Netpeak Spider 3.2: рендеринг JavaScript и аудит в PDF
Обновления

Друзья, из этого поста вы узнаете, что мы приготовили для вас в рамках долгожданного релиза Netpeak Spider 3.2 :) Нам прямо не терпится поделиться подробностями, но для начала — небольшой видеотизер.
А теперь приступим к деталям. Если вы хотите перейти к конкретному разделу, поберегите ваши колёсики на мышках и воспользуйтесь содержанием:
- 1. Рендеринг JavaScript
- 2. Технический SEO-аудит (PDF)
- 3. Расширенное описание ошибок
- 4. Остальные изменения
- 5. Коротко о главном
Смотрите детальный видеообзор новой версии в посте «Netpeak Spider 3.2: пробуем на практике последние обновления».
1. Рендеринг JavaScript
Прежде чем рассказать об особенностях этой долгожданной функции в нашем краулере, давайте вспомним, как Google индексирует контент, который добавляется на страницу скриптами.
Не терпится скорее попробовать рендеринг JavaScript? Скрыть подробности и перейти к особенностям настройки функции в Netpeak Spider.
1.1. Что такое рендеринг JavaScript
Выполнение или рендеринг JavaScript — это формирование окончательного слепка HTML-кода страницы, учитывая изменения, внесённые JS-скриптами.
Изначально поисковые роботы сканировали и индексировали только контент, который передавался в статическом исходном коде HTML. Однако сейчас при разработке сайтов всё чаще используют JS-фреймворки, когда контент частично или полностью добавляется с помощью JavaScript. Вот наглядный пример HTML-кода до и после выполнения JavaScript с нашего же сайта:
- отображение цены Netpeak Spider на одной из наших страниц — до выполнения JavaScript:
- отображение этого же блока после выполнения JS-скриптов:
Google пришлось подстроиться под развитие веб-технологий, и сейчас он уже обрабатывает и рендерит контент, который добавляется на страницу с помощью JavaScript. Их сервис веб-рендеринга (WRS) основан на браузере Chrome.
Поисковый робот Google сканирует сайты в две стадии:
- Во время первой он (как раньше) работает только с HTML: запрашивает исходный код, сканирует и индексирует контент, а также добавляет найденные ссылки в очередь сканирования.
- На второй стадии выполняется рендеринг (отображение) контента. На этом этапе ему необходимы ресурсы для выполнения JavaScript. Потому если ресурсов сканирования недостаточно, между первой и второй стадией возможен временной интервал.
Разделение индексации и рендеринга позволяет Google максимально быстро проиндексировать контент, который доступен без JavaScript, а потом вернуться и добавить контент, для которого он требуется.
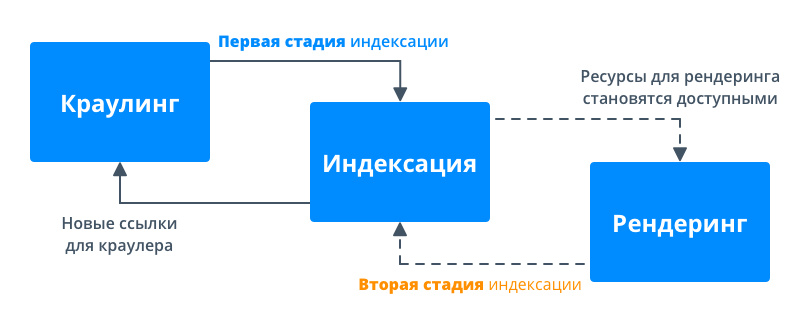
Если на первом этапе Google не получил важный контент страницы, то добавление этого контента в индекс будет происходить на втором этапе, где возможны задержки.
Есть два способа передачи контента, которые используют современные веб-приложения:
- Рендеринг на стороне клиента (client-side rendering, CSR) — поисковая система получает пустую HTML-страницу (практически без контента), а основной контент добавляется на страницу с помощью скриптов JavaScript. В таком случае необходимо ждать второй стадии сканирования, и контент может попасть в индекс с задержкой.
- Рендеринг на стороне сервера (server-side rendering, SSR) — в этом случае поисковая система получает слепок HTML уже со всем важным контентом страницы. Потому он добавляется в индекс на первой стадии сканирования, и можно не переживать из-за возможных задержек второй стадии.
Продвинутый SEO-специалист должен разбираться в этих аспектах. По сути JavaScript SEO — это обеспечение того, что контент, который добавляется на страницу с помощью JavaScript, успешно обрабатывается поисковым роботом, попадает в индекс и учитывается в ранжировании.
Дальше мы объясним, зачем обработка JavaScript нужна в современных SEO-инструментах, и как её использовать.
1.2. Зачем рендеринг JavaScript нужен в краулере
Если вы попытаетесь просканировать сайт, на котором используется CSR, традиционным способом (анализируя только HTML), краулер не сможет обнаружить данные, которые добавляются с помощью JavaScript (ссылки, описания, изображения и т.д.), а следовательно и найти ошибки на таком сайте.
Поэтому, чтобы обработать подобные сайты как Googlebot, краулеру нужен браузер для выполнения JavaScript → чтобы загрузить весь контент с учётом изменений, внесённых скриптами, и только потом анализировать его.
1.3. Как настроить рендеринг JavaScript в Netpeak Spider
В Netpeak Spider рендеринг JavaScript реализован с помощью встроенного браузера Chromium, на основе которого создан самый популярный в мире браузер Chrome. Мы используем одну из последних версий Chromium, что делает сканирование в Netpeak Spider максимально продвинутым и приближённым к поведению Googlebot, но не идентичным, так как Google использует старую версию браузера Chrome 41, которая не поддерживает некоторые современные особенности JavaScript.
Чтобы начать сканирование страниц с выполнением скриптов JS, зайдите в настройки → вкладка «Основные» → отметьте галочкой пункт «Включить рендеринг JavaScript и установить AJAX timeout, c»:
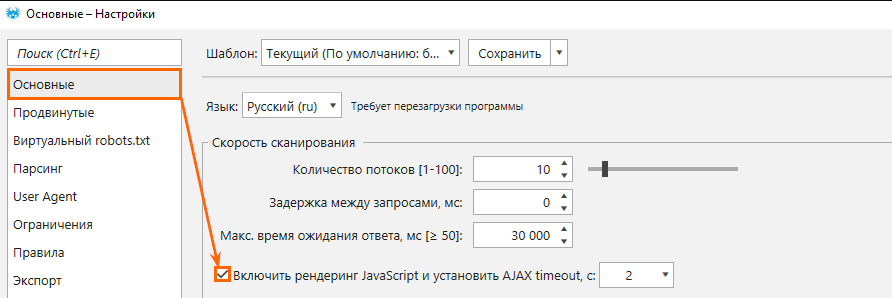
Настройка «AJAX timeout» устанавливает время ожидания выполнения JavaScript после загрузки страницы и файлов ресурсов (JS / CSS). Это нужно, чтобы все скрипты успели отработать.
