WordPress SEO: Duplicate Content and Canonical Issues
How to

While struggling to achieve a place in the sun at the top of the SERP, SEO specialists not only use white hat techniques but also black hat tricks which are not welcome by search engines.
Even though the second case doesn’t always happen at your will, Google and other search engines can drop your website rankings as a result. In this article we’ll explain how to avoid such cases and find all issues on WordPress website before Google does.
1. Duplicates Role in SEO
According to Google, duplicate content generally refers to substantive blocks of content within or across domains that either completely match other content or are appreciably similar.
In other words, if the same content is placed on two different links, it counts as a duplication. In such cases search engines have to choose which one should be shown in search results. That’s why duplicate content can negatively affect on your website’s positions in SERP.
1.1. Types of Duplicate Content
These are main types of duplicates that can be found on website:
- full duplicates of pages (identical HTML-code)
- duplicates of Body content (contents in ‘body’ tag)
- duplicates of Title (name of the page)
- duplicates of Description
- duplicates of H1 (main heading)
While creating pages or posts in WordPress, use H2-H6 headings. H1, the most important heading, is generated automatically. H1 usually contains names of categories, pages or posts. If your website header contains usual text heading with the name of your website instead of image and/or logo, it will also be in the H1 tag. We strongly advise you to get rid of a text header because each page should contain only one H1 tag.
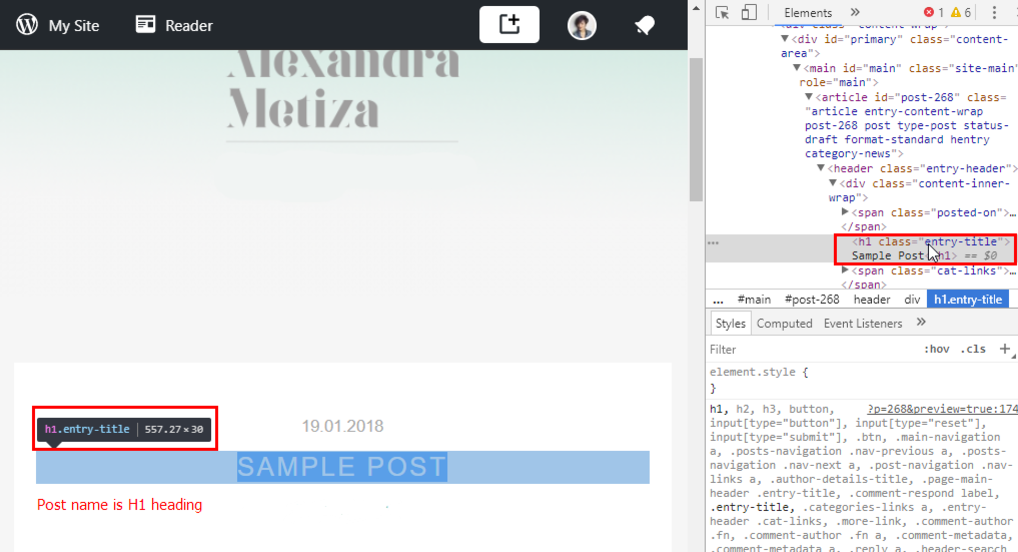
2. How to Find Duplicate Content
2.1. Detect Duplicate Content with Netpeak Spider
All types of duplicates except H1 ones belong to severe issues. Netpeak Spider shows it as clearly as possible: you can see all issues on your website according to their severity degree for SEO.
