Почему новые сайты плохо ранжируются в Google News [Исследование эксперта]
От экспертов
![Почему новые сайты плохо ранжируются в Google News [Исследование эксперта]](https://static.netpeaksoftware.com/media/ru/image/blog/post/d8d906bf/900x300/d2d0d1-2.png)
До декабря 2019 года для ранжирования сайта в Google News необходимо было отправить заявку на добавление в корпус Новостей через центр для издателей Google. Эта заявка проверялась в полуавтоматическом режиме, и многие информационные сайты получали отказ.
10 декабря 2019 года Google сообщил о запуске нового центра для издателей. В это же время в Справке для издателей появилась следующая информация:
«Издателям больше не нужно отправлять свой сайт, чтобы иметь право на участие в Google News. Издатели автоматически рассматриваются для главных новостей или вкладки Новостей поиска. Им просто нужно создавать высококачественный контент и соблюдать правила в отношении содержания Новостей Google».
Другими словами, отбором сайтов для индексирования и ранжирования в Google News занимается исключительно алгоритм, а человеческий фактор (влияние ревьюверов) исключён.
Ранее попасть в корпус Новостей было достаточно сложно, но новый процесс алгоритмического отбора сайтов стал ещё жёстче. Издатели массово начали жаловаться на то, что после регистрации в новом центре их сайты не ранжируются на вкладке Новости.
Команда Google сообщила, что регистрация сайта не гарантирует его ранжирования в Google News. По сути, новый центр — это лишь профиль издания, в котором можно настроить реквизиты издания и особенности показа новостей. К сожалению, по прошествии 9 месяцев с момента запуска нового центра команда Google News так и не дала официального объяснения, почему сайты не ранжируются на вкладке Новости.
Отвечая на вопросы издателей на Справочном форуме Google News, я анализировал сайты, которые претендовали на ранжирование. Оказалось, что многие из ресурсов не отвечают основным требованиям в отношении контента и техническим требованиям или нарушают рекомендации Google для вебмастеров. Однако были и достаточно качественные сайты.
Я решил провести своё исследование этой проблемы.
Дисклеймер: Все выводы, которые я сделал, являются моим личным мнением и основаны на результатах анализа моего набора данных. Ваш опыт и выводы других экспертов могут отличаться от моих.
Полученные результаты можно использовать в качестве вектора для улучшения качества сайта и повышения вероятности его ранжирования в Google News.
1. Ход исследования
1.1. Первый этап
При помощи SEMrush я получил список основных поисковых запросов одного из крупнейших украинских изданий, которое публикует новости разных тематик. При помощи самописного парсера по каждому из 644 запросов я получил из вкладки Новости топ-30 ссылок.
Затем я загрузил эти ссылки (19320 штук) в Netpeak Checker и получил данные по таким параметрам:
- «Время ответа сервера»,
- «Title»,
- «Длина Title»,
- «Description»,
- «Длина Description»,
- «Исходящие ссылки,
- «Внутренние ссылки,
- «Внешние ссылки,
- «Значение H1»,
- «Длина H1»,
- «Размер контента»,
- «Количество слов»,
- «Content-Length».
