Page is Not Indexed: Discovered — Currently Not Indexed Issue
Site Audit Issues

Content:
- What Does Discovered — Currently Not Indexed mean?
- What Causes the Discovered Currently Not Indexed Error?
- How to Do Website Audit With Netpeak Spider?
- Conclusion
Website owners can regularly face the "Page is Not Indexed: “Discovered — Currently Not Indexed” issue. It indicates that the search engine found a webpage but has not yet added it to its index. That means that the page is not currently visible on the search results. So why, if the page exists, is it not crawled – currently not indexed?
Netpeak Spider will gladly share all the insights on the matter and offer its services for the proper website audit, which will help detect and resolve all of the issues you currently have.
What Does Discovered — Currently Not Indexed mean?
If you see a message that says “Discovered — currently not indexed” in the Google Search Console, it means that Google knows about this link but hasn’t crawled and indexed it yet. What does indexing mean in SEO? A search engine's index organizes the information and websites they are aware of. Basically, no indexing means no ranking for a search engine. Of course, Google may revisit the page later without your intervention, but still, it’s better to take action to ensure the correct indexing.
Aside from Discovered — currently not indexed, there is also a Crawled currently not indexed issue. If Google crawled but not indexed your pages, they go to the Excluded category in Google Search Console.
Different factors may prevent Google from crawling and indexing the page. Among these factors are server matters, technical issues on websites that limit or prevent Google's crawling ability, and problems associated with the quality of pages. Let’s take a closer look at the reasons for such page indexing issues.
What Causes the Discovered Currently Not Indexed Error?
So why is Google not indexing my pages? When you own a large website, there might be several reasons why you face a Discovered — Currently Not Indexed issue:
Server capacity problems
If your website has limitations on crawling, Google’s ability to search and index web pages may be disrupted. As your website expands, it will need more bots to crawl its content. This can be further done by bots from Microsoft, Apple, and other legal sources linked to data scraping.
Many bots can use server resources to crawl content for big websites, particularly in the evening (the most overloaded time). To efficiently handle a website with many pages, use a dedicated server or a cloud host. Cloud servers offer scalable resources such as bandwidth, GPU, and RAM, making them capable of hosting large websites.
Content overload
Your website may have a lot of content that Google doesn't want to crawl. If your website uses parameters like eCommerce product filters, you can stop Google from crawling those pages by disallowing them in the robots.txt file. Additionally, you should remove low-quality content such as duplicate content, outdated information, or pages with low traffic. The key is to make your content more unique so that Google will crawl and index it.
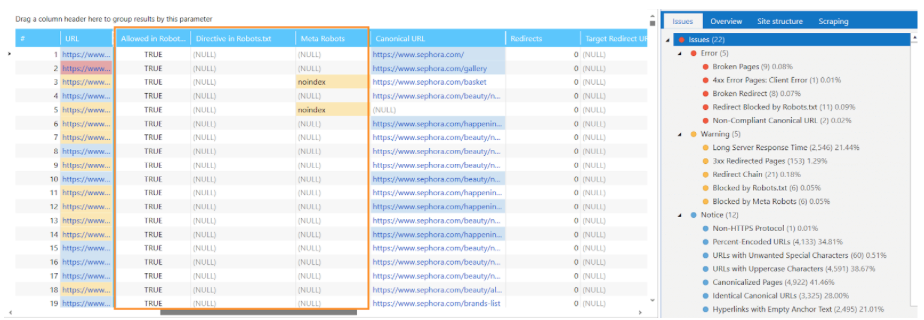
Internal linking structure
Incorporating internal links within your website is essential to ensure its proper functioning. Google commonly ignores URLs with no internal links or an insufficient number of them and may even remove them from its index. It’s crucial to create a coherent and logical structure with internal links to improve the optimization of your website. A possible solution is to use HTML sitemaps to establish connectivity among all your internal pages.
