Как найти и дооптимизировать старые статьи на блоге
Кейсы

Иногда ошибочно полагать, что старые статьи блога, которые приносят мало трафика или перестали приносить его вообще, нельзя реанимировать. Оптимизация старого контента способствует увеличению трафика не хуже, чем создание нового.
Вопрос только в том, как искать и грамотно дооптимизировать уже существующие статьи. Об этом я расскажу в своём посте.
1. Какие статьи нужно оптимизировать: типы
Я выделил четыре основных типа постов:
- Посты с большим падением трафика из поисковых систем. Такие посты уже приносили трафик, но со временем утратили актуальность либо же уступили место в выдаче более свежим (по дате публикации) постам.
- Старые посты с низким, практически нулевым трафиком. Они скорее всего были изначально не до конца оптимизированы, либо же освещали невостребованную тему.
- Статьи с устаревшей информацией.
- Статьи с частотной упущенной семантикой.
2. Как найти старый контент, который нужно оптимизировать
2.1. Поиск статей первого типа
Чтобы собрать посты первого типа, мне нужно выгрузить данные из Google Analytics по сеансам за два периода и сравнить их между собой, чтобы найти те, которые значительно просели.
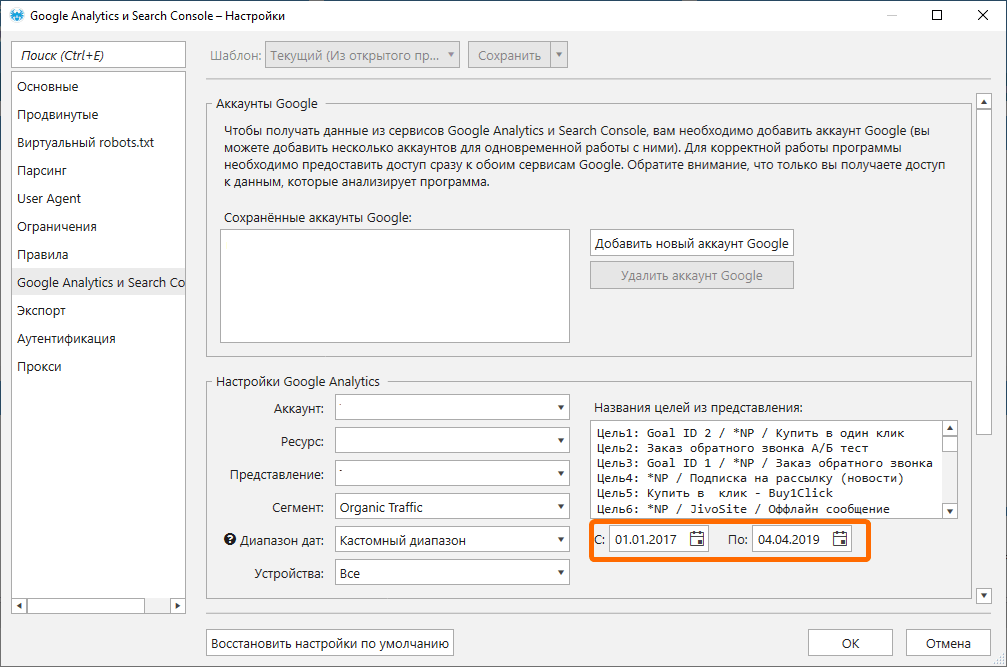
Первый период более давний: за начальную точку я беру дату создания блога, конечная — за полгода до того момента, когда приступаю к работе с этими статьями.
Таким образом я узнаю, сколько органического трафика они получали. Диапазон дат будет варьироваться на каждом проекте в зависимости от возраста блога.
Для получения и выгрузки данных я использую Netpeak Spider:
- В настройках «Google Analytics и Google Search Console» добавляю аккаунт Google. Выбираю нужный мне ресурс, представление и отмечаю диапазон дат для анализа трафика за давний период. Выбираю сегмент «Organic Traffic». Сохраняю настройки.