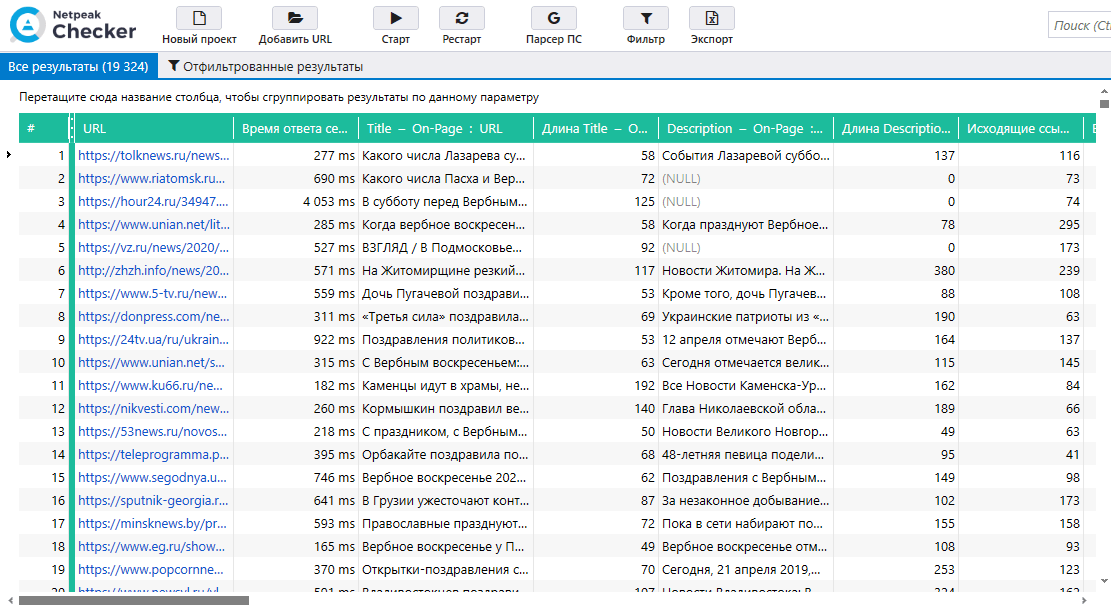
Используя API Serpstat в Netpeak Checker, я получил данные о трафике (параметр «Суммарный трафик»).
API Majestic позволил получить значения таких показателей:
- «Host параметры»: Trust Flow, Citation Flow, External Backlinks, Referring Domains,
- «URL параметры»: Trust Flow, Citation Flow, External Backlinks, Referring Domains.
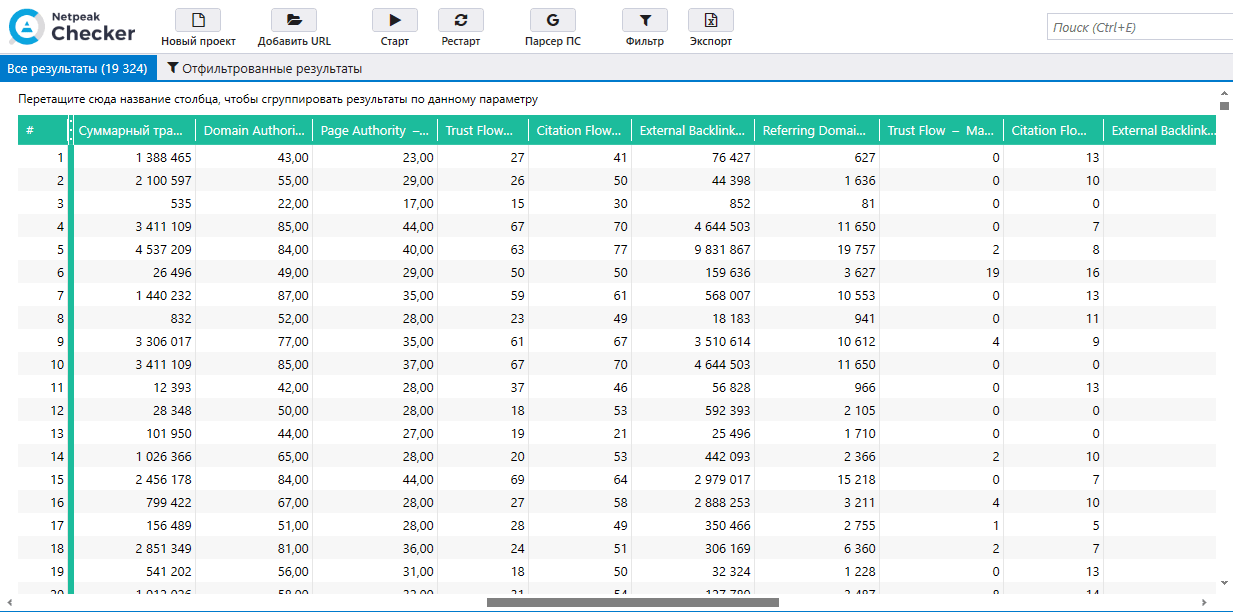
По API Google получены значения показателей для мобильной и десктопной версий: FCP, FID, LCP, CLS, а также Mobile Score и Desktop Score Google PageSpeed Insights.
