Netpeak Spider 3.2: JavaScript Rendering and SEO Audit in PDF
Updates

Folks, in this post you will find out what we've prepared in the long-awaited Netpeak Spider 3.2 update :) We can't wait to share all details but first, let's watch a short video teaser.
Now let's get on with the details. If you're so eager to read a certain part, save your scroll wheel and use the clickable content:
- 1. JavaScript Rendering
- 2. SEO Audit
- 3. Enhanced Issue Description
- 4. Other Changes
- 5. In a Nutshell
To get access to Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
1. JavaScript Rendering
Before we talk about this long-desired feature in our crawler, let's go over how Google indexes content created dynamically using JavaScript.
Can't wait to try JavaScript rendering? Hide details and go to the descripton of the rendering settings in Netpeak Spider.
1.1. What Is JavaScript Rendering
JavaScript rendering is the final view of the webpage's HTML code with the changes made by JS-scripts.
Initially, search robots crawled and indexed only content in the static HTML source code. Now website developing includes JS frameworks (such as Angular, React, and Vue) to add content partially or fully using JavaScript.
Here is a clear example of HTML code before and after JavaScript execution from our own website:
- the view of Netpeak Spider price on one of our pages – before JavaScript execution:
- the view of the same block after JS-scripts execution:
Google had to adapt to the evolution of web technologies, and now it processes and renders content that is added to a page using JavaScript. Their web rendering service (WRS) is based on Chrome browser.
Googlebot crawls sites in 2 waves:
- During the first one, it (as before) works only with HTML: it requests source code, crawls and indexes content, and also adds found links to the crawl queue.
- The second wave involves content rendering. At this stage, search bot needs resources to execute JavaScript. Therefore, if there are insufficient crawling resources, rendering requires an extra time.
Google separates indexing and rendering to quickly index content that is available without JavaScript, and then go back and add content for which it is required.
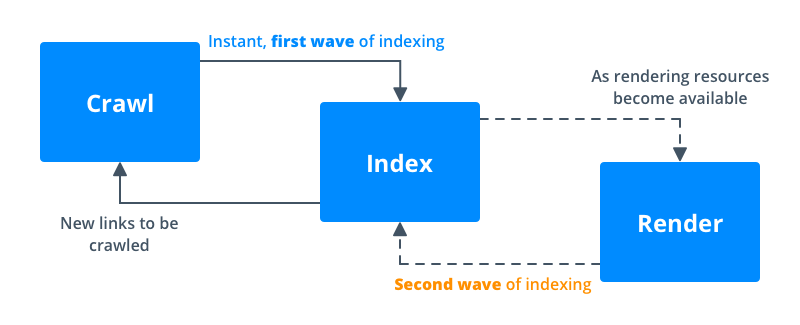
If Google did not receive important page content at the first wave, then adding of this content to the index will occur at the second wave with possible delays.
Modern web applications use 2 ways of content rendering:
- Client-side rendering (CSR) – the search engine gets an empty HTML page (with almost no content), and the main content is added to the page using JavaScript scripts. In this case, you have to wait for the second wave of crawling, and the content may be indexed with a delay.
- Server-side rendering (SSR) – in this case, the search engine receives the full HTML with all important webpage content. Therefore, Googlebot adds content to the index at the first wave of crawling, and you don't have to worry about possible delays of the second wave.
An advanced SEO specialist has to understand these nuances. Essentially, JavaScript SEO is ensuring that content added to a page with JavaScript is successfully processed by a search robot, indexed, and ranked.
Now we will explain why JavaScript rendering is needed in modern SEO tools, and how to use it.
1.2. Why Does Crawler Need JavaScript Rendering
If you try to crawl a site that uses CSR in a traditional way (analyzing only HTML), the crawler will not be able to detect the data added with JavaScript (links, descriptions, images, etc.), thus it will not find issues on such site.
That's why, to process such sites as a Googlebot, the crawler needs a browser to execute JavaScript → to download all the content added by the scripts and only then analyze it.
1.3. How to Set up JavaScript Rendering in Netpeak Spider
We've implemented JavaScript rendering in Netpeak Spider using integrated Chromium browser. The world's most popular browser Chrome was created on the basis of that browser. We use one of the latest versions of Chromium, which makes crawling in Netpeak Spider as advanced and close to Googlebot as possible. Though it's not the same, because Google uses the old version of Chrome 41 browser, which does not support some modern JavaScript features.
To start crawling pages with enabled JS rendering, go to the 'Settings' → 'General' tab → tick the 'Enable JavaScript rendering and set AJAX timeout, s' checkbox:
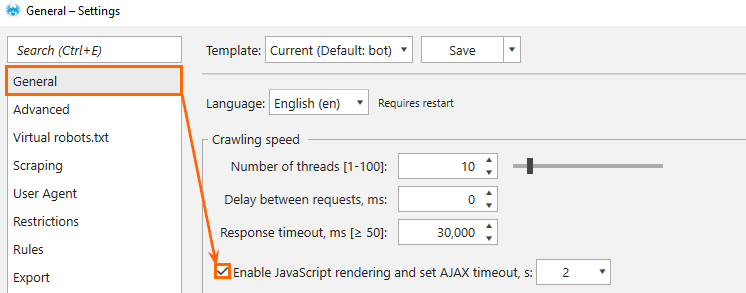
The 'AJAX timeout' sets the timeout for JavaScript execution after the page and resource files (JS / CSS) are loaded. It is necessary for all the scripts to have enough time to work.
Note: the longer AJAX timeout, the more time crawling takes. In most cases, the default value (2 seconds) will be sufficient for JavaScript execution. However, you can customize it yourself if the analyzed site has the AJAX requests that take longer to execute. Also, we do not recommend lowering the default value, because the code may not be fully processed.
