Как проверить сайт на SEO-ошибки и найти точки роста трафика проекта: пошаговый мануал
Мануалы

Некомплексный подход к аудиту сайта — одна из распространённых ошибок агентств и фрилансеров. Тратя время и деньги на исправление одной ошибки на странице, вы можете не увидеть более серьёзные проблемы на всём сайте, которые тормозят продвижение.
Другими словами, без понимания картины происходящего есть большие риски неправильно приоритизировать задачи. Это повлечёт за собой не только слабую динамику результатов, но и большие затраты на их достижение.
В посте я расскажу, как избежать этих проблем с помощью инструмента, в котором можно регулярно агрегировать данные, быстро их анализировать, а также проводить анализ сайта на SEO-ошибки. Он поможет вам грамотно расставлять приоритеты, находить точки роста и эффективнее продвигать сайт.
- 1. Главные преимущества подхода
- 2. Основные этапы сбора данных для полноценного SEO-аудита
- 3. Что получаем в итоге
- 4. Как это применить
- 5. Нюансы, которые важно учитывать
- Подводим итоги
1. Главные преимущества подхода
Решение проблемы я нахожу в использовании онлайн-приложения Google Таблицы. Оно позволяет агрегировать данные, а также имеет ряд преимуществ, среди которых:
- Комплексность. Данные из разных источников находятся в одном месте.
- Скорость. Анализ данных, поиск инсайтов и точек роста происходит за минимальное количество времени.
- Доступность и простота. Google Таблицы — бесплатный и универсальный инструмент для агрегации данных.
- Кастомизируемость. Возможность менять, удалять, добавлять данные в любой момент времени.
2. Основные этапы сбора данных для полноценного SEO-аудита
Я буду описывать подход на примере интернет-магазина, но методика работает и с другими типами сайтов.
Этап первый. Сканирование сайта
Сканирование я провожу в краулере Netpeak Spider. Чтобы получить нужные данные, в программе задаю такие настройки:
- На вкладке «Настройки» → «Основные» выставляю количество потоков (в моём случае — 5). И отмечаю все пункты базовых настроек, кроме сканирования внутри раздела.
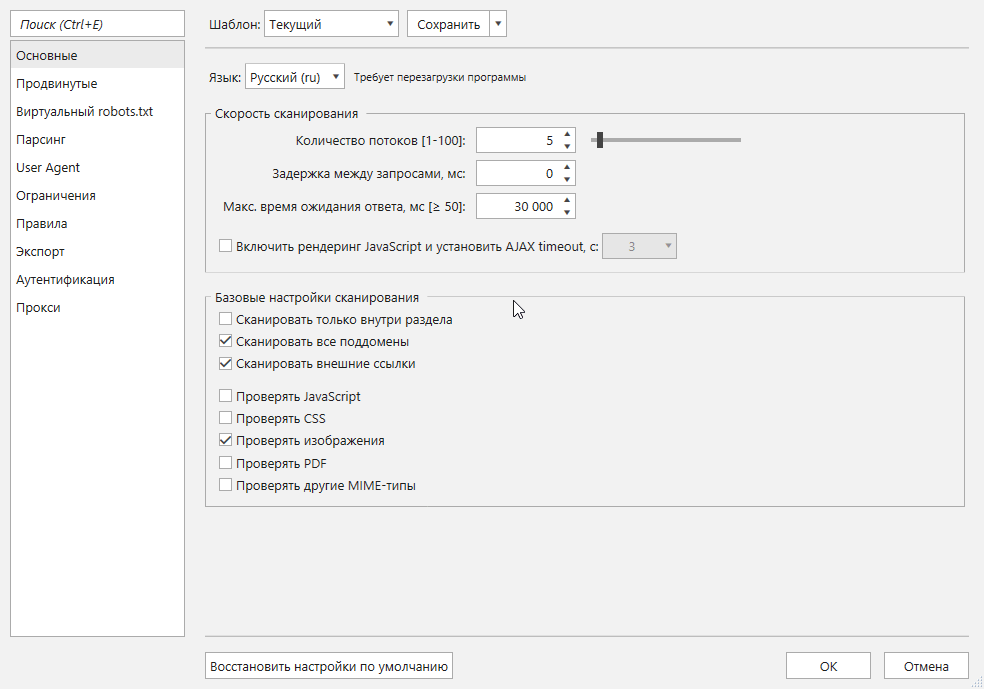
- На вкладке «Продвинутые» оставляю пустым чекбокс «Учитывать инструкции по сканированию и индексации». Это позволит найти большее количество страниц и проверить правильность настройки инструкций.
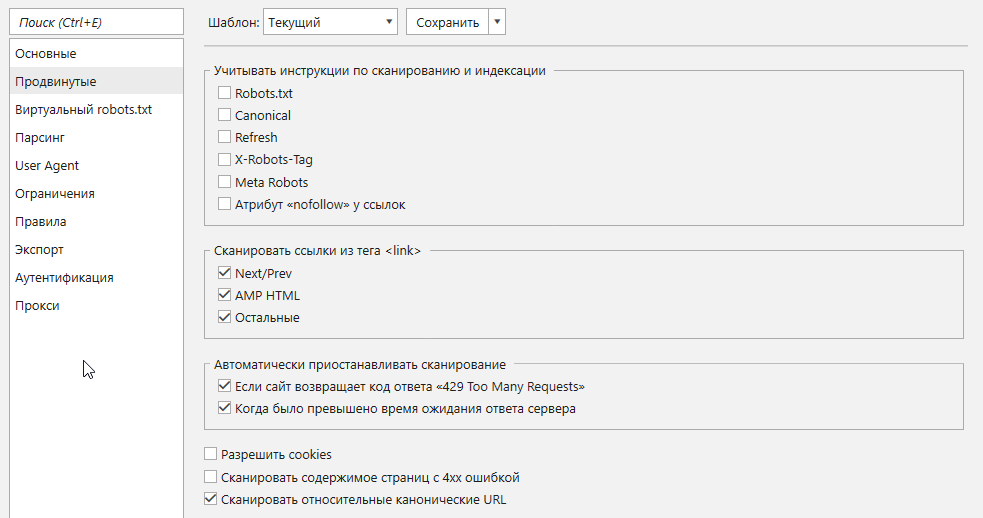
- На вкладке «Google Analytics и Search Console» добавляю аккаунт и на боковой панели программы отмечаю параметры, которые нужны для дальнейшей работы:
- сеансы (за последние полгода или меньше);
- показатель отказов;
- достижения нужных целей.