Обратите внимание: чем больше AJAX timeout, тем дольше будет происходить сканирование. В большинстве случаев значения по умолчанию (2 секунды) будет достаточно для выполнения JavaScript, однако вы можете настраивать его самостоятельно, если на анализируемом сайте есть AJAX-запросы, которые выполняются дольше. Также не советуем занижать это значение, так как код может не успеть полностью обработаться.
Давайте рассмотрим пример сканирования сайта, где контент полностью выводится с помощью JavaScript. В этом случае вы не сможете просканировать такой сайт без включённого рендеринга JS.
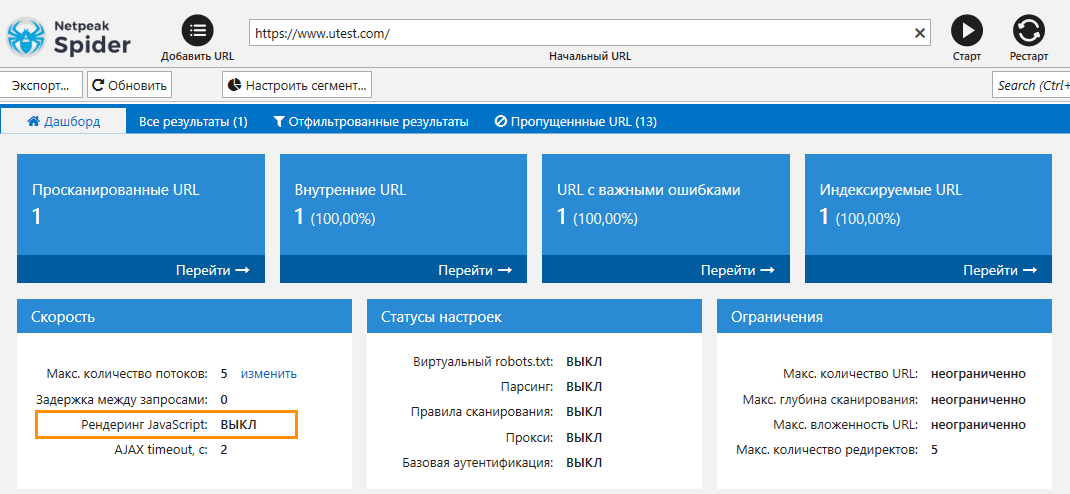
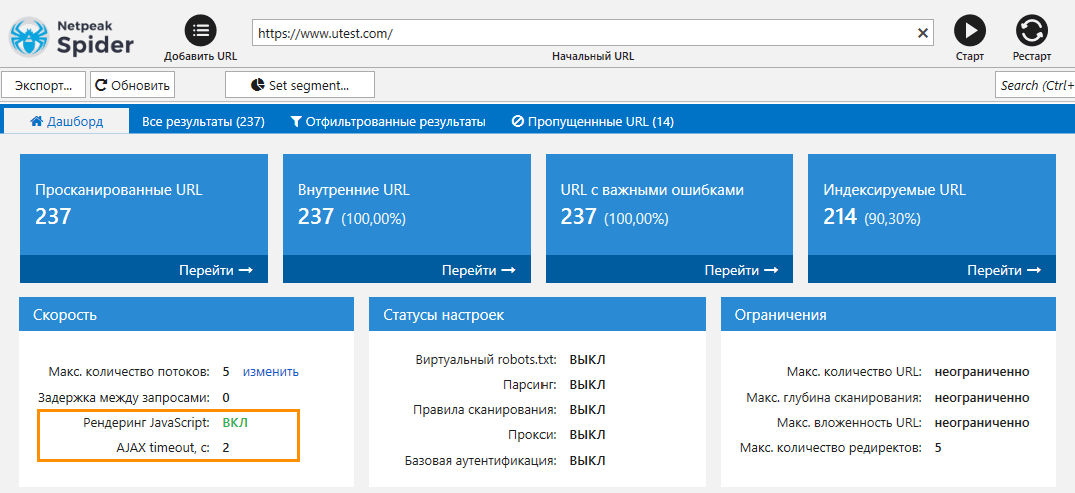
1.4. Особенности JS-рендеринга в Netpeak Spider
Netpeak Spider использует рендеринг с выполнением JS-скриптов только для HTML-страниц с кодом ответа 200 OK. Это ускоряет работу программы и позволяет не тратить ресурсы на страницы, для обработки которых не нужно использовать браузер.
Если вы хотите просканировать сайт с включённым рендерингом JavaScript, помните, что это увеличивает время сканирования. Когда краулер работает без рендеринга, происходит всего один запрос для получения HTML-кода страницы. Когда вы включаете рендеринг, дополнительно происходит запрос в Chromium для получения HTML-кода, загрузка JS и CSS-файлов и само выполнение JavaScript за время, указанное в настройке AJAX timeout. Соответственно, сканирование займёт больше времени.
Совет: мы рекомендуем включать рендеринг JavaScript, только если вам необходимо просканировать сайт с CSR, и не советуем включать его для сканирования всех сайтов по умолчанию (особенно при сканировании сайтов с тысячами и более страниц, что может вызвать большую нагрузку на компьютер).
Также при рендеринге JavaScript Netpeak Spider:
- использует User Agent, выбранный пользователем в настройках сканирования;
- поддерживает базовую аутентификацию;
- поддерживает список прокси;
- блокирует запросы к аналитическим сервисам (Google Analytics, Яндекс.Метрика и т.д.), чтобы не искажать аналитику сайта;
- учитывает cookies независимо от настроек, выставленных на вкладке «Продвинутые»;
- не загружает iframe и изображения;
- ограничен 25 потоками. Таким образом, если вы выставите в настройках сканирования 100 потоков, Netpeak Spider будет одновременно сканировать 100 документов обычным способом, однако рендерить будет только 25 доступных HTML-страниц.
А теперь давайте перейдём ко второй новой функции нашего краулера. Подозреваем, что визуалам она особенно понравится ;)
2. Технический SEO-аудит (PDF)
В новой версии Netpeak Spider мы добавили возможность в один клик экспортировать отчёт в формате PDF с SEO-аудитом на основании результатов проведённого сканирования.
