WordPress SEO: Создание файла Robots.txt. Использование тега Meta Robots. XML-карта сайта
Мануалы

Мы продолжаем нашу серию материалов о пошаговой технической оптимизации новых сайтов для начинающих специалистов и вебмастеров. В этом посте расскажу, как создать файл Robots.txt, тег Meta Robots и XML-карту сайта.
1. Файл Robots.txt
Согласно Google, Robots.txt — это специальный файл, расположенный в корневом каталоге сайта. Вебмастер указывает в нём, какие страницы и данные не следует индексировать. Файл содержит директивы, описывающие доступ к разделам сайта. Например, с его помощью можно создать отдельные настройки доступа для поисковых роботов, предназначенных для мобильных устройств и обычных компьютеров.
По сути, это текстовый файл, который можно редактировать в стандартном блокноте.
1.1. Основные требования к файлу Robots.txt
- Он должен быть доступен по адресу: site.com/robots.txt;
- Размер файла не должен превышать 500 килобайт;
- Текст не должен содержать кириллицы. Если же у вас кириллический домен, то нужно использовать Punycode для его транскрипции.
1.2. Нюансы файла Robots.txt
Не забывайте, что:
- Инструкции Robots.txt носят рекомендательный характер;
- Настройки Robots.txt не влияют на другие сайты (в Robots.txt можно закрывать только страницы или файлы данного сайта);
- В командах Robots.txt учитывается регистр.
Виды указаний Robots.txt поисковым роботам:
- Частичный доступ к отдельным частям сайта;
- Полный запрет сканирования.
1.3. В каких случаях используется Robots.txt
С помощью файла Robots.txt мы можем закрывать от поисковых роботов страницы, которым нежелательно попадать в индекс, например:
- запрет индексирования страницы с личной информацией пользователей;
- страницы с документацией и служебной информацией, которая не влияет на отображение интерфейса сайта;
- определённые типы файлов, например, PDF-файлы;
- панель администратора и т.п.
1.4. Как создать Robots.txt
Файл Robots.txt создать можно при помощи любого текстового редактора. Его синтаксис включает в себя три основных элемента:
Помимо этого, в файле могут присутствовать также два дополнительных элемента:
Полученный файл Robots.txt мы помещаем в корневой каталог сайта. Если домен настраиваемого сайта основной — файл будет расположен по адресу /public_html/. Если дополнительный — в одноимённой папке вида /site.com/. Чтобы поместить файл в соответствующую папку, вам понадобится любой FTP-клиент (например, Filezilla) и доступ к FTP, который предоставляется при покупке хостинга провайдером.
User-agent
Инструкции Allow и Disallow воспринимаются роботами как единое целое и относятся только к тем поисковым роботам, которые были указаны в первой строке. Всего существует порядка 300 различных поисковых роботов. Если вы хотите применить одни и те же правила ко всем поисковым роботам, то в поле «User-agent» достаточно поставить звёздочку (*). Этот символ означает любую последовательность символов.
Disallow
Disallow предоставляет поисковым роботам рекомендации, какие из частей сайта не следует сканировать.
Если вы ставите в Robots.txt Disallow: /, то закрываете весь контент сайта от сканирования.
Если вам необходимо закрыть от сканирования конкретную папку, используйте Disallow: /papka.
Подобным образом можно скрыть конкретный URL, файл или же определенный тип файлов. К примеру, если вам нужно закрыть от индексации все PDF-файлы на сайте, в Robots.txt нужно прописать следующую инструкцию:
Звёздочка перед расширением файла означает любую последовательность символов (любое название), а знак доллара в конце указывает, что запрет индексации касается исключительно файлов, заканчивающихся на .pdf.
Перечень команд блокировки URL для файла Robots.txt детально прописан в справочных материалах от Google.
Allow
Allow разрешает сканировать какой-либо файл, директиву или страницу. Допустим, необходимо, чтобы роботы могли посмотреть только страницы, которые начинались бы со слова /other, а весь остальной контент закрыть. В этом случае прописывается следующая комбинация:
Правила Allow и Disallow сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. В примере получился был бы следующий порядок учёта инструкций: сначала робот учёл бы Disallow: / , а затем Allow: /other, то есть папка /other проиндексировалась бы.