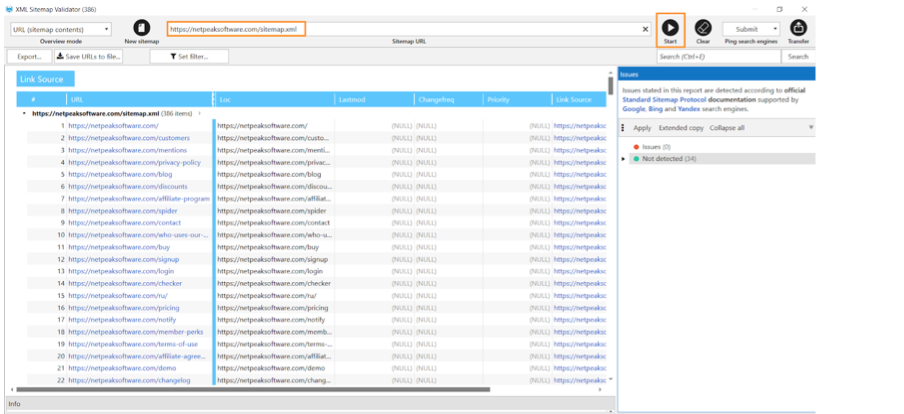
Content quality issues
Google evaluates the quality of a page, even when it hasn’t been crawled yet. Instead of directly rating the page, Google makes the presumption based on other pages in the same domain, considering link patterns and website structure. Thus, pages that seem low-quality compared to others may be lowered to crawl.
Shallow central content, poor presentation, lacking supporting content, unoriginal content, and manipulative ones such as auto-generated or duplicated content can be signs of bad quality. Overall, enhancing the quality of content within the website and specific pages should strengthen Google's interest in crawling your page.
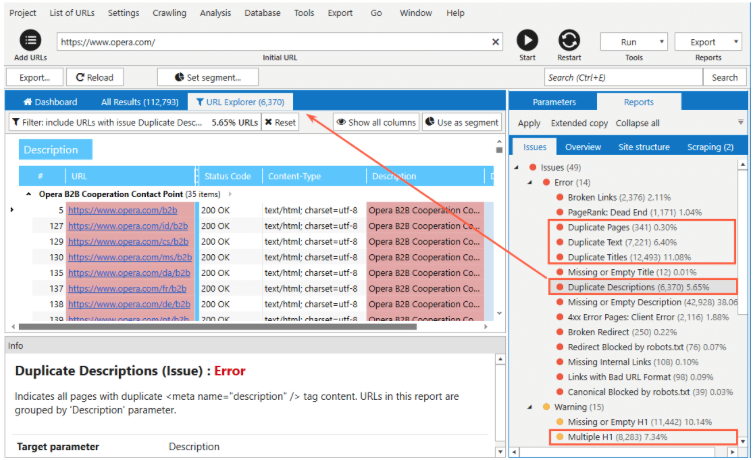
You can also noindex pages on your website that are not good quality. This can improve the ratio between good- and bad-quality pages on your site.
How to Do Website Audit With Netpeak Spider?
A full technical SEO audit lets you identify essential problems that complicate your progress toward the top of SERP. If you face issues such as the page is not indexed: crawled — currently not indexed or discovered — currently not indexed, you definitely require a friendly website crawler. Netpeak Spider is ideal when you need an all-in-one crawler to check if your website functions correctly. Below are some of the beneficial features Netpeak Spider provides its users.

Crawl Budget Optimization Audit
The crawl budget is the total number of web pages on your website that Googlebot can crawl. The crawl budget audit is crucial for large websites with a high volume of links, for instance, an eCommerce site with filtering search functionality. This type of audit uses segmentation methods. After it’s complete, you will receive the following issue reports:
- Compliant pages with low PageRank. Such pages should get more link equity than non-compliant pages to increase website traffic. Find pages that don’t have link equity and add internal links to them.
