Netpeak Spider 3.0: New SEO Hope
Updates

Residents of the Milky Way Galaxy, today we launch to space a completely new version of our crawler → Netpeak Spider 3.0 with the code name ‘New SEO Hope’. It is the greatest update in the life of our program with more than 300 improvements: from super features to small usability upgrades. May the Force be with you to get the best out of this post!
Let’s go over the major changes and then check out a comparison of the crawling by technical specifications between Netpeak Spider and its three competitors. Use content to scroll to the episode you’d like to read:
- Crawling Giant Websites
- Hyper-Speed Crawling
- Advanced SEO Analytics
- More Details About Update
- Other Changes
- Comparison with Competitors
- In a Nutshell
- Surprise
You can crawl website, scrape, spot 80+ SEO issues, and work with other basic features in the free version of Netpeak Spider crawler that is not limited by the term of use and the number of analyzed URLs.
To get access to free Netpeak Spider, you just need to sign up, download, and launch the program 😉
Sign Up and Download Freemium Version of Netpeak Spider
P.S. Right after signup, you'll also have the opportunity to try all paid functionality and then compare all our plans and pick the most suitable for you.
I. Crawling Giant Websites
The new version of the program specializes on the analysis of large websites (we're talking about millions of pages). Now you can crawl such websites even without having a ‘sky-high’ computer configuration – thanks to the improved crawling management and optimal use of RAM.
1. Resume Crawling
Now you can stop crawling, save the project and then, if you want, resume website crawling:
- For example, the next day → you just need to open the project and click on the ‘Start’ button.
- On another computer → to do so, just transfer the entire folder with the project to the necessary computer (for example, if your computer reaches RAM limit and you want to continue crawling on more powerful one), open the project there and click again on the treasured ‘Start’ button.
2. Recrawling the List of URLs
Imagine that Netpeak Spider has detected Title duplicates on your website. You’ve exported the report and sent it to the developer with an explanation how to fix this issue.
Previously, to check if issue was fixed, you had to crawl the entire website or a list of URLs again. Now you can select an issue in sidebar and start recrawling pages only with this issue → and you will get a completely updated report of the entire website.
Of course, you can recrawl both single URL and URL list on ‘All Results’ or ‘URL Explorer’ tabs.
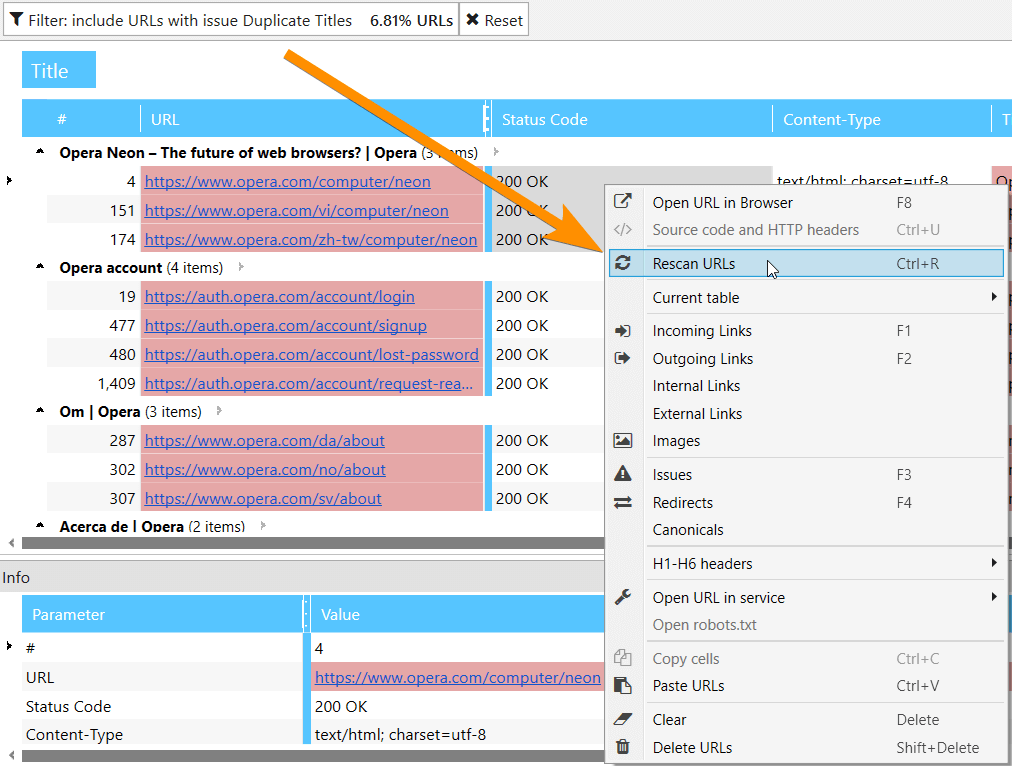
3. Deleting URLs from Results
If you’ve crawled some extra data and it made your report too heavy, now you can easily delete this information, and all your basic reports will be updated. Keep in mind that URL will be deleted globally → so it is recommended to save the project before deleting and only after that change results.
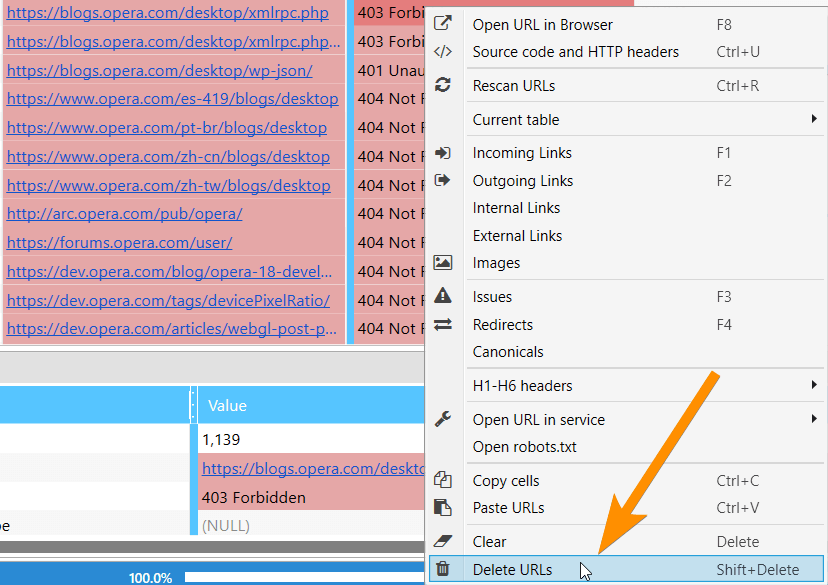
Also, now you can just clear results without deleting URLs. It is very useful when you need to recrawl same pages with new parameters.
4. Changing Parameters During Crawling
This change gives you an ultimate power in crawling management.
Let’s take a look at two cases:
- If you’ve started crawling and then realized that you forgot to include some significant parameters or parsing of necessary HTML fragment, now you can stop crawling, enable necessary parameters and then continue crawling. In this case, crawled pages will not be recrawled and included parameters will be applied only for new pages.
- If you’ve started crawling and understood that there is too much data (that is blowing your RAM), you can stop crawling, turn off unnecessary parameters, and resume it. And, voila, you freed up RAM and now can parse more data. By the way, the good news is that received data is not deleted, but just hidden. It means that if you turn these parameters back on, the data will appear in the table and be in all reports.
Use Case
I started crawling 1,000,000 pages but RAM usage was too high. After analyzing the report, I realized that these pages don’t have ‘Duplicate Pages’ and ‘Long Server Response Time’ issues. So I paused crawling and turned off the ‘Page Hash’ and ‘Response Time’ parameters. Then I just continued crawling by pressing ‘Start’ button. Columns with these issues were hidden and RAM consumption decreased → now I can crawl even more pages.