Поскольку основная проблема связана с временным интервалом (датой создания сайта и датой запуска нового центра для издателей), из Whois я собрал данные по показателям Creation Date и Root Domain.
Проверять параметры и собирать данные из сервисов вы можете даже в бесплатной версии Netpeak Checker без ограничений по времени. Также во Freemium-версии доступны и другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Checker, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
После сбора и чистки всех данных осталось 18588 ссылок из вкладки Новости поиска Google.
Как оказалось, все эти ссылки принадлежали 2270 сайтам, из которых только 12 (0,5%) были запущены после релиза нового центра для издателей. Часть из этих сайтов-новичков расположена на доменах-дропах, ещё часть — это известные информационные сайты, которые по какой-то причине сменили домен.
Исходя из этого можно сделать первый вывод: действительно, новый алгоритм ранжирования во вкладке Новости Google в большинстве случаев игнорирует сайты, которым меньше года.
Однако учитывая, что некоторые новые сайты всё-таки попадают в рейтинг, можно предположить, что скорее всего это не техническая проблема (баг). На мой взгляд, при обучении алгоритма BERT использовались завышенные пороги по критерию, который можно условно назвать «Дата запуска» (Date launch).
1.2. Второй этап
На втором этапе выявления возможных отличий и зависимостей я на Справочном форуме Google News отобрал 10 сайтов, представители которых жаловались на проблемы с ранжированием.
В SEMrush по этому набору я получил 7549 ссылок. Затем в Netpeak Checker собрал те же данные, которые были в первичном наборе (пункт 1.1), и соединил их все.
Полученный сводный набор разделил на два класса по двум критериям:
- По возрасту сайта → Возраст: More 1 year, Less 1 year.
- По признаку ранжирования → News Ranking: Yes, No.
В процессе интеллектуального анализа данных (Data Mining) я использовал «Линейный график» — это стандартный виджет визуализации, который отображает профили данных, обычно в виде упорядоченных числовых данных.
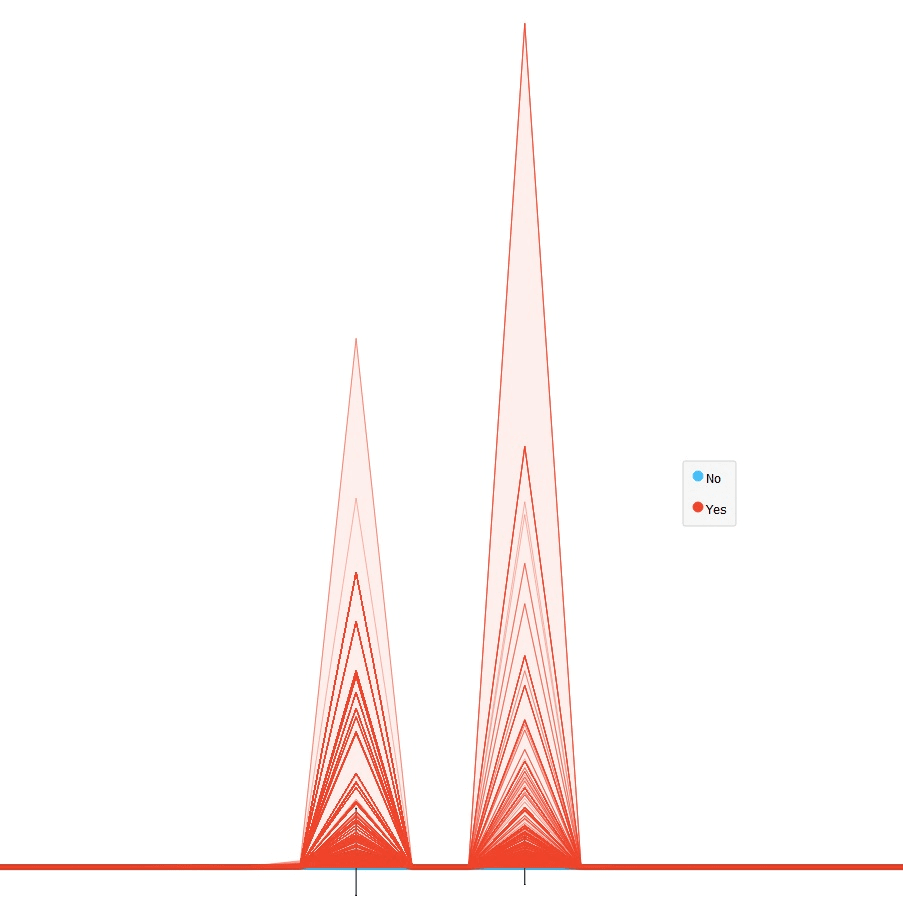
Он показал, что наилучшими атрибутами разделения классов являются трафик (Суммарный трафик по Serpstat) и количество внешних обратных ссылок (Majestic:Host параметры → External Backlinks).