- На боковой панели включаю параметр «Сеансы» в группе «Google Analytics».
- Перехожу в главное окно и ввожу начальный URL сайта.
- Нажимаю «Старт». По окончании сканирования все данные попадут в основную таблицу.
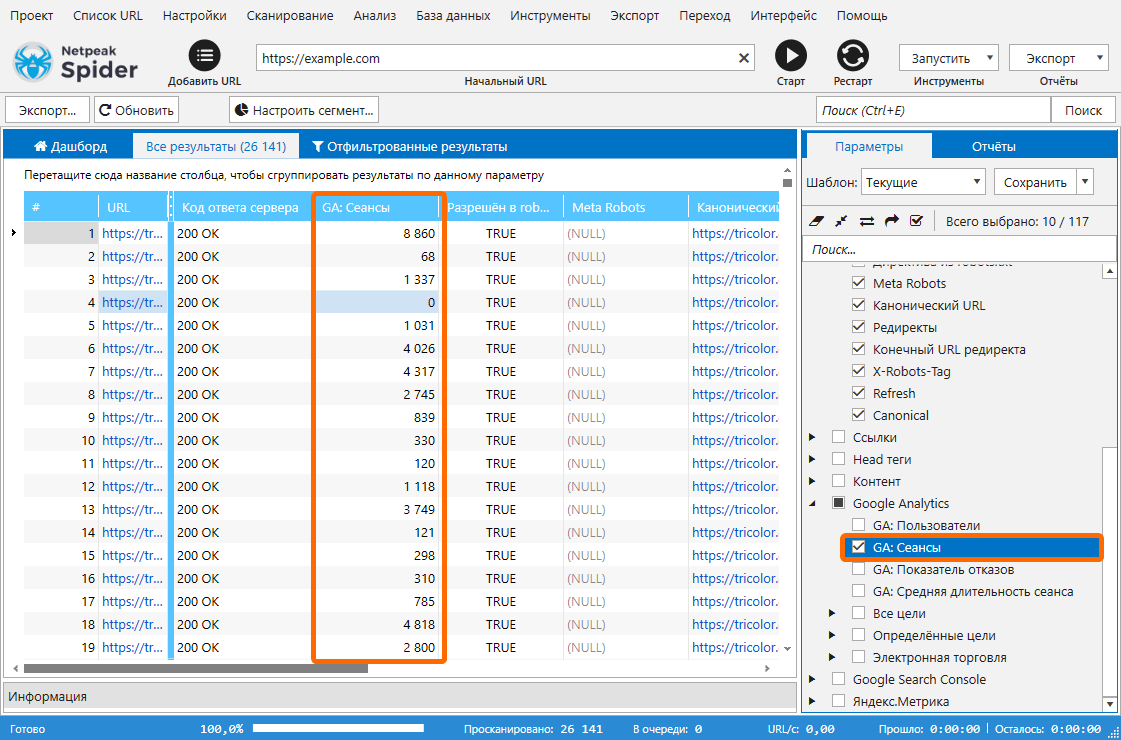
- Экспортирую данные из Netpeak Spider и заношу их в отдельную таблицу.
