How to Find and Fix Duplicate Content on Your Website
Use Cases

You have optimized your website, trying to make it more attractive, but search engines are reluctant to rank it? There could be many reasons for it. The most common one is duplicate content. If you don’t deal with it, you probably won’t succeed in promoting your website in SERP.
In this post, you’ll find out how to find and fix this issue with Netpeak Spider tool.
To get access to Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
1. What Is Duplicate Content and Why Is It Dangerous
Duplicate content represents pieces of information within one or several domains which are fully identical. In other words, if the same content is available by two different addresses, that’s duplicate content.
Duplicate content on your website is one of the negative factors that search engines consider and that can lower rankings in SERP.
Moreover, duplicates can cause many other issues including:
- Indexing issues. Due to limited crawl, budget search robots can’t index essential pages if there is a lot of duplicate content. There’s also a risk that the website will get penalized, and its crawl budget will be shortened.
- Issues with showing top priority page in organic search. Because of duplicate content, a copy of the page you wanted to promote can appear in SERP. And the other way around: pages will compete with each other and both won’t appear in SERP.
- Dispersion of internal and external PageRank.
2. Causes of Duplicate Content
The most widespread causes of duplicate content are:
- Errors in the content management system (CMS). If set up incorrectly, it can cause duplicates, while creating printer-only versions or archives. Frequently, the system generates several URLs for one article various website sections may contain.
- Redirection (301 redirect) is not set up after switching from http to https. The same for cases when there is no redirect to the main site mirror (if a website is available with and without www, with and without slash in the end).
- Incorrect setting and automatic link generation during website operation.
- Adding get-parameters and UTMs to the URL.
- Human factor. The webmaster may duplicate the page by mistake.
- Changes in website structure, when pages get new addresses while the old ones are not deleted.
3. Types of Duplicate Content and How to Fix Them
There might be several types of duplicate content within one site:
- completely duplicate pages (identical HTML code)
- duplicate text (<body> contents)
- duplicate Title (page titles)
- duplicate Description (page description)
- duplicate H1 (main heading)
Below we’ll describe each type and how to fix it.
3.1. Duplicate Pages
If all HTML-code of different pages is identical, so these pages are duplicates. If there are a few duplicates, the chance of being penalized by the search engine is very small. But if there are a lot of duplicate pages, it can cause the waste of crawling budget.
How to fix duplicate pages: set 301 redirects from duplicates to the main URL. If you have to delete the page, set 404 server response code correctly and delete all links to this page.
If duplicate pages should be available to visits and crawling, specify the main page using <link rel="canonical" /> tag or HTTP-header ‘Link: rel="canonical"’.
3.2. Duplicate Text
Pages with identical texts can have different titles and descriptions but search robots still consider them as duplicates.
How to fix duplicate text: replace the duplicate text with the unique one. You can set 301 redirects from unimportant for promotion pages to the main URL, or you can just delete them and set 404 response code.
3.3. Duplicate Title
Title tag plays a significant role in site optimization because it’s used as a title in snippets in SERP. Duplicates can cause appearing pages in SERP with inappropriate titles. In such cases, a search engine can make up a snippet title by itself but it will hardly be clickable for users. As a result, the traffic loss from SERP.
How to fix duplicate title: write a unique title for each page within your website. It has to explain users and search engines the page’s content and consist relevant search query. The recommended title length is from 40 to 140 characters.
3.4. Duplicate Description
A meta description tag affects snippet formation and directly CTR.
That’s why it’s important to write descriptions that reflect the page’s content and make users click on the snippet.
How to fix duplicate description: compose unique descriptions with relevant keywords for each page. The recommended description length is from 100 to 260 characters.
3.5. Duplicate H1
If pages with different content have identical H1 headers, search robots and users can consider website low-quality.
How to fix duplicate H1: write a unique, short and informative H1 containing from 3 to 7 words.
Read more → Content relevance checker
4. How to Find Duplicates
We’ve already found why duplicates can be dangerous and their types. Now we’ll deal with the main task – how to find them on your website.