На скриншоте ниже показано распределение сайтов в зависимости от даты запуска.
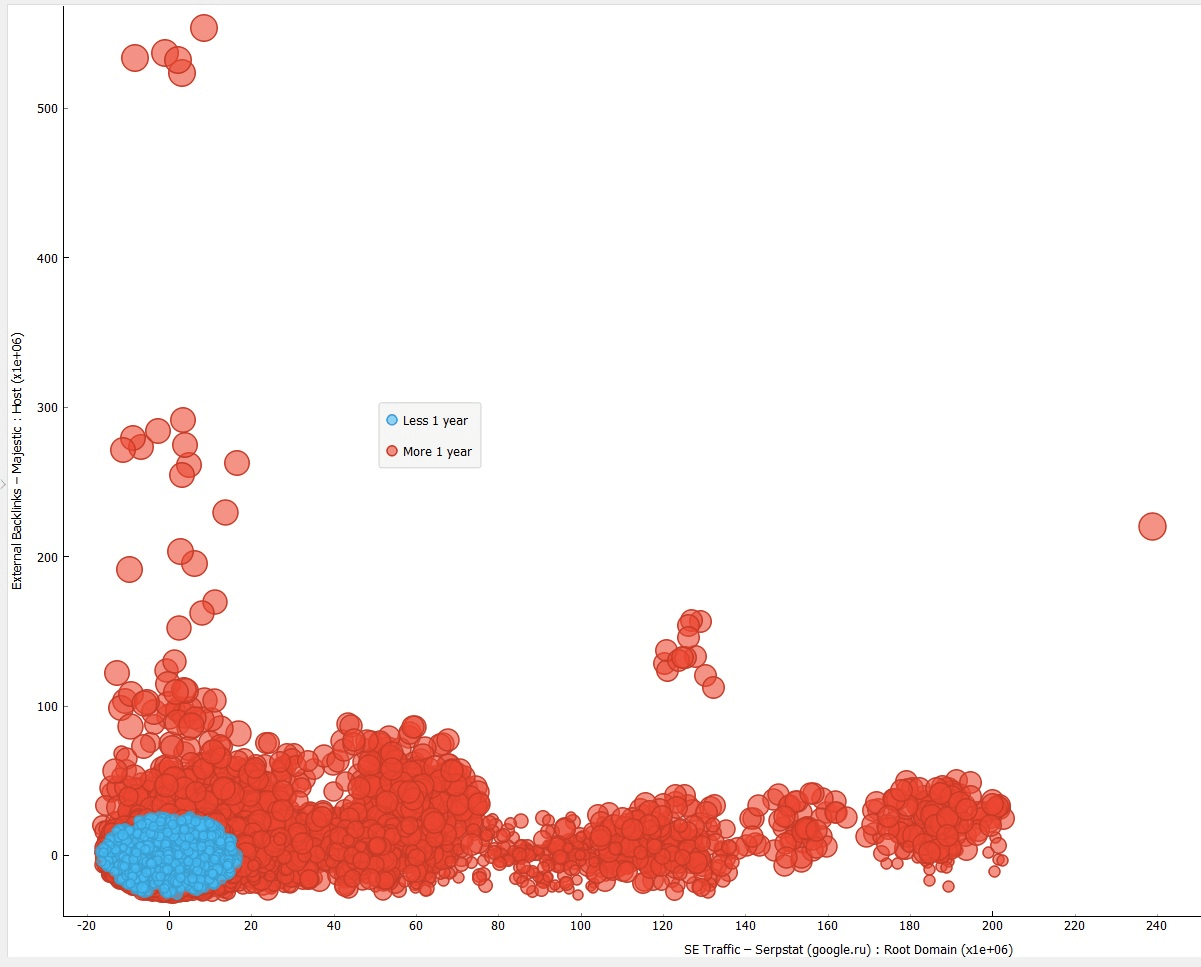
По горизонтали отображён объём трафика, по вертикали — количество внешних ссылок на сайт, размер элементов — «Host параметры»:Majestic Trust Flow. Сами сайты по дате создания разделены на два класса «До 1 года» (синие элементы) и «Больше 1 года» (красные элементы).
