Атрибут rel=canonical как способ борьбы с дубликатами
Кейсы

Уникальность и качество контента на странице — одни из влияющих факторов ранжирования сайта. Дубликаты страниц внутри сайта наносят ущерб его поисковому продвижению. Как следствие — сайт хуже ранжируется в органическом поиске.
В рамках этого поста я расскажу, как поисковые системы определяют канонические страницы, в чём причины появления дубликатов, а также как найти канонические ошибки на своём сайте.
1. Какие страницы считаются каноническими, а какие — дублями?
Если на вашем сайте одна и та же страница доступна по нескольким URL, или разные страницы содержат похожий контент (например, версии для мобильных устройств и компьютеров), Google будет считать один из этих URL каноническим, а остальные — его дубликатами. Сканирование канонического URL будет выполняться намного чаще, чем его копий, поэтому очень важно убедиться, что Google определил каноническими именно те страницы, которые таковыми и являются.
Атрибут rel="canonical" устраняет дубли, «склеивая» копирующие друг друга страницы и, таким образом, позволяет улучшить ранжирование сайта. Но в отличие от 301 редиректа (Moved Permanently), который перенаправляет пользователей на нужную страницу, атрибут rel="canonical" предназначен только для роботов. На взаимодействии пользователей с сайтом это никак не сказывается.
2. Как Google определяет канонические страницы?
Канонические страницы выбираются по ряду критериев (сигналов). Ими могут быть:
- протокол (http или https),
- предпочтительный для пользователя домен,
- качество страницы,
- присутствие URL в файле Sitemap,
- наличие маркера rel="canonical".
Стоит отметить, что даже если вы сообщите Google о своём выборе, система в качестве канонической может быть выбрать иную страницу по собственному усмотрению.
Канонический атрибут используется в следующих случаях:
- необходимо сохранить страницы с частично дублирующимся контентом;
- возникают сложности при удалении или предотвращении появления дублей;
- сложно реализовать 301 редирект;
- на сайте автоматически создаются версии страниц для печати;
- на сайте содержатся страницы фильтрации.
3. Как можно указать каноническую страницу?
Чтобы задать атрибут rel="canonical", нужно разместить его в блоке
страницы, прописав тег вида <link rel="canonical" href="https://example.com/a"/>, где https://example.com/a — адрес канонической страницы. Указывая URL канонической страницы, важно ставить абсолютную ссылку (полный адрес, включая http:// или https://). Это снизит риск появления ошибок в HTTP.Существуют следующие нюансы:
- Тег rel="canonical" → работает только для HTML-страниц.
- HTTP-заголовок rel="canonical" → работает для всех типов страниц.
- Файл Sitemap → менее значимый сигнал для робота Googlebot, чем атрибут rel="canonical".
3.1. Когда rel="canonical" не склеивает страницы
- Склеивание http и https версий сайта (в таких ситуациях нужно проставлять постраничный редирект).
- Склеивание страниц с www и без (в таких ситуациях нужно проставлять постраничный редирект).
- Когда контент страниц значительно отличается. В таком случае Google не будет следовать рекомендации, указанной в теге rel="canonical".
У нас в Ask Inweb был подобный вопрос, ознакомиться с комментарием эксперта можно тут.
3.2. Когда rel="canonical" склеивает страницы
Тег rel="canonical" склеивает страницы только в том случае, когда каноническая страница, выбранная Google и пользователем совпадают. Для этого контент данных страниц должен быть максимально идентичен.
Рассмотрим основные случаи, когда rel="canonical" успешно склеивает страницы.
3.2.1. Один товар по разным URL-адресам
Если страница с максимально идентичным контентом доступна по двум URL, один из которых выбран в качестве канонического.