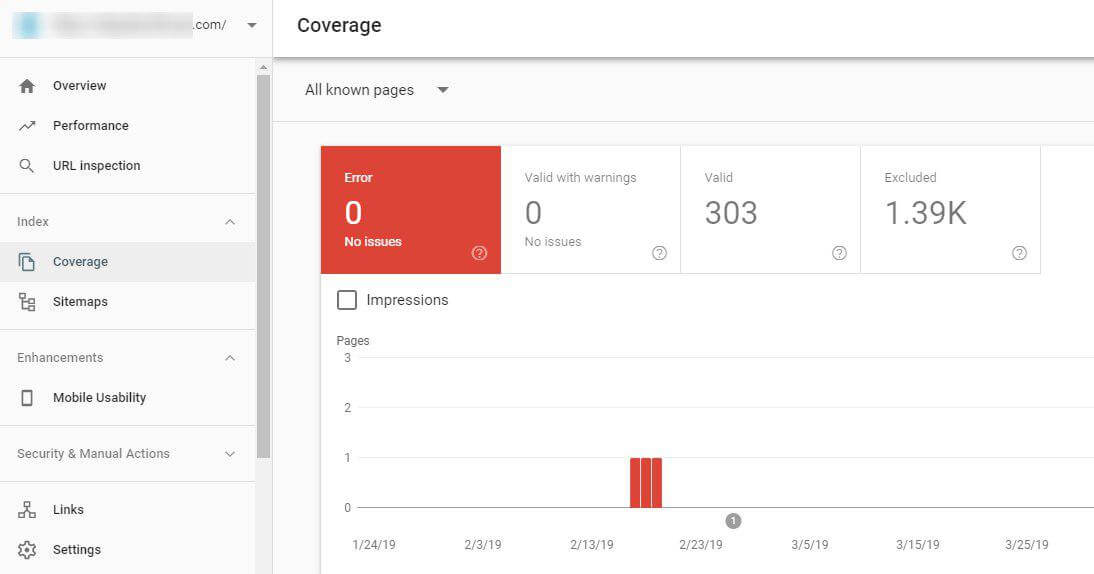
You can find them using Google Search Console.
Open ‘Coverage’ report in Google Search Console and if there are issues, look through them to find duplicates.
Also, you can find duplicates manually using site: operator. Paste the text’s fragment, then add a search operator and the domain to the search box.
To automate this process, you can use Netpeak Spider to find all types of duplicate content within your website. The tool will find all on-site duplicates and define them as errors and warnings.
In order to do it, you have to:
- Start Netpeak Spider.
- Go to the ‘Advanced’ section of the ‘Settings’ menu.
- Tick all boxes in the ‘Consider indexation instructions’ block. In case you have already taken care of duplicate content, setting instructions for crawlers and the Canonical attribute, then all prudently hidden duplicates will not appear in crawling results.
If hidden duplicates still appear in crawling results, you should pay attention and deal with them.
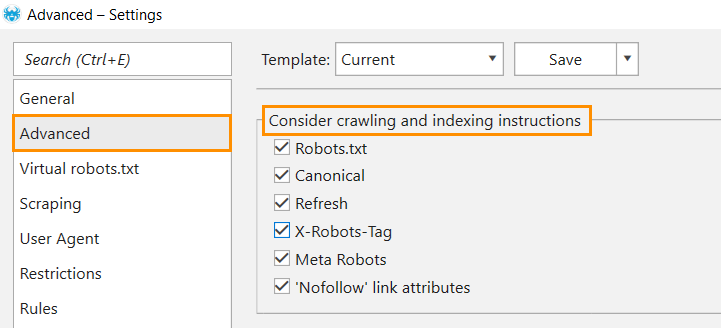
- Click ‘OK’ to save settings.
- Enter the website URL in the address bar and click ‘Start’ to start crawling.
- When crawling is complete, all detected issues, including the ones related to duplicate content, will be shown in the ‘Reports’ tab → ‘Issues’ in a sidebar. To filter results and only see the list of pages containing a certain issue, click on its name.