Как видно на скриншоте, у сайтов, которым нет ещё года, значительно меньше качественных обратных ссылок и трафика. Это логично, поскольку новые сайты не очень популярны, и обычно количество страниц с высококачественным контентом у них невелико.
Google Поиск и Discover несомненно отличаются, но имеют общие принципы «E-A-T» применительно к содержанию. Напомню, что «E-A-T» расшифровывается как «Экспертиза», «Авторитет», «Доверие» (Траст).
Учитывая это, некоторым объяснением к ранжированию сайтов в Google News может послужить абзац из Справки к Discover:
«Наши автоматизированные системы отображают контент… с сайтов, на которых есть много отдельных страниц, демонстрирующих опыт, авторитетность и надёжность (E-A-T)».
Если сравнить два издания — новое и старое, безусловно, у второго будет намного больше страниц, которые могут демонстрировать высокий уровень «E-A-T».
На мой взгляд, если смотреть на график выше, количество страниц в индексе Google в совокупности с хорошим трафиком может указывать на то, что материалы написаны экспертами. Количество обратных ссылок, передающих PageRank, формируют авторитетность страницы. Дата запуска сайта может в какой-то степени быть критерием надёжности (траста) сайта.
Используя машинное обучение, в сервисе BigML я создал модель в виде дерева решений, точность которой составляет 99,9%. Предиктором дерева решений является показатель Majestic Trust Flow: Host.
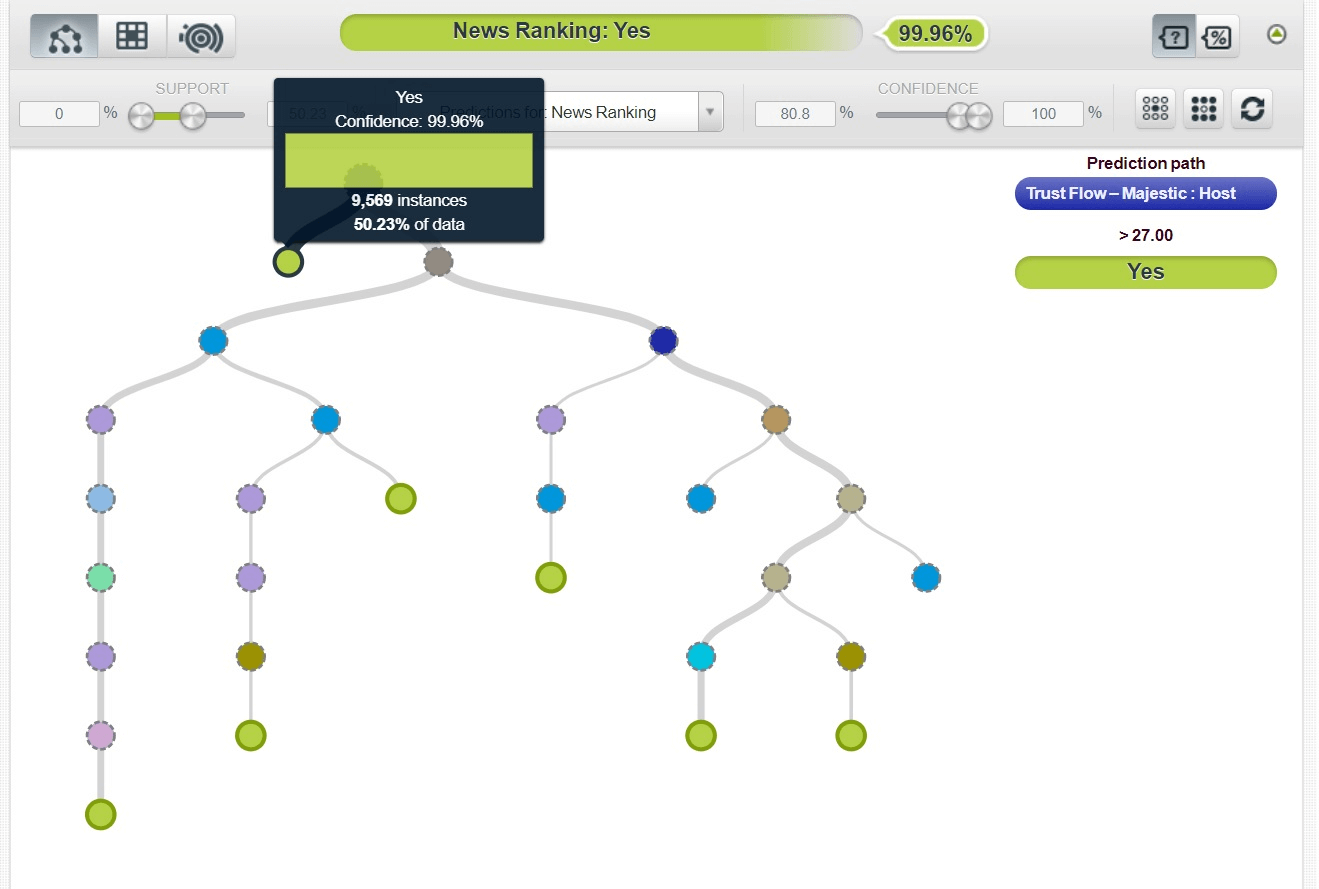
Наиболее вероятный сценарий: если Majestic TF больше 27, сайт скорее всего будет ранжироваться во вкладке Google News. Нарастить Trust Flow до такого уровня за год достаточно сложно. И вполне логично, что по этому сценарию сайты-одногодки имеют проблемы с ранжированием в Google News.
