, ancillary blocks, etc.
- URL depth should be logically optimized. Don’t make users perform hundred of clicks to find what they look for.
- All pages should contain a link to the main page of the website.
You can check your competitor’s website structure in Netpeak Spider to analyze it and borrow the best solutions to your own pocket.
2.8. Internal Links
Internal linking is links that lead from one page to another within one website. A competent internal linking will help:
- increase page authority, the relevance of queries, and usability
- indexing of pages with more than two clicks from the initial page
- distribute link equity (PageRank) across the pages
- improve time on the website and number of page views
Here are the main rules to help you do internal linking right:
- build the correct website structure
- distribute the weight within the website so that pages with a high level of authority lead to the pages that you want to promote
- link each page of the website to at least one other page
- internal links should not be closed with the rel=nofollow attribute because they stop distributing the link equity in this case
Inaccurate link distribution can cause such PageRank issues as dead ends and orphan pages. For instance, when the page has incoming links, but zero outgoing ones it's called a ‘dead end’.
To find out how much weight the website pages receive and what pages lack links to other pages, use the ‘Internal PageRank calculation’ tool in Netpeak Spider.
- In the sidebar, click the parameters in the ‘Links’ group before crawling.
- Crawl your website, then go to the ‘Tools’ menu and select ‘Internal PageRank calculation’.
- Here you'll see a table with information on pages: about weight, status codes, number of outgoing and incoming links.
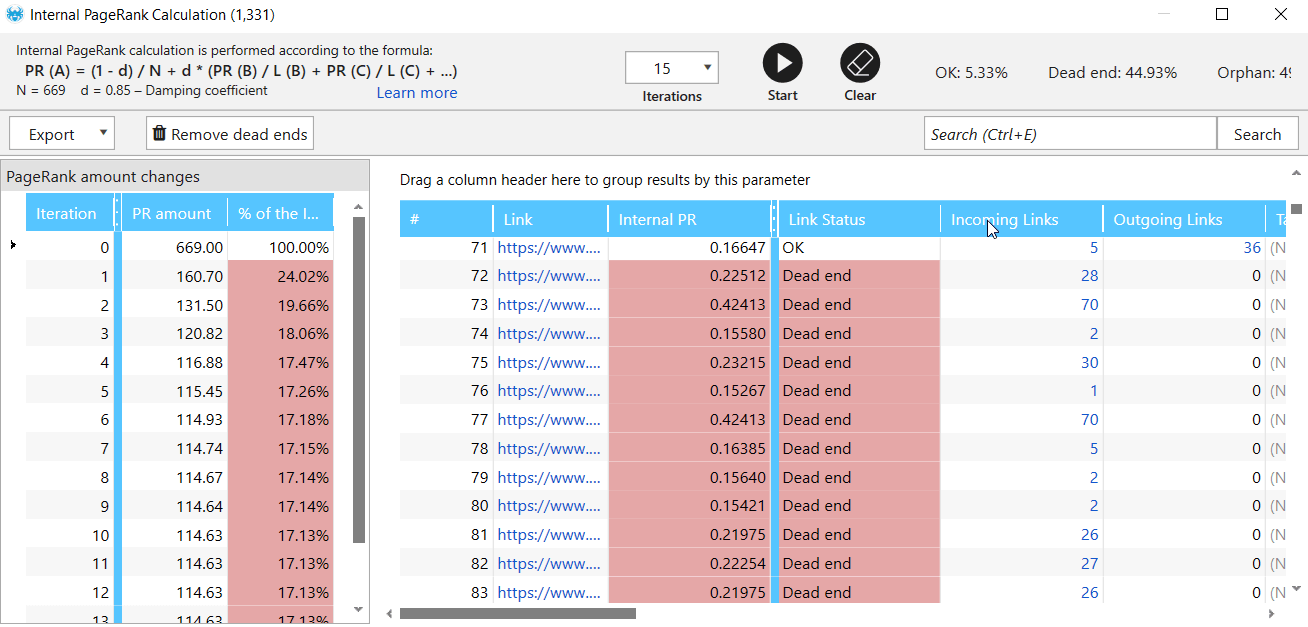
- In the issue reports in the program's main window, see if the errors ‘PageRank: Orphan’ and ‘PageRank: Missing Outgoing Links’ were found.
2.9. XML Sitemap
XML sitemap provides robots with the list of web pages to crawl and index. However, none of the search engines guarantees that all URLs specified in the file will be added to the search index. Use Google Search Console to see indexed and submitted pages.