II. Hyper-Speed Crawling
We completely rearranged working process with:
- The database → there is a massive amount of data, so we’ve made substantial optimization. It results in a significant increase in the speed.
- Results table → to save computer resources, table will not be updated every time it receives new results. Updating occurs automatically after crawling is stopped or paused. Please note that tab title includes an asterisk (*) during the crawling. It indicates that program is receiving data but not displaying it in the table yet (if you need data right now, just press ‘Reload’ button above the results table).
- Comprehensive data analysis → incoming links, internal PageRank, and other complex parameters will be calculated once the crawling is stopped or complete. It makes the process as accurate as possible and allows you to save a lot of time on real-time calculations.
We conducted tests to compare crawling speed of Netpeak Spider 3.0 and the previous version, Netpeak Spider 2.1, with the same conditions and got great results. The new version shows up to 30 times increase in speed.
By the way, to monitor crawling speed, we’ve added corresponding metric to the status panel – now you can check the average crawling speed.
III. Advanced SEO Analytics
5. Dashboard
Information summary about crawling settings and process, diagrams with information about site structure, etc., SEO-insights, default filters – you can find all this stuff on our new ‘Dashboard’ tab.
We’ve implemented two states of this tab:
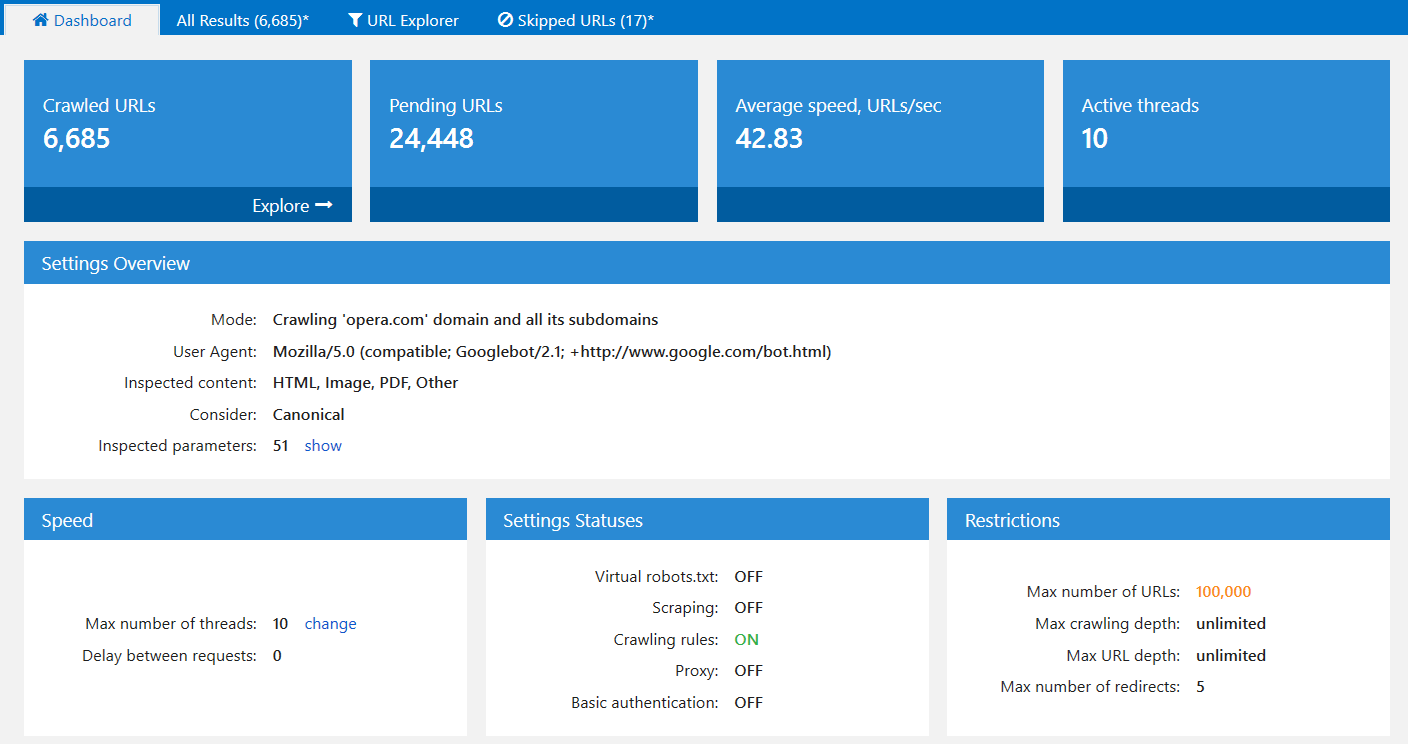
5.1. During Crawling
Users frequently ask us why crawling went wrong or even failed. It turned out that all problems remain in selected crawling settings. Therefore, we decided to gather and show useful and clear dashboard with an overview of the crawling process and important settings:
If necessary, you can download full screenshot of this panel using ‘Export…’ button: for example, to send it to us if you have some questions about your website’s crawlingg process.
5.2. After Crawling Is Stopped or Finished
When crawling is complete or paused, settings take a back seat. Diagrams with useful insights about crawled pages take first place:
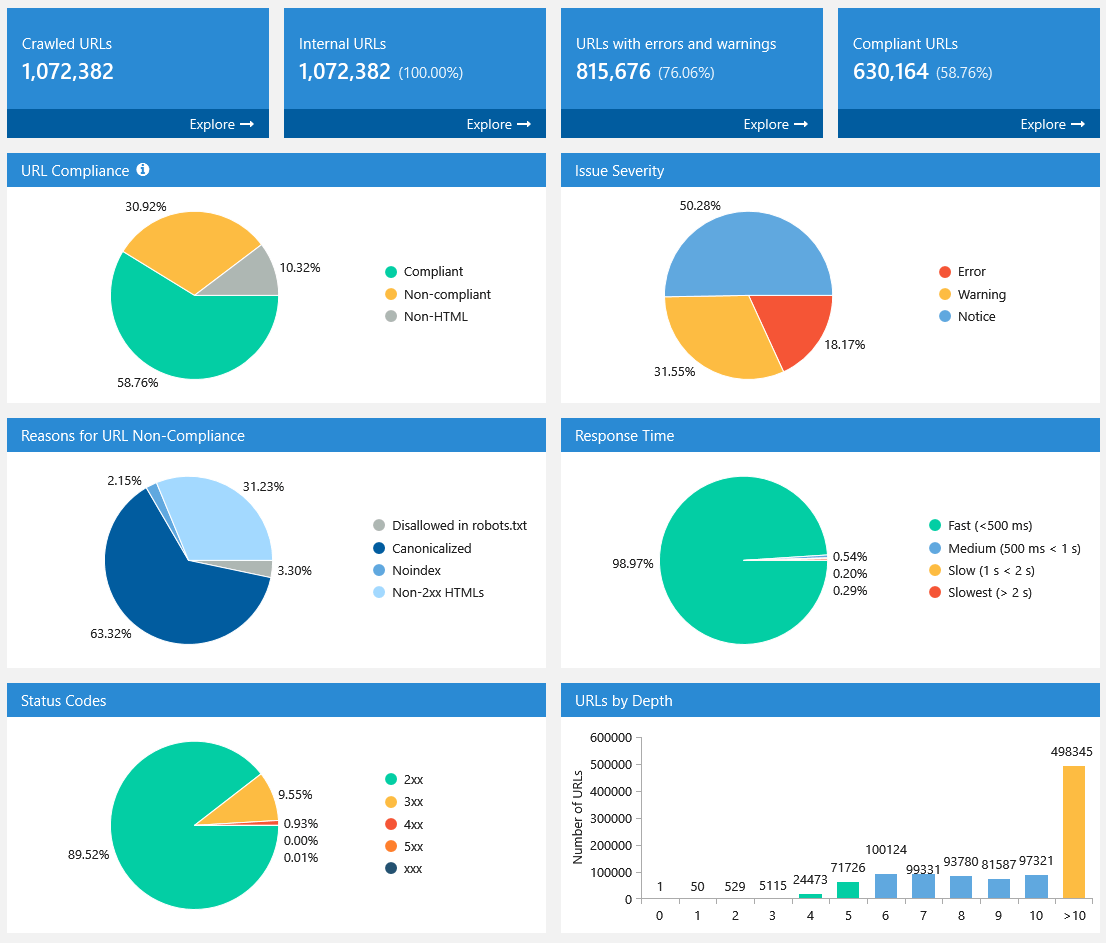
All diagrams are interactive: you can click on any part of the chart or any value near it and go to results filtered for that value.