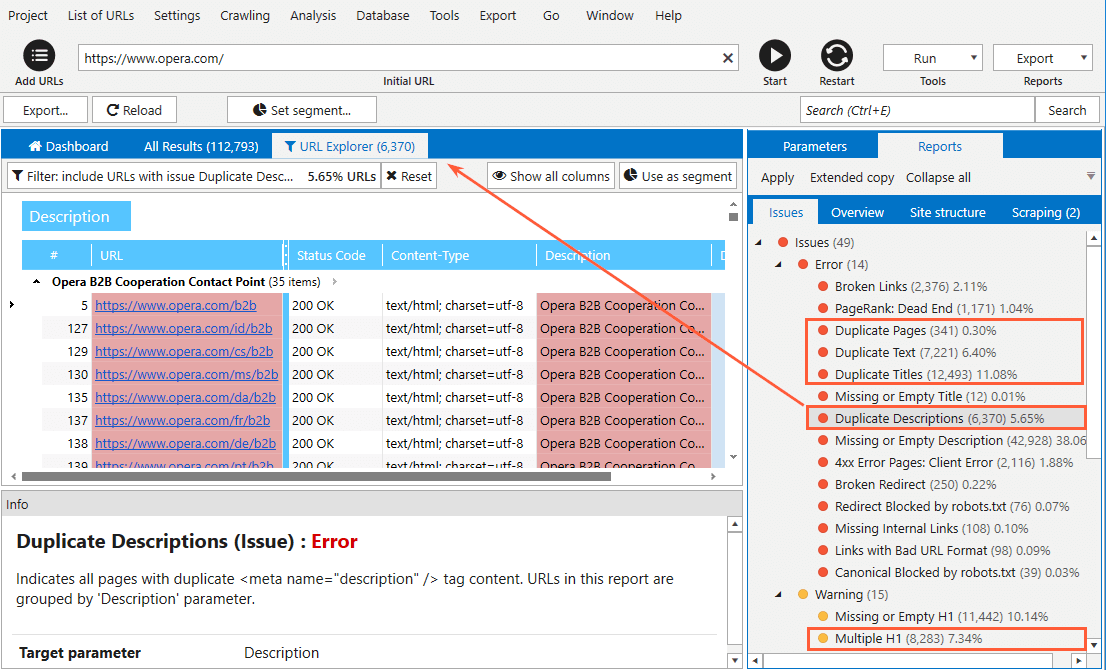
- Click ‘Current table results’ in the ‘Export’ menu to export filtered results.
5. How to Deal with Duplicate Content
To eliminate duplicate content on a website, you can use one of the following methods:
- 301 redirect. It helps to remove duplicates that are caused by:
- switching to a new CMS
- switching to secure protocol
- several website ‘mirrors’ – with and without www, with and without slash in the end
- different cases in URL
- The rel=”canonical” attribute. It helps when:
- both duplicate pages have to be available
- the website has a mobile version (or accelerated mobile page version), which may be defined as duplicate
- the website has pagination and filtration pages
- Setting search instructions using robots.txt, Robots meta tag and X-Robots-Tag to disallow indexing or following links with duplicate content.
Learn more about directives:
1. In robots.txt: 'What Is Robots.txt, and How to Create It'.
2. In X-Robots-Tag: 'X-Robots-Tag in SEO Optimization'.
In a Nutshell
Duplicates harm the promotion of pages in SERP. Your time and resources invested in optimization can be wasted because of them. Regular checking of the site for duplicates and their elimination is the best way to prevent the negative effects caused by them.
You can search for duplicates in Google Search Console, using the search operator or Netpeak Spider.
The most effective ways to get rid of duplicate pages:
- setting 301 redirecе to an important page for a promotion,
- implementation of the tag or the HTTP header ‘Link: rel =" canonical "’,
- deleting the page and setting 404 server response code.
To eliminate duplicates of title, description, and H1, it is necessary to create unique text on each page and it is recommended to arrange it according to the search engines recommendations.
Share your experience and anti-duplicate methods in the comments :)
Digging This Use Case? Let's Discuss Netpeak Spider Perks in Person