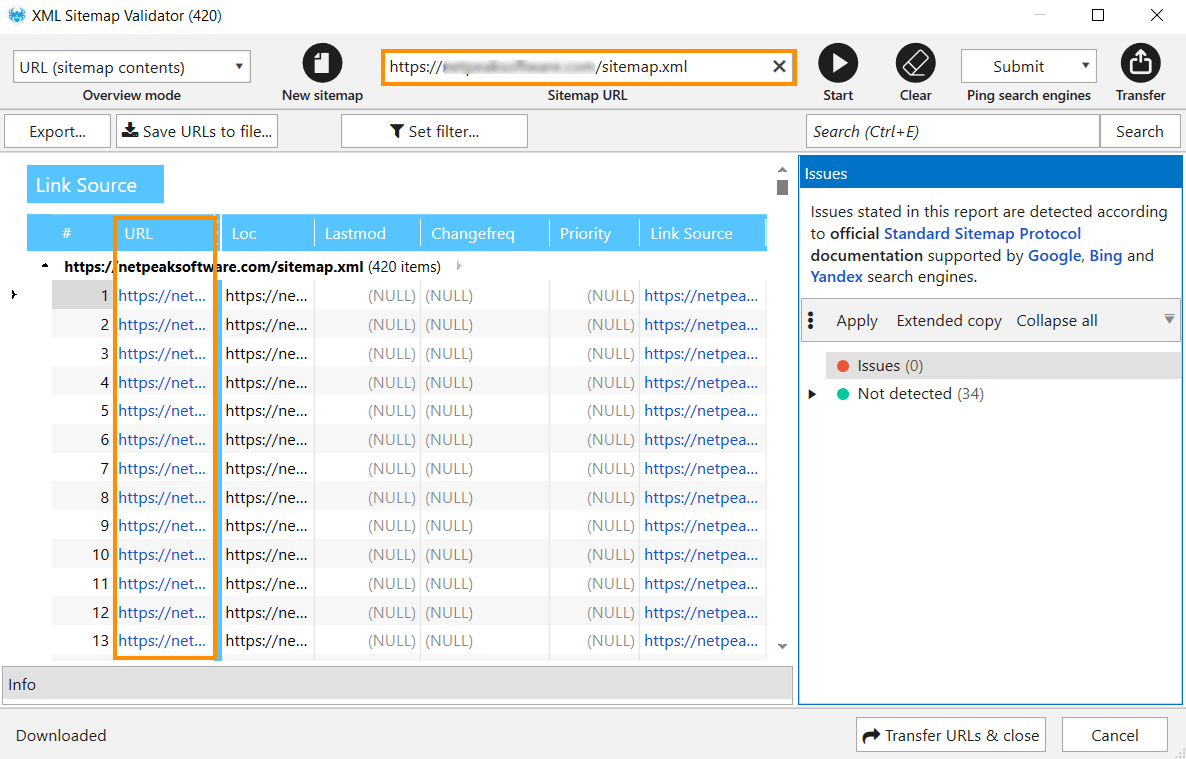
To see the XML sitemap pages, go to the 'XML Sitemap Validator' built-in tool in Netpeak Spider, simply paste your sitemap URL and count to three until the list of URLs displays in the table.
2.10. HTTP / HTTPS protocols
Previously, HTTPS protocols were relevant exclusively for websites which processed personal data and financial transactions. Now Google considers the HTTPS protocol to be an important ranking factor. Unlike HTTP, this protocol guarantees encryption, data integrity, and better authentication. So secure HTTPS protocol is a basic requirement for all websites these days.
When the website is transferred to secure protocol, make sure that you don’t have other resources (such as images, videos, stylesheets, scripts) that are loaded over an insecure HTTP connection – it’s a cause of the mixed content issue.
Read more → Importance of technical SEO
3. How to Do Technical Audit with Netpeak Spider
And since it’s hardly possible to do an audit without dedicated tools, I’ll use Netpeak Spider to showcase how to do a comprehensive audit of the above-mentioned factors and the hazards they may cause.
- Launch the program and enter the initial website URL to the ‘Initial URL’ field.