Also, you can download full screenshot of this panel using the ’Export…’ button. This data and the issue report allow you to quickly understand current status of the analyzed website.
6. Site Structure
We’ve implemented a new report with the full site structure in the tree view, where you can filter pages at any level:
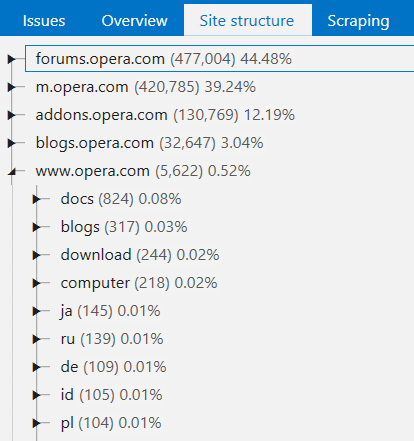
Try to select a category and press ‘Advanced copy’ button. Results will be copied to clipboard. Now you can paste them into external table (for example, Google Sheets or Microsoft Excel). I'll show how it works in the video below.
7. Segments
This is a unique feature on the market of desktop products and it opens up infinite possibilities for analytics.
Segments — this function allows you to change data view using a certain filter. Segments affect all reports in the program, including ‘Issues’, ‘Overview’, ‘Site Structure’, ‘Dashboard’, etc.
Take a look at two cases:
Task 1
To find out which site directory has the highest number of critical errors:
- Open issue report in the sidebar
- Filter errors
- Use this filter as a segment
- Go to the report with site structure
- (for example) download report using extended copy
- Task is completed.
Task 2
To find out exact site directory issues:
- Open website structure report in the sidebar
- Filter by certain directory
- Use this filter as a segment
- Go to the issues report
- (for example) download report using export function
- Task is completed.
Right now we are working on post with more useful examples of data segmentation :)
8. Export
Imagine another situation: you crawled the website and found 40 errors on it. To fix them, you need to export this information, process it and send to the developer.
Previously, it was necessary to go into each ‘Issue Report’, export it separately and clean extra information, because for fixing 'Duplicate Title' issue you don't need 'Response Time' parameter. We fixed this once and for all by developing default export templates. Now you can get required reports (or even all reports) in two clicks:
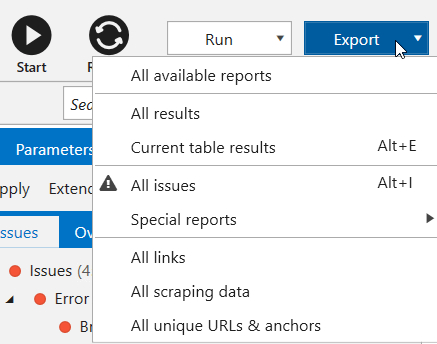
Additionally, now you can export the following data:
- All issues → exporting all issue reports into one folder;
- Custom issue reports → here are reports with convenient current data view on certain issues:
- Broken links
- Missing images ALT attributes
- Redirect chain
- Redirect blocked by Robots.txt
- Bad URL format redirects
- Canonical chain
- Canonical blocked by Robots.txt
- Links with bad URL format
- All links → export external and internal links on crawled pages separately;
- All unique URLs and anchors → in the same way, export separately all external and internal links. Data in the first report is grouped by URL, in the second one – by URL and anchor.
The new version allows to crawl large websites without any problems, so we’ve also prepared an automatic splitting of .xlsx files, if there are more than 1 million results in the report.
To export various reports, save projects, filter, and segment data, you’ll need the Netpeak Spider Standard plan. If you are not familiar with our tools yet, after signup, you’ll have the opportunity to give a try to all paid features immediately.
Check out the plans, subscribe to the most suitable for you, and get inspiring insights!
Remember light and dark sides of the Force? You have to make a challenging choice:
IV. More Details About Update
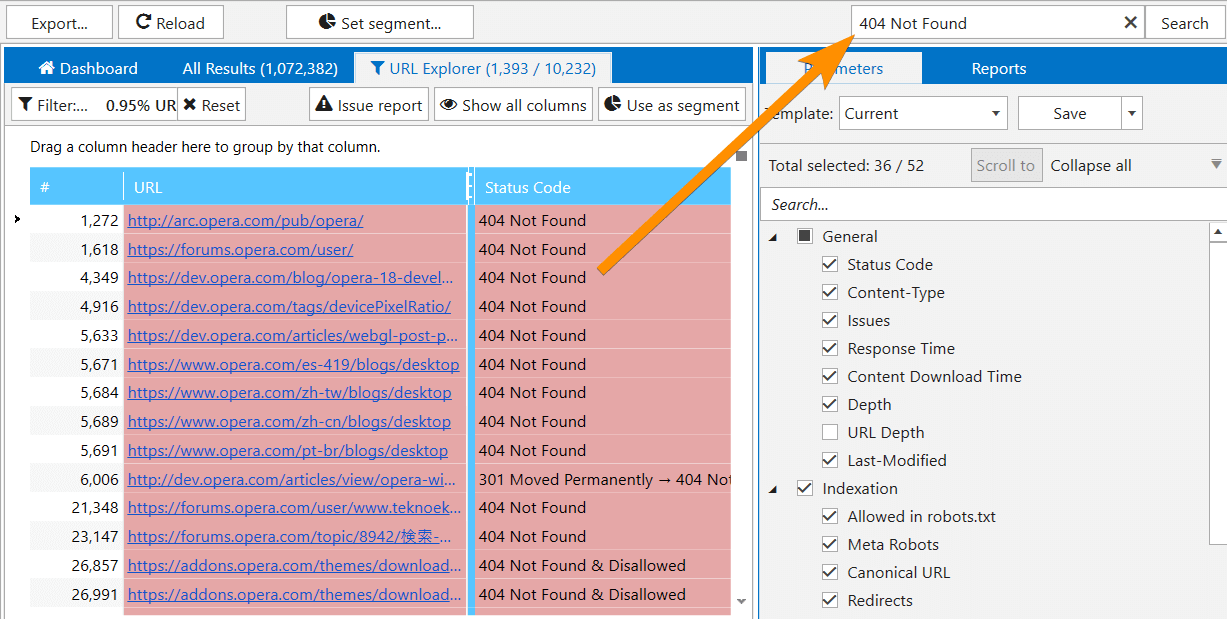
9. Determining Compliant URLs
Now Netpeak Spider determines 3 types of page compliancy:
- Compliant – HTML files with 2xx status code, not disallowed in indexation instructions (robots.txt, Canonical, Meta Robots, etc.). They are the most important pages on your website, because they can potentially lead organic traffic.
- Non-compliant – HTML files with non-2xx status code or disallowed by indexation instructions. These pages usually do not lead traffic from search engines and also waste crawling budget.
- Non-HTML – other documents with lower chances for high ranking in SERP.
Compliance becomes a unified concept for tools and analytics inside the program, most issues can be detected only for compliant URLs (for example, previously we also considered disallowed URLs for duplicates report, but starting from now we search for duplicates only among compliant URLs).