Благодаря этой функции вы сможете получить в Netpeak Spider лучшее от «двух миров»: глубину анализа и кастомизацию десктопного инструмента и визуализацию результатов на уровне самых продвинутых онлайн-продуктов.
Отчёт доступен в меню «Экспорт»:
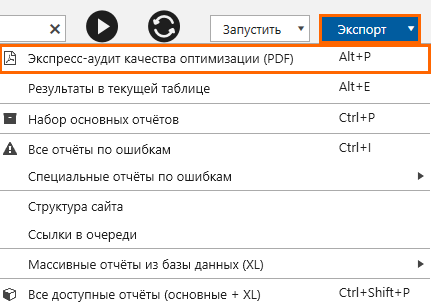
PDF — универсальный формат, который подходит для печати и без труда откроется почти на любом устройстве.
Мы поставили себе цель добиться максимально качественной визуализации данных, добавив в логику программы совершенно новые показатели, а также учли такие нюансы:
- В отчёте будут показаны только те данные, которые были найдены на сайте во время сканирования. Разделы и диаграммы, для которых нет данных, не выводятся — а значит, вы не увидите пустые листы и таблицы, просто потому что во время сканирования не была найдена та или иная ошибка / параметр.
- В отчёте отображаются показательные примеры для анализа данных, а не полный список соответствующих URL. А значит при анализе средних и крупных сайтов не придётся пролистывать десятки страниц отчёта с сотнями трудночитаемых ссылок.
2.1. Кому это будет полезно?
PDF-отчёты пригодятся в первую очередь SEO-специалистам. Это улучшенная и расширенная (на 20+ страниц) версия дашборда программы, которой удобно пользоваться для оценки качества оптимизации проекта или списка URL. Тут наглядно показана ключевая информация для аудита сайта — достаточно дополнить её собственными рекомендациями и можно отправлять клиенту или же коллегам на внедрение.
Если же вы специалист по продажам, то в отчёте есть краткая сводка о состоянии сайта, с помощью которой вы сможете быстро оценить проект и обсудить фронт работ с клиентом.
2.2. Структура и особенности PDF-отчётов
Отчёт строится по данным из таблицы «Все результаты», на которые непосредственно влияют настройки, параметры и сегментация (попробуйте протестировать различные виды отчётов, меняя их).
Каждый раздел отчёта посвящён определённому аспекту оптимизации. Давайте пройдёмся подробнее по каждому из них.
2.2.1. Заглавная страница + содержание
Если во время анализа в Netpeak Spider использовался режим сканирования сайта, то на первой странице будет показан скриншот начальной страницы и домен сканируемого ресурса, чтобы было удобно визуально различить отчёты для разных сайтов.

Если же был просканирован просто список URL без начальной страницы, то вместо скриншота будет показано специальное изображение:
На каждый раздел из содержания стоит якорная ссылка, чтобы было удобно перемещаться по документу.
2.2.2. Сводка
В этом разделе собрана краткая сводка по результатам сканирования. Это самый ёмкий отчёт: он позволяет быстро понять, какие данные анализируются, и какие ошибки были найдены.
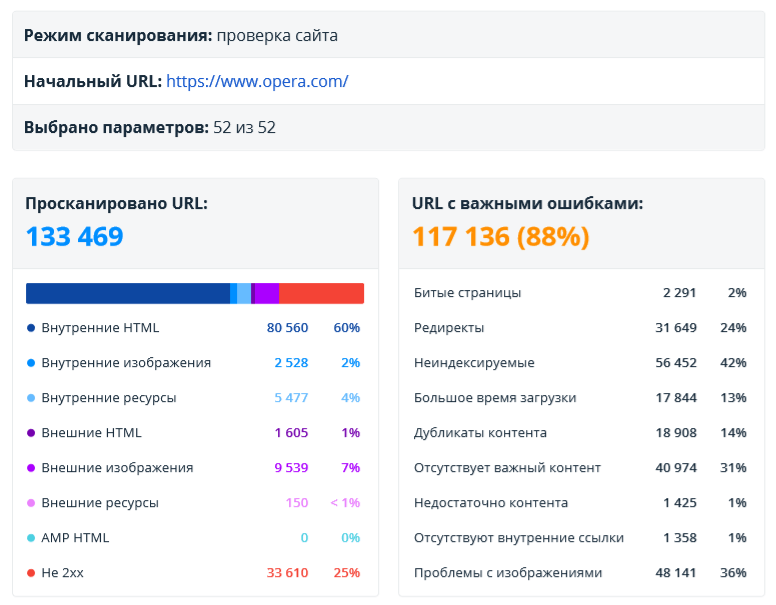
Здесь отображаются такие данные:
- Режим сканирования → проверка сайта или проверка списка URL.
- Начальный URL сканирования. Если был просканирован список URL, то здесь отобразится первый URL из списка.
- Количество параметров, которые были выбраны во время генерации отчёта.
- Количество и типы URL, по которым построен текущий отчёт.
- Количество URL с важными ошибками (высокой и средней критичности).
- Основные типы ошибок → свежая группировка для ещё более быстрого понимания результатов аудита.
- Тип контента → отдельные диаграммы для внешних и внутренних страниц.
- Основные хосты.