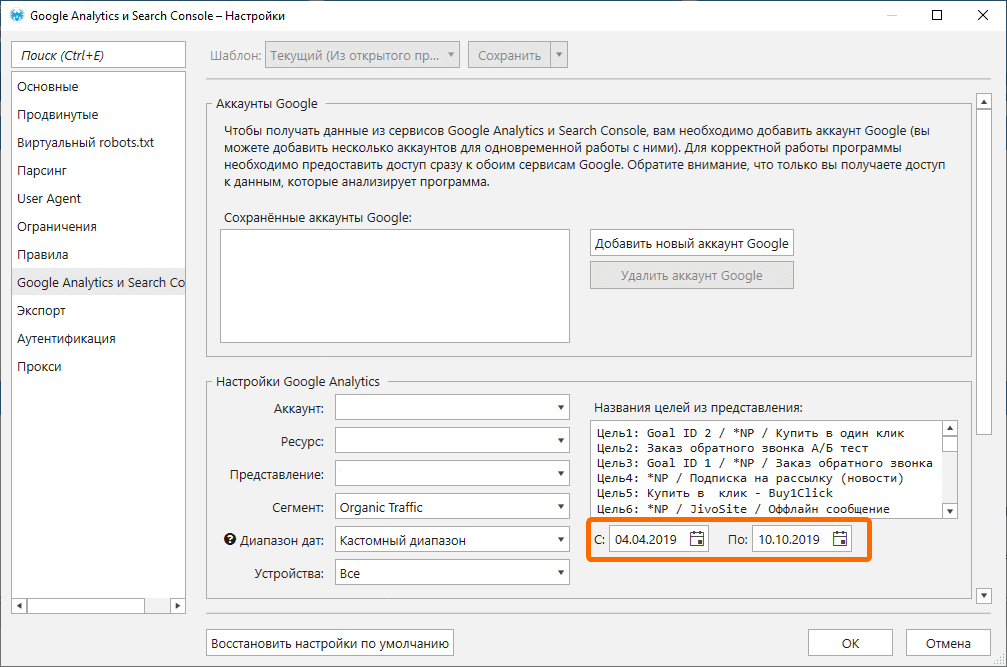
Таким же образом собираю данные по новым сеансам: начальная точка — за полгода до текущей даты, конечная — текущая дата.
Использовать интеграцию с Google Analytics и Search Console вы можете даже в бесплатной версии Netpeak Spider без ограничений по времени. Также во Freemium-версии доступны и другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.- Дату публикации. Самый важный показатель, так как помогает понимать актуальность.
- Количество просмотров.
- Показатели вовлечённости (апвоуты, шейры).
- Процент проседания — сколько осталось процентов трафика по сравнению с тем, что было раньше.
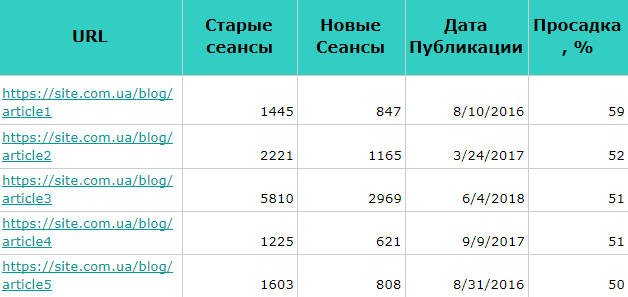
Данные по дате публикации, количеству просмотров и комментариев я получаю с помощью функции парсинга исходного кода.
2.2. Поиск второго типа статей
Здесь как раз понадобится дата публикации, чтобы определить причины, по которым статья не набрала сеансов: из-за плохой оптимизации или в силу своей новизны. Те, что были опубликованы давно и не набрали минимальное количество сеансов, и будут страницами, которые мы возьмём в работу.
2.3. Поиск третьего типа статей
Cтатьи с устаревшей информацией придётся искать вручную, так как с лёгкостью автоматизировать этот процесс не получится 😅
2.4. Поиск четвёртого типа статей
Искать посты с упущенной семантикой мне помогает Serpstat. В сервисе я по очереди вставляю каждый URL и после анализа перехожу в раздел «Упущенные фразы».
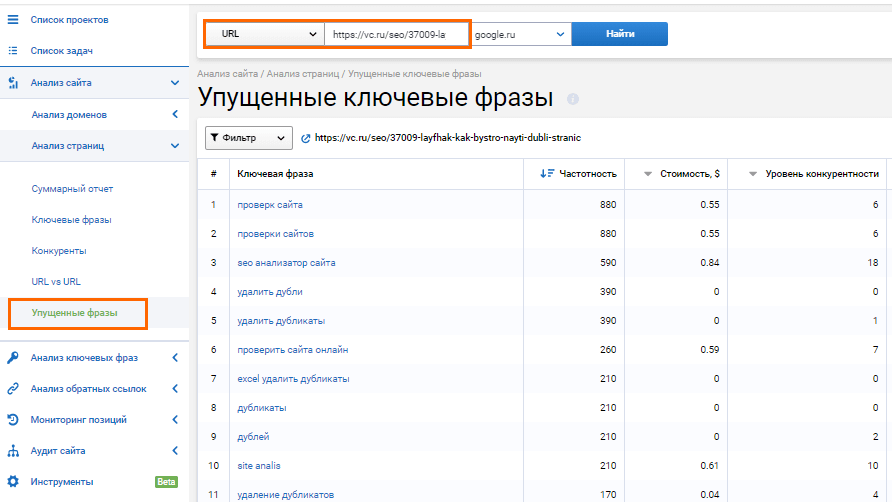
Всё это заношу в свою таблицу.