Пример:
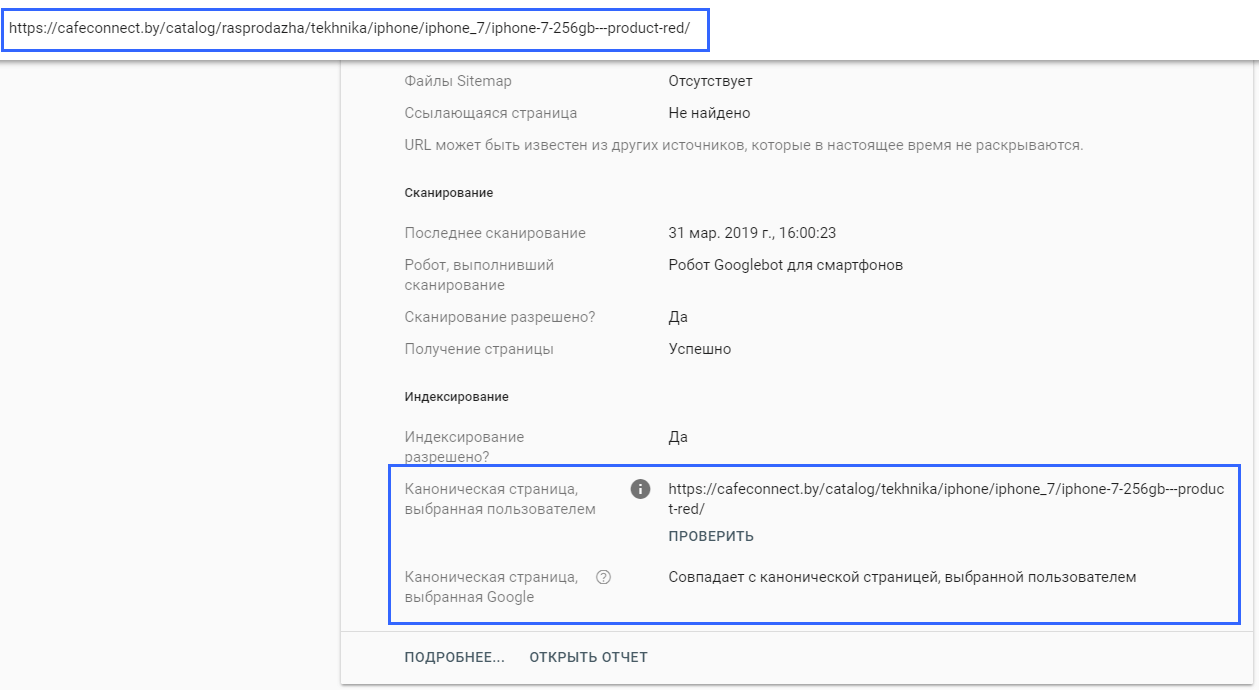
Со страницы https://cafeconnect.by/catalog/rasprodazha/tekhnika/iphone/iphone_7/iphone-7-256gb---product-red/ прописан rel="canonical" на очень похожую страницу https://cafeconnect.by/catalog/tekhnika/iphone/iphone_7/iphone-7-256gb---product-red/
Таким образом мы склеиваем товар, который находится в категории «Распродажа» с основной страницей данного товара.
3.2.2. Страницы с get-параметрами, не влияющие на содержание документа
В зависимости от CMS-системы сайта создаются различные страницы с get-параметрами, например, указанием языковой версии.
Пример:
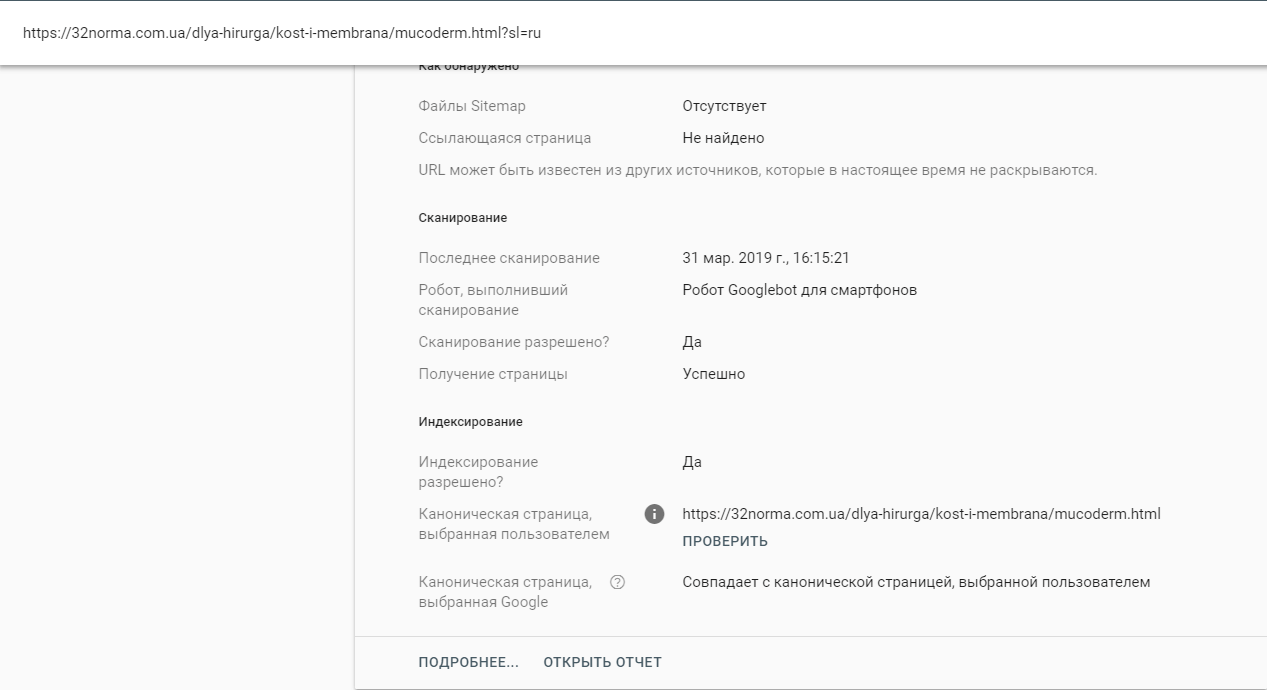
Со страницы https://32norma.com.ua/dlya-hirurga/kost-i-membrana/mucoderm.html?sl=ru прописан тег rel="canonical" на страницу https://32norma.com.ua/dlya-hirurga/kost-i-membrana/mucoderm.html
Так как эти страницы отличаются лишь наличием get-параметров, их можно успешно склеить.