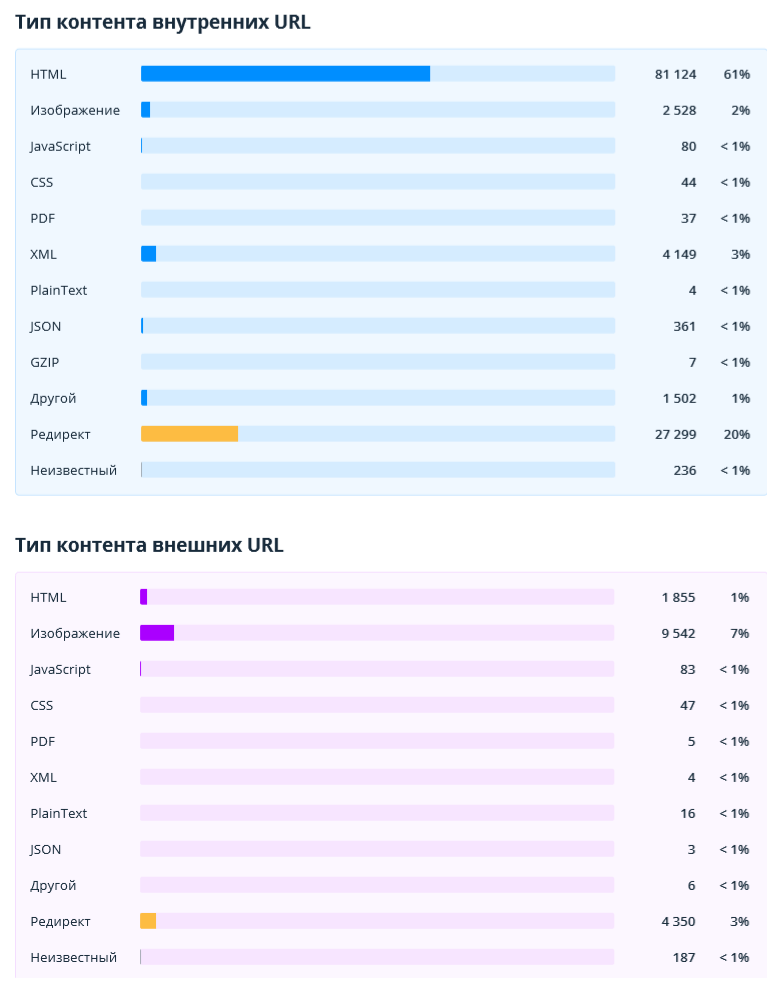
2.2.2.1. Тип контента (внутренних и внешних URL)
Эти отчёты помогают оценить и сравнить количество разных типов документов, которые были найдены во время сканирования. Отдельно показаны диаграммы для внутренних и внешних URL (здесь и в остальных разделах отчёта они будут отмечены синим и фиолетовым цветом соответственно).
2.2.2.2. Основные хосты
В этой таблице отображены основные хосты, которые анализируются в данном аудите — может быть полезно, если на вашем сайте много хостов или при проверке списка URL.
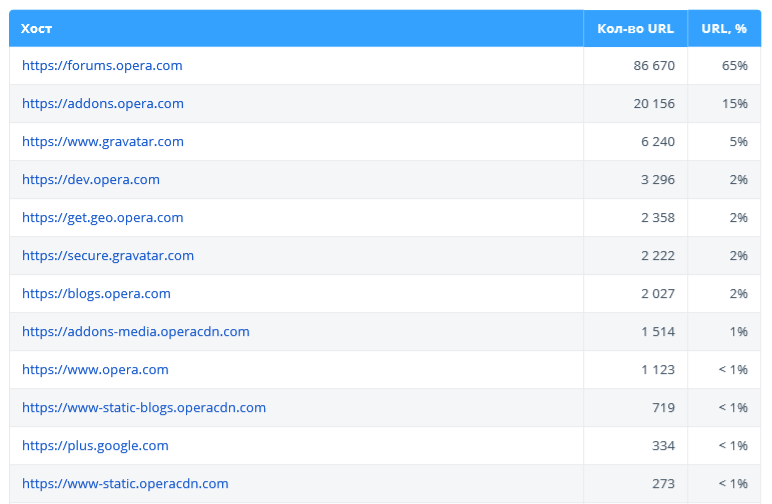
2.2.3. Структура URL
Этот отчёт поможет визуально оценить структуру просканированных URL. Здесь показаны наиболее популярные хосты и сегменты второго уровня (например, site.com/category/).
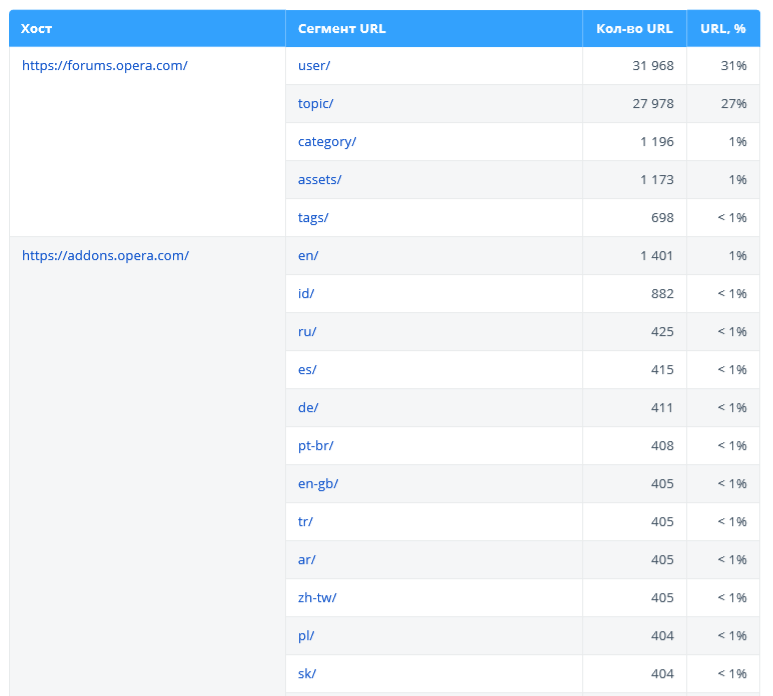
Обратите внимание: в таблице представлены максимум 40 сегментов, а полную структуру сайта можно получить в Netpeak Spider в отчёте «Структура сайта». Также из отчёта по структуре исключены URL с редиректами, потому что они не являются конечными адресами страниц, и нет смысла анализировать их сегменты.
Ещё мы добавили в отчёт данные по [документам в корне] — количество документов, которые находятся в корне сайта, то есть не содержат сегменты.
2.2.4. Коды ответов сервера
В данном разделе показаны коды ответов сервера внутренних и внешних URL.