Чтобы быстро проверить упущенные фразы для группы страниц удобно использовать метод «URL Missing Keywords» в Serpstat API Console. Вот так выглядит условие, по которому можно получить нужные ключи:
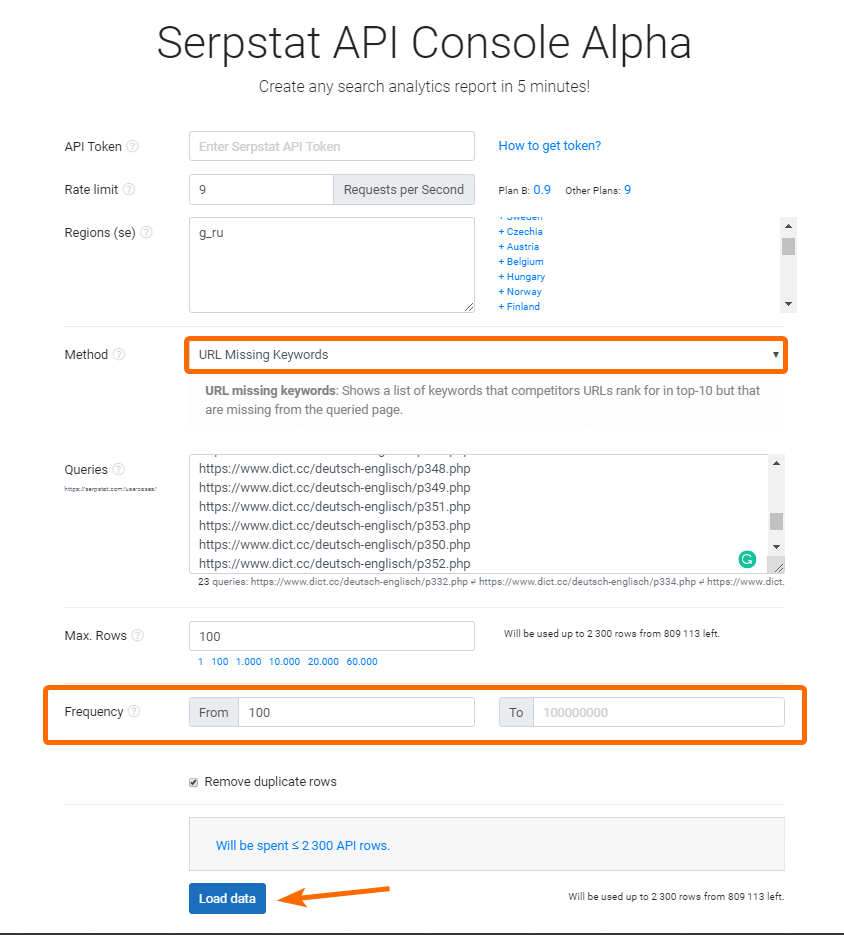
2.5. Какие статьи нужно удалить, а какие оптимизировать
После сбора всех типов статей необходимо понять, какие нуждаются в оптимизации, а какие требуется удалить, чтобы они не висели на сайте мёртвым грузом.
Удалять следует статьи, которые:
- Бесполезно актуализировать. Например, любые статьи-мануалы по Google+. Они не станут актуальными, так как социальная сеть уже закрыта.