10. Issues
Issues Panel
Previously, you could filter only pages with certain issue. Starting from now, issues are displayed in the tree view, so you can filter URLs with exact issue severity or all pages that have at least one issue.
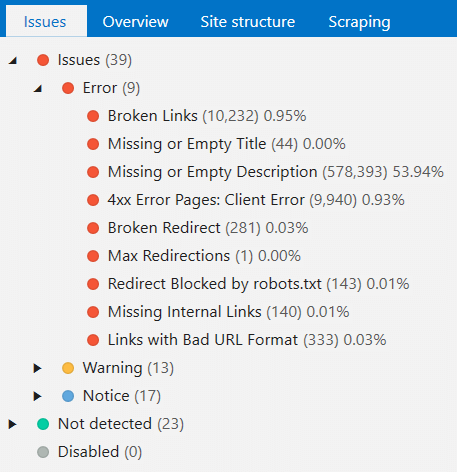
Now, clicking on the exact issue, you will see columns related only to this problem. You can press ‘Show all columns’ to receive complete report for filtered URLs.
For better understanding of each issue, we added descriptions which will be displayed on ‘Info’ panel at the bottom of the screen after selecting an issue. Soon we will add useful tips on how to solve them and how they affect your website.
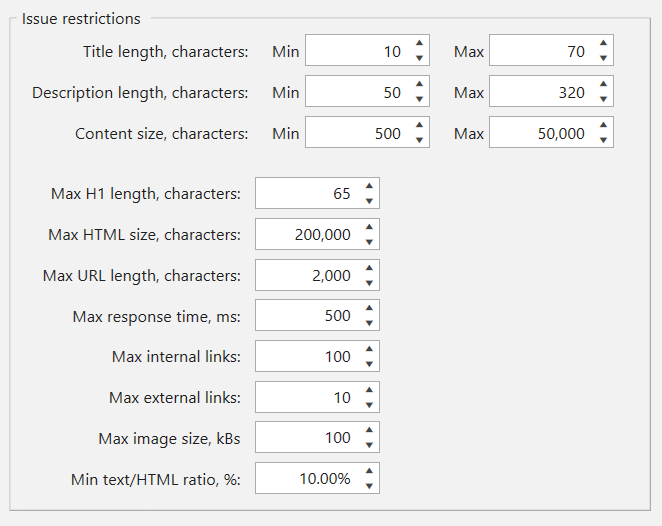
Each Issue Is Customizable
On ‘Restrictions’ tab of crawling settings you can customize almost all issue parameters to fit your conditions. For example, if you think that max image size of 100kB is too small, you can increase this number, and new values will be considered next time you start crawling.
Changes in Issues
We added new issues:
- Broken Links → Indicates unavailable pages, as well as the ones returning 4xx and higher HTTP status codes.
- Percent-Encoded URLs → Indicates pages that contain percent-encoded (non-ASCII) characters in URL.
Changed the approach to analyzing old issues:
- Broken Images → Indicates images returning 4xx and higher HTTP status codes, and unavailable images.
- Broken Redirect → Indicates all pages that redirect to unavailable URLs or URLs with 4xx or higher status code.
And of course, we got rid of outdated issues:
- Connection Error и Other Failed URLs → Moved to the ‘Broken Links’ category.
- Missing or Empty Canonical → We will not notify you about this optional tag anymore.
Special ‘Issue Report’ Button
Netpeak Spider can identify issues that need additional info. For example, when you choose ‘Missing Images ALT Attributes’ issue, program will filter pages with these images, but SEO specialists usually ask exactly for images report, so we added a quick access to special reports for the following issues:
- Broken Images
- Bad URL Format
- Redirect Blocked by robots.txt
- Canonical Blocked by robots.txt
- Missing Images ALT Attributes
- Internal Nofollow Links
- External Nofollow Links
11. Tools
In 3.0 version, we made quality improvements for all our tools. Let’s take a closer look at each of them.
Internal PageRank Calculation
Interface of the tool was completely rebuilt for more comfortable work with the following updates:
- Added ‘Internal PR’ parameter for each link → changes in tool are based on this article. Netpeak Spider calculates internal PageRank and shows results according to ‘second formula’ from mentioned article:
- N – total number of pages (nodes) on the website that were used in calculation.
- d – damping factor (most common value is 0.85).
- L – number of outbound links.
- if PR > 1,0 → page gets link equity.
- if PR = 1,0 → page shares and gets the same amount of link equity.
- if PR < 1,0 → page gives link equity away.
- Internal PageRank calculation is processed only for compliant URLs. Thus, images and other content types different from HTML will not be accounted for.
- We added ‘Link Weight’ parameter to show (you won’t believe it) how much link equity is distributed across the website. Let me remind that in ‘Internal PageRank Calculation’ tool you can delete even whole nodes. Thus, you can imitate situation to see what will happen to each page’s PR if you have no links to deleted node. It helps you optimize internal link weight distribution if you use this structure on your website after simulation in our tool.
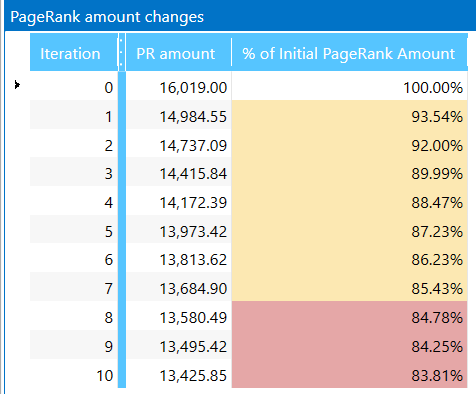
- We created new ‘PageRank changes’ table. During each iteration program calculates the ratio of internal PageRank on current iteration to PR on zero iteration. If the amount is decreasing, it means that natural link equity distribution is breached and you have ‘dead ends’ (it’s the right time to fix them!) on your website.
PR (A) = (1 - d) / N + d * (PR(B) / L(B) + PR(C) / L(C) + ...)