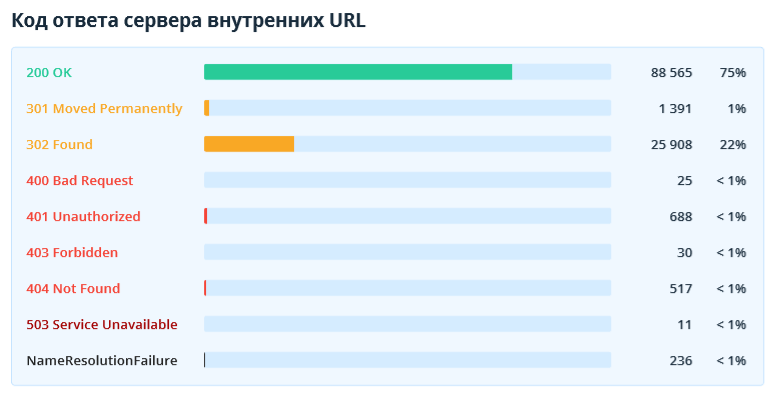
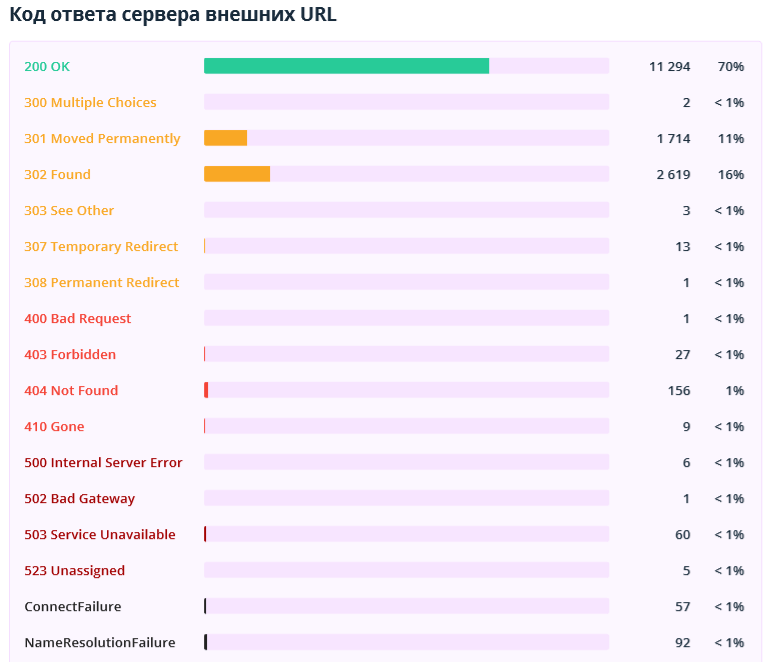
Обратите здесь внимание на недоступные документы, редиректы и страницы, которые возвращают код ответа сервера 4xx и выше. Чтобы получить список ссылок на них, экспортируйте отчёты «Битые ссылки» и «Редиректы: входящие ссылки и конечные URL» в Netpeak Spider.
2.2.5. Сканирование и индексация
В разделе показаны данные об инструкциях и серверных настройках, которые влияют на сканирование и индексацию контента (здесь анализируются только внутренние URL). Напомним, что неиндексируемые документы зачастую не приносят трафик из поисковых систем и даже, напротив, расходуют краулинговый бюджет.
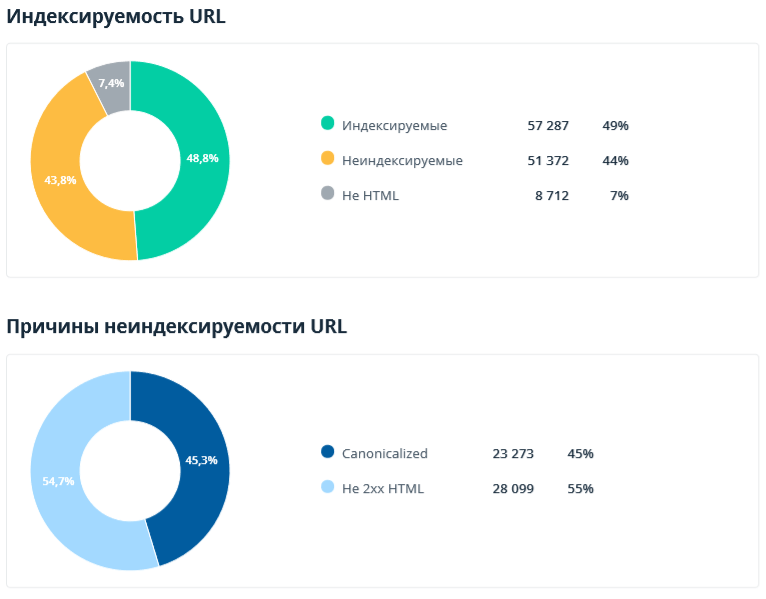
Возможно, диаграммы по индексируемости и причинам неиндексируемости URL вам уже знакомы (они также доступны на дашборде Netpeak Spider). А сводки по значениям Meta Robots и X-Robots-Tag, а также по использованию canonical — это новые отчёты, доступные пока что только в аудите.
2.2.6. Глубина и вложенность URL
В данном разделе показаны глубина (количество кликов от начальной сканируемой страницы до текущей) и вложенность URL (количество сегментов в адресе документа).
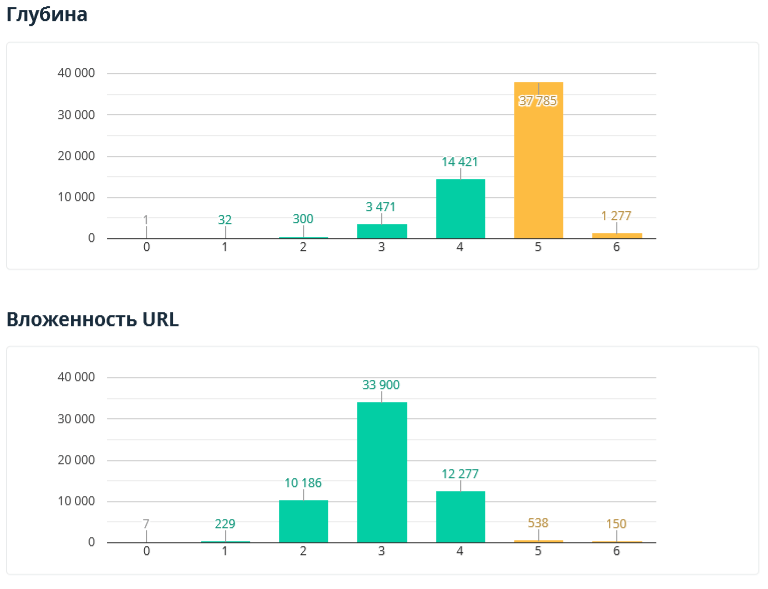
Обратите внимание: в отчёте анализируются только внутренние индексируемые HTML-страницы, а значение глубины «0» присваивается URL, с которого начиналось сканирование или которые были добавлены списком.
Подробнее о возможных проблемах:
- Страницы с глубиной больше «4» потенциально могут хуже индексироваться и, как следствие, не приносить органический трафик.
- URL страниц с вложенностью больше «4» и / или слишком длинным адресом могут сложнее восприниматься посетителями сайта.
2.2.7. Скорость загрузки
Этот отчёт помогает оценить скорость ответа сервера внутренних и внешних документов. Данный параметр является важным фактором ранжирования — быстрые сайты зачастую получают больше трафика, меньше отказов и показывают более высокие результаты по конверсии. В отчёте анализируются только URL с 2xx кодом ответа сервера.