Стоит отметить, что на практике действия ПС не всегда соответствуют нашим ожиданиям. Даже если вы укажете одну каноническую страницу, Google может выбрать в качестве таковой другую. Это зависит от многих факторов, например, от представленных на странице материалов или её эффективности в Google. Чёткого перечня причин, влияющих на выбор системы, не существует, а выводы специалистов строятся только на опыте, логике и догадках.
4. Канонический URL на другом домене
В случае низкой уникальности, ПС может воспринимать страницу дублем страницы постороннего ресурса.
Пример из недавней практики:
Мы поменяли домен, удалив сайт на старом домене, но даже по истечению полутора месяцев Google считает страницы нового сайта дубликатами старого.
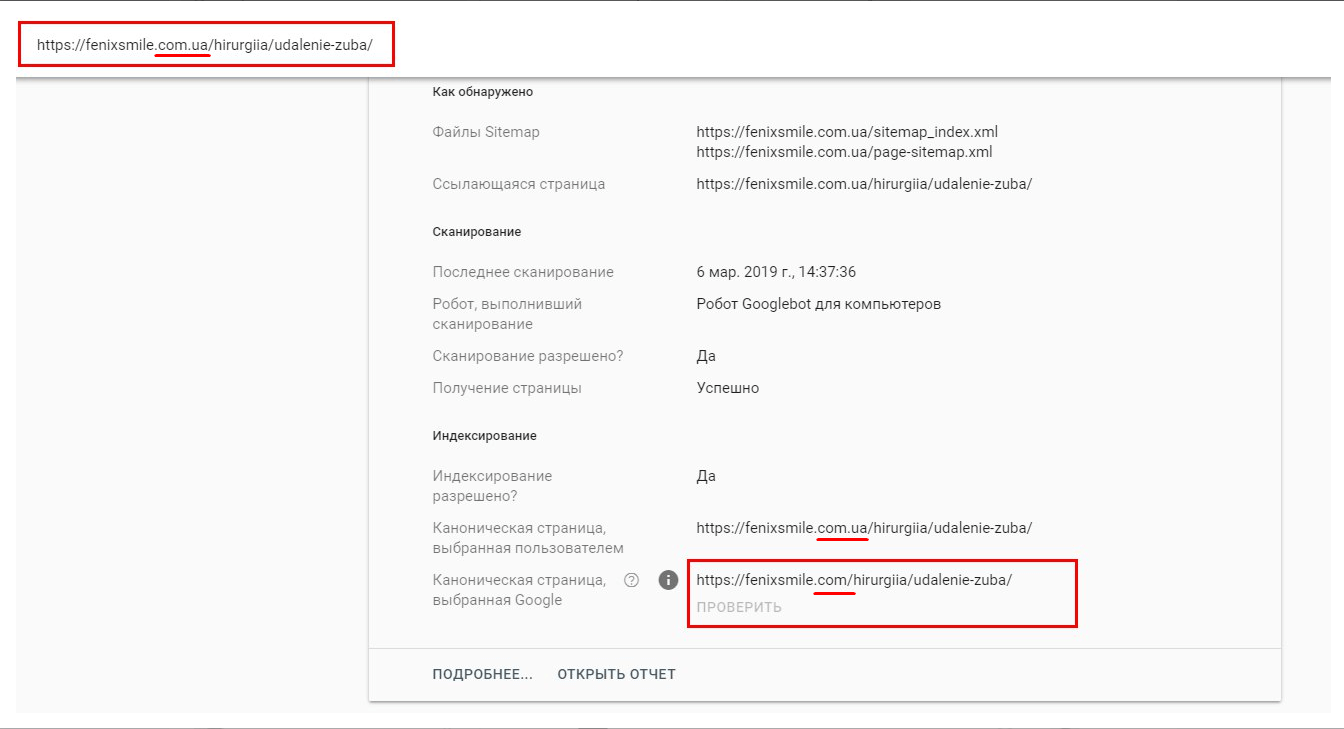
В Search Console указан домен канонической страницы, так как в аккаунт добавлены оба сайта. В других ситуациях отмечается, что «данная страница не относится к вашим ресурсам».