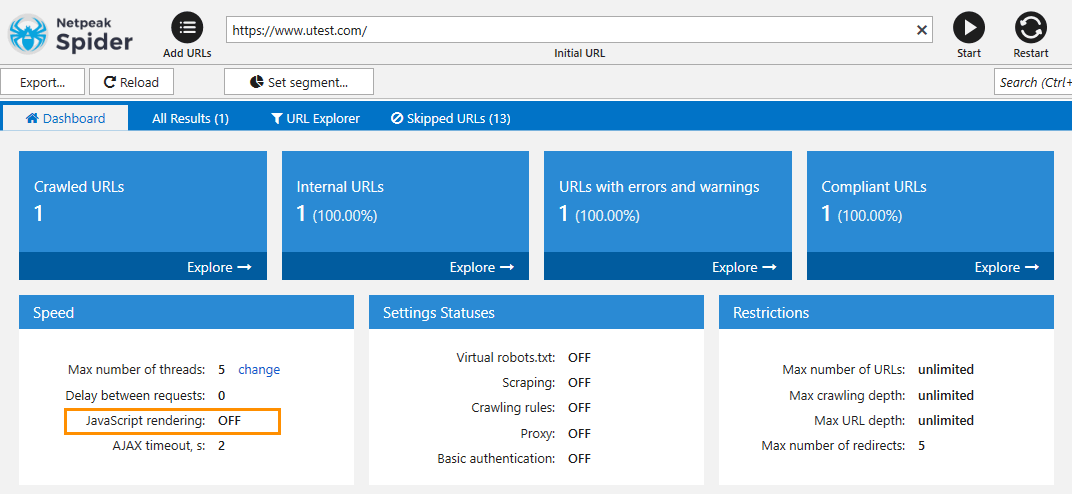
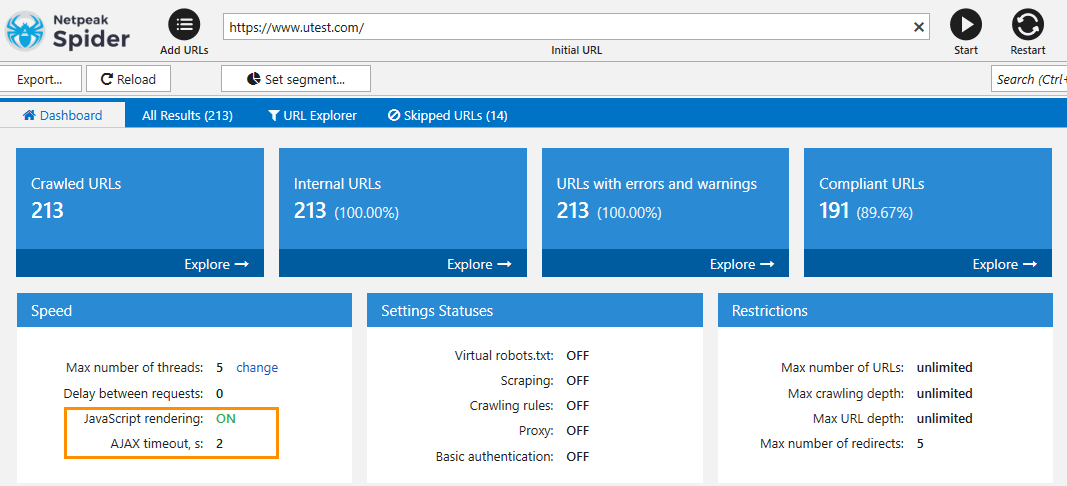
Let's look at the example of crawling a website where the whole content is shown using JavaScript. In this case, you will not be able to crawl such site without enabled JS rendering.
1.4. Peculiarities of JS Rendering in Netpeak Spider
Netpeak Spider executes JS scripts only for HTML pages with a 200 OK response code. It speeds up the program and allows you not to waste resources on the pages that don't need the browser for processing.
If you want to crawl a site with enabled JavaScript rendering, remember that it increases crawling time. When the crawler works without rendering, there is only one request to get the HTML code of a page. When you enable the rendering, there is an additional request to Chromium to get the HTML code, load the JS and CSS files, and execute the JavaScript during the time specified in the AJAX timeout setting. Accordingly, crawling will take more time.
Tip: we recommend enabling JavaScript rendering only if you need to crawl a site with CSR, and we do not recommend enabling it to crawl all sites by default (particularly, if you crawl sites with thousands of pages or more, since it may cause a heavy load on the computer).
Also, while JavaScript rendering is enabled, Netpeak Spider:
- uses the User Agent chosen by a user in the crawling settings;
- supports basic authentication;
- supports list of proxies;
- blocks requests to analytics services (Google Analytics, Yandex.Metrica, etc.) in order not to distort site analytics;
- considers cookies regardless of the settings on the 'Advanced' tab;
- doesn't load iframes and images;
- is limited to 25 threads. So if you set 100 threads in the crawling settings, Netpeak Spider will simultaneously crawl 100 documents in the usual way, however, only 25 compliant HTML pages will be rendered.
Now let's dive into the second new feature in our crawler. We reckon that visual learners will definitely like it ;)
2. SEO Audit
In the new Netpeak Spider version, you can export a report in PDF format in one click with technical SEO audit based on the crawling results.
This feature allows you to get the best of 'two worlds' in Netpeak Spider: the deep analysis and customization of the desktop tool and the results visualization like in the most advanced online products.
This report is available on the 'Reports' tab:
We set a goal to achieve the highest quality data visualization adding completely new metrics to the program logic, and took into account the following nuances:
- The report will only show data found on a site during crawling. Sections and diagrams without data are not displayed. It means that you will not see empty sheets and tables because some issue / parameter was not found during the crawling.
- The report displays illustrative examples for data analysis, rather than a complete list of relevant URLs. So, when analyzing medium and large sites, you will not have to scroll through dozens of the report pages with hundreds of hard-to-read links.
