How to Use link rel=canonical to Prevent and Fix Duplicates
Use Cases

The uniqueness and quality of the content are one of the key factors for ranking. Duplicate pages within the website hamper its search engine promotion. As a result, the website ranking is worse in organic search. Canonical SEO is a little something you have to consider during your optimization process.
In this post, you’ll learn how search engines identify canonical pages and how to find issues with canonical URL on your website.
Read more → Canonical tag checker
1. Canonical and Duplicate Pages. What Are They?
If the same page is available at several URLs on your website, or different pages have similar content (for example, mobile and desktop versions of the website), Google will consider one of these URLs canonical and the rest as duplicates. Canonical URL will be crawled much more frequently than its copies. So it’s crucial to make sure that Google has considered the right pages as canonical.
The rel="canonical" attribute eliminates duplicates. It consolidates the pages that copy each other and, thus, improves the site ranking. Unlike the 301 redirect (Moved Permanently), which redirects users to the necessary page, the rel="canonical" attribute is intended only for robots. It does not affect user experience with the website.
2. How Does Google Determine Canonical Pages?
A canonical URL is the URL of the page that Google thinks is most representative from a set of duplicate pages on your site.
Canonical pages are considered according to several criteria (signals). They may be:
- protocol (http or https)
- the preferable for user domain
- page quality
- presence of URL in Sitemap
- the presence of rel="canonical"
Keep in mind that even if you tell Google about your choice, the search engine can choose another page as a canonical at its own discretion.
You can use the canonical attribute in the following cases:
- It is necessary to save pages with partially duplicated content.
- There are difficulties in removing or preventing duplicates.
- It’s challenging to implement 301 redirects.
- Printing versions of pages are automatically created on the site.
- The site contains filtering pages.
3. How to Specify Canonical Page
To set the attribute rel="canonical", you need to place it in the page block. Type the following tag <link rel = "canonical" href = "https://example.com/a" />, where https://example.com/a is the address of the canonical page. It is important to put an absolute link (full address, including http:// or https://) when specifying the URL of a canonical page. This will reduce the risk of HTTP issues.
There are the following nuances:
- The rel="canonical" tag works only for HTML pages.
- The HTTP header rel="canonical" works for all types of pages.
- The sitemap is a less significant signal for Googlebot than the rel="canonical" attribute.
Read more about how to specify the canonical page in Google Help Center.
3.1. When rel="canonical" Doesn’t Consolidate Pages
- Consolidating http and https versions of the website (in such situations, you need to set a redirect for each page).
- Consolidating pages with www and without (in such situations, you need to set a redirect for each page).
- When the pages’ content is significantly different. In this case, Google will not follow the recommendation specified in the rel="canonical" tag.
3.2. When rel="canonical" Consolidates Pages
The rel = "canonical" tag consolidates pages only if the canonical page chosen by Google and the user matches. For this, the content of these pages should be as similar as possible.
Let’s look at the main cases where rel="canonical" consolidates pages successfully.
3.2.1. One Product Available at Different URLs
If the page with very similar content is available at two URLs and one of which is selected as canonical.
Example:
rel="canonical" is specified from page https://cafeconnect.by/catalog/sales/gadgets/iphone/iphone_7/iphone-7-256gb---product-red/ to the similar page https://cafeconnect.by/catalog/gadgets/iphone/iphone_7/iphone-7-256gb---product-red/
So we consolidate the product, which is in the ‘Sale’ category with the main page of this product.
3.2.2. Pages with GET-Parameters
Depending on the site’s CMS, different pages can be created with GET-parameters. For example, pages with a different language version.
Example:
rel="canonical" is specified from the page https://32norma.com.ua/dlya-hirurga/kost-i-membrana/mucoderm.html?sl=ru to the page https://32norma.com.ua/dlya-hirurga/kost-i-membrana/mucoderm.html
These pages differ only by GET-parameter, so they can be successfully consolidated.
Keep in mind that in practice search engine actions do not always meet our expectations. Even if you specify one canonical page, Google may choose another for it. It depends on many factors, for example, on the materials on the page or its effectiveness in Google. There is no clear list of reasons affecting this choice, and specialists can draw conclusions only on experience and logic.
4. Canonical URL on Another Domain
The canonical can be in a different domain than a duplicate.
In the case of low uniqueness, a search engine can consider the page as a duplicate of the page on another resource.
Example from the recent project:
We changed the domain, the site was removed from the old domain. But even after a month and a half, Google considers the pages of the new site as duplicates of the old one.