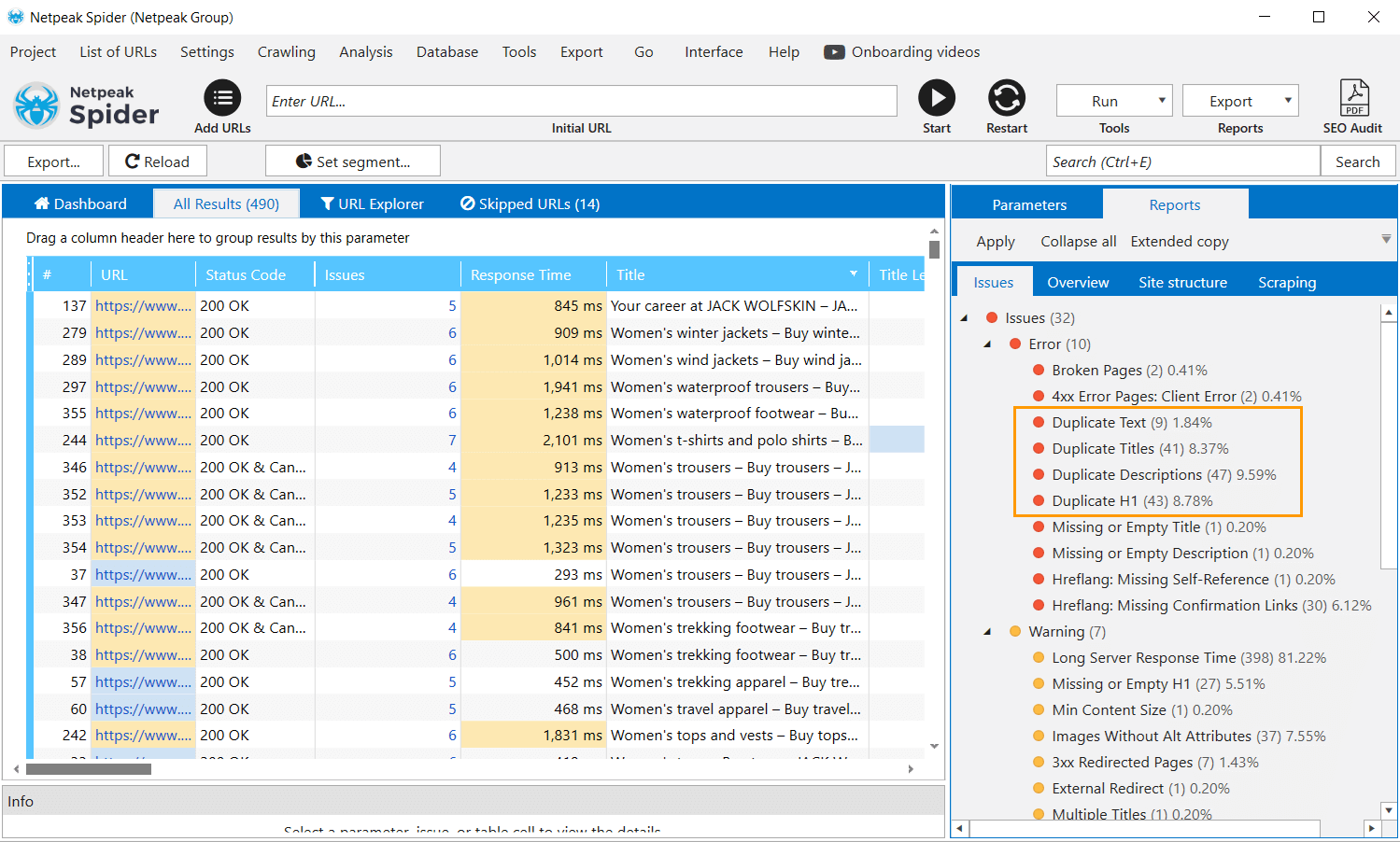
You can check all kinds of duplicates even in the free version of Netpeak Spider crawler that is not limited by the term of use and the number of analyzed URLs. Other basic features are also available in the Freemium version of the program.
To get access to free Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
If you found duplicate Description, Title or H1 tags, open the console of your website and fix it manually. You have to replace duplicate content with unique one.
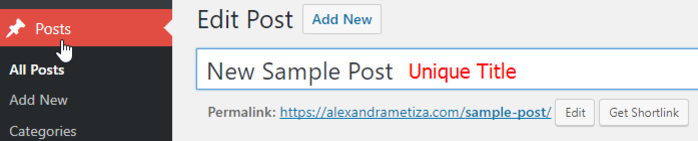
To do that, use the built-in page editor and YOAST plugin we mentioned before.