Что делать?
Переписывать контент на странице, максимально повышать уровень его уникальности и надеяться на лучшее.
5. Как найти канонические ошибки в Netpeak Spider
Убедиться, что rel="canonical" выставлен корректно и ведёт на страницу с 200 кодом ответа сервера, можно с помощью Netpeak Spider. Краулер определяет несколько типов канонических ошибок:
- canonical, заблокированный в Robots.txt;
- цепочка canonical;
- дубликаты canonical URL.
Поиск ошибок проводится в следующем порядке:
- Запустите Netpeak Spider.
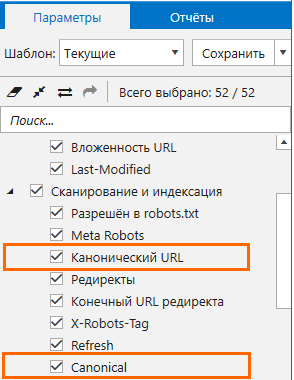
- Откройте настройки программы и перейдите на вкладку «Параметры» на боковой панели.
- Проверьте, отмечены ли параметры «Canonical» и «Канонический URL» в пункте «Индексация».
- Вставьте в строку поиска анализируемый домен и нажмите кнопку «Старт» для запуска сканирования.
- По итогу сканирования ознакомьтесь со всеми найденными ошибками на вкладке боковой панели «Отчёты» → «Ошибки».
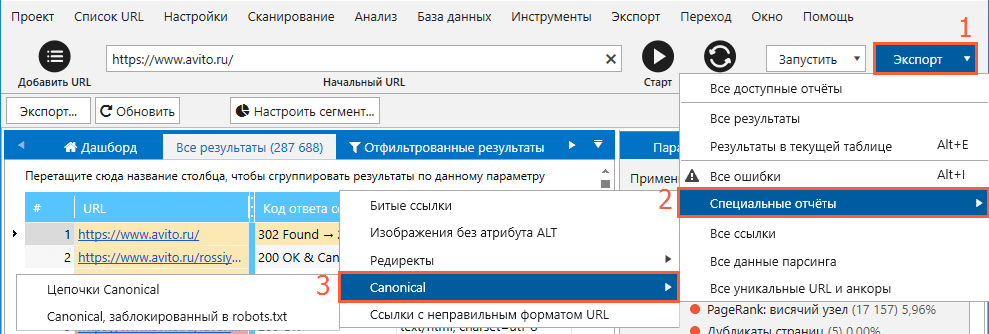
- Воспользуйтесь опцией «Экспорт» → «Результаты в текущей таблице», чтобы выгрузить отфильтрованные результаты по каждой отдельной ошибке для передачи данных разработчику.
- При необходимости экспортируйте все данные, связанные с тегом сanonical, в отдельный файл. Для этого нажмите в правом верхнем углу окна на кнопку «Экспорт» → «Специальные отчёты» → «Canonical».
Находить канонические ошибки и другие ошибки технической оптимизации вы можете в бесплатной версии Netpeak Spider без ограничений по времени! Также во Freemium-версии доступны и другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.6. Подводим итоги
Атрибут rel="canonical" — практически самый действенный инструмент в процессе указания канонических страниц. Но даже он воспринимается поисковой системой как рекомендация и не всегда влияет на выбор Google.
Необходимо убедиться в том, что:
- вы правильно разместили rel="canonical",
- уникальность страницы соответствует необходимому уровню,
- все значимые страницы сайта доступны для индексации.
Полезные ссылки по теме:
- Как консолидировать повторяющиеся URL — справка Search Console.
- Как предотвратить сканирование одинаковых страниц, URL которых различаются параметрами — справка Search Console.
- Повторяющийся контент — справка Search Console.
Расскажите в комментариях, как вы ищете и устраняете канонические ошибки на своих сайтах ;)
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider



