WordPress SEO: Поиск дубликатов и канонических ошибок
Мануалы

В борьбе за своё место под солнцем в топе поисковой выдачи SEO-специалисты зачастую прибегают не только к «законным» методам поисковой оптимизации, но и манипуляциям, которые отнюдь не приветствуются поисковыми системами. Среди них видное место занимает умышленное воровство контента, а также его многократное дублирование в рамках одного домена.
Несмотря на то, что второе не всегда происходит по вашей воле, Google и все прочие поисковые системы могут основательно понизить позиции вашего сайта, если обнаружат внутри него дублирующийся контент. В этой статье мы разберемся, как избежать подобного развития событий в случае с сайтами на CMS WordPress и найти все существующие дубликаты до того, как это сделает Google.
1. Роль дубликатов в SEO
Согласно Google, повторяющимся контентом обычно называют большие блоки информации в рамках одного или нескольких доменов, содержание которых либо полностью совпадает, либо почти не отличается.
Иными словами, если один и тот же материал размещён по двум различным ссылкам, это и есть дублирование.
Наличие дубликатов в сети ставит перед поисковыми системами вопрос, какой же из материалов стоит показывать в выдаче, и приводит к понижению позиций сайта с дублированным контентом.
1.1. Типы дубликатов
Можно выделить несколько основных типов дубликатов, которые встречаются внутри сайта:
- полные дубликаты страниц (идентичный HTML-код);
- дубликаты содержимого Body (содержимое в «теле» страницы);
- дубликаты Title (названия страницы);
- дубликаты Description (описания страницы);
- дубликаты H1 (главного заголовка).
Создавая страницы или записи в WordPress, используйте заголовки H2-H6. Заголовки первого порядка H1 генерируются автоматически. Как правило, в тег H1 помещаются названия рубрик, страниц или постов. Если в качестве хедера (главной «шапки» страницы) используется не изображение или логотип, а стандартный текстовый заголовок с названием сайта, то он также будет находиться внутри тега H1. Настоятельно рекомендуем как можно скорее избавиться от текстового хедера, чтобы на странице не было одновременно несколько тегов H1.
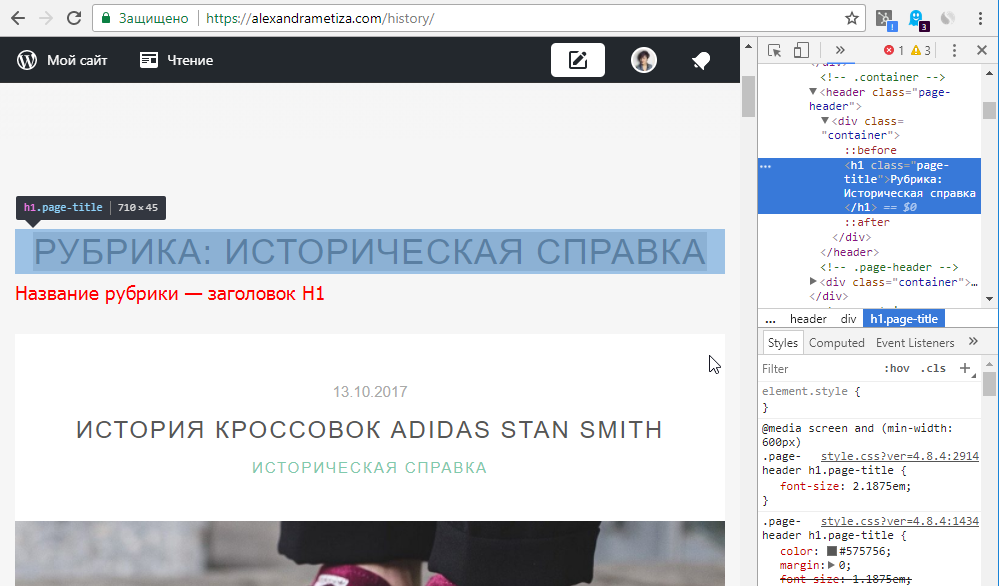
2. Как найти дубликаты на сайте
2.1. Поиск дубликатов с помощью Netpeak Spider
Все типы дубликатов внутри сайта, за исключением дубликатов тега H1, относятся к ошибкам с высокой степенью критичности. Максимально наглядно это демонстрирует Netpeak Spider, который подсвечивает существующие ошибки в соответствии с уровнем их влияния на SEO вашего сайта.