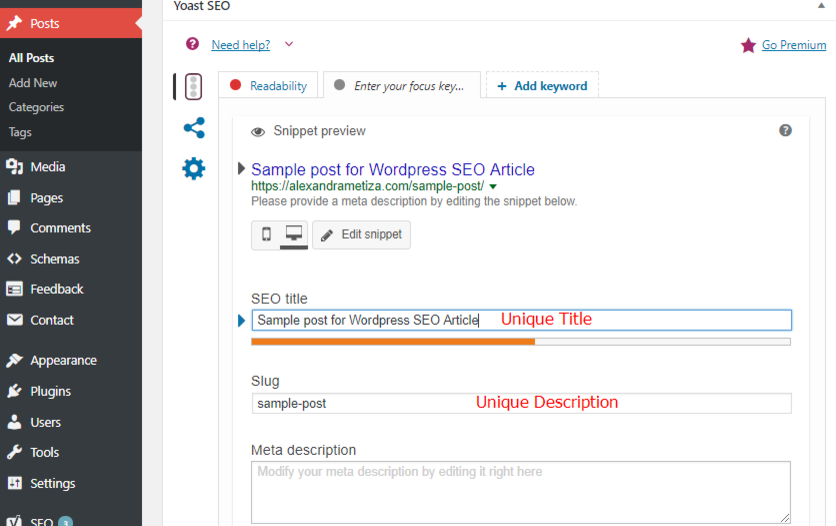
When dealing with duplication of Body tag content (the main content of the page or a post) we need to specify the canonical page – the primary source which will be defined by search engines as priority page. However, we will analyze similar cases a bit later.
If Netpeak Spider shows that there are duplicates of the whole pages on your website, it is necessary to set redirects or to specify canonical page for all of them.
2.2. Causes of Page Duplicates You Didn’t Create
- CMS (in our case it’s WordPress) can generate several URLs for one post if you place it in several categories at the same time without appropriate settings.
- If you have http and https website versions and versions with or without www prefix at the same time, search engines will identify them as duplicates.
- If you have several versions of a page with slashes or any other symbols at the end, they also will be identified as full duplicates.
3. How to Get Rid of Duplicates
3.1. WordPress Permanent Links Settings
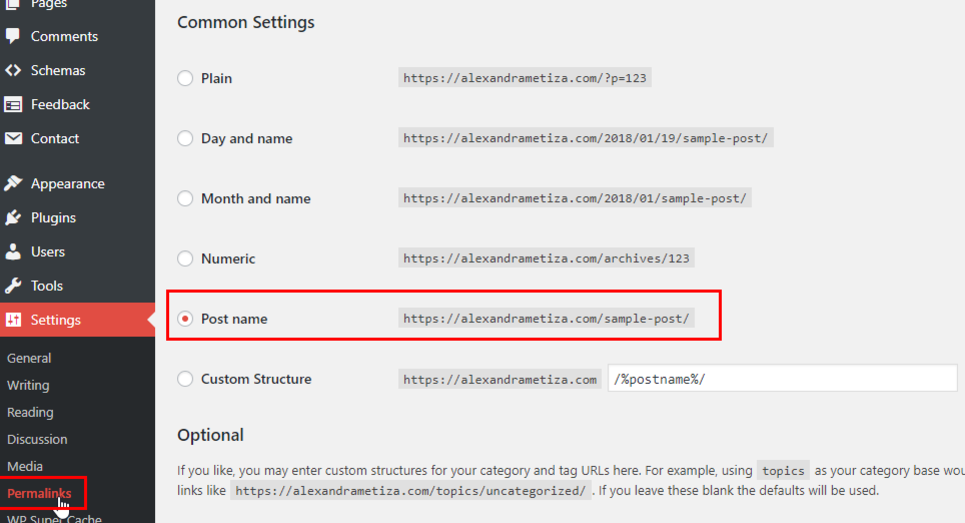
To avoid generating several addresses for the same page or post, go to your website console → ‘Settings’ → ‘Permalinks’ and in the ‘Common Settings’ choose the ‘Post Name’ parameter. Thus, each post will be available at one link.
3.1.1. What You Should Consider While Creating Permanent Links
- If your language consists of non-Latinic symbols, you need to install and activate any transliteration plugin for automatic converting your language symbols in URL addresses to Latinic.
- Brevity is the soul of wit, so don’t create too long URL addresses for your post.