2.1. Who Will Find This Report Useful?
First of all, PDF reports will be useful for SEO specialists. This is an improved and expanded (20+ pages) version of the dashboard, which is convenient for assessing the optimization quality of a project or a list of URLs. The key information for site audit is clearly shown here. It is enough to add your own recommendations and you can send it to a client or colleagues for implementation.
If you are a sales specialist, the report contains a brief summary of the site status. It can help you quickly evaluate the project and discuss the scope of work with the client.
2.2. Structure and Peculiarities of PDF Reports
The report is based on the data from the 'All Results' table, which is directly affected by the settings, parameters, and segmentation. You can test the report by changing different settings.
Each section of the report is dedicated to a certain optimization aspect. Let's take a closer look at each of them.
2.2.1. Title Page + Contents
If you crawl a website in Netpeak Spider, then the first page will show a screenshot of the initial page and the domain of the crawled resource. So it is easy to distinguish reports for different sites.

If you crawl a list of URLs, you'll see the corresponding image instead of a screenshot:
To ease navigation through the document, there is an anchor link for each section of the content.
2.2.2. Overview
This section contains a brief overview of crawling results. This is the most succinct report. It allows you to quickly understand what data is being analyzed, and what issues were found.
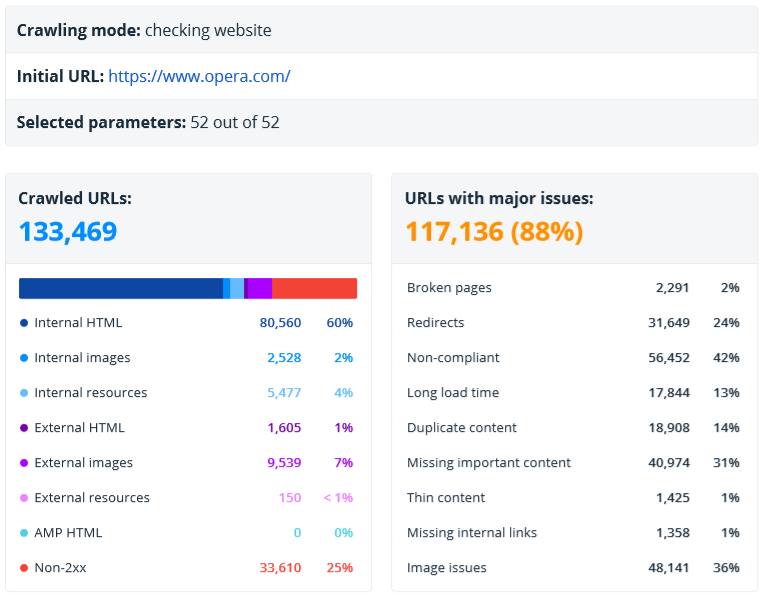
It shows the following data:
- Crawling mode → crawling of a website or a list of URLs.
- Initial URL. If Netpeak Spider crawls a list of URLs, you'll see the first URL from the list.
- The number of parameters selected during report generation.
- The number and types of URLs the current report is based on.
- The number of URLs with major issues (errors and warnings).
- The main types of issues → fresh grouping for even faster understanding of audit results.
- Content type → separate diagrams for external and internal pages.
- The main hosts.
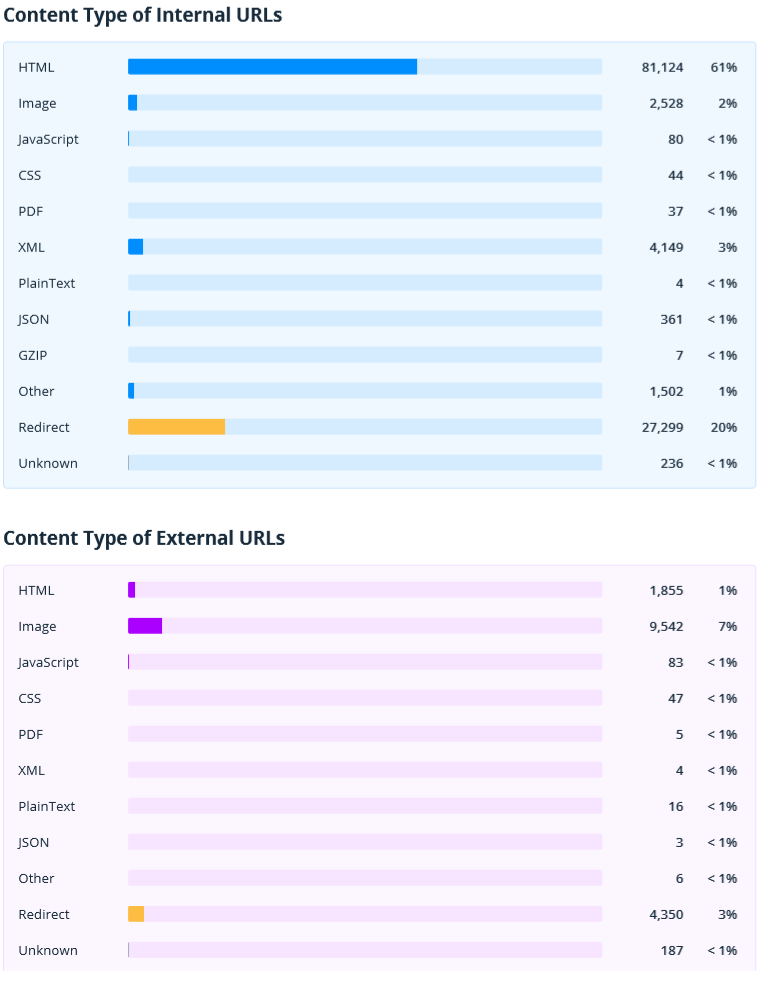
2.2.2.1. Content Type (of Internal and External URLs)
These reports help evaluate and compare the number of different document types found during crawling. You'll see separate charts for internal and external URLs (here and in other report sections they will be marked in blue and violet accordingly).