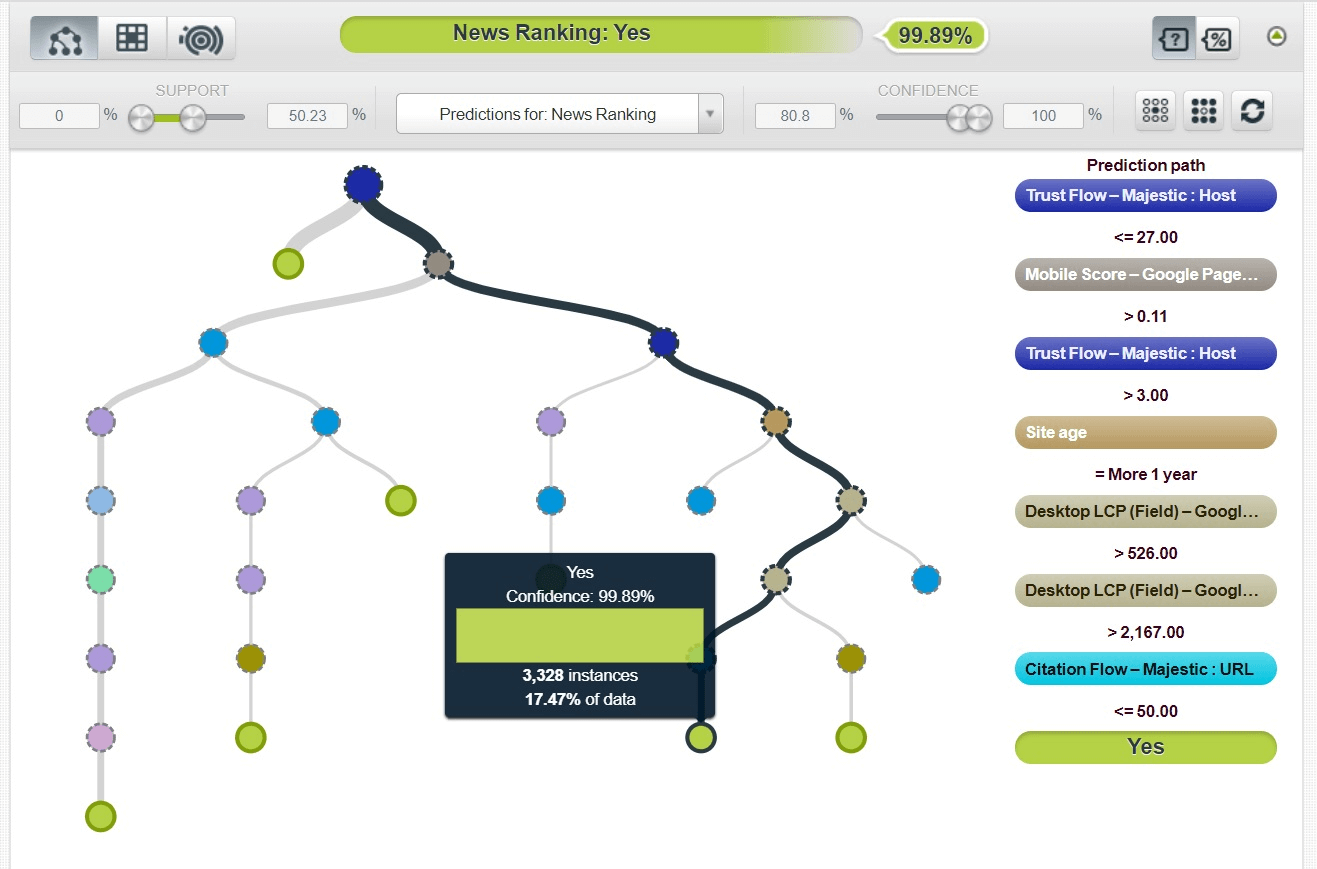
На втором по уровню вероятности сценарии видно, что даже если показатель Majestic Trust Flow в интервале от 3 до 27, но при этом сайт существует более года, высока вероятность того, что он будет ранжироваться во вкладке Новости.
Учитывая второй сценарий, можно предположить, что по модели «E-A-T» для новых сайтов первичным критерием отбора является параметр Авторитет, который во многом формируется за счёт качественных обратных ссылок (PageRank). Второй по значимости — возраст сайта (Дата запуска).
Эти выводы согласуются с результатами, ранее полученными при использовании интеллектуального анализа данных (скриншот выше, где показано распределение сайтов в зависимости от даты запуска).