- Search engine friendly URLs are important for your visitors and search engine robots. They must be user-friendly for average visitors and show them where this link leads.

3.2. Canonical URL Setting and rel=canonical Attribute
Another way of dealing with duplicates is to use the rel=canonical attribute. It shows search engines which page is more preferred for indexation. It means that if you have several pages with partially duplicated content and need to focus search engine on one of them, you can do it using rel=canonical without any damage to your website. Moreover, this attribute passes nearly the same amount of link equity from non-canonical pages to the main one (canonical). Even if there is no duplicate content on your website, we highly recommend to set rel=canonical attribute of this page to itself. In the case of WordPress websites the simplest solution is to use YOAST plugin.
3.2.1. How to Set Canonical Page in Yoast:
- Enter the page editor.
- Scroll down to the YOAST settings panel and open ‘Advanced’ tab on the left sidebar.
- Put the canonical page address in the ‘Canonical’ URL field. If this is an unique page or post that doesn’t duplicate any other content from your website, you need to paste a link to current page and save changes.
3.2.2. Canonical Issues
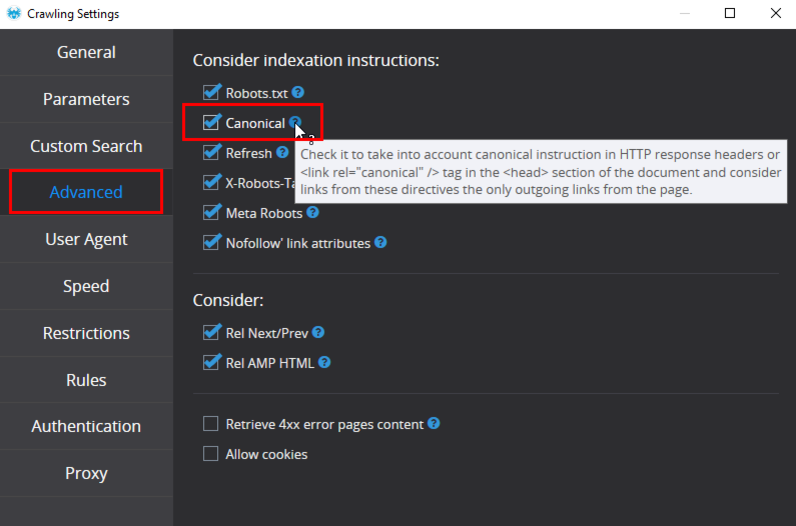
After setting rel=canonical attribute for all posts and pages you need to check if everything was done correctly. Use Netpeak Spider to find 5 types of issues with Canonical:
- Canonical chains
- Canonical chains blocked by Robots.txt
- Duplicate Canonical URLs
- Missing or empty Canonical
- Different page URL and canonical URL
For correct display of crawling results make sure that all actual instructions for search robots including Canonical are considered by Netpeak Spider. All other parameters required for canonical issues and duplicate content search are set by default.
3.3. Redirects Setting
We've already been talking about .htaccess redirects in our previous article 'WordPress SEO: Security Connection with HTTPS'. There is a detailed instruction for moving to HTTPS and setting server redirect configuration. Follow our instructions to successfully set redirection to the main version of your website with HTTPS and also without www and some symbols at the end.
3.4. The Final Check
Perform final duplicate content checking with Netpeak Spider to make sure that you’ve done everything right and all redirects work correctly. After completing the crawling, you only need to check if there are any critical issues on your website and all canonical tags are in their proper places.
4. Summary
- Content duplication (including main page content and different tags within single page and whole website) is one of the search engine negative ranking signals. That’s why Netpeak Spider duplicate content check is necessary for your website’s SEO.
- Rel=canonical attribute is an important tool which helps you focus search engines on pages preferred for indexation and protect yourself in case of content duplication.
- Among all duplicate content types that have negative consequences for your website’s positions in SERP, different website versions that exist at the same time are especially dangerous for SEO. You can solve this problem using server redirects with .htaccess file.
While we're preparing a new article about content optimization, feel free to leave your comments, questions, and suggestions. We’ll be glad to answer all of them and help you solve any problems with your WordPress websites.