Where:
Also for better understanding, result (new ‘Internal PR’ parameter) is turned to the ‘first formula’ view using simple multiplying:
PR (first formula) = PR (second formula) * N (total number of pages in calculation)
Assuming results:
XML Sitemap Validator
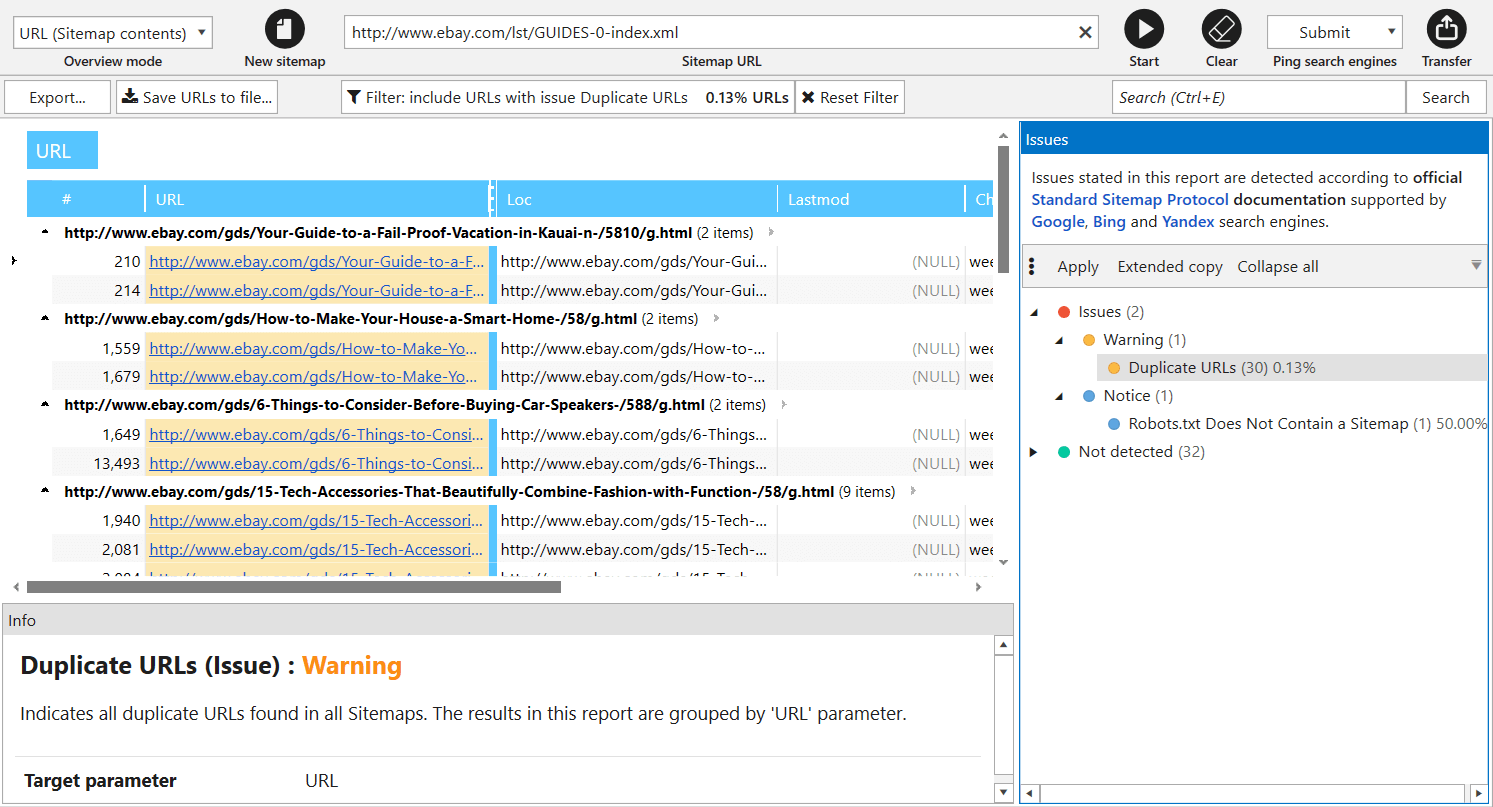
In previous version of Netpeak Spider, XML Sitemap validator was one of the crawling modes, but now we transformed it into separate tool. You can solve the following tasks using it:
- Parsing links from Sitemap and importing them to the main table for further analysis.
- XML Sitemap validation → we completely updated all issues (now there are 34 of them) according to main Google recommendations.
- Ping XML Sitemap to search engines to draw their attention to changes in it.
Note that crawling rules also work for link parsing from XML Sitemaps. For comfortable use, we save your previous requests here: start entering URL, and tool will show you previously crawled XML Sitemaps.
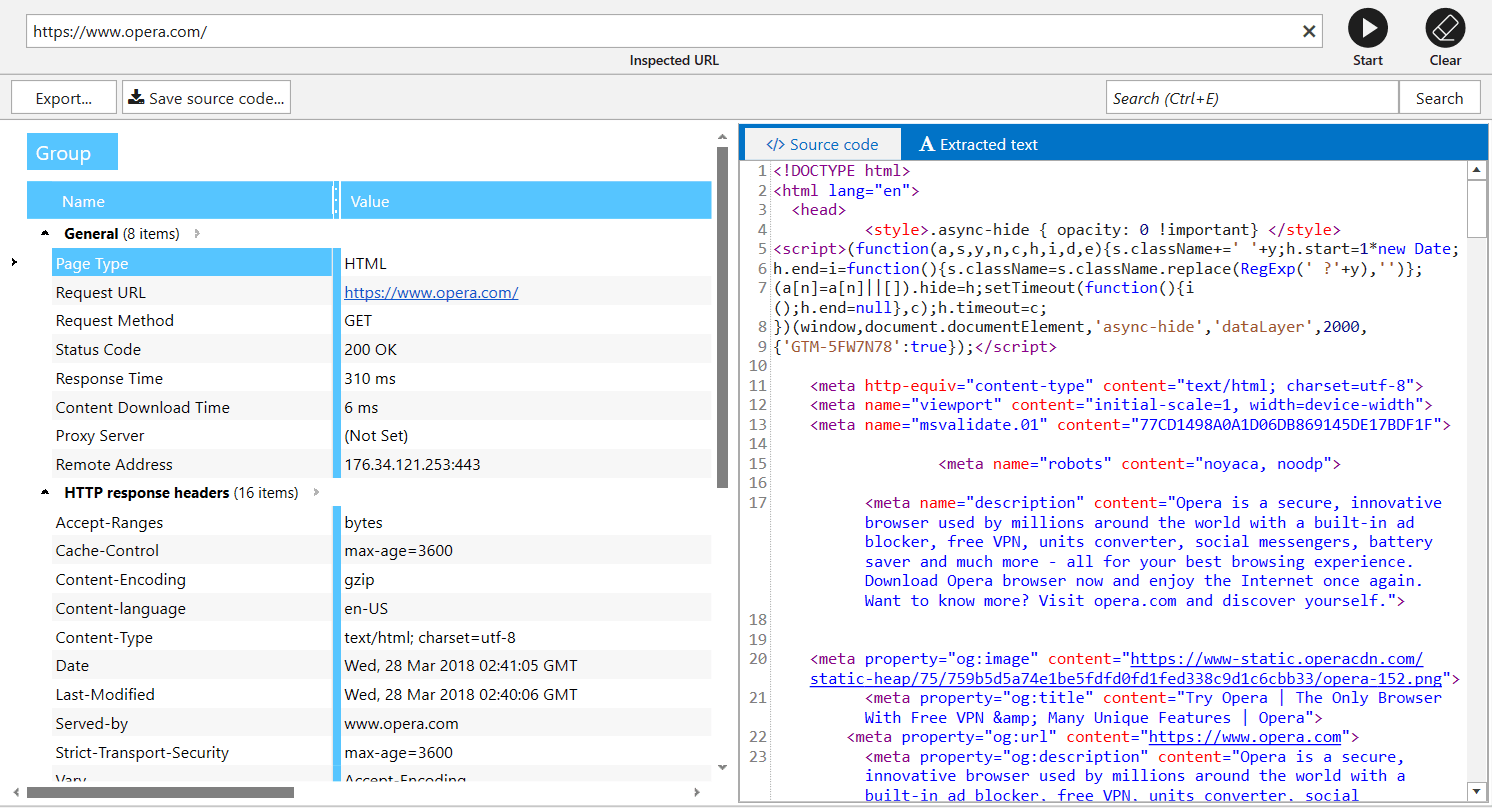
Source Code and HTTP Headers Analysis
As well as other tools, we improved interface of this one and added ‘Extracted text’ tab showing content of the page excluding HTML tags. This feature doesn’t replace Google cached ‘text-only’ view (as more reliable source), but can show you how exactly Netpeak Spider analyzes text on webpage to count characters and words.
Also, we save all your queries in this tool, so you can analyze necessary page again without any problems.
Sitemap Generator
In addition to the interface changes of this tool, it now creates Sitemaps only for compliant URLs. You no longer have to worry about disallowed pages being added to Sitemap by mistake.
As we validate XML Sitemaps according to lots of Google recommendations, Sitemap generator uses the same instructions.
12. Custom Templates
Since Netpeak Spider was created, our users were asking us for this small feature. We are glad to announce that we finished developing custom templates.
We went even further and released default templates and opportunity to create your own templates for:
- Settings → These templates save information about all crawling settings tabs (except for ‘Export’, ‘Authentication’, and ‘Proxy’) and allow you to switch between them in 2 clicks. Note that we have default templates you can use for various tasks. For example, if you need to make a simple crawl or use ‘search engine bot eyes’ to take a deep look at your website.