2.2.2.2. Top Hosts
This table contains main hosts analyzed in the audit. It may be very handy if your website has a lot of hosts or if you crawl a list of URLs.
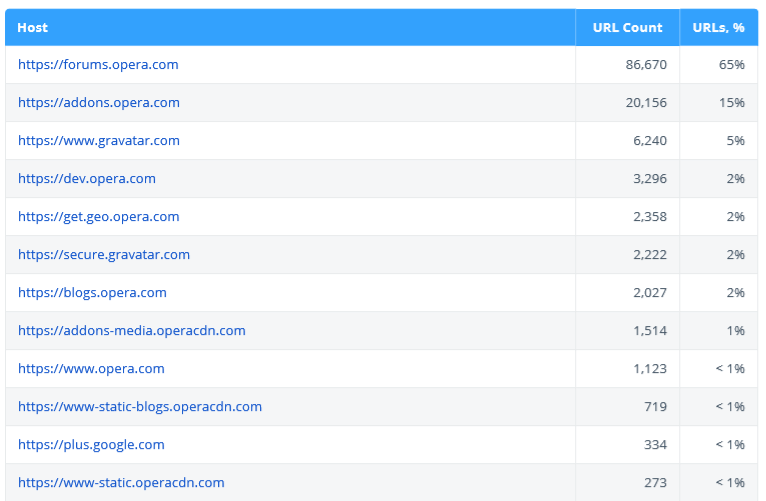
2.2.3. URL Structure
This report helps to visualize the structure of crawled URLs. It shows the most popular hosts and second-tier segments (e.g. site.com/category/).
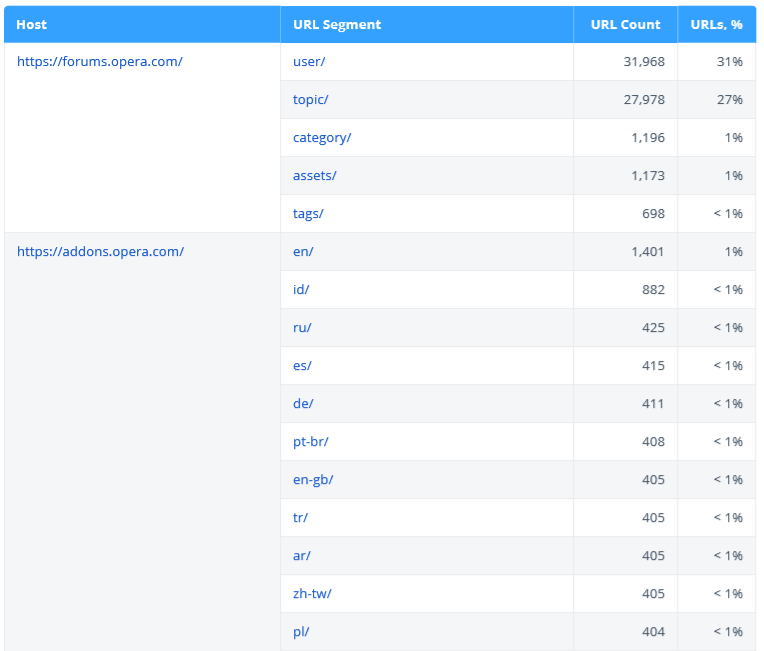
Note that the table shows only up to 40 segments. You can get a complete site structure in the 'Site structure' report in Netpeak Spider. Also, URLs with redirects are excluded from this report because they are not the final addresses of the pages and it makes no sense to analyze their segments.
Also, we've added data about [root documents] – the number of documents in the site root (they do not contain segments).
2.2.4. Status Codes
This section shows status codes of internal and external URLs.
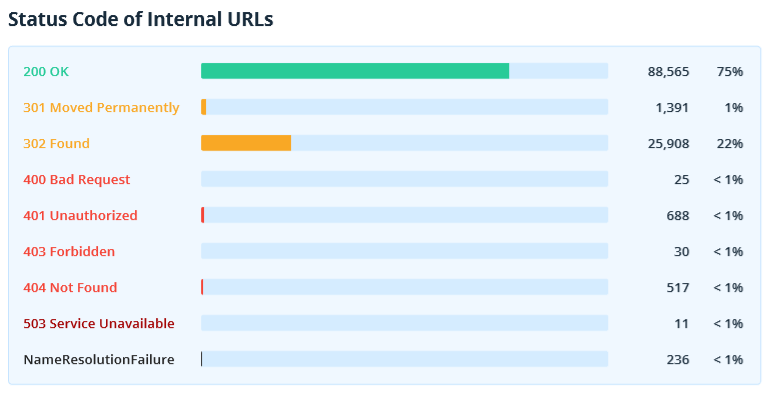
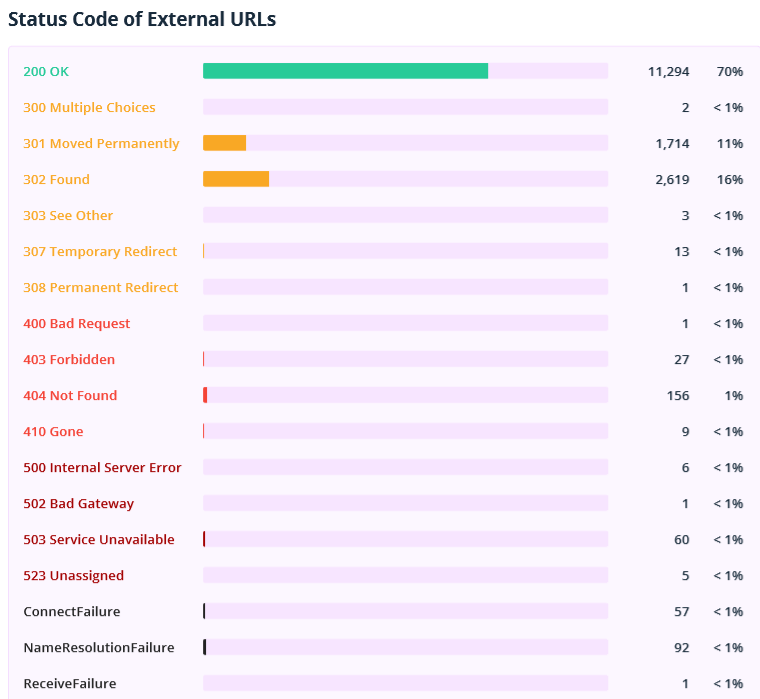
Pay attention to the unavailable documents, redirects, pages returning 4xx and higher status codes. Export the 'Broken links' and 'Redirects: incoming links and final URLs' reports in Netpeak Spider to get a list of links leading to such pages.