Чаще всего для генерации и обработки HTML-страниц сервер тратит больше времени, а статические файлы обычно кэшируются и возвращаются быстрее. Потому мы разделили отчёты для HTML и не HTML-страниц, чтобы анализировать страницы похожих типов.
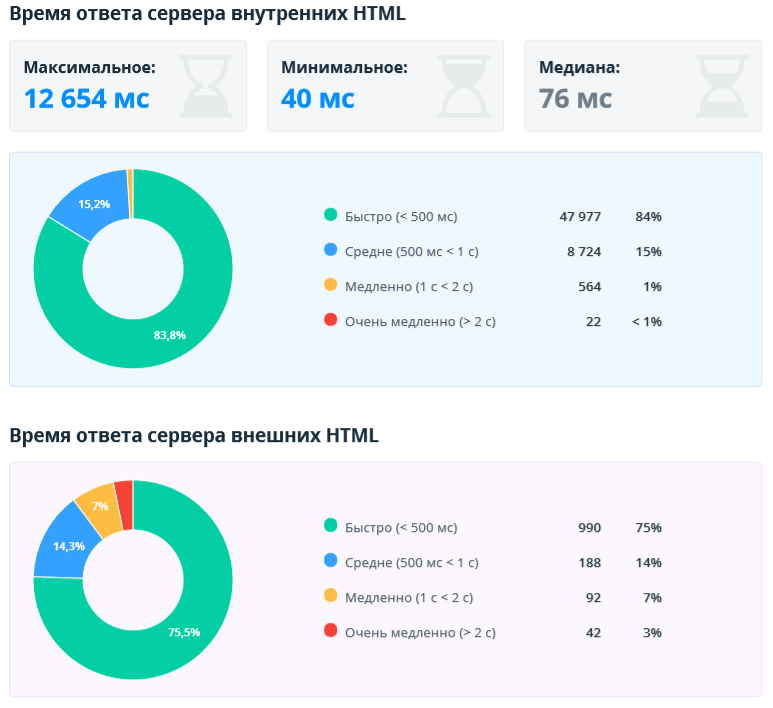
Также отдельно показаны внутренние и внешние документы. В первую очередь нужно обращать внимание на внутренние и сделать всё возможное, чтобы они загружались быстро. Но не стоит забывать и о внешних. Если сайт ссылается на внешний документ, который долго открывается, то это ухудшает пользовательский опыт. Если на HTML-страницу загружаются внешние ресурсы (JS, CSS, изображения, шрифты), то скорость их загрузки напрямую влияет на скорость загрузки всей страницы.
Для внутренних документов выводятся дополнительно максимальное, минимальное значение и медиана. Это помогает быстро оценить разброс по скорости загрузки. Если сервер работает стабильно, то разброс должен быть небольшим.
2.2.8. Протоколы HTTP/HTTPS
В данном разделе показаны протоколы документов: защищённый (HTTPS) и незащищённый (HTTP). Мы показываем этот отчёт, так как если на сайтах с HTTPS-протоколом есть HTML-страницы, изображения или ресурсы с HTTP-протоколом, это может привести к ошибке «Смешанное содержимое». В этом случае пользователи могут увидеть в браузере соответствующее предупреждение, а поисковые системы будут считать сайт небезопасным.
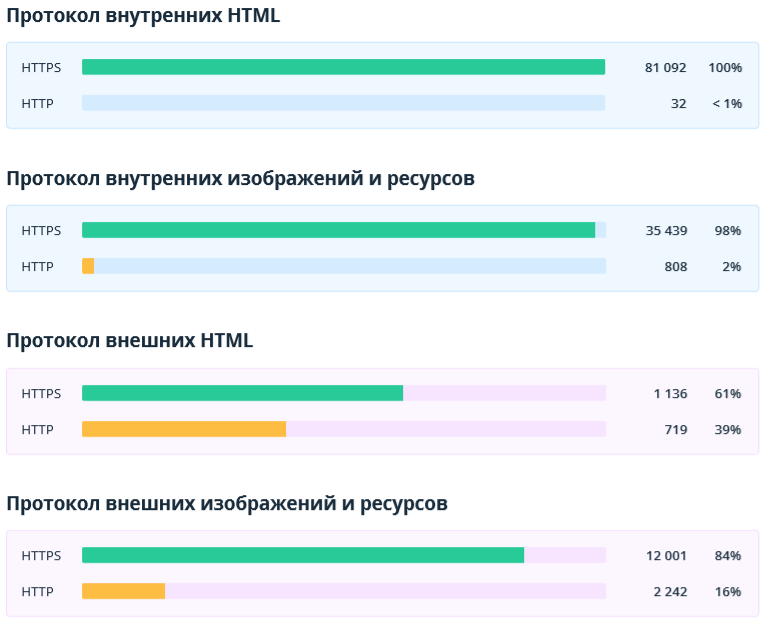
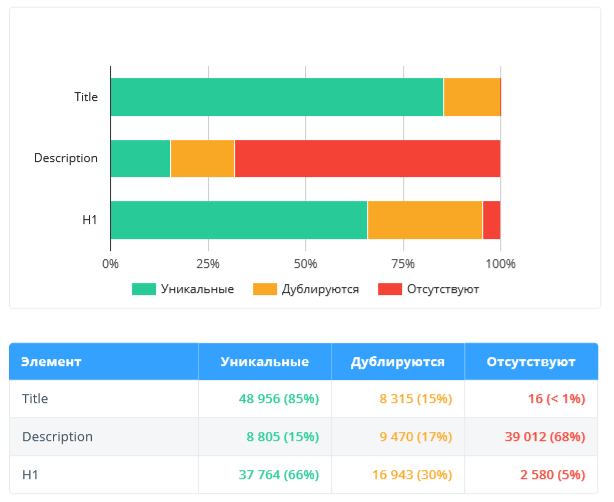
2.2.9. Оптимизация контента
В данном разделе анализируются только внутренние индексируемые страницы, потому что SEO-ошибки, связанные с контентом, необходимо устранять в первую очередь для внутренних страниц сайта, которые потенциально получают трафик.
Мы сосредоточились на данных, которые могут быть сигналом об упущенных возможностях оптимизации и негативно повлиять на ранжирование и отображение сайта в выдаче поисковых систем:
- Title, description, H1: уникальность, наличие на страницах, длина → как для пользователей, так и для поисковых систем ошибки в этих параметрах могут говорить о некачественности сайта.
- Количество символов и слов на странице → часто страницы с бóльшим количеством текста находятся выше в поиске, так как лучше раскрывают тему.
- Размер изображений → картинки с большим весом загружаются медленнее и тем самым снижают скорость загрузки страницы. Если же страница загружается долго (особенно на мобильных устройствах, где скорость интернета ниже), пользователь может посчитать сайт некачественным и покинуть его.