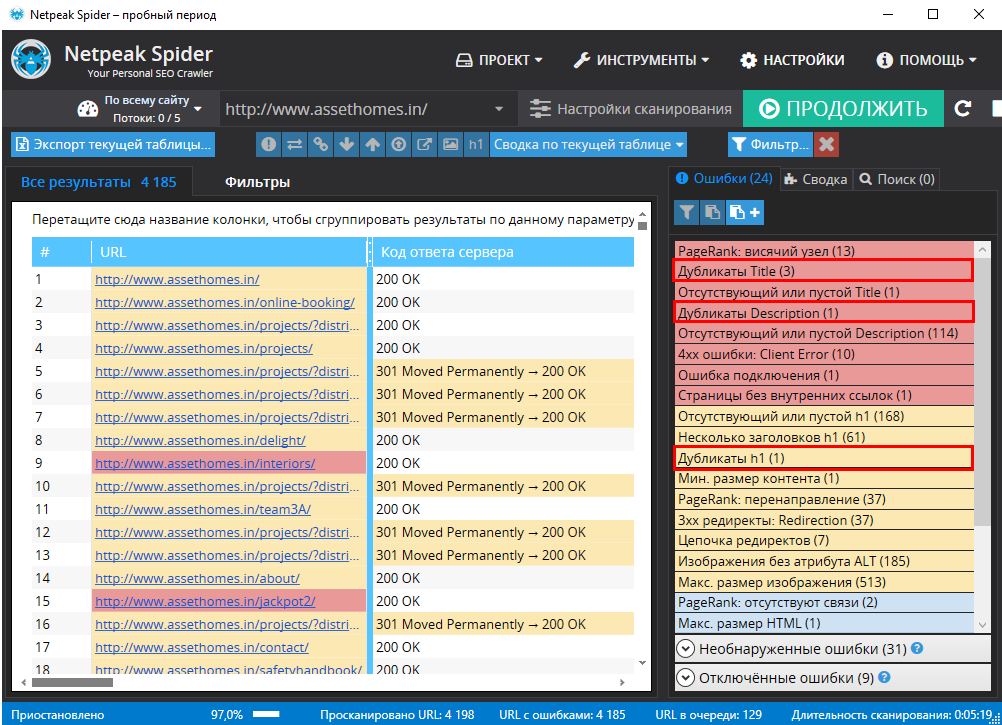
Хотите быстро проверять сайт на всевозможные дубликаты в Netpeak Spider? Эта и другие фичи (анализ 80+ SEO-параметров, встроенные инструменты, интеграции с сервисами аналитики, экспорт различных отчётов, сегментация и многое другое) доступны в тарифе Lite. Если вы ещё не зарегистрированы у нас на сайте, то после регистрации у вас будет возможность сразу же потестировать платные функции.
Ознакомьтесь с тарифами, оформляйте доступ к понравившемуся, и вперёд получать крутые инсайты!
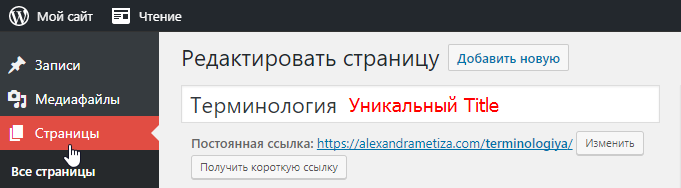
Для этого будет достаточно воспользоваться встроенным редактором страниц, а также плагином YOAST, который мы неоднократно упоминали.
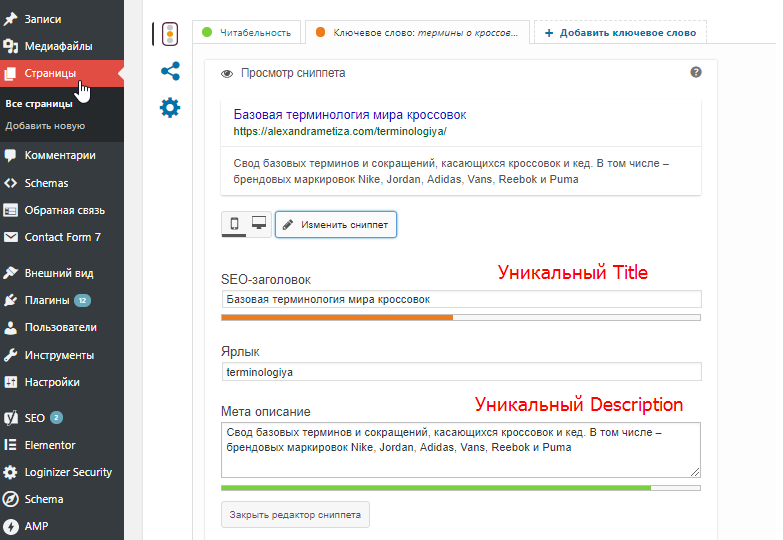
В случае с дублированием содержимого Body (основного содержимого страницы или поста) нам нужно указать каноническую страницу-первоисточник, которую поисковик будет определять как приоритетную. Однако к разбору подобных случаев мы вернёмся чуть позже.