2.2.5. Crawling and Indexing
This section shows data on instructions and server settings affecting website crawling and indexing (only internal URLs are analyzed here). Note that non-compliant documents usually don't drive search traffic and even waste crawl budget.
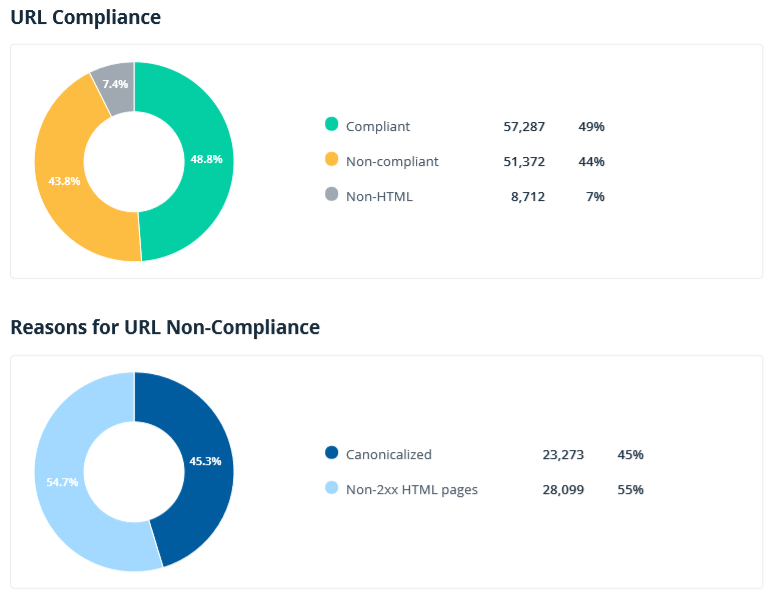
You might be already familiar with the charts on reasons for URL compliance and non-compliance (they are also available on the Netpeak Spider dashboard). Meta Robots, X-Robots-Tag, and canonical overviews are the new reports that are currently available only in audit.
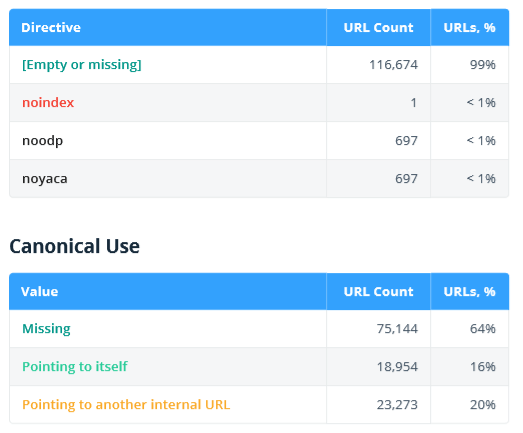
2.2.6. Click and URL Depth
This section shows click depth (the number of clicks from the initial page) and URL depth (the number of segments in a URL).
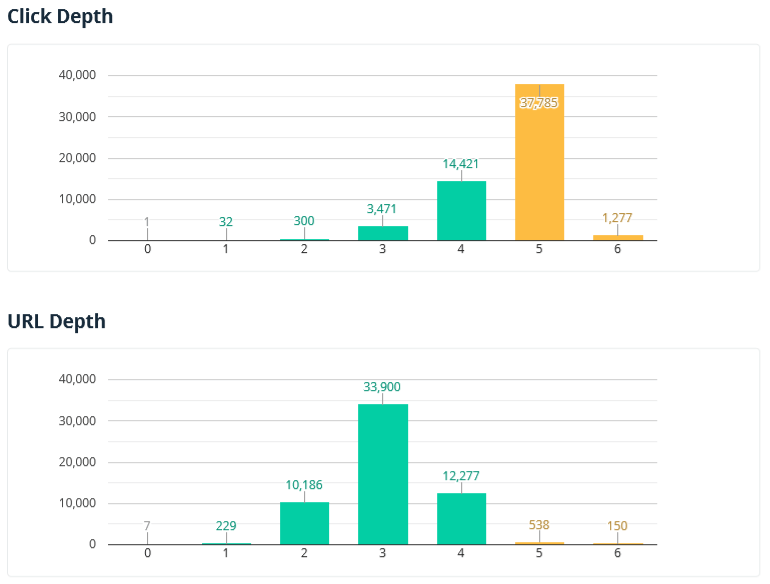
Note that only internal compliant HTML pages are analyzed in this report. The '0' value is assigned to the initial URL or to all URLs added as a list.
More about possible issues:
- Pages with click depth over '4' may have indexing issues, thus not drive organic traffic.
- Page URLs with depth over '4' and/or too long address may be hard to perceive for site visitors.
2.2.7. Load Speed
This report helps to evaluate the server response time of internal and external documents. This parameter is a major ranking factor – fast sites usually drive more traffic, have lower bounce rate, and higher conversion rate. Note that only URLs returning 2xx status code are analyzed in this report.