- Получали очень низкий, практически нулевой трафик и их тематика не соответствует запросам вашей ЦА.
Какие статьи стоит дооптимизировать?
- Статьи с частотной упущенной семантикой.
- Статьи, которые получали трафик, но из-за устаревшей информации перестали приносить пользу, и их можно актуализировать.
3. Как дооптимизировать старые статьи
3.1. Улучшить техническую оптимизацию
Техническая оптимизация охватывает множество аспектов, я же выделил из них три самых главных:
- скорость загрузки сайта;
Способы по оптимизации скорости загрузки мы описали в посте «Как бороться с медленной загрузкой сайта с Netpeak Spider».
- внутренняя перелинковка;
- микроразметка.
Благодаря настройке этих базовых параметров технической оптимизации посетителям будет удобнее пользоваться вашим сайтом, поисковые роботы смогут получить больше информации о нём, а поисковики учтут эти позитивные изменения при ранжировании.
3.2. Работа с упущенной семантикой
Выше я уже рассказал, как искать упущенную семантику. После этого все ключевые фразы, собранные в Serpstat, я преобразовываю в кластеры. Удаляю мусорные и нерелевантные ключи, остальные фильтрую по отдельным кластерам и высчитываю суммарную частотность.
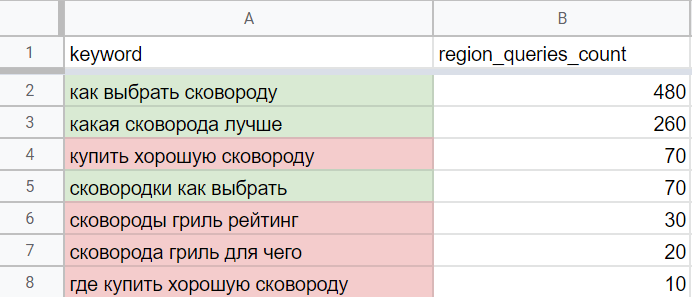
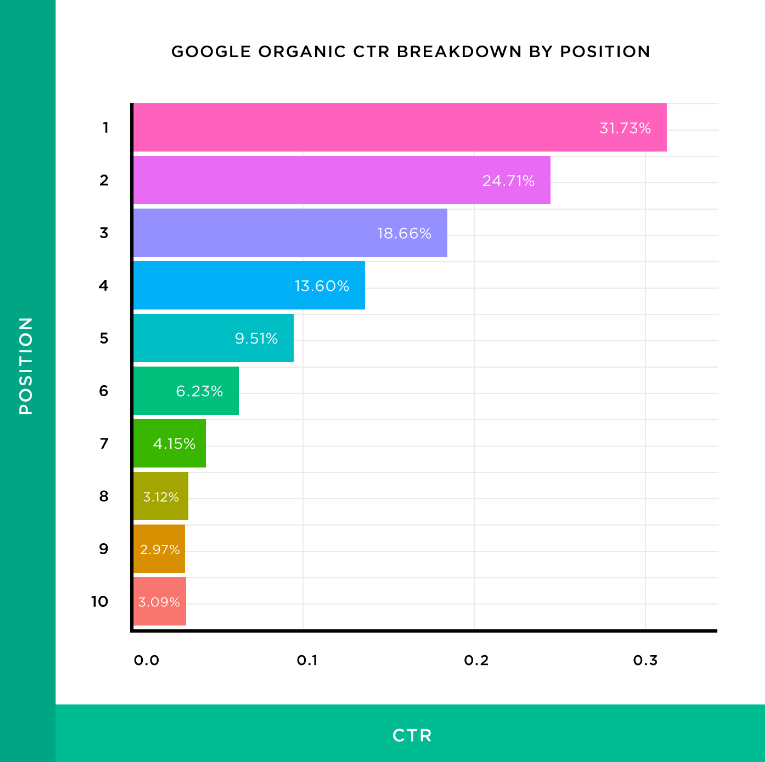
Далее оцениваю шансы попадания по этим фразам в топ по конкурентам в выдаче. Примерное количество трафика можно условно посчитать, умножив суммарную частотность на коэффициент CTR (исходя из того, на какой позиции в данный момент находится страница). Например, если вы сильнее ваших конкурентов и занимаете одну из топ-3 позиций, суммарную частотность можно умножить на более высокий коэффициент (~0.5).