- На вкладке «Парсинг» я заношу регулярные выражения и уникальные коды, чтобы точно определить типы страниц, количество товаров на листингах, список категорий и т. д. Большинство данных я извлекаю из микроразметки. Для рассматриваемого сайта это выглядит следующим образом:
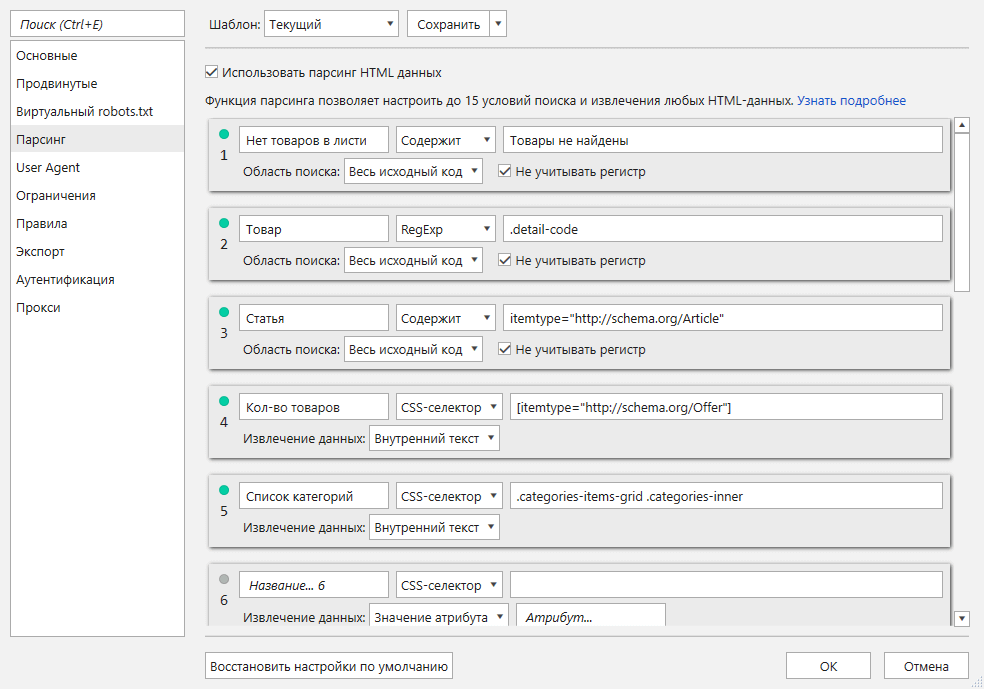 Читайте также: «Как парсить различные данные с помощью Netpeak Spider».
Читайте также: «Как парсить различные данные с помощью Netpeak Spider». - На вкладке «Параметры» боковой панели выставляю шаблон «По умолчанию» → он содержит все необходимые параметры для поиска ошибок.
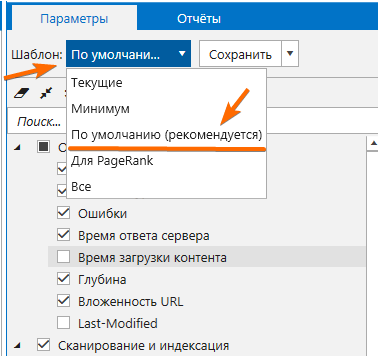
- Указываю начальный URL сайта и нажимаю «Старт»
Пока сайт сканируется, я перехожу к следующему этапу.
Чтобы начать пользоваться Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить программу
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.
Этап второй. Проверка индексации
Для проверки наличия страниц в индексе вы можете воспользоваться Netpeak Checker, Rush Analytics, Overlead.me и другими инструментами.
В Netpeak Checker это делается следующим образом:
- Вставьте список страниц сайта, который вы получите с помощью Netpeak Spider.
- На боковой панели отметьте пункты «Google SERP» или «Яндекс SERP», после чего запустите сканирование.
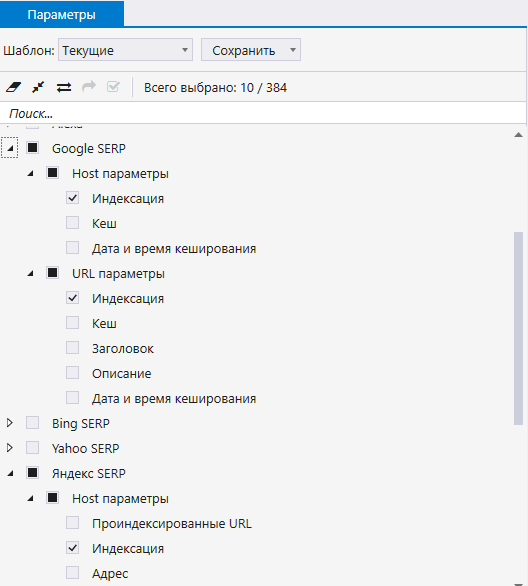
Вы можете сэкономить на проверке индексации и считать сразу проиндексированными страницы, которые получали показы и трафик за последнюю неделю или две (по данным из Google Analytics и Google Search Console.).