Если рассмотреть самый вероятный сценарий, почему сайт не ранжируется во вкладке Новости поиска Google, мы увидим такие результаты:
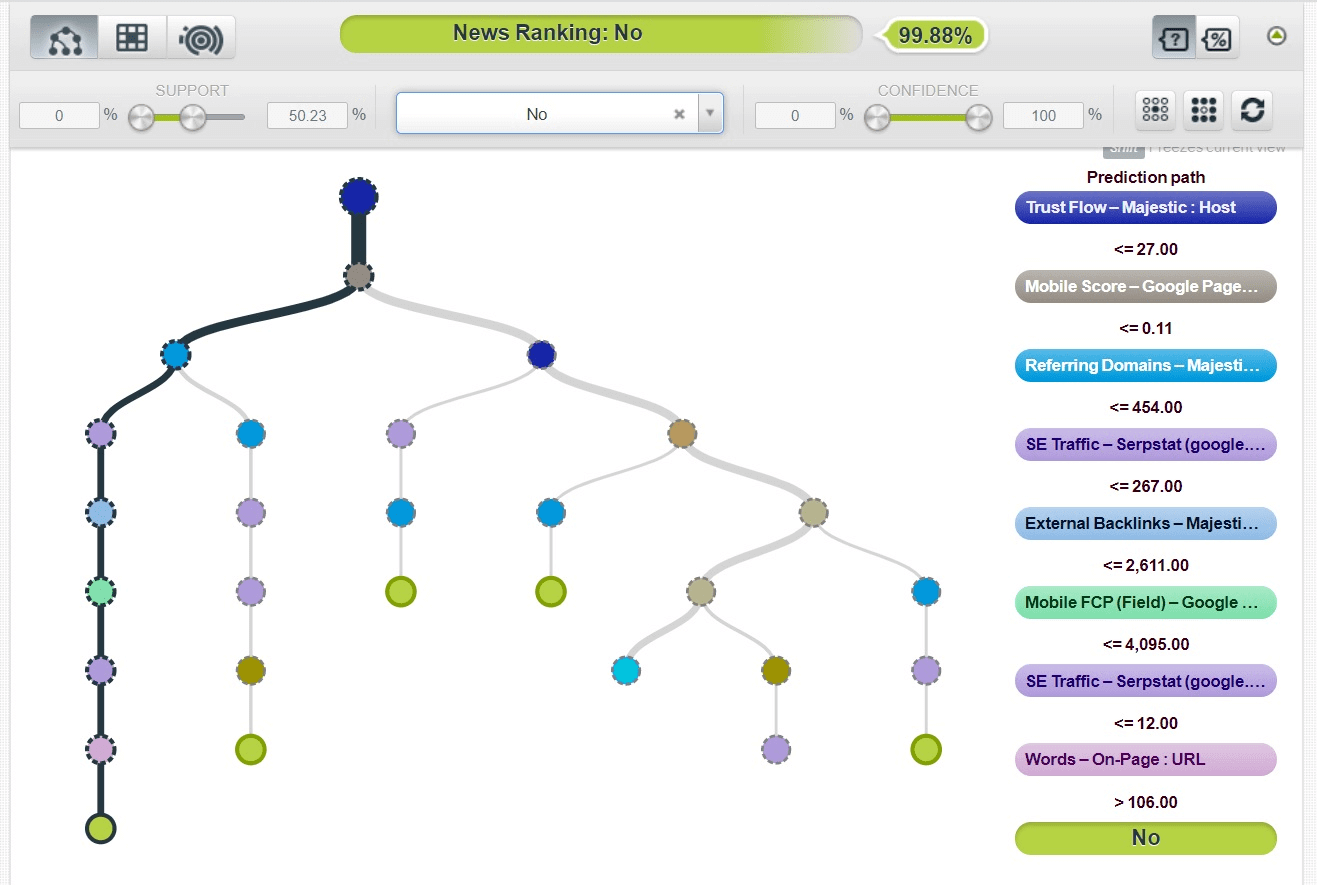
С большой вероятностью можно утверждать, что сайт не будет ранжироваться в Новостях, если у него:
- мало качественных обратных ссылок и ссылающихся доменов;
- низкая скорость загрузки мобильной версии;
- мало органического трафика.
Выводы
Многие новые сайты не отвечают техническим требованиям и политике в отношении контента Google News. Абсолютно справедливо, что такие сайты не должны ранжироваться во вкладке Новости поиска Google.
При отборе сайтов для ранжирования Google используется машинное обучение, и вероятнее всего, критерии отбора довольно высокие. Возможно, по замыслу разработчиков такие меры должны уменьшить количество спама и показов некачественных сайтов в Google News.
Сайты новостей давно приравнены к категории YMYL, и при их оценке должны применяться высокие стандарты «E-A-T».
Результаты показывают, что, скорее всего, важными сигналами ранжирования являются:
- Количество и качество обратных ссылок — основной сигнал.
- Траст и все элементы, которые его формируют, в том числе дата запуска (возраст) сайта.
- Уровень органического трафика сайта, что видимо коррелирует с уровнем интереса к публикациям и экспертностью авторов (издания).