Typically, a server spends more time generating and processing HTML pages, while static files are usually cached and returned faster. That's why we have separated the reports for HTML and non-HTML pages to analyze pages of similar types.
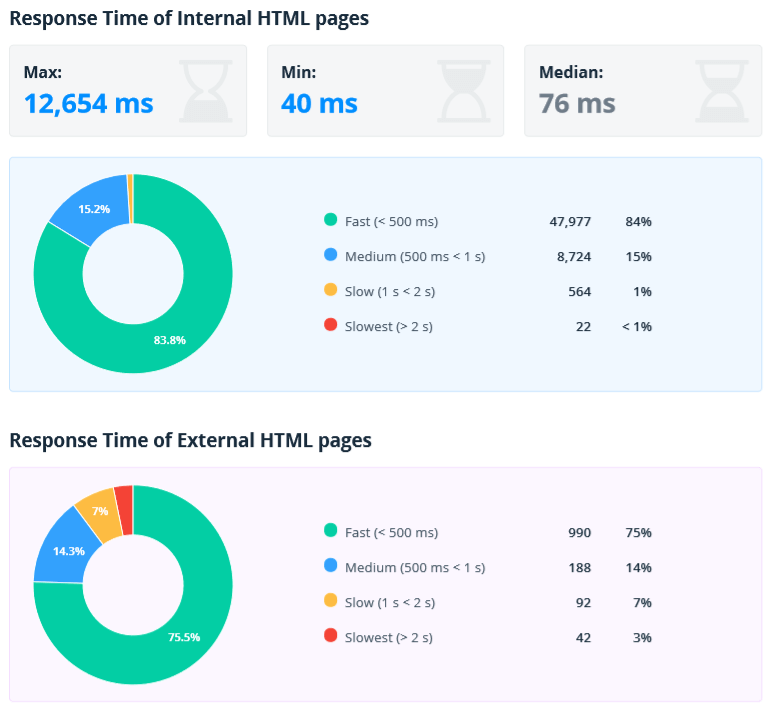
Also, internal and external documents are shown separately. First of all, you need to pay attention to internal ones and do everything in your power to make them load quickly. But do not forget about external. If the site refers to an external document that takes a long time to open, it will worsen the user experience. And if external resources (JS, CSS, images, fonts) are loaded to the HTML page, then their load speed directly affects the load speed of an entire page.
Additional maximum, minimum, and median values are displayed for internal documents. This will help to quickly assess the variation in load speed. If the server is stable, then the spread should be small.
2.2.8. HTTP/HTTPS Protocols
This section contains document protocols: secure (HTTPS), and insecure (HTTP). If websites with HTTPS protocol have HTML pages, images, or resources with HTTP protocol, it may cause the 'Mixed content' issue. In this case users may see a corresponding warning in browser and search engines will consider the site insecure.

2.2.9. Content Optimization
This section analyzes only the internal compliant pages, because the content-related SEO issues should be fixed firstSEO auditotentially drive traffic.
We've focused on data that can be a signal for wasted optimization opportunities that can negatively affect ranking and website visibility in SERP.
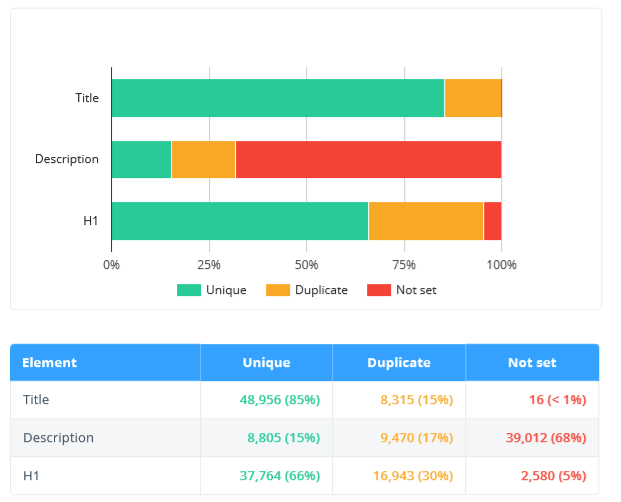
- Duplicate and Missing Title, Description, H1 → for both users and search engines, issues with these parameters can indicate poor quality of the site.
- The number of characters and words on a page → often pages with more text have higher rankings because they cover the topic better.
- Image size → pictures with a big size load slower and reduce the page load speed. If a page loads for a long time (especially on mobile devices, where the Internet speed is lower), the user may find the site low-quality and leave it.
2.2.10. Issues
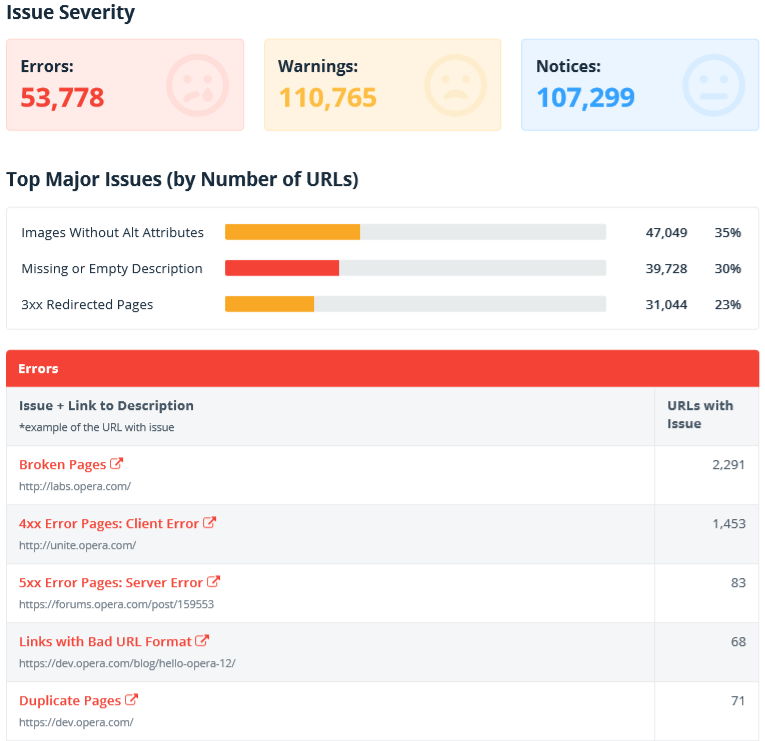
This section contains reports on issues detected during crawling:
- the number of URLs with issues of different severity
- top major issues that may have the most noticeable effect when fixed
- the issue list with links to documentation and examples of the URLs they've been detected on
2.2.11. Terms
At the end of the audit you'll find the meaning of some important terms.