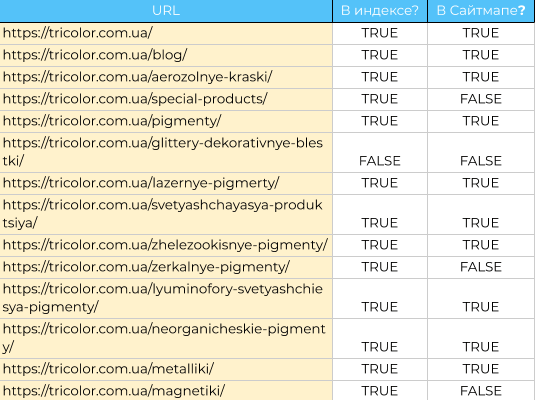
Также нужно узнать, есть ли неиндексируемые страницы в XML-карте сайта. Для этого выгрузите URL из файла Sitemap и просканируйте их. Если вы нашли ошибки на этих страницах, их нужно либо исправить, либо заменить на индексируемые страницы, которых в карте ещё не было.
Этап третий. Определение категорий для сегментации по важным параметрам
На этом этапе я добавляю в таблицу следующие On-Page данные страниц:
- скорость ответа сервера;
- глубина страницы от главной;
- количество слов на странице;
- инструкции по индексации и сканированию;
- title и description;
- заголовки.
Советую использовать категоризацию для параметров с численным показателем (например, количество слов на странице можно разбить на категории: от 100 до 500, от 501 до 1000, от 1001 до 2000), чтобы потом легко сегментировать данные при построении диаграмм.
Этап четвёртый. Экспорт и определение качества обратных ссылок
Чтобы собрать все ссылки на сайт, рекомендую использовать несколько сервисов анализа ссылок, а также добавлять вручную ссылки, полученные после кампаний по линкбилдингу (потому что они могут не отобразиться в сервисах).
Как собирать и выгружать обратные ссылки с помощью Ahrefs:
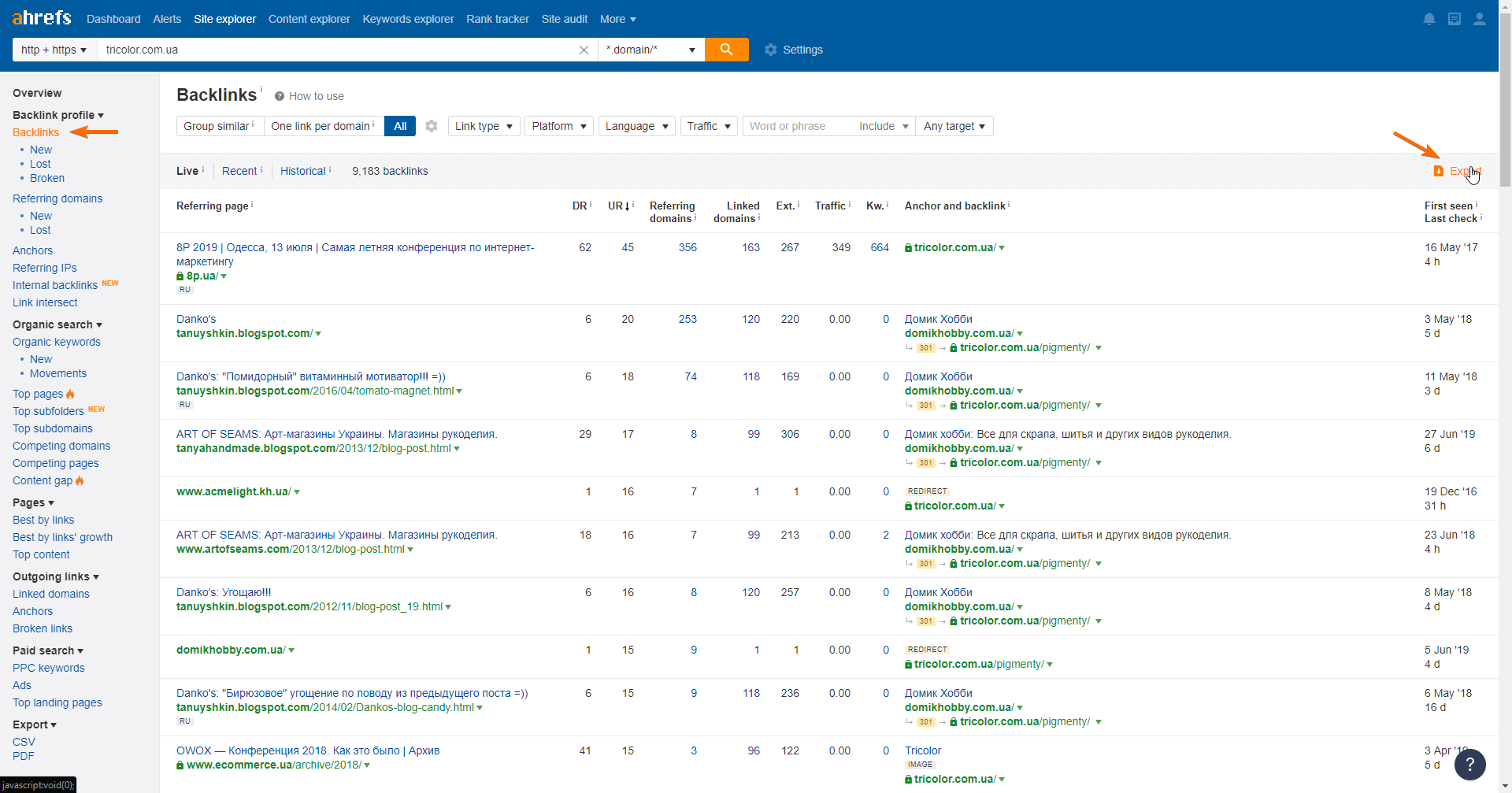
Импортируйте данные из Ahrefs или того сервиса, в котором вы собираете бэклинки, в Google Таблицы и отсортируйте их в таком порядке:
- Referring Page URL;
- Link URL;
- Domain Rating;
- URL Rating (desc);
- Redirect chain (from);
- Redirect chain (to);
- Redirect type;
- Type.