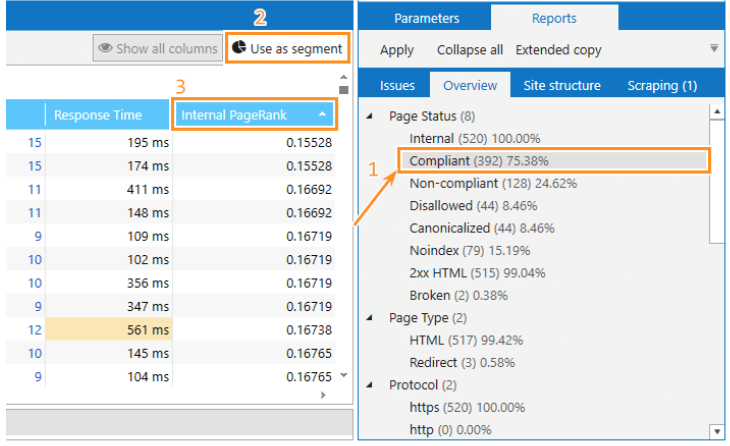
- Non-compliant pages with high PageRank.
- Pages with a click depth far from the “5” value of the first page. Identify which important pages are located far away from the first one using a click-depth segment.
- Pages without link equity.
Media Files Audit
Another critical aspect of promoting a website that you need to focus on is optimizing images. It can help you adhere to search engines' recommendations on visual content on web pages. Netpeak Spider looks at major issues related to images and other media files (including audio and archives) with topics including “Images without ALT Attributes,” “Max Image Size,” and “Other SEO Issues.” You can identify general issues, such as redirects and broken links for media files, and any new reason preventing your videos from being indexed. Just crawl the website using default program settings to audit image and audio-related issues. After the crawling is completed, you can use the segmentation feature to filter out results:
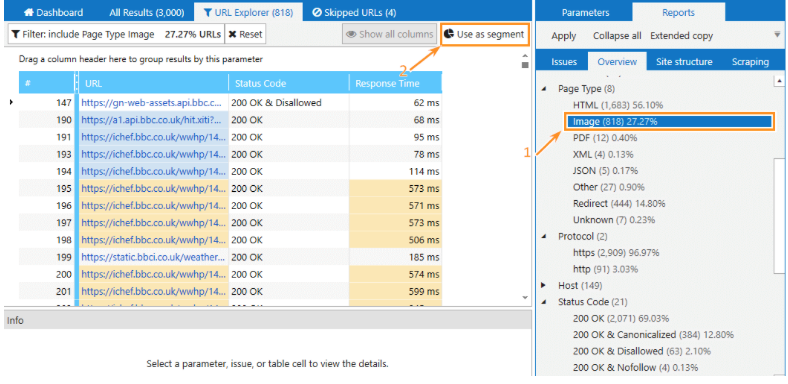
Internal Linking Audit
Internal linking plays a vital role in search engine indexing. That’s why Netpeak Spider has an in-built “For PageRank” parameters template that collects information regarding internal and external links through the whole website, including anchor texts, rel attribute values, and link types. The Database module contains all reports.
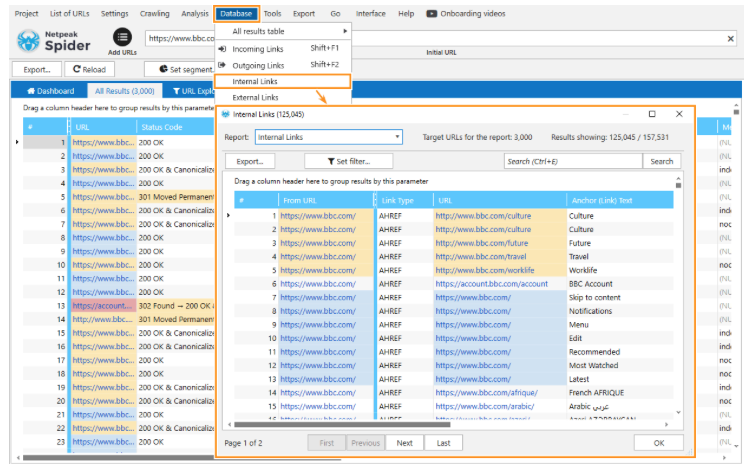
The program also sheds light on the link equity distribution, pages with bad link equity, and insignificant pages with high PageRank. The “Internal Pagerank calculation” tool determines adverse effects on link equity and gives an overview of how the link equity is distributed.
Dashboards and Reports Building
After crawling the website with Netpeak Spider, you will have access to several essential diagrams, such as:
- Intuitive dashboards that will allow you to get project insights. You can easily export and share the project’s “health score.”