- Crawled URLs – documents that have any data in the 'All Results' table. Note that segmentation affects this parameter.
- Major issues – errors and warnings only.
- Internal URLs – documents with the same domain name as the initial URL or the first URL in a list: usually, they are the internal pages of the analyzed website. They are highlighted in blue in all sections of the report.
- External URLs – documents with the domain name different from the initial URL: you have to enable the 'Crawl external links' option on the 'General' tab of crawling settings to crawl them. They are highlighted in violet in all sections of the report.
- Resources – documents that are not HTML nor images and return a 2xx status code. They include JavaScript, CSS, PDF, XML, JSON, PlainText, GZIP, etc.
- Non-compliant – HTML documents returning not a 2xx status code or disallowed from crawling and indexing.
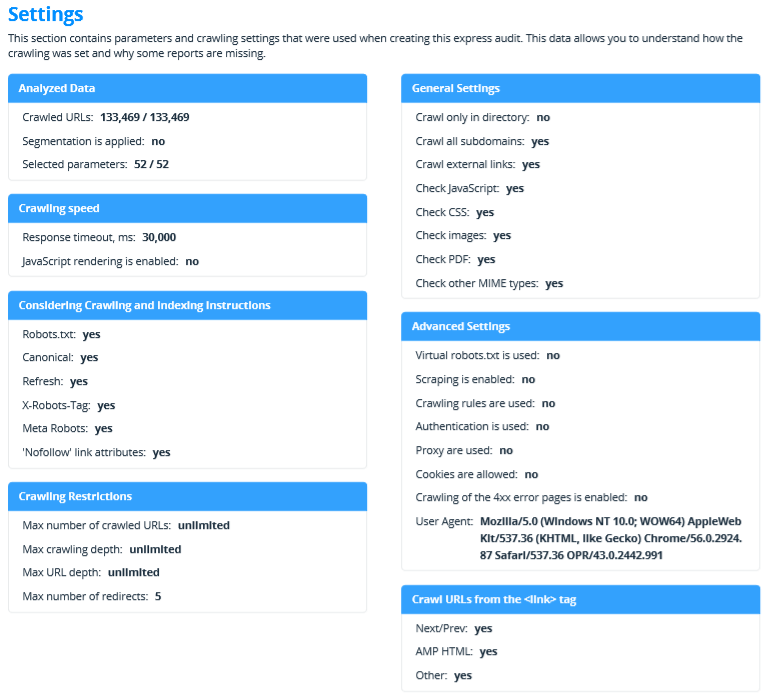
2.2.12. Settings
This section contains parameters and crawling settings that were used when creating this audit. We have thought about possible situations beforehand that's why we show this data. It allows you to understand how the crawling was set and why some reports are missing.
Now it's up to you → try to generate a report on already saved projects, or run crawling to collect data and explore all details in the report ;)
3. Enhanced Issue Description
During crawling Netpeak Spider shows detected, undetected, and disabled issues on a website. They can be errors, warnings, and notices, and are indicated by the corresponding color.
If you click on any issue on the 'Issues' tab in a sidebar, a detailed description appears in the 'Information' panel at the bottom of the interface.
We have significantly expanded the description of each issue with the following points:
- the threat the issue can cause
- how to fix it
- useful links for deeper understanding of the problem
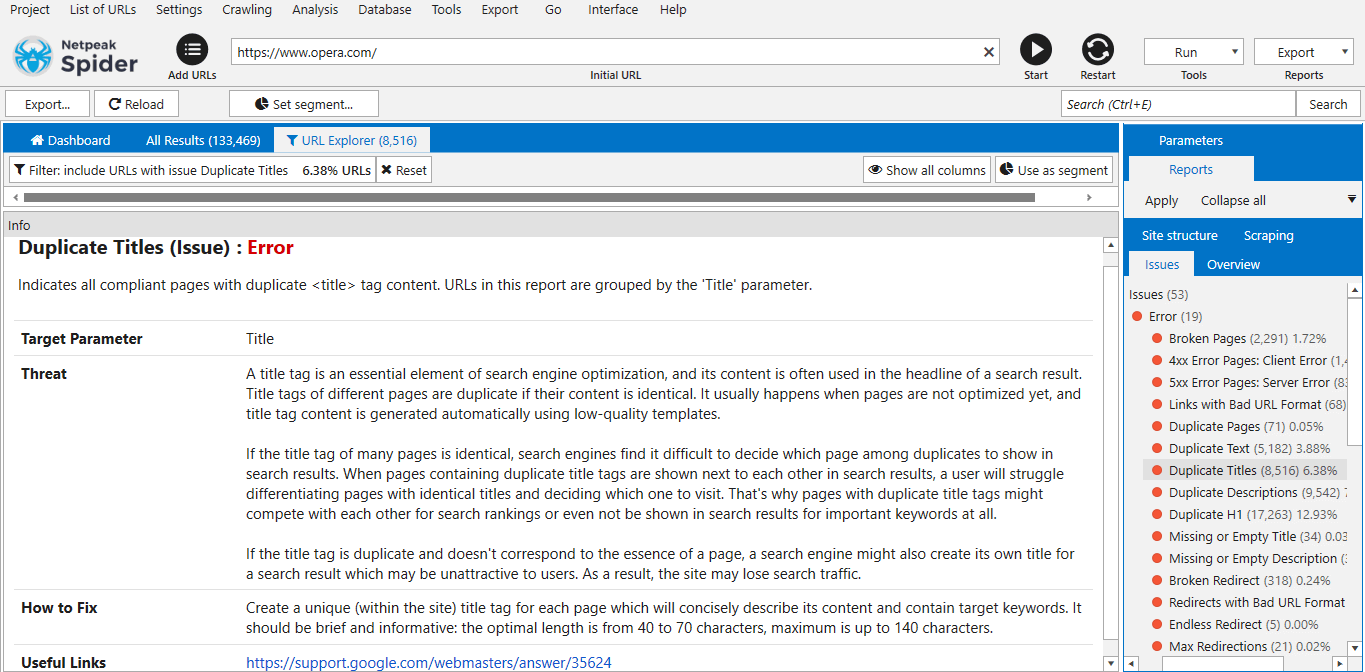
Now, if you have any questions about issues, look at the 'Information' panel. We tried to answer most of them there. By the way, try changing the height of this panel → it will be more convenient to read detailed issue descriptions, where we've got carried away ;)
3.1. Export of the Report with Enhanced Issue Descriptions
We will surprise you with another useful feature that will allow you to apply enhanced issue descriptions directly to your work.