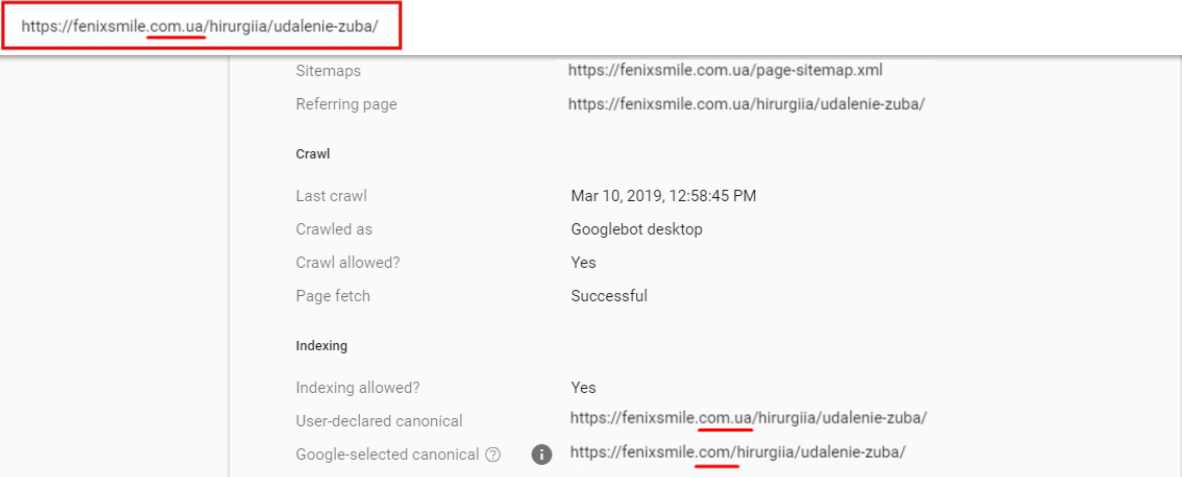
The Search Console contains the domain of the canonical page since both sites have been added to the account. In other situations, it is noted that ‘this page does not apply to your resources.’
How to fix it?
Rewrite content on the page, maximize its uniqueness and hope for the best.
5. How to Find Canonical Issues Using Netpeak Spider
You can make sure that rel="canonical" is set correctly and leads to a page with 200 server response code using Netpeak Spider.
You can detect canonical issues absolutely for free → Netpeak Spider crawler has a free version that is not limited by the term of use and the number of analyzed URLs. Other basic features are also available in the Freemium version of the program.
To get access to free Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
Crawler detects several types of canonical issues:
- canonical Blocked by Robots.txt
- canonical Chain
- identical Canonical URLs
To find these issues, you need to:
- Start Netpeak Spider.
- Go to the ‘Parameters’ tab in a sidebar and tick ‘Canonical URL’ and ‘Canonicals’ parameters.
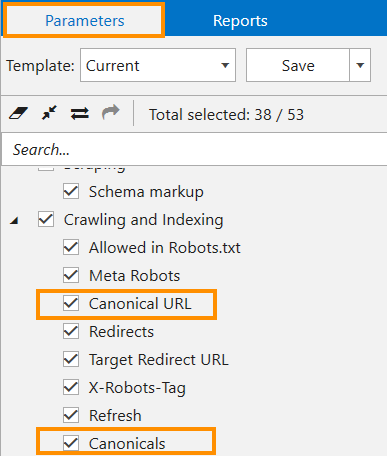
- Insert the analyzed domain into the search bar and click the ‘Start’ button to start crawling.
- When crawling is finished, review ‘Reports’ tab → ‘Issues’.
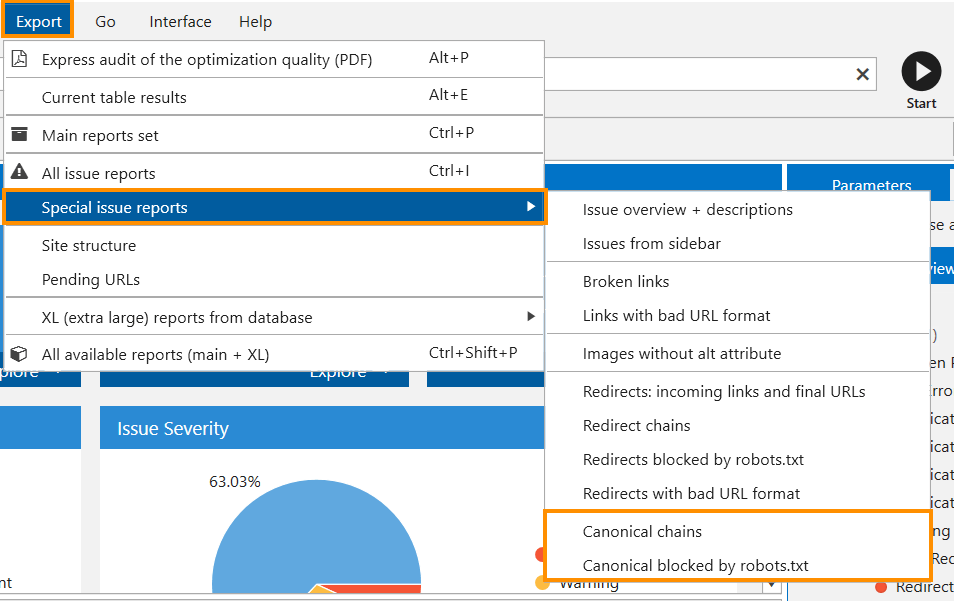
- Use the ‘Export’ → ‘Current table results’ to upload the filtered results for each issue.