- Filters and Segments → Create your own templates if you often use the same conditions for data segmentation and filtering.
- Parameters → You can find these templates on ‘Parameters’ tab of sidebar. Note that we also have defaults for them: choose ‘Minimum’ if you need to crawl your website and get its structure as fast as possible without analyzing irrelevant issues.
13. Virtual robots.txt
If you need to test new robots.txt file and check how search engine robots will understand it, you should try ‘Virtual robots.txt’ setting. Netpeak Spider will use this virtual file instead of the file in root directory of your website.
14. Settings
Crawling settings have also been changed:
- Finally you will be able to view settings during crawling. Threads number will change right after you press ‘OK’, and the rest of settings – after the crawling is stopped. Note that you don’t have to recrawl the website if you need to change some settings. If it’s not critical for you, you can change them in the middle of crawling, and Netpeak Spider will consider these changes immediately. Flexibility level 110, isn’t it? :)
- Added export settings → since there’s about one million more reports in the program now, we’ve implemented export settings to make it easier for you to change format and locale of generated files, manage file export, etc.
- Upgraded ‘User Agent’ tab → implemented comfortable User Agent settings with search, and also added more User Agents that our clients were asking for.
- Proxy settings turned into ‘Proxy List’ → we’ve added a new proxy list validation tool, just like in Netpeak Checker. If you need to use one proxy (for instance, to access the website closed by IP), – simply add one proxy to the list. If you need to imitate several users’ interaction with the website or list of URLs, add numerous proxies and they will be immediately verified.
- Implemented default settings templates for the most popular occasions: regular crawling (getting maximum number of URLs), Googlebot-style crawling (considering indexation instructions) or crawling certain section.
15. Combining Several Crawling Modes
This is a new and unique feature. Previously, you had to choose crawling mode to run the program – for instance, if you wanted to crawl the entire website or only specific list of URLs. But now you can combine these modes! :)
In a new program version you can add URLs for crawling in the following ways:
- By crawling the website → simply add a URL into the ‘Initial URL’ field and press ‘Start’ button: pages will be added according to the crawling progress.
- Manually → this way a separate window with text input will be opened for you to add URLs list with each URL on a new line.
- From file → we significantly modified this function and added URL import from files with such extensions: .xlsx (Microsoft Excel), .csv (comma-separated values), .xml (Extensible Markup Language), .nspj (Netpeak Spider project) and .ncpj (Netpeak Checker project).
- From XML Sitemap → XML Sitemap validator will be opened, so that you can import URLs for crawling in the main table.
- From clipboard → simply use Ctrl+V combination with program’s main table opened, URL list from clipboard will be added to the table and notification with brief summary information will appear (what is successfully added, what is already in the table, what is not added because of bad URL format).
- Drag and Drop → you can simply transfer project or any other file with extensions mentioned above from file straight to the main table: Netpeak Spider will analyze files and upload necessary data.
Note that now all URLs you import to the program will be organized in initial order. To simplify data search and comparing crawling results from different periods.
Attention!
Combining several crawling modes provides greater flexibility, but can also be complicated. Let’s see how program will operate in certain cases:
- Pressing 'Start' button:
- If URL is entered in ‘Initial URL’ field and the table is empty → Netpeak Spider will crawl entire website starting from this URL.
- If URL is entered in ‘Initial URL’ field and there are URLs in the table → the program will crawl the website from ‘Initial URL’ field and will additionally crawl URLs entered to the table using their outgoing links for crawling (interesting hack if you’d like to start crawling the website from different points).
- If ‘Initial URL’ field is empty and there are URLs in the table → only URLs added to the table will be crawled (just like the old ‘List of URLs’ crawling mode). Of course, you will get the data only for URls with no results.
- Pressing 'Restart' button:
- If URL is entered in ‘Initial URL’ field → the program will delete all crawling results and start crawling the website again, whether there were URLs added manually in the table or not.
- If ‘Initial URL’ field is empty and there are URLs in the table → all added URLs will be recrawled again.
As you may have noticed, program behaves differently according to whether there is an URL in ‘Initial URL’.
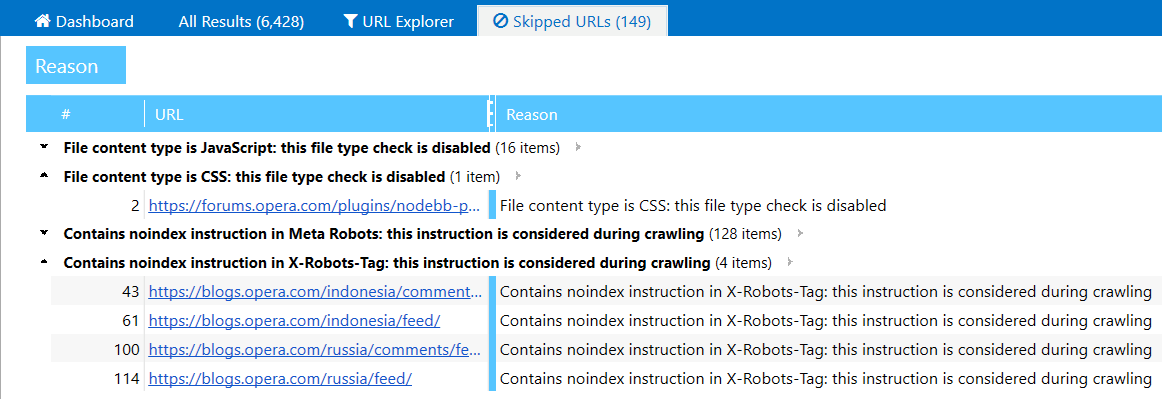
16. Table of URLs Skipped While Crawling
‘Can’t crawl the website for some reason’ – this is one of the most frequent problems our clients have while working with Netpeak Spider. Now we have two new ways to solve it:
- URL you’ve entered to ‘Initial URL’ field will be always added to the table. This way, you will know if this URL redirects to another website or simply unavailable at the moment.
- ‘Skipped URLs’ tab will appear only if some pages were ignored while crawling. Here you will see URLs and the reason why they were skipped: for example, you’ve enabled considering indexation instructions from robots.txt file, applied crawling rules or disabled checking some of content types.
17. Quick Search in Table
Quick search in table is implemented in all interfaces of the program – just press Ctrl+E and enter search query:
Be careful: this function is applied to all table columns. If you need to filter data by certain parameter or segment all data, use the following functions:
- Ctrl+F→ filter settings
- Ctrl+Shift+F → segment settings
18. ‘Analysis’ Module
From now on complicated calculations are performed after crawling is complete or stopped. If corresponding parameters are enabled by default, you will see a window where you can cancel data analysis. With ‘Analysis’ module you can analyze results at any time: for example, after deleting some results for recalculating PageRank or the number of incoming links.