- Enable these parameters in a sidebar and make sure you know what they’re responsible for:
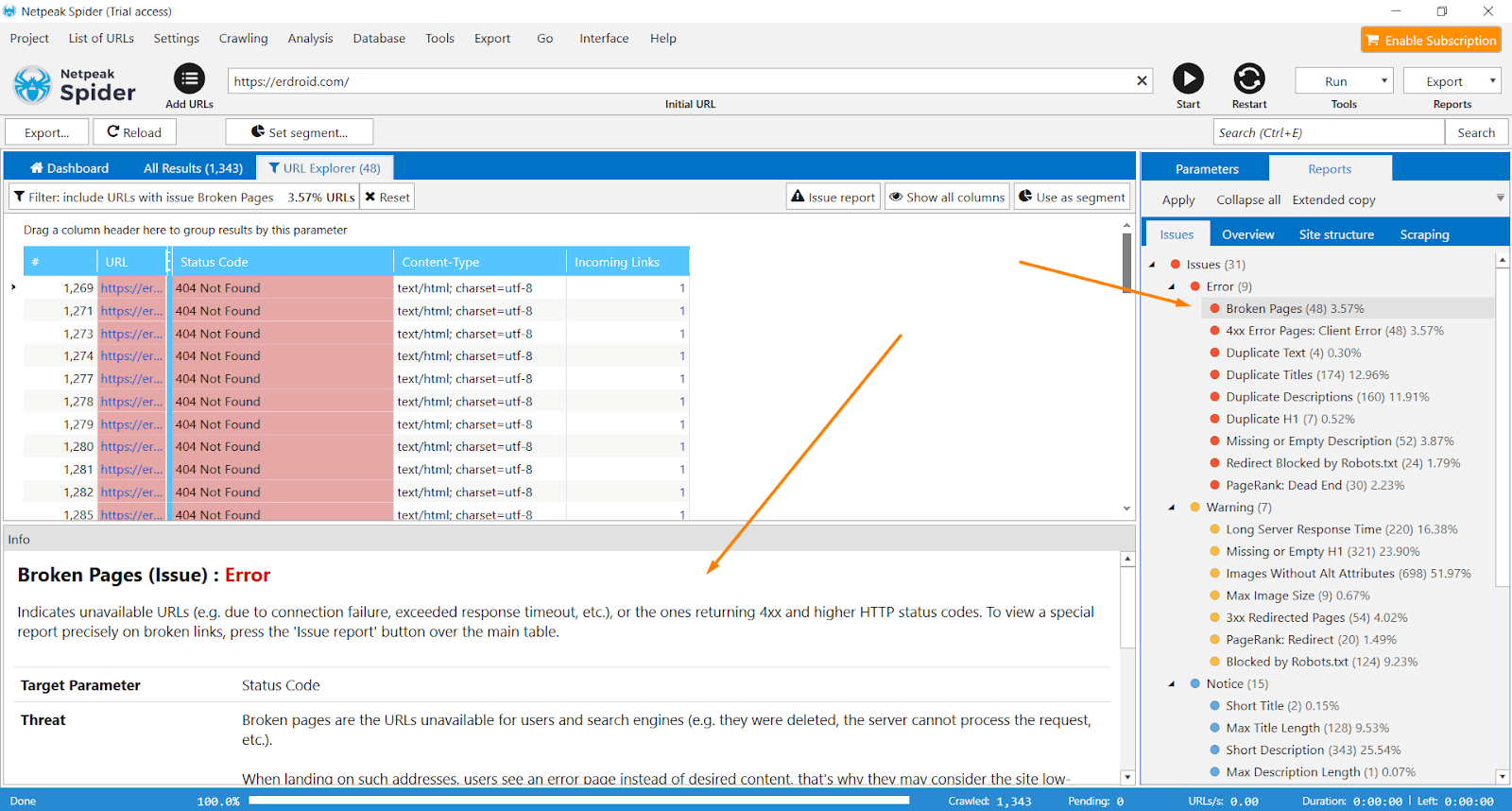
- ‘Status Code’ → with this parameter on, you’ll be able to check status codes of all pages on your website and spot such issues as broken pages, 4XX error pages, broken redirects, endless redirects, broken images, etc.
- ‘Content-type’ → check the type of the returned content: text/html, image/png, application/pdf, etc.
- ‘Issues’ → the number of all issues found on the page.
- ‘Response Time’ → check if it takes long to load resources on your website.
- ‘Click Depth’ and ‘URL Depth’ → to analyze website structure and optimize internal linking.
- ‘Crawling and Indexing’ → check crawling and indexing instructions for the current URL: robots.txt, Meta Robots, X-Robots-Tag, canonical, etc. Also, see if any issues with redirects occur on your website.
- ‘Links’ → analyze incoming and outgoing links, internal PageRank, spot mixed content issue, and pages with HTTPS protocol that link to other pages with HTTP.
- ‘Head Tags’ → check out titles, descriptions, hreflang attributes, etc.
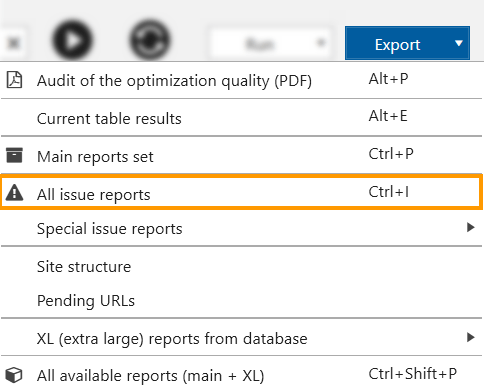
With these settings in action, the program will check website pages for all available SEO issues. To export all reports on the issues detected, use the 'Export' menu.
Or approach the results in the main table just in the program. In a sidebar, you’ll see all the issues listed in the order of severity. Red is for critical issues. Yellow stands for the warning, and blue indicates other various aspects worth your attention.
Recap
Technical website audit is a regular process that can't be ignored if you want the website to rank high and receive traffic, leads, and conversions. Determine the frequency depending on the niche you work in and the website size. It can be conducted when:
- the website’s launched
- it’s relocated to a new domain
- any changes such as redesign are done
- routine weekly / quarterly crawls to spot random issues timely
This blog post includes main technical aspects analysis. If you want to go further, consider the analysis of content, images, backlinks, etc.