XML Sitemap
Карта сайта — это файл, который содержит адреса всех URL сайта, которые должны быть проиндексированы роботами. Обычно она размещается в корневом каталоге сайта и имеет вид http://site.com/sitemap.xml. Карта сайта — файл, благодаря которому поисковый робот быстро обнаруживает изменения в списке существующих URLов и появление новых. Он будет заглядывать в этот файл при каждом новом обходе сайта. У вас может быть несколько разных карт в зависимости от контента — например, дополнительная карта для изображений или Google News Sitemap для контентно-новостных проектов.
Для создания XML-карты сайта вы можете использовать встроенный генератор Netpeak Spider.
Чтобы сгенерировать XML Sitemap и Image Sitemap для изображений в Netpeak Spider вам нужно открыть меню «Инструменты» и выбрать соответствующий пункт. В открывшемся окне мы выбираем, какая карта нам требуется, задаём необходимые параметры и генерируем карты. В случае, если размер карты превышает 5 Мб, вы можете сжать её в .gz архив для экономии трафика. Более детально о генерации Sitemap в Netpeak Spider можно прочитать в нашем подробном гайде.
После создания Sitemap мы помещаем один или оба файла в корневой каталог сайта и указываем их адрес в файле Robots.txt.
Инструкцию нужно правильно вписать в файл Robots.txt:
Если вам требуется XML-карта Google News Sitemap, вы можете использовать плагин XML Sitemap & Google News feeds. С помощью этих плагинов сгенерированные карты помещаются в корневой каталог сайта автоматически.
1.5. Возможные проблемы в файле Robots.txt:
- Неправильный порядок команд. Должна соблюдаться чёткая логическая последовательность инструкций. Сначала User Agent, затем Allow и Disallow. Если вы разрешаете весь сайт, но запрещаете какие-то отдельные разделы или файлы, то изначально ставится Allow, затем — Disallow. Если же запрещаете весь раздел, но хотите открыть какие-то его части, первоочередным является запрет, а значит Disallow будет стоять выше Allow.
- Запись нескольких папок/директорий в одной инструкции Allow или Disallow. Если вы хотите прописать в robots.txt несколько различных инструкций Allow и Disallow, то каждую из них нужно указывать с новой строки:
- Неправильное название файла. Имя должно быть исключительно «robots.txt», состоящее только из строчных латинских букв.
- Пустое правило User-agent. Если вы хотите задать общие инструкции для всех роботов, то ставьте звёздочку.
- Ошибки синтаксиса. В случае, если вы по ошибке указали какой-то из дополнительных элементов синтаксиса в какой-то из инструкций, робот может неверно их истолковать.
2. Meta Robots
Метатег robots — это тег, который позволяет определять настройки индексации и отображения в результатах поиска отдельно для каждой страницы. Его следует помещать в раздел <head> кода страницы.
В качестве примера мы рассматриваем сайт с CMS WordPress, а потому не можем делать этого напрямую. Для создания базовых meta robots для всех поисковых роботов будет достаточно базового функционала SEO-плагина Yoast, который можно найти в продвинутых настройках. Для расширенных возможностей потребуется плагин Meta Tag Manager, с помощью которого мы сможем добавлять любые meta-теги на все страницы нашего сайта. Если вы работаете с другой CMS, вы можете без проблем найти аналогичное решение для своего движка.
Meta Robots состоит из двух ключевых атрибутов: name и content. Первый отвечает за выбор нужного нам поискового робота, а второй — за инструкции для него.
Такой тег сообщает сразу всем поисковым роботам, что данную страницу не нужно индексировать и показывать в результатах поиска. Но если мы изменим name, к примеру, на googlebot, то инструкция будет относиться только к поисковому роботу Google.
Если нужно задать инструкции для нескольких поисковых роботов, можно использовать несколько метатегов robots:
Тег указывает на запрет индексирования для поискового робота Google.
Тег указывает на запрет отображения расширенного сниппета для новостного поискового робота Google.
