Netpeak Spider 3.0: новая SEO-надежда
Обновления

Жители галактики Млечный Путь, сегодня мы запускаем на орбиту совершенно новую версию нашего продукта → Netpeak Spider 3.0 с кодовым именем «Новая SEO-надежда». Это самое крупное обновление за всё время существования программы, которое включает в себя около 300 изменений: от супер-фич до небольших фиксов в юзабилити. Используйте Силу, чтобы извлечь максимум из этого поста!
Итак, пройдёмся по основным изменениям, после чего рассмотрим сравнение краулинга по техническим параметрам с тремя нашими конкурентами. Воспользуйтесь содержанием для быстрого перехода к необходимым эпизодам:
- Анализ сайтов-гигантов
- Гиперскорость сканирования
- Продвинутая SEO-аналитика
- Подробнее об обновлении
- Остальные изменения
- Сравнение с конкурентами
- Коротко о главном
Смотрите детальный видеообзор в посте «Netpeak Spider 3.0: обзор улучшений».
I. Анализ сайтов-гигантов
Новая версия программы специализируется на анализе больших сайтов (например, 1 000 000 страниц). Теперь пробить такой сайт можно даже не имея «заоблачной» конфигурации компьютера.
И всё это благодаря улучшенному управлению сканированием и оптимальному потреблению оперативной памяти.
1. Возможность продолжить сканирование
Теперь вы можете остановить сканирование, сохранить проект и потом, если вам удобно, досканировать сайт:
- к примеру, на следующий день → для этого необходимо просто открыть проект и нажать на кнопку «Старт»;
- на другом компьютере → для этого необходимо перенести всю папку с проектом на нужный компьютер (например, более мощный), открыть проект там и снова нажать на заветную кнопку «Старт».
2. Перепробивка списка URL
Представьте, что Netpeak Spider обнаружил на вашем сайте проблему с дубликатами тега Title. Вы экспортируете отчёт и отправляете его разработчику, попутно объясняя, как исправить эту ошибку.
Раньше, чтобы проверить корректность исправления ошибки, вам нужно было сканировать весь сайт заново или мучиться со списками URL. Теперь же вы можете выбрать ошибку в боковой панели и запустить пересканирование только тех страниц, которые ей соответствуют → на выходе вы получите полностью обновлённый отчёт по всему сайту.
Разумеется, вы можете пересканировать как один URL, так и любой список URL на вкладках «Все результаты» или «Отфильтрованные результаты».
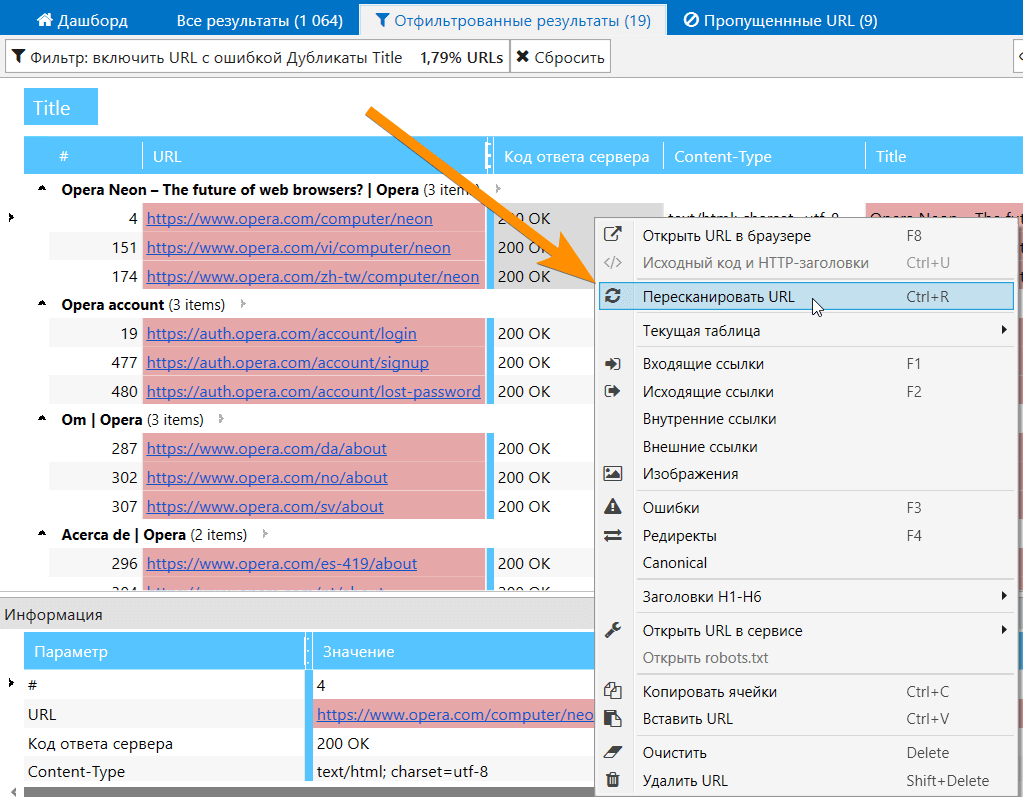
3. Удаление URL из результатов
Если вы просканировали что-то лишнее, и вам мешают эти данные в отчётах, теперь вы можете без проблем удалить их, и все стандартные отчёты будут обновлены. Обратите внимание, что система удаления URL глобальная → советуем сохранить проект перед удалением страниц, а потом уже экспериментировать с результатами.