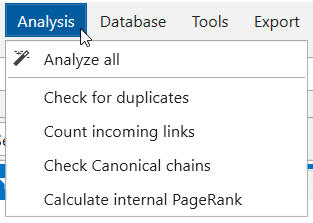
The following data is processed after crawling is complete/stopped:
- Checking all duplicates
- Counting incoming links for every URL
- Checking Canonical chains
- Calculating internal PageRank
19. ‘Database’ Module
All comprehensive data arrays were moved to a single module – one more unique feature of new Netpeak Spider. Using this module, you can view massive lists of:
- incoming, outgoing, internal, and external links
- images
- issues
- redirects
- Canonical
- H1-H6 headers
In this module we have implemented easy switching between needed parameters and also pagination (from 50,000 to 1,000,000 results per page depending on amount of free RAM) allowing to view unlimited data:
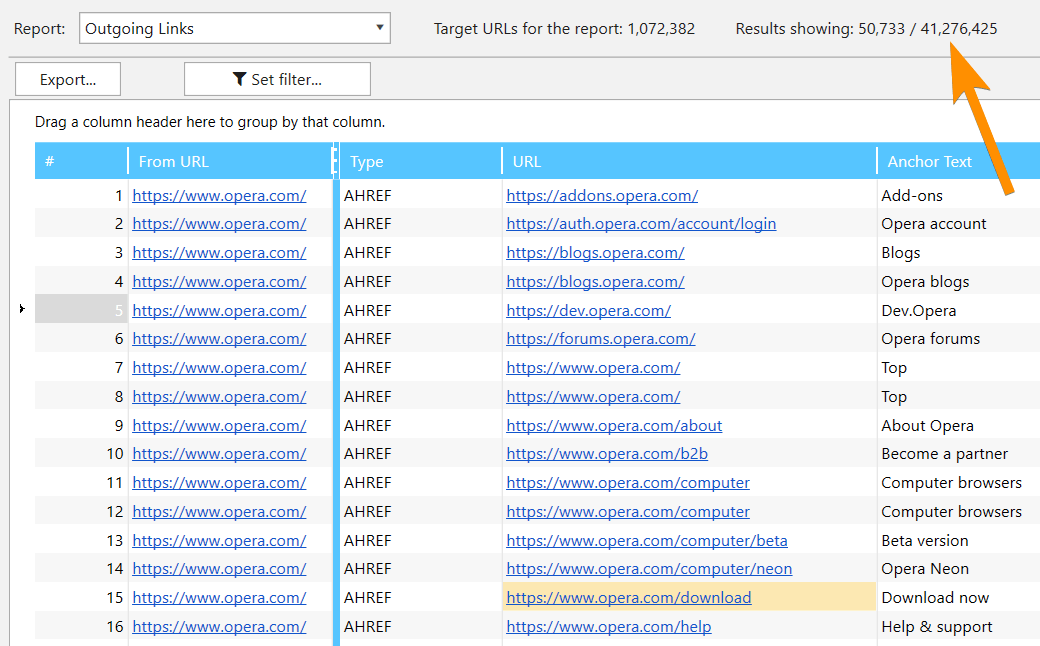
Note that when applying filter, this module will be used not only for current pagination page, but also for all data, that’s why it can take some time.
20. Parameters
Sidebar
Parameters setting has been moved from crawling settings to ‘Parameters’ tab in sidebar. Now, just like in Netpeak Checker, you can search by all parameters and view a detailed tip about them on ‘Info’ panel.
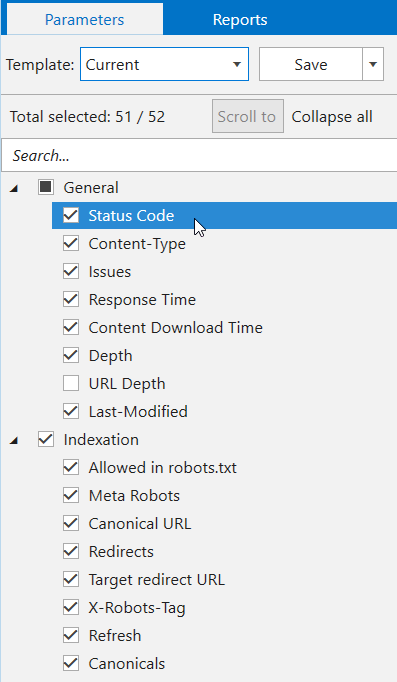
If you have already got results in the main table, you can click on a parameter (or use ‘Scroll to’ button on this panel) to quickly reach the corresponding parameter in the current table.
We’ve also implemented default parameter templates for the most common cases:
- Minimal (for quick crawling of the website to gather all URLs).
- Recommended (optimal for the majority of cases – identifies max types of issues).
- For PageRank (minimum parameters necessary for calculation).
- All available parameters.
Changes in Parameters
Added new ‘URL Depth’ parameter showing number of segments in inspected page's URL. Unlike 'Depth' parameter, URL depth is a static one not depending on initial URL. For instance, URL depth for https://example.com/category/ page is 1, for https://example.com/category/product/ page is 2 and so forth.
Changed some old parameters:
- ‘Page Body Hash’ is now called ‘Text Hash’ and allows you to search for duplicates not only by HTML in <body> section, but also by text content.
- Canonicals are now treated like redirect chains.
21. Filters
We’ve updated the interface, added search by parameters and added an opportunity to create custom templates:
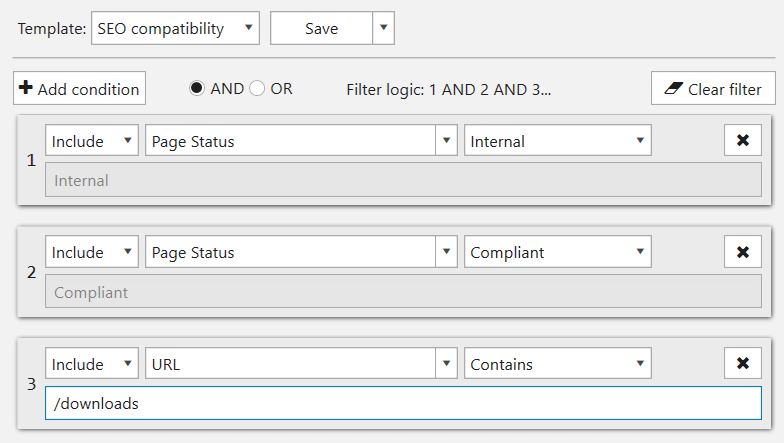
I’d like to remind that there are default filters on ‘Dashboard’, as well as on ‘Issues’, ‘Overview’, ‘Site Structure’, and ‘Scraping’ tabs, leading to ‘URL Explorer’ tab with corresponding filter applied. This is where you’ll find ‘Use as segment’ function allowing you to limit current data view and see reports in another light.
You can hide other changes and go to comparison with competitors
V. Other Changes
Here is a brief summary of other upgrades in Netpeak Spider 3.0:- Monitoring memory limit → checking the amount of free RAM and disk space: there should be at least 128 MB of both available for program to run. If limit is reached, the crawling stops and the data remains intact.
- Choosing initial URL → when you start typing, a tooltip appears (similar to the Chrome browser) containing the list of URLs from which the crawling successfully started.
- In addition to usual project downloading, ‘Project’ menu was added →'Recent projects', where you can open the last project you worked with (Ctrl+Shift+T combination).
- ‘Open URL in service’ item is added to the shortcut menu, it allows you to open the selected URL in Google services, Bing, Yahoo, Yandex, Serpstat, Majestic, Open Site Explorer (Mozscape), Ahrefs, Google PageSpeed, Mobile Friendly Test, Google Cache, Wayback Machine (Web Archive), W3C Validator or all at once (very fun function for your browser). Also the ‘Open robots.txt’ item was added in the shortcut menu which (of course, by coincidence) opens a robots.txt file in the root folder of the selected host.
- When you click on any cell in the table on the ‘Info’ panel, the same table will be shown with the analyzed parameters, only vertically and specially for this URL.
- Multi-window → it is now possible to open several Netpeak Spider windows at once and run separate crawlings.
- Special status codes → there is an addition to such response codes as Disallow / Canonicalized / Refresh Redirected / Noindex / Nofollow. Now they are always displayed, regardless of whether you want to consider indexing rules or whether the corresponding parameter is enabled. You can filter pages by page status on the ‘Overview’ tab in the sidebar.
- The ‘Custom search and extraction’ function was renamed to ‘Scraping’ → now it works in a similar way to other internal tables. We no longer separate search and extraction (now data is always collected). You can also enable / disable scraping just like any other parameter in the sidebar on the ‘Parameters’ tab.