Перечень всех возможных директив, которые используются в Meta Robots, можно найти в инструкциях для вебмастеров от Google.
3. Проверка на ошибки
3.1. Проверка файла Robots.txt и Meta Robots
Чтобы проверить, правильно ли заданы инструкции в файле Robots.txt и тегах Meta Robots, просканируйте сайт в Netpeak Spider.
Отметьте в продвинутых настройках сканирования, что вы хотите учитывать инструкции Robots.txt и Meta Robots, и соответственно выберите User-agent (Googlebot, например) на смежной вкладке настроек сканирования. Netpeak Spider просканирует файл с учетом всех указанных правил, как это будет выполнять робот поисковой системы.
3.2. Проверка XML Sitemap
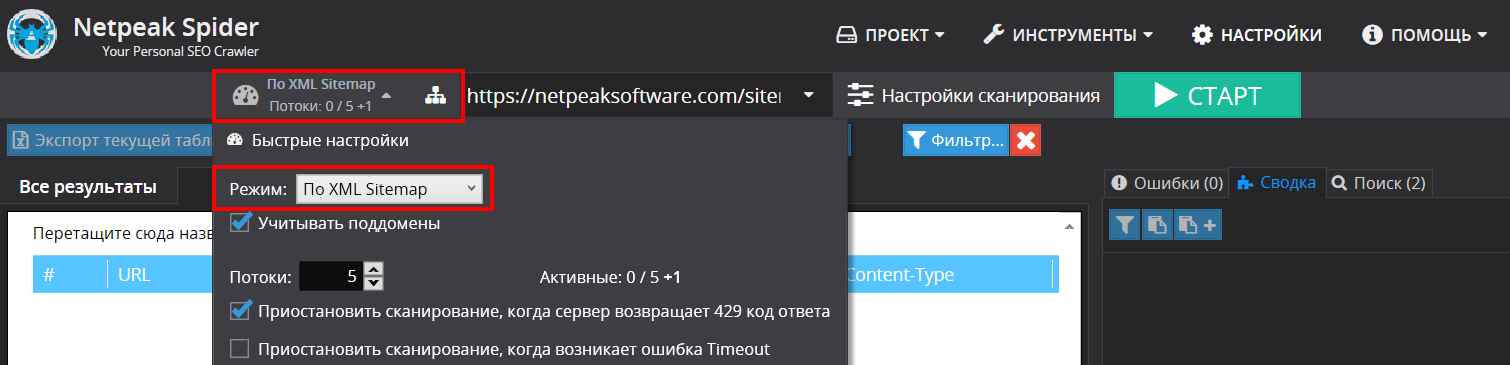
Для проверки карты сайта на ошибки необходимо в быстрых настройках (слева от адресной строки) выбрать режим проверки «по XML Sitemap». Проверка производится согласно схемам валидации для файлов Sitemap и для файлов индекса Sitemap, которые поддерживаются поисковыми системами Google, Bing, Yahoo и Yandex.
У Netpeak Spider есть бесплатная версия без ограничений по времени, в которой вы можете проверить сайт на ошибки, в том числе провести проверку индексации и найти ошибки в XML-карте сайта. Также во Freemium-версии доступны и другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.
4. Подводим итоги
- Создание файла Robots.txt и настройка метатега robots являются одними из ключевых этапов SEO-оптимизации сайта. Инструкции, которые задаются с их помощью, определяют, какие из частей вашего сайта должны быть видны поисковым роботам, а какие — нет.
- Проверка файла Robots.txt с помощью Netpeak Spider имеет первостепенное значение: малейшая ошибка в синтаксисе может закрыть ваш сайт от сканирования или же, наоборот, открыть роботам доступ к нежелательным файлам.
- Не стоит недооценивать значение XML-карта сайта. Корректная, своевременно обновляемая карта сайта позволит поисковым роботам быстро обнаружить все изменения в списке существующих URLов, а также появление новых.
В следующем посте мы поговорим о видах дубликатов, канонических ошибках и настройке редиректов. Следите за новостями: совсем скоро мы порадуем вас множеством новых интересных материалов!