Now you can export a combination from a brief summary of all found issues and their enhanced descriptions. This will allow you to quickly set a technical task and fix them.

This report is called 'Issue overview + descriptions'. You can find it in the 'Export' → 'Issue Reports' tab, and in the following bulk exports:
- 'Main reports set'
- 'All issues'
- 'All available reports (main + XL)'
3.2. Issues Changes: Issue Severity, Names, Sorting
We also made a 'spring cleaning' among our parameters and issues. Here you'll find out what has changed.
3.2.1. Changes in Issue Severity
Warnings → errors:
- Duplicate H1
- Canonical Chain
- 5xx Error Pages: Server Error
- Bad AMP HTML Format
Errors → notices:
- Bad Base Tag Format
- Max URL Length
Warnings → notices:
- Multiple H1
3.2.2. Changes in Issues' and Parameters' Names
- Broken Links → Broken Pages (because you'll see pages in this report and you can look at links in the separate interface or even export them in the 'Export' menu),
- Duplicate Canonicals → Identical Canonical URLs.
3.2.3. Changes in the Logic of Determining Issues and Parameters
- 'Bad Base Tag Format' issue: previously, the relative URL in this tag was considered an issue. Now the issue is determined if the URL with the wrong format is specified in the href attribute.
- 'Canonical URL' parameter: now only the absolute URL is taken into account in the canonical instruction, as required by Google. If relative is specified → the value in the table will be (NULL).
3.2.4. Changes in the Issues Sorting
We improved the sorting of issues by moving the most significant and common ones to the prominent places.
4. Other Changes
We always strive to implement as many new useful features for our users as possible. To develop the JavaScript rendering function, we used the .NET 4.5.2 framework. Therefore, the new Netpeak Spider can only work on the Windows operating system not lower than 7 SP1 version, since older versions of the OS do not support this framework.
Let's check out a brief description of other changes in Netpeak Spider 3.2:
- We've changed the logic of determining the internal addresses for a URL list. To determine whether a link is external or internal, Netpeak Spider considers the 'Initial URL'. If the domain matches, the link is considered internal, if it doesn't match, then it's external. Previously, when crawling a list of URLs without an initial one, all links were considered external. Now they are compared with each other: if all the hosts of the addresses belong to the same domain, the URL will go to the internal links report; if at least one URL belongs to another domain, all addresses will be considered external. These changes affect results in reports.
- We've improved the 'Default' parameter template. This was necessary for proper use of the new feature exporting SEO audit in PDF.
- The results sorting in the table is saved only for a single session (until the program is restarted). In a new session, the sorting will be standard by the URLs' sequence number. We did it to make users' experience with results more clear and convenient.
- During crawling you can see the new 'JavaScript rendering' and 'Ajax Timeout' settings on the dashboard.
- We've optimized the work with robots.txt. Now, when you start / continue crawling, only one request for each host is sent to robots.txt (previously, if you set many threads several requests could be sent for the same robots.txt).
- The project's and export files' name is created based on the initial URL of the crawling. Now, when saving a project or report, the host name from the initial URL (if a certain site is crawled) or the first URL in the table (if a custom URL list is checked) will be indicated in the file name.
- We've improved alerts in the lower right corner: to make it easier to click on it and go to the file location folder, a successful table or report export is now displayed within 60 seconds (it used to be 7 seconds). Alerts about the end of crawling and others will no longer disturb you from other programs. Earlier, when they occurred, Netpeak Spider window became active.
- Setting 'Allow cookies' is enabled by default on the advanced settings tab. This is one of the frequent reasons why the site is not crawled or is being crawled incorrectly, so we have enabled cookies by default. Remember that this setting does not affect the rendering in browser: when crawling in Chromium is enabled, cookies are always taken into account.
- We've changed a lot of texts within the program to explain more nuances and tips on how a tool works. If you notice any inaccuracies, please contact our support team.
5. In a Nutshell
In Netpeak Spider 3.2, we have implemented long-awaited features. Now you can use our program more comprehensively with the following changes:
- JavaScript rendering;
- SEO audit in PDF with the following reports: 'Overview', 'URL Structure', 'Crawling and Indexing', 'Status Codes', 'Click and URL Depth', 'Load Speed', 'HTTP/HTTPS Protocols', 'Content Optimization', and 'Issues';
- Enhanced issue description: the threat the issue can cause, how to fix it, useful links for deeper understading of the problem;
- New 'Issue overview + descriptions' export;
- And 50+ other improvements