Удалите сквозные ссылки, nofollow ссылки и отделите качественные от некачественных.
Чтобы определить, какие ссылки плохие, а какие хорошие, я опираюсь на два показателя — Domain Rating и URL Rating по Ahrefs. Если первый ниже 15, а второй ниже пяти, то ссылку считаю некачественной.
Хочу заметить, что эти пороговые значения не являются эталонными для всех проектов. Конкретно в этом случае они были выбраны на основании медианной величины DR и UR всех ссылок на этот ресурс.
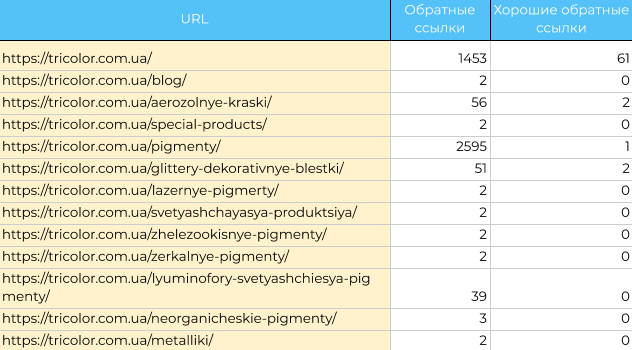
Таким образом вы увидете, какие из страниц заспамлены, и какие ссылки в будущем вам нужно будет отклонить в Google Disavow Links Tool.
Этап пятый. Оценка видимости для приоритезации продвижения страниц
Если у вас есть собранная семантика, по которой вы собираете данные по позициям и частотности, добавьте её в докс, чтобы смотреть видимость каждой страницы. Если её нет, то данные можно собрать из сервисов Serpstat, Spywords, Keys.so, Google Search Console или Яндекс.Вебмастер.
Соберите общую частотность страницы и количество показов именно по небрендовым ключам. Для чего это нужно:
- Чтобы приоритезировать работу со страницами и понимать за что в первую очередь браться.
- Чтобы увидеть, сколько ключей у страницы находится в топе и видеть потенциал роста.
Этап шестой. Сбор данных по трафику и конверсиям
Так как перед сканированием в Netpeak Spider мы использовали интеграцию с Google Analytics и Search Console, то собирать их отдельно не нужно.
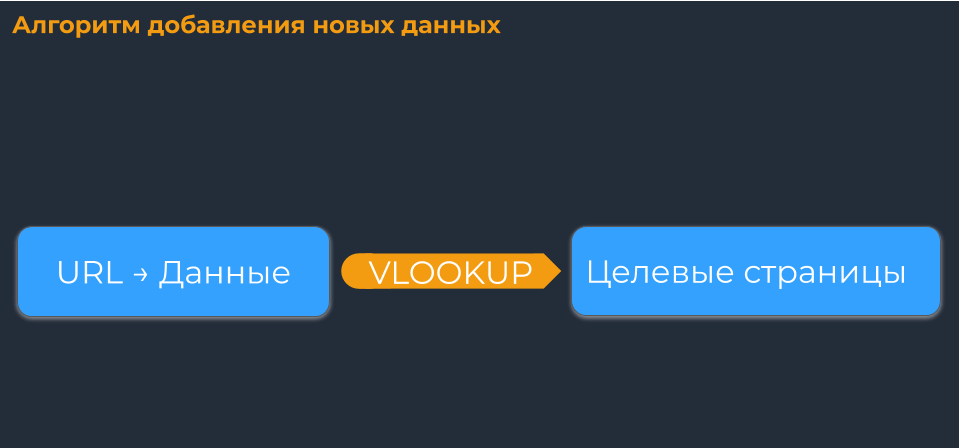
Если же вы не собирали эти параметры в Netpeak Spider, то данные можно получить с помощью расширений для Google Таблиц: Google Analytics и Search Analytics for Sheets. Консолидируйте их со страницами, используя функцию VLOOKUP (вертикальный поиск результата). Смотрите не только трафик, но и конверсионность.
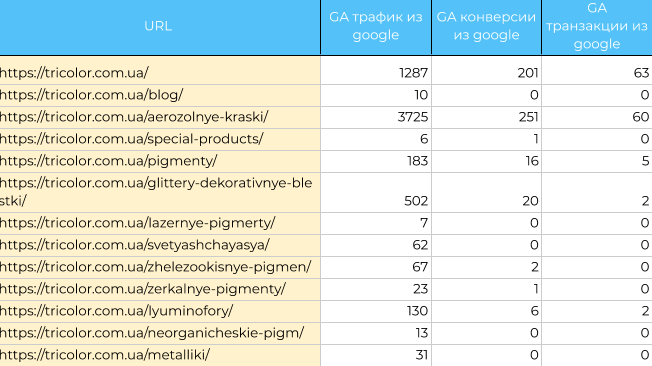
Детальный и пошаговый мануал по сбору данных для аудита сайта изложен в этом SOP.