- If it’s necessary, export all Canonical tag data into a separate file. To do this, click on the button ‘Export’ → ‘Special issue reports’.
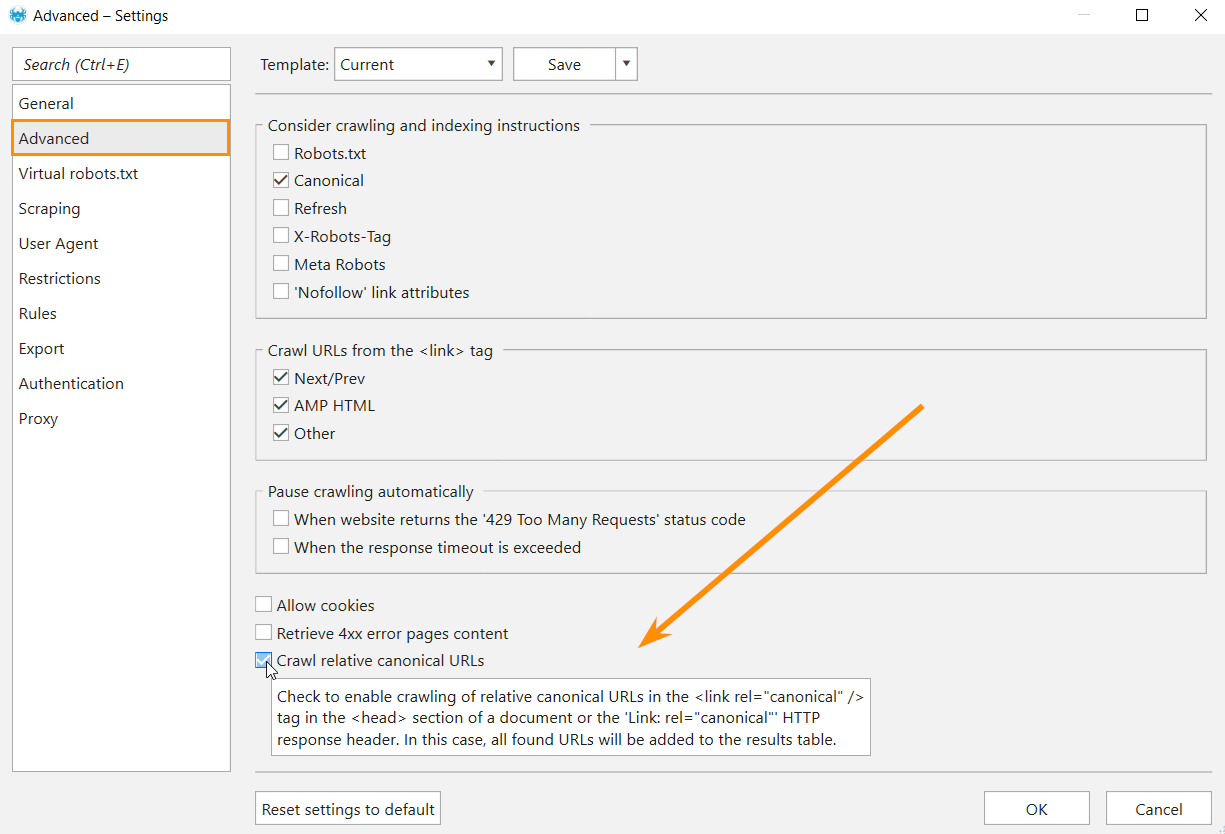
Pro tip: Google recommends using only absolute URLs in canonical. But after additional research, we found out it’s necessary to show the relative URL in canonical as an issue instead of just not crawling it. So to find canonicals with relative URL, go to ‘Settings’, select the ‘Advanced’ tab, tick ‘Crawl relative canonical URLs’ and click ‘OK’.
6. Summing up
The rel="canonical" attribute is practically the most effective way to specify canonical pages. But it is considered by the search engine as a recommendation and does not always affect the Google choice.
Make sure that:
- you set rel="canonical" correctly
- the page is enough unique
- all important pages are available for indexation
Useful links:
- How to define a canonical page for similar or duplicate pages – Search Console Help.
- How to block crawling of parameterized duplicate content – Search Console Help.
- Duplicate content – Search Console Help.
Share how do you find and fix canonical issues in the comments below ;)