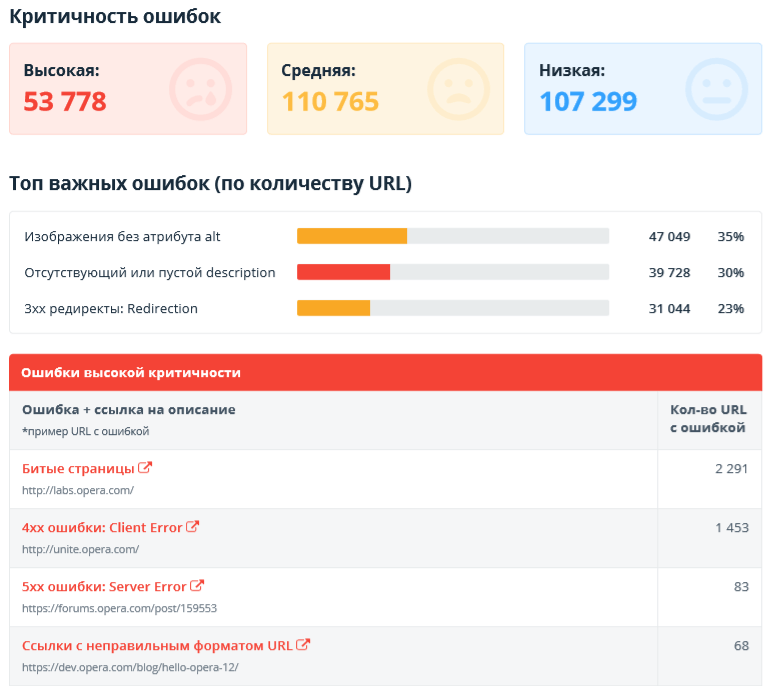
2.2.10. Ошибки
В этом разделе показаны отчёты об ошибках, обнаруженных во время сканирования:
- Количество URL с ошибками различной степени критичности.
- Топ самых важных ошибок, исправление которых может дать наиболее ощутимый результат при продвижении.
- Cписок самих ошибок со ссылками на документацию и примерами URL, где они были обнаружены.
2.2.11. Термины
В конце аудита описано значение некоторых важных терминов.
- Просканированные URL — документы, по которым есть хотя бы какие-то данные в таблице со всеми результатами. Обратите внимание, что применение сегментации влияет на этот показатель.
- Важные ошибки — ошибки только высокой и средней критичности.
- Внутренние URL — документы с таким же доменом, как у начального URL или у первого URL в списке: обычно это внутренние страницы сканируемого сайта. Во всех разделах они отмечены синим цветом.
- Внешние URL — документы с адресом, не содержащим домен начального URL: чтобы включить их анализ, выберите «Сканировать внешние ссылки» на вкладке «Основные» настроек сканирования. Во всех разделах они отмечены фиолетовым цветом.
- Ресурсы — документы, которые не являются HTML или изображениями и возвращают 2xx код ответа сервера. В их числе: файлы JavaScript, CSS, PDF, XML, JSON, PlainText, GZIP и другие.
- Неиндексируемые — HTML-документы с отличным от 2xx кодом ответа сервера или закрытые от сканирования и индексации.
2.2.12. Настройки
В этом разделе показаны параметры и настройки сканирования, которые использовались при создании аудита. Мы заранее продумали возможные ситуации и вывели информацию, которая позволит определить, каким образом происходило сканирование, и почему не отображаются некоторые отчёты.

А теперь дело за вами → поскорее попробуйте сгенерировать отчёт по уже сохранённым проектам или же запускайте сканирование, чтобы собрать данные и рассмотреть отчёт во всех деталях ;)
3. Расширенное описание ошибок
Во время сканирования Netpeak Spider показывает обнаруженные, а также необнаруженные и отключённые ошибки на сайте. Они могут быть высокой, средней и низкой критичности, что отмечено соответствующим цветом.
Если вы нажмёте на любую ошибку на боковой панели на вкладке «Ошибки», то в нижней части интерфейса на панели «Информация» появится её подробное описание.
Мы существенно расширили описание каждой ошибки пунктами:
- чем грозит эта ошибка,
- как её исправить,
- подборкой полезных ссылок на материалы, которые помогут глубже разобраться в проблеме.
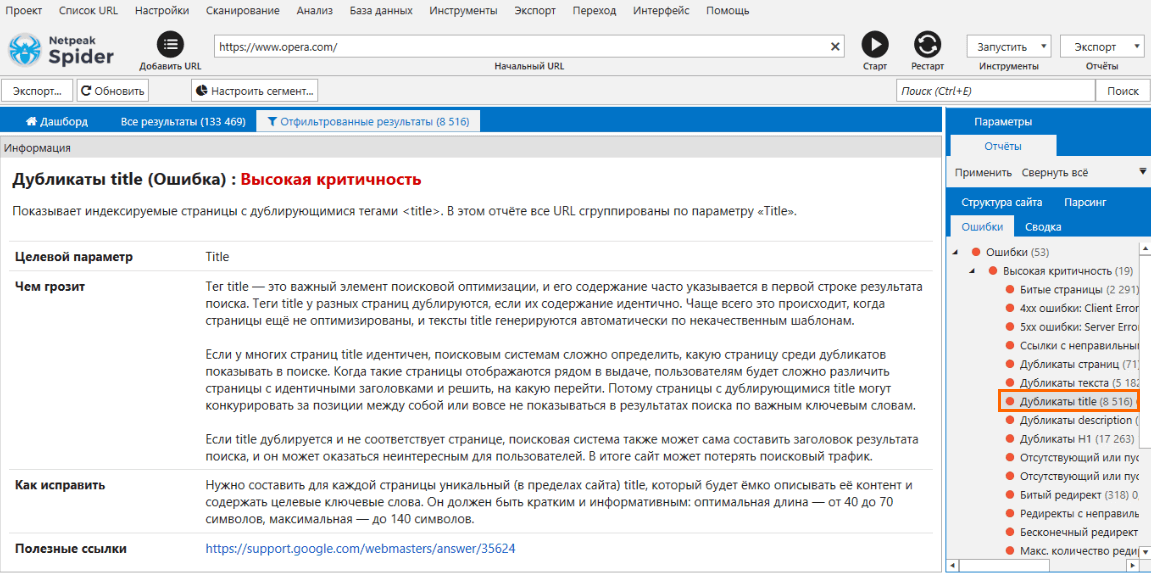
Теперь при возникновении каких-либо вопросов об ошибках обязательно загляните на панель «Информация» — мы постарались ответить на большую часть из них именно там. Кстати, попробуйте менять высоту этой панели → так будет удобнее читать детальные описания ошибок, где мы особенно увлеклись ;)
3.1. Экспорт отчёта с расширенными описаниями ошибок
Порадуем ещё одной полезной функцией, которая позволит применить наши расширенные описания ошибок непосредственно в вашей работе.
Теперь вы можете экспортировать комбинацию из краткой сводки по всем найденным ошибкам и расширенными описаниями к ним. Это позволит быстро поставить техническое задание на их устранение.

Этот отчёт называется «Сводка по ошибкам + описания». Он доступен в меню «Экспорт» → «Отчёты по ошибкам», а также в таких пакетных выгрузках:
- «Набор основных отчётов»,
- «Все ошибки»,
- «Все доступные отчёты (основные + XL)».
3.2. Изменения в ошибках: степень критичности, названия, сортировка
Мы также сделали «весеннюю уборку» среди наших параметров и ошибок — и вот что изменилось.
3.2.1. Изменения в степени критичности ошибок
Средняя → высокая:
- Дубликаты H1;
- Цепочка канонических URL;
- 5xx ошибки: Server Error;
- Неправильный формат AMP HTML.
Высокая → низкая:
- Неправильный формат тега Base;
- Макс. длина URL.
Средняя → низкая:
- Несколько заголовков H1.
3.2.2. Изменения в названиях ошибок и параметров
- Битые ссылки → Битые страницы (так как в этом отчёте вы видите всё-таки страницы, а ссылки можно просмотреть в отдельном интерфейсе или даже выгрузить через меню «Экспорт»);
- Дубликаты Canonical URL → Одинаковые канонические URL;
- Canonical, заблокированный в robots.txt → Канонический URL, заблокированный в robots.txt;
- Цепочка Canonical → Цепочка канонических URL;
- Canonical URL → Канонический URL.
3.2.3. Изменения в логике определения ошибок и параметров
- Ошибка «Неправильный формат тега Base»: раньше относительный URL в этом теге считался ошибкой. Теперь ошибка определяется, если в атрибуте href указан URL с неправильным форматом.
- Параметр «Канонический URL»: теперь учитывается только абсолютный URL в инструкции canonical, как требует этого Google. Если указан относительный → в таблице будет указано значение (NULL).
3.2.4. Изменения в сортировке ошибок
Мы улучшили сортировку ошибок, поставив на видные места наиболее важные и распространённые из них.
4. Остальные изменения
Мы всегда стремимся реализовать как можно больше новых полезных фич для наших пользователей. Для разработки функции выполнения JavaScript мы воспользовались версией фреймворка .NET 4.5.2. Потому новый Netpeak Spider может работать только на операционной системе Windows не ниже версии 7 SP1, так как более старые версии ОС не поддерживают этот фреймворк.
Кратко опишем другие изменения в Netpeak Spider 3.2:
- Изменена логика определения внутренних адресов для списка URL. Чтобы определить, является ли ссылка внешней или внутренней, Netpeak Spider учитывает «Начальный URL»: если домен совпадает, ссылка считается внутренней, если нет — внешней. Раньше при сканировании списка URL (и при отсутствии начального) все ссылки считались внешними. Теперь же они сравниваются друг с другом: если все хосты адресов принадлежат одному домену, URL пойдут в отчёт о внутренних ссылках; если хотя бы один URL относится к другому домену, все адреса будут считаться внешними. Эти изменения влияют на отображение результатов в отчётах.
- Улучшили шаблон параметров «По умолчанию». Это было необходимо для эффективной работы новой функции экспорта аудита в PDF.
- Сортировка результатов в таблице сохраняется только на период сессии, то есть до перезагрузки программы. В новой сессии сортировка будет стандартная, по порядковому номеру URL. Мы вынуждены были так сделать, чтобы не создавать нашим пользователям лишний повод запутаться в результатах анализа.
- На дашборде во время сканирования теперь выводятся новые настройки «Рендеринг JavaScript» и «Ajax Timeout».
- Оптимизирована работа с robots.txt. Теперь при запуске / продолжении сканирования запрос к robots.txt отправляется только один для каждого хоста (раньше могло отправляться несколько для одного и того же robots.txt, если было установлено много потоков).
- Название проекта и файлов экспорта формируется на основе начального URL сканирования. Теперь при сохранении проекта или отчёта в названии файла будет указываться хост из начального URL (если сканируется определённый сайт) или первого URL в таблице (если проверяется кастомный список URL).
- Были улучшены оповещения в правом нижнем углу: об успешном экспорте таблицы или отчёта теперь отображается в течение 60 секунд (раньше было 7 секунд), чтобы было удобнее кликнуть на него и перейти в папку расположения файла; об окончании сканирования и остальные теперь не перебивают фокус с других программ (раньше при их возникновении активным становилось окно Netpeak Spider).
- По умолчанию включена настройка «Разрешить cookies» на вкладке продвинутых настроек. Это является одной из частых причин, почему сайт не сканируется или сканируется некорректно, потому мы включили учёт cookies по умолчанию. Напомним, что эта настройка не влияет на рендеринг в браузере: при сканировании в Chromium cookies всегда учитываются.
- Произведено множество изменений текстов внутри программы, чтобы ещё лучше объяснить некоторые нюансы или подсказать, как работает определённый функционал. Если вы замечаете какие-то неточности, сообщайте в нашу службу поддержки.
Зарегистрируйтесь, если вы ещё не с нами
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд!
5. Коротко о главном
В версии Netpeak Spider 3.2 мы реализовали долгожданный функционал, который теперь позволит пользователям более широко использовать нашу программу, а именно:
- Рендеринг JavaScript;
- Технический SEO-аудит в PDF с отчётами: «Сводка», «Структура URL», «Сканирование и индексация», «Коды ответов сервера», «Глубина и вложенность URL», «Скорость загрузки», «Протоколы HTTP/HTTPS», «Оптимизация контента» и «Ошибки»;
- Расширенное описание ошибок: чем грозит, как исправить и список полезных ссылок;
- Экспорт нового отчёта «Сводка по ошибкам + описания»;
- А также 50+ других улучшений.
Друзья, спасибо за внимание! Надеемся, теперь ваша работа с Netpeak Spider станет ещё более эффективной ;) Мы были бы очень рады узнать о вашем фидбеке, так что не забывайте о возможности оставить комментарий с отзывом или предложением, а мы пока работаем над внедрением новых фич в Netpeak Checker!