3. Что получаем в итоге
Выполнив все этапы, мы получили данные для комплексного анализа страниц в одном месте. Это позволяет в любой момент времени сделать нужную выборку и ничего не упустить.
Для лучшей приоритезации в таблицу можно добавить:
- данные по посещению страниц роботами из логов;
- данные из CRM (иногда данные по транзакциям, заполнению форм в CRM более точные, чем в аналитике, потому что adblocker может их блокировать);
- данные из систем call-tracking;
- исторические данные по анализируемым параметрам;
- или данные по разным каналам трафика.
Для наглядности посмотрите таблицу с примером SEO-аудита. Вы можете вставлять данные в шаблон, а он автоматически будет определять ошибки с помощью формул Google Таблиц.
Данные из разных сервисов в таблицу вы можете выгружать вручную, но иногда для более быстрого сбора лучше использовать API. Таким образом вы будете собирать их на новые листы, применять функцию VLOOKUP и подтягивать в основную таблицу по каждому URL.
4. Как это применить
Благодаря агрегированным данным вы сможете:
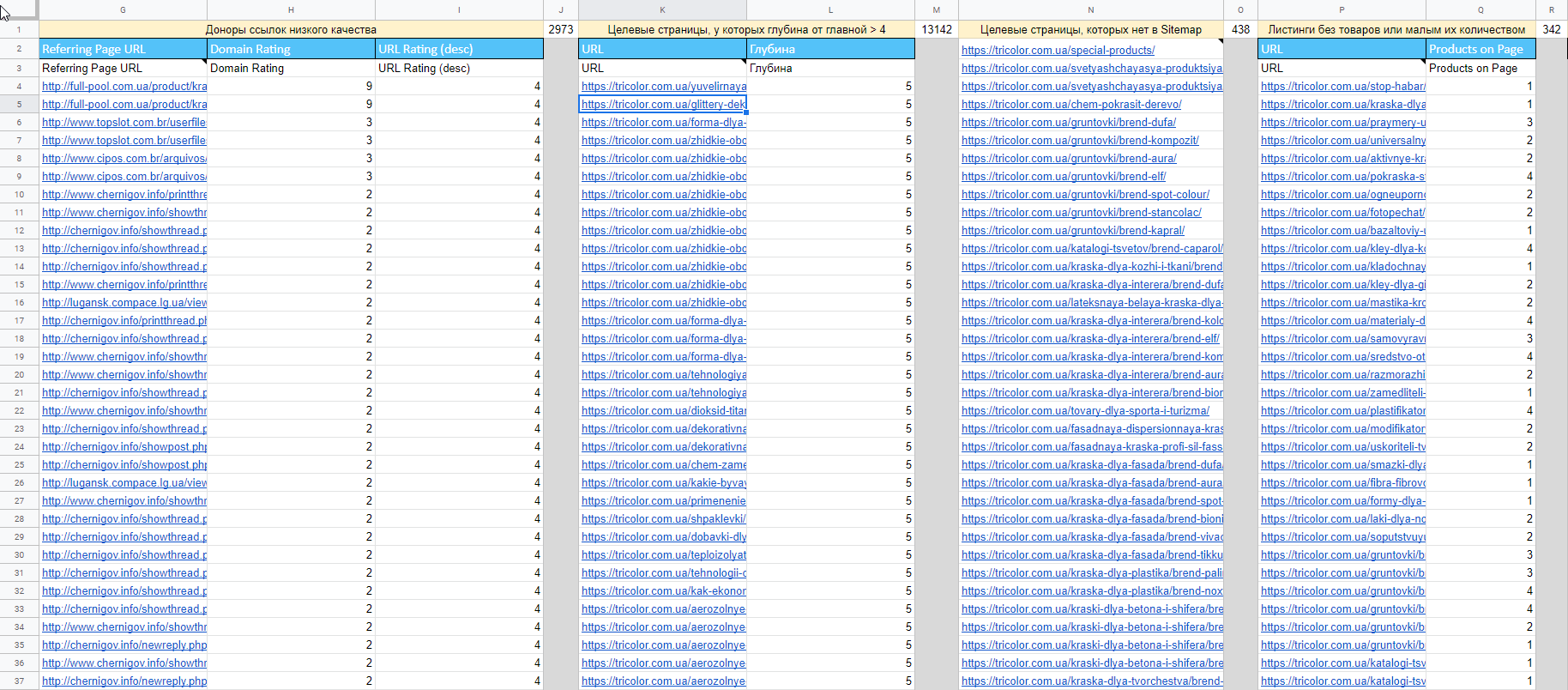
- Определить, какие страницы не попали в индекс.
- Найти доноров ссылок низкого качества.
- Узнать причины неиндексируемости страниц и найти страницы с ошибками в Sitemap.
- Найти нецелевые страницы с трафиком.
- Проанализировать ассортимент сайта и получить листинг товаров, содержащих низкое количество товаров.