Если же Netpeak Spider показывает, что на сайте присутствуют дубликаты целых страниц, нужно поставить либо редиректы (перенаправления), либо указать для них каноническую страницу.
2.2. Откуда берутся дубли страниц, которые вы не создавали:
- CMS (в нашем случае — WordPress) может генерировать несколько URL для одной статьи, если вы размещаете её одновременно в нескольких рубриках без указания соответствующих настроек.
- Если у вас одновременно существуют версии сайта с префиксом www и без него, а также http и https-версии без соответствующих редиректов, поисковик определит их как дубликаты.
- Если у вас есть несколько вариантов страницы со слешем в конце или какими-либо символами после него, а также UTM-метками и GET-параметрами, то они также определяются как полные дубли.
3. Как избавиться от дубликатов
3.1. Настраиваем постоянные ссылки в WordPress
Для того, чтобы у вас не генерировалось несколько различных адресов для одной и той же страницы, заходим в Консоль вашего сайта → Настройки → Постоянные ссылки и в блоке «Общие настройки» выбираем параметр «Название записи». Таким образом, каждая из создаваемых вами записей будет доступна только по одному адресу.
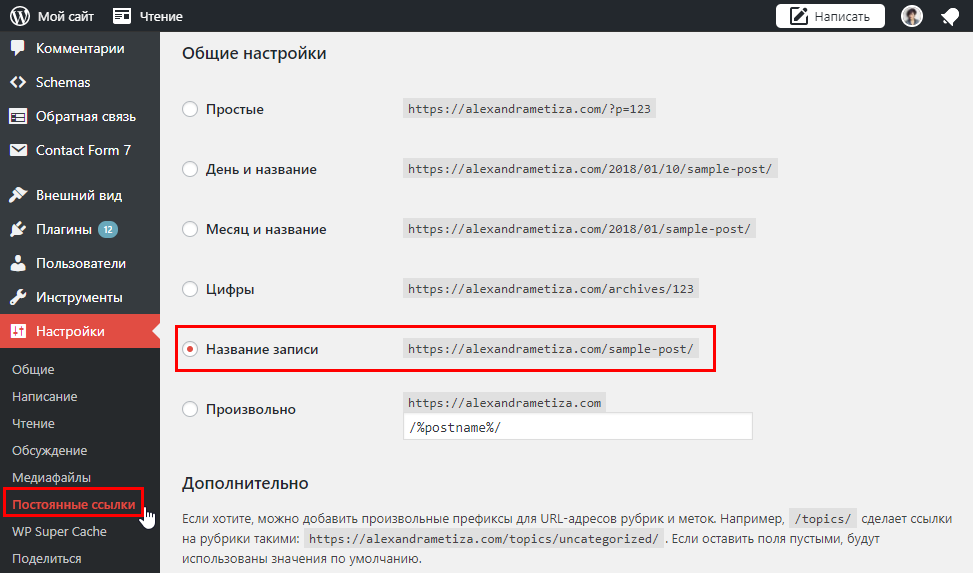
3.1.1. Что нужно учитывать при создании постоянных ссылок:
- Необходимо установить и активировать плагин Cyr-to-Lat для автоматической конвертации кириллических символов в латинские в URL-адресах.
- Краткость — сестра таланта, а потому не пытайтесь сделать URL-адрес вашего поста чересчур длинным.
- ЧПУ или «человеко-понятные урлы» важны как для посетителей вашего сайта, так и для роботов поисковых систем. Потому делайте URL-адрес таким, чтобы сразу было ясно, куда он ведёт читателя.
3.2. Указываем канонические ссылки и настраиваем атрибут rel=canonical
Ещё один способ борьбы с дубликатами — атрибут rel=canonical. Он используется для устранения полных или частичных дублей контента на сайте. С его помощью вы указываете роботам поисковых систем предпочтительную для индексации страницу. То есть если у вас есть несколько страниц с частично повторяющимся контентом, и вам необходимо сосредоточить внимание поисковика лишь на одной из них, rel=canonical позволит вам это сделать без ущерба для сайта в целом. К тому же, при использовании этого атрибута все характеристики дополнительных (неканонических) страниц передаются основной (канонической) странице.