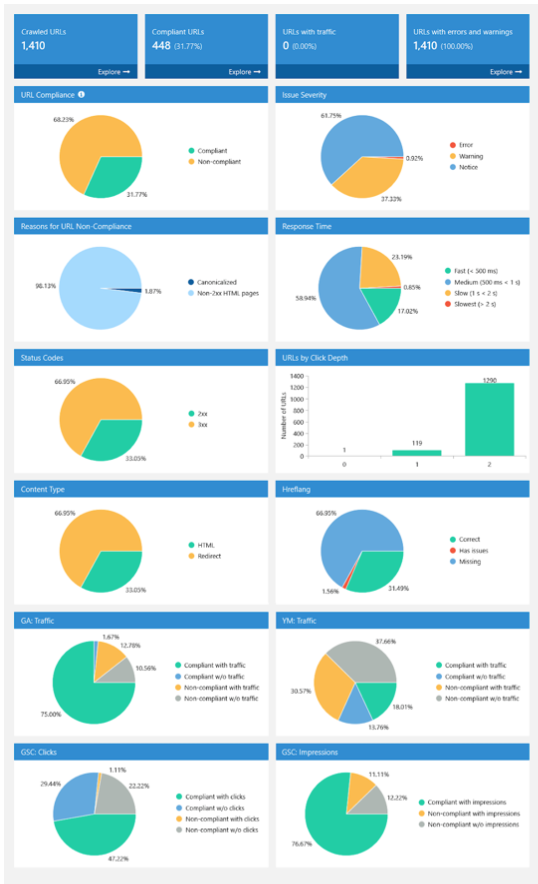
- Program tables that efficiently manage large data sets. These include grouping, sorting, quick search, custom filters, internal databases, and a convenient context menu.
- Highlight over 100 SEO problems with our software by color-coding them according to their severity level. For affected pages, click on issues and elaborate fix descriptions. Resources available to facilitate in-depth problem-solving.
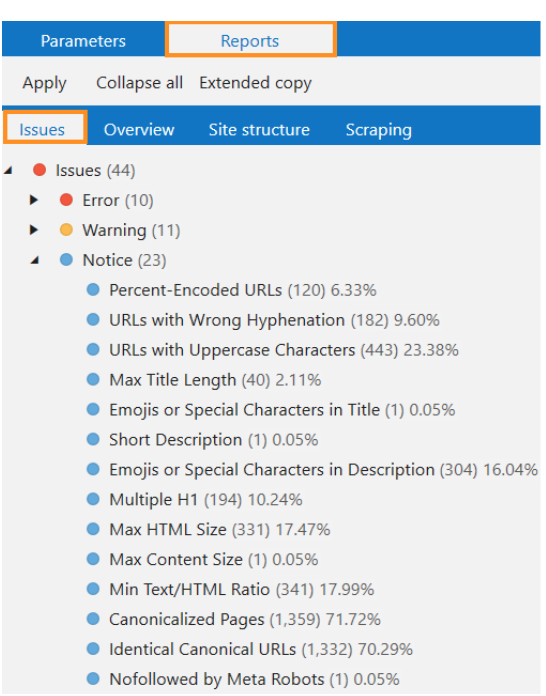
- The retrieved data helps the crawler to provide information on page status and file types.
- The next tab will look into the project site structure. Navigate link segments and examine the structure. Generate detailed reports on competitor analysis.
- The feature of scraping collects data from web pages. Extract prices, reviews, SEO texts, tags, and publication dates. Filter results by scraper for detailed analysis.

Conclusion
The search console uses the indexing status to determine the eligible web pages for ranking. If Google found a page but didn’t index it or crawled but not indexed it, it can mean the website has issues that require attention. Google has several reasons for not indexing a page it finds, including server overload and content quality issues. If you come across how to fix Crawled but not indexed or Discovered currently not indexed pages, frequent website monitoring with tools like Netpeak Spider is the answer. Our crawler has excellent features for solving many tasks and saving time on issue detection. Click here to audit your website and let Netpeak Spider take care of all the issues.
.png)