- Узнать, какие целевые страницы не добавлены в карту сайта
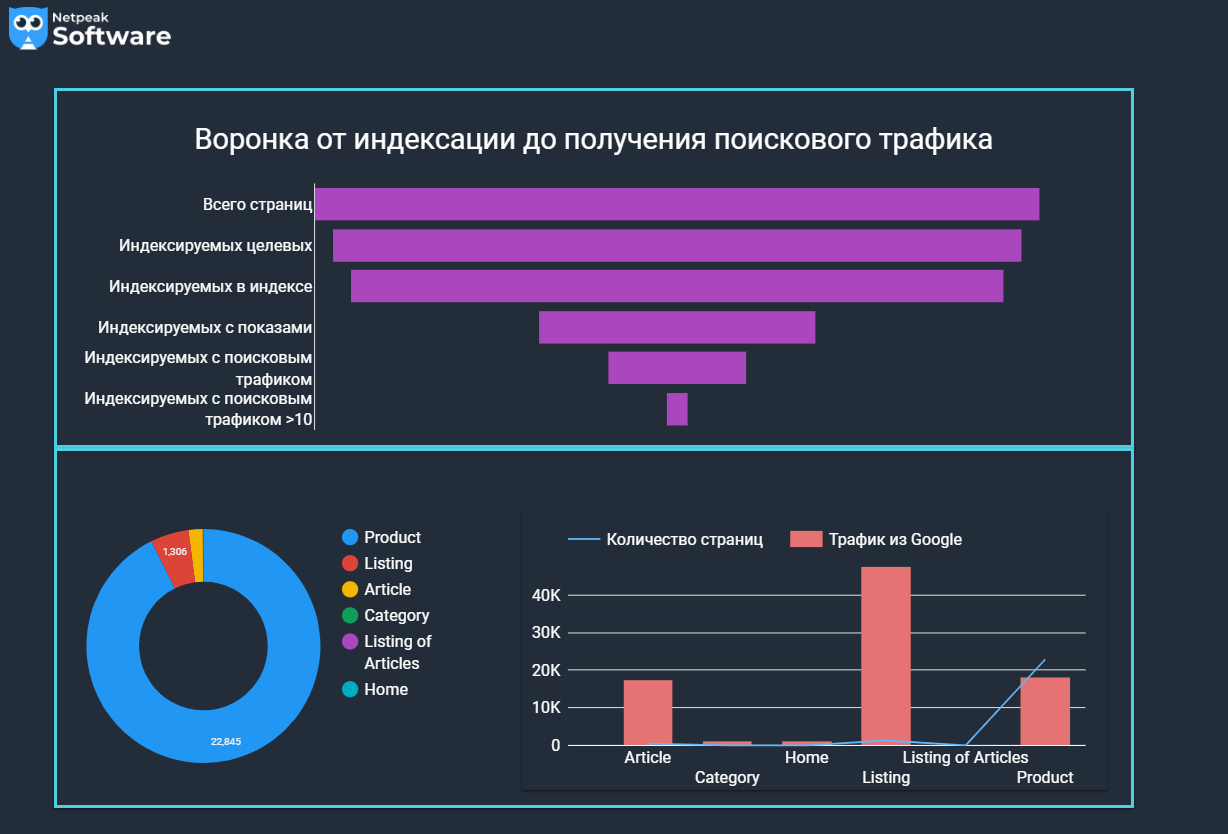
Все эти данные можно визуализировать в Google Таблицах для анализа. Например, диаграмма ниже показывает воронку распределения страниц на этапах от индексации до получения конверсий. Здесь наблюдается значительное сужение воронки на этапе получения показов, и с этим нужно бороться в первую очередь.
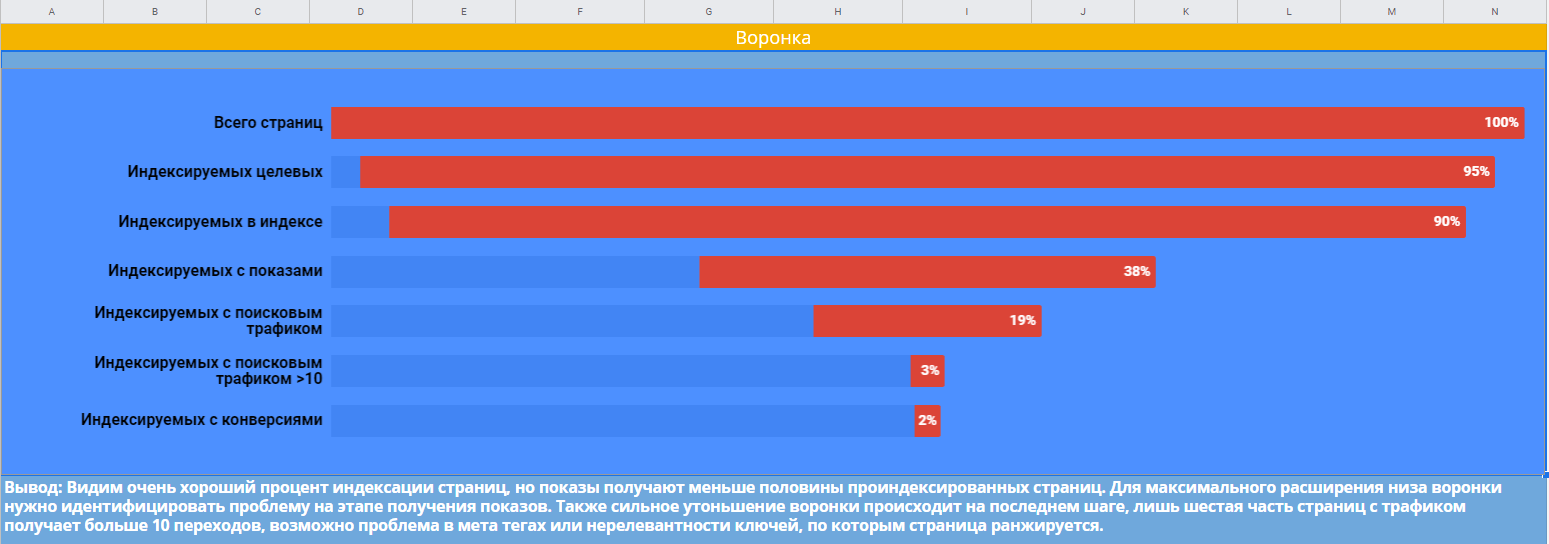
Следующая диаграмма показывает количество страниц каждого типа, и какие из них не индексируются. Можно заметить, что большинство страниц, которые не попали в индекс, — это карточки товаров.