И даже если на сайте нет дублей страниц (или их отдельных частей), рекомендуется ставить всем страницам rel=canonical на саму себя.
В случае с сайтами на базе WordPress это проще всего реализовать с плагином YOAST.
3.2.2. Канонические ошибки
После того, как вы добавите канонические ссылки на все страницы и посты, проверьте правильность выполненной работы с помощью Netpeak Spider. Программа может обнаружить пять типов ошибок, связанных с атрибутом Canonical:
- Цепочки Canonical;
- Цепочка Canonical, заблокированная в Robots.txt;
- Дубликаты Canonical URL;
- Отсутствующий или пустой Canonical;
- Разные URL страницы и Canonical URL.
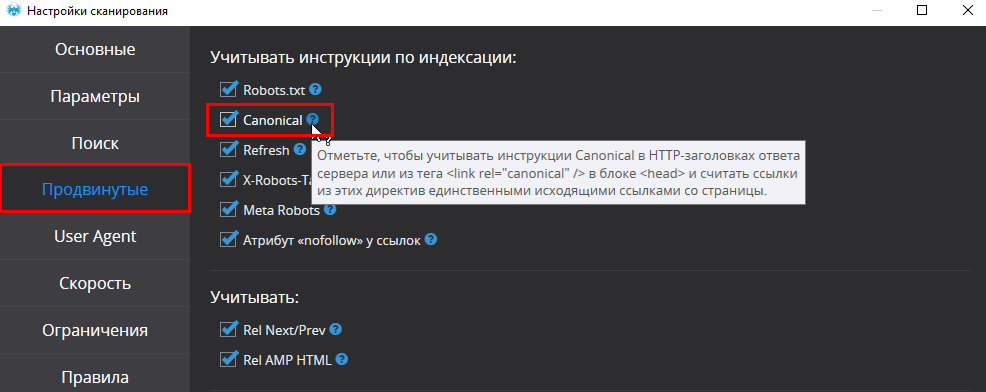
Для корректного отображения результатов поиска для начала убедитесь, что в продвинутых настройках сканирования учитываются все указанные вами инструкции для поисковых роботов, в том числе — атрибут Canonical.
Все прочие настройки, необходимые для поиска канонических ошибок и дубликатов, выставлены в Netpeak Spider по умолчанию.
3.3. Настраиваем серверные редиректы
Мы уже говорили о настройке редиректа в файле .htaccess в рамках статьи, посвященной настройке безопасного подключения с HTTPS. В третьем пункте статьи приведена инструкция для переезда на HTTPS и установки настроек серверного редиректа. Следуя ей, вы настроите переадресацию на единственную версию сайта: с HTTPS, без префикса www и без дополнительных слешей и символов после него.
Сейчас будем использовать аналогичную инструкцию, так что если вы уже настраивали с нами редирект на своем сайте, можете пропустить этот пункт.
Как только настроили редирект на главную версию сайта, не забудьте указать в файле Robots.txt инструкцию Host. Она должна содержать ссылку на главное зеркало сайта (основная его версия). Эта инструкция выполняется только роботами поисковой системы Яндекс. Читайте о том, как её указать в статье «Создание файла Robots.txt. Использование тега Meta Robots. XML-карта сайта» (пункт 1.4.).
3.4. Финальная проверка
Чтобы убедиться, что вы всё сделали правильно, и переадресация выполняется корректно, выполните заключительную проверку на наличие дублей в Netpeak Spider. После окончания краулинга вам нужно лишь убедиться, что на сайте не присутствуют упомянутые ранее ошибки высокой и средней критичности, а все канонические атрибуты выставлены на верных страницах в соответствии со своим назначением.
4. Подводим итоги
- Дублирование контента, включая основное содержимое страницы и различные теги внутри него, входит в число факторов, негативно влияющих на ранжирование вашего сайта поисковыми системами. Потому проверка на наличие дубликатов при помощи Netpeak Spider является важной составляющей оптимизации вашего сайта.
- Атрибут rel=canonical — важный инструмент, который помогает сосредоточить внимание поисковиков на предпочтительных для индексации страницах, а также обезопасить себя в случае дублирования контента внутри сайта.
- К дубликатам, на которые негативно реагируют поисковые системы, относятся также и различные версии сайта, существующие параллельно. Эту проблему помогает решить настройка редиректов внутри серверного файла-конфигуратора .htaccess.
А пока новый материал, посвященный оптимизации контента в CMS WordPress, находится в процессе подготовки, мы ждём ваших комментариев, вопросов и предложений. Мы будем рады ответить на них и помочь вам в решении проблем, связанных с SEO ваших сайтов на базе WordPress.