- Added saving the positions of all windows and panels → and if something goes wrong, you can always reset their positions using the ‘Window’ menu → ‘Reset all positions’, ‘Reset window positions’ or ‘Reset panel positions’.
- Migration of saved projects from Netpeak Spider 2.1 version to projects 3.0 is complete.
Of course, we got rid of some functions:
- Crawling mode ‘Google SERP’ → don’t be upset, a special tool for solving similar problems will be added to Netpeak Checker.
- Quick settings → now all settings can be viewed during the crawling, so this functionality has lost sense.
- Crawling mode ‘Only Directories’ → it turned into a check mark on the ‘General’ tab of crawling settings.
VI. Comparison with Competitors
Friends, it's time to change the Force balance in the Galaxy. We will not compare tools by the functional (we will do this a bit later), but by three technical parameters:
- RAM consumption
- Disc space consumption
- Analysis time
To make more clear comparison, we tested programs using a medium site (10,000 URLs) and a large one (100,000 URLs). We wanted to add 1 million URLs to the comparison, but, frankly speaking, not all programs could cope even with 100 thousand.
Comparison is divided in two parts – with our previous version and with the main competitors on the global market.
Comparison with 2.1 Version
As a young padawan, version 3.0 should be better than its predecessor 2.1. That’s the only way it can fulfill its potential.
Medium Website (10K pages)
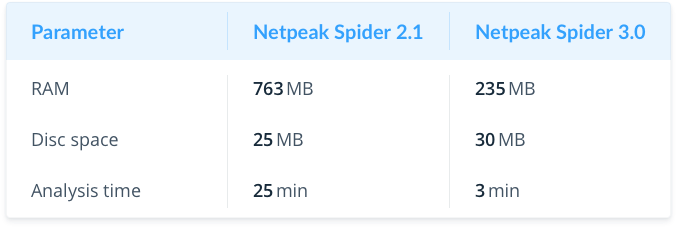
As you can see, when analyzing medium sites, we reduced RAM consumption by 3 times and accelerated crawling by 8 times.
Large Website (100K pages)
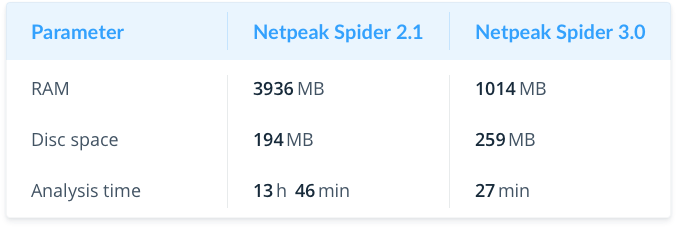
It highlights the strengths of the new version – RAM consumption has decreased even more (4 times), and crawling took 30 times less time.
Comparison with Screaming Frog SEO Spider, WebSite Auditor and Sitebulb
I would not like to advertise competitors, but our users always ask how we differ from them – so let's compare Netpeak Spider 3.0 to well-known programs (Screaming Frog SEO Spider, WebSite Auditor) and a young child of our British colleagues (Sitebulb)!
The latest Screaming Frog SEO Spider update was supposed to bring itself closer to successful crawling of large websites. And we were just wondering how these new modes work – so we will reveal their secrets too.
I should note that we performed crawling with the same settings and using the same websites. The best results are marked by green color and the worst – by red color.
Medium Website (10K Pages)
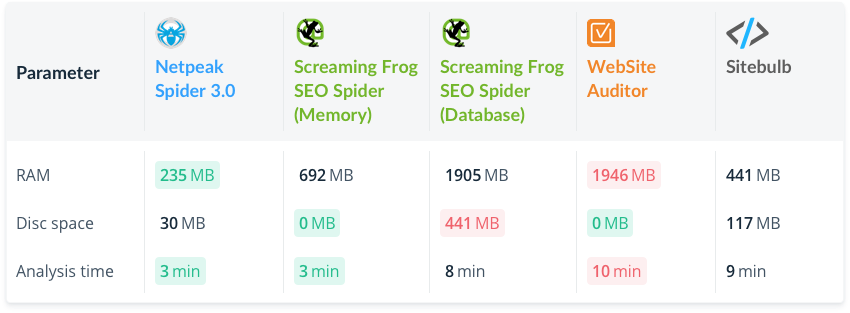
Netpeak Spider uses less RAM and becomes RAM-saving leader (the nearest competitor consumes 2 times more), and we go along with Screaming Frog SEO Spider in terms of analysis time (in Memory mode).
Large Website (100K Pages)
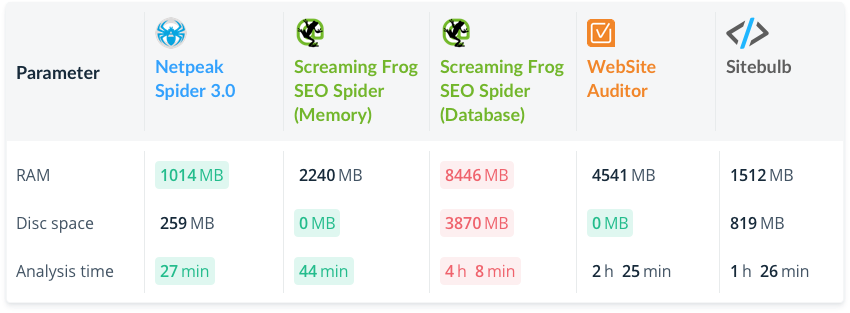
It is noticeable that green color is tending to the left :) In this case, we have the fastest crawling consuming the least amount of RAM.
Let’s focus on interesting fact – for some reason Screaming Frog SEO Spider starts consuming much more RAM after switching from Memory mode to Database mode (nonsense, isn’t it?), considering that the other technical specifications also suffer (as you can see by red color concentration).
VII. In a Nutshell
Netpeak Spider 3.0 has transformed into a super fast tool, allowing you to work with huge websites and conduct comprehensive SEO analytics without any setbacks.
- Up to 30 times faster crawling, compared to 2.1.
- Optimized RAM usage.
- Option to resume crawling after opening the project.
- Deleting URLs from report.
- Recrawling a URL or a list of URLs.
- Changing parameters during crawling.
- Data segmentation.
- Site structure report.
- Dashboard (information about crawling process and diagrams after it’s complete).
- Exporting 10+ new reports and 60+ issue reports in two clicks.
- Determining compliant URLs.
- Special reports for every issue.
- Rebuilt tools ‘Internal PageRank Calculation’, ‘XML Sitemap Validator’, ‘Source Code and HTTP Header Analysis’, and ‘Sitemap Generator’.
- Custom templates for settings, filters / segments, and parameters.
- Virtual robots.txt.
- Combining all of the crawling modes into one.
- List of URLs, skipped by crawler.
- Quick search in tables.
- Delaying comprehensive data analysis.
- New ‘Parameters’ tab with search and scrolling to parameter in table.
- Monitoring memory limit for data integrity.
- And hundreds of other improvements…
Compared with the previous 2.1 version, we improved memory consumption by 4 times and reduced crawling time by 30 times (by the example of a large sites crawling). Comparison with competitors shows that we consume the less amount of RAM and have the fastest crawling speed.
VIII. Surprise
On the occasion of the long-awaited release, we decided to give you lots of presents!
Free Trial
- If you have already used Netpeak Spider, then especially for you we give opportunity to try the new version for a whole week (until April 4th inclusive);
- If you have not tried Netpeak Spider, you have 14-days free trial.
No matter what, press on the button and find out the level of midichlorians in your blood:
By the way, to add a little sunshine to your day we added one more little surprise while launching a new version!
In conclusion, I would like to thank you for not being afraid and have reached the end of this post through thick and thin!
We are already working on Netpeak Spider 3.1 version. Also, Netpeak Checker 2.2 is being developed.
We put a lot of effort into this release, so we are looking forward to hear your feedback ;)
May the crawling Force be with you!