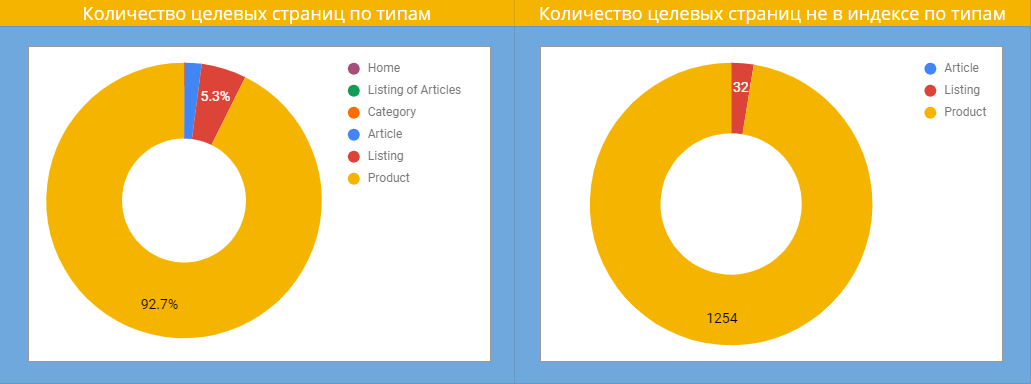
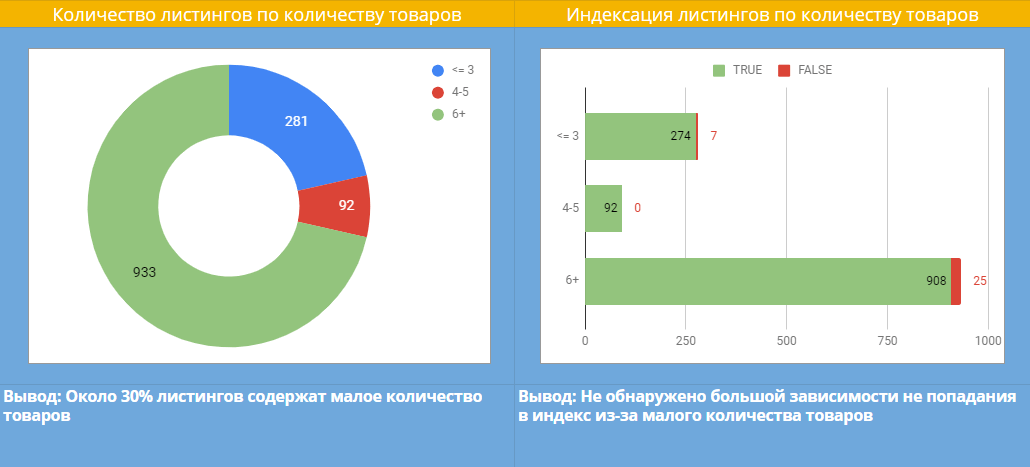
Нам нужно понять, почему так происходит. Для этого анализируем количество товаров на листингах и видим, что 30% листингов содержат небольшое количество товаров. Именно это влияет на индексацию? Нет, так как на диаграмме ниже видно, что прямая корреляция между показателями отсутствует.
Возможно, причина в контенте. Собираем среднее количество слов на каждом типе страниц и анализируем. Видим, что страницы с малым количеством текста так же хорошо индексируются, как и с большим, поэтому причина не в контенте.

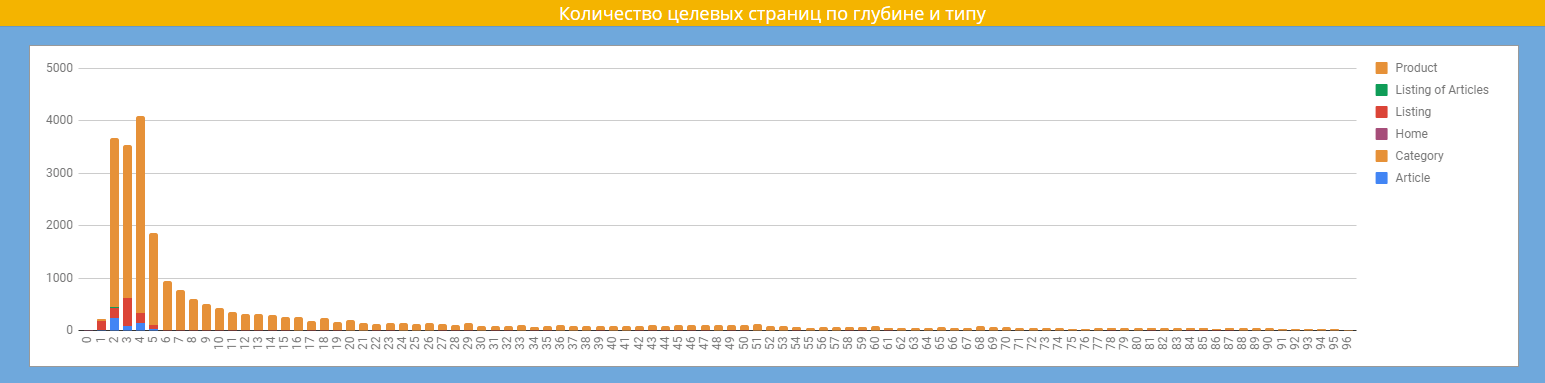
Изучаем глубину страниц сайта и наконец видим, что именно она является причиной плохой индексации. Ищем проблему в алгоритме внутренней перелинковки и добавляем больше фильтров и тегов для лучшего охвата семантики и снижения количества кликов до таких страниц.