Приблизительные коэффициенты вы можете взять из графика, который составил Брайан Дин на основе своего исследования.
Затем сравниваю кластеры между собой по количеству потенциального трафика и делаю прогноз, чтобы приоритизировать работу с кластерами запросов.
3.3. Дооптимизация старого контента
Когда у меня есть собранная семантика, я начинаю наполнять ею следующие элементы контента:
- title,
- meta description;
- заголовки H1-H3;
- первые абзацы текста.
Далее следует частичная или полная редактура статьи. Она нужна в тех случаях, когда текст написан сложным языком либо не полностью раскрывает тему.
Затем проверяю, оптимизированы ли изображения и видео в статьях.
Ещё один источник трафика для статьи: хороший контент в комментариях. Мотивируйте читателей блога писать содержательные и информативные комментарии, так как поисковики часто показывают страницу именно благодаря релевантности ответа в комментариях запросу пользователя. Хороший пример — блог Moz.com, где комментарии помогают получать больше информации по теме статьи.
3.3. Получение внешних ссылок
Вариантов получения бэклинков белыми способами много. Например, развивать сотрудничество с блогами похожих тематик: это может быть обмен ссылок, размещение ссылок по бартеру и т.д.
Через определённое время все описанные выше шаги придётся повторять по мере того, как будет устаревать контент.
4. Приоритизация задач
Я расставляю приоритеты по работе со старыми статьями в таком порядке:
- Статьи с упущенной семантикой.
- Статьи, которые получают показы по нерелевантным ключам.
- Статьи с неактуальными данными.
- Страницы с контентом, которые содержат ошибки технической оптимизации.
Каждый специалист приоритизирует задачи так, как считает нужным, и мои взгляды на это могут отличаться от ваших 😊
5. Что делать дальше?
Обязательный процесс после оптимизации статей — регулярное постраничное отслеживание изменений трафика. Так вы сможете понимать, какие именно работы приносят результат, и решать, на что стоит тратить ресурсы.
Я советую отслеживать изменения каждые 2 месяца.
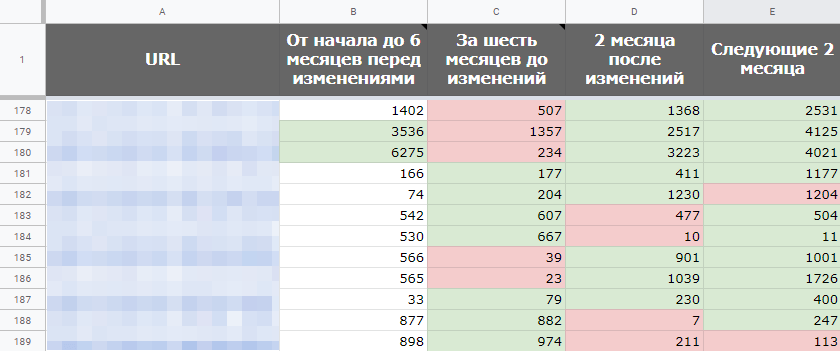
Подводим итоги
Чтобы увеличить трафик путём оптимизации старого контента, необходимо в первую очередь обозначить статьи, которые нуждаются в дооптимизации. Затем определить, в какие из них можно «вдохнуть новую жизнь», а какие реанимировать бесполезно. И только потом приступать к основным работам:
- улучшить показатели технической оптимизации;
- работать с упущенной семантикой;
- наполнять контент ключевыми словами;
- получать внешние ссылки на статьи.
И, конечно, после выполнения всех работ регулярно мониторить изменения трафика.
А как вы проводите оптимизацию старого контента? Буду рад, если поделитесь в комментариях 👇
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Checker