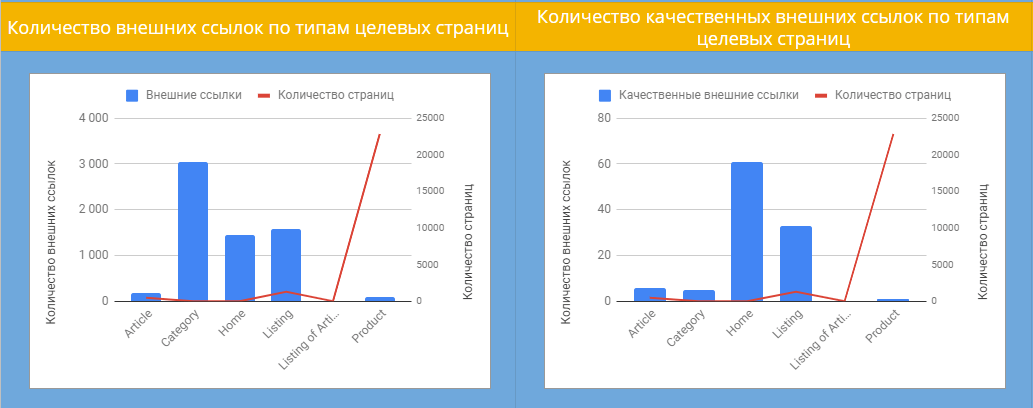
Далее разбираемся, на какие типы страниц чаще всего ссылаются внешние ресурсы. Левая диаграмма показывает, что большинство ссылок ведут на страницы категорий. Но глядя на правую диаграмму можно заметить, что общее количество качественных бэклинков не больше ста. Здесь напрашивается вывод о том, что нужно эффективно перенаправлять внутренний ссылочный вес со страниц категорий на приоритетные страницы и наращивать качественную ссылочную массу.
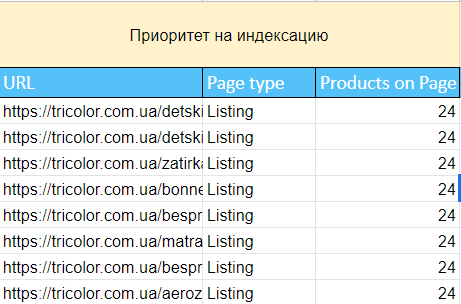
Находим с помощью формул точки роста проекта. Например, в моём случае — это страницы и ключи, которые нужно дооптимизировать для вывода в топ.

Для работы с непроиндексированными страницами я использовал сортировку по принципу: сначала листинги с наибольшим количеством товаров (так как они чаще всего являются страницей входа на пути к конверсии на этом проекте), а после них сами карточки.
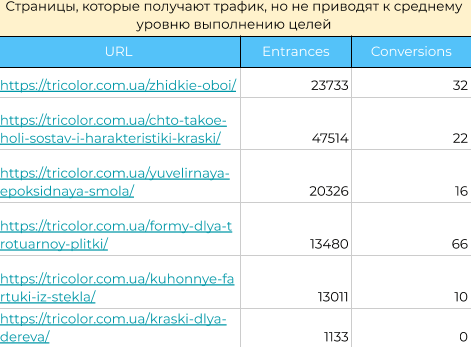
Выгружаю страницы с хорошими показателями трафика и низкими показателями конверсий и начинаю заниматься их оптимизацией. Здесь уже происходит работа не только по поисковой оптимизации, но и по оптимизации конверсий (CRO).
Итак, мы получили данные и диаграммы, демонстрирующие реальные проблемы на сайте. Их можно показать клиенту и в таком виде, а можно для презентабельности визуализировать отчёты в Google Data Studio.
5. Нюансы, которые важно учитывать
Каждый отдельный проект имеет свои нюансы, поэтому мой шаблон SOP необходимо кастомизировать с учётом того, что:
- Определять тип страницы / категории не всегда можно по URL. Нужно использовать парсинг по элементам на странице (schema, хлебные крошки, куски кода).
- Могут быть смешанные данные в сервисах по http и https-протоколам. Показатели необходимо склеивать.
- Если старые бэклинки ведут на HTTP версию сайта, а вы переехали на HTTPS, тоже нужно склеивать.
- Категории по количеству слов, внутренних ссылок определяются индивидуально для проекта.
- Для каждого проекта нужно сделать шаблон регулярного выражения, который будет определять брендовость запроса.
- Проще анализировать сайт с историей, у него больше данных, и это позволяет лучше ориентироваться в ситуации.
- Если вы работаете с большими проектами (более 30 тысяч страниц), вы столкнётесь с ограничением в 5 миллионов ячеек таблицы, поэтому для агрегации Google Таблицах и Excel (более 50-70 тысяч страниц) не подойдут.
А ещё наш Product Marketing Manager Костя Баньковский написал пост и снял видео о том, как настроить краулер Netpeak Spider, чтобы найти нестандартные SEO-ошибки на сайте:
Подводим итоги
С помощью алгоритма сбора данных, который я описал в этом посте, вы сможете проводить комплексный анализ данных, проверять сайт на SEO-ошибки, находить реальные проблемы и точки роста. Все данные можно визуализировать и показать клиенту.
Используйте мой шаблон и делитесь фидбеком :)