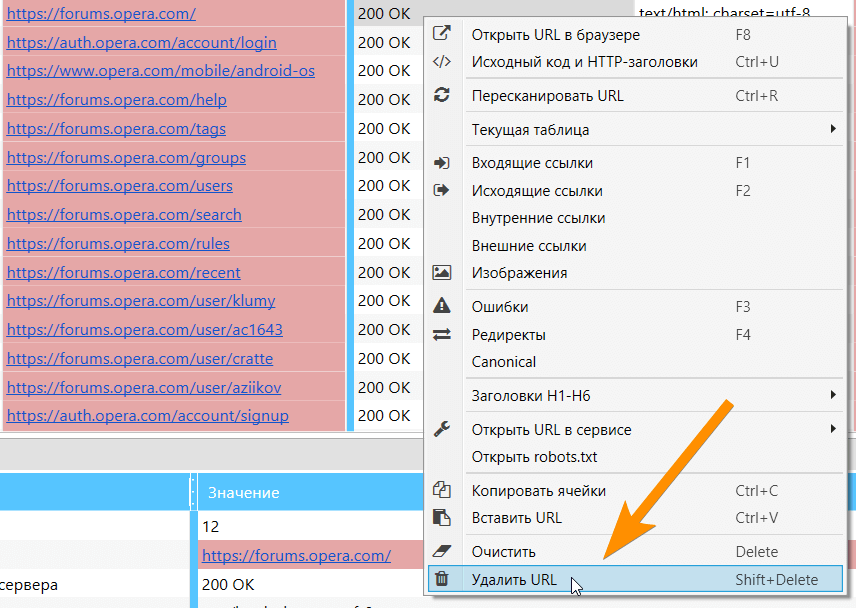
Также теперь вы можете просто очистить результаты, не удаляя сами URL — крайне полезно, когда вам необходимо как-то по-новому просканировать уже существующие страницы.
4. Изменение параметров в ходе сканирования
Это изменение даёт +100 к вашей Силе управления сканированием.
Рассмотрим два противоположных случая:
- Если вы начали сканирование, а потом вспомнили, что не включили какой-то важный параметр или парсинг какого-то фрагмента HTML-кода, то теперь вы можете остановить сканирование, включить необходимые параметры и продолжить сканирование дальше. В этом случае уже просканированные страницы не будут перепробиваться, а включённые параметры начнут появляться только для новых страниц.
- Если вы начали сканирование и понимаете, что данных слишком много (а данные забивают оперативную память), при этом вы спокойно сможете без них прожить, то аналогично — останавливаете сканирование, выключаете ненужные параметры или парсеры, продолжаете сканирование. И, вуаля, оперативная память освобождается и позволяет вам пробить ещё больше результатов. Кстати, хорошая новость в том, что те данные, которые уже успел получить Netpeak Spider, не удаляются, а просто скрываются — если вы потом снова включите эти параметры, то данные появятся в таблице и будут учитываться во всех отчётах.
Кейс из жизни
Я прокраулил 1 000 000 страниц сайта и понимаю, что упёрся в лимит по оперативной памяти. Бегло проанализировав отчёт, я понимаю, что на этом миллионе страниц ни разу не были найдены ошибки с полными дубликатами и слишком большим временем ответа сервера. Я останавливаю сканирование и выключаю параметры «Хеш страницы» и «Время ответа сервера». После этого запускаю сканирование дальше с помощью кнопки «Старт». Эти две колонки скрываются, потребление оперативной памяти уменьшается → теперь я могу просканировать ещё больше страниц.
II. Гиперскорость сканирования
Мы полностью переделали принципы работы программы:
- С базой данных → все супер-тяжёлые данные попадают туда, потому мы провели серьёзную оптимизацию, что дало значительный прирост к скорости.
- С таблицей результатов → теперь при получении результатов таблица не обновляется каждый раз, чтобы сэкономить огромное количество ресурсов компьютера: обновление происходит автоматически после окончания или приостановки сканирования. Обратите внимание, что при сканировании в названии вкладки ставится звёздочка «*» — это указывает на то, что данные получаются, но пока что не отображаются в таблице (если вам сильно нужны данные, то просто нажмите кнопку «Обновить» над таблицей с результатами).
- С анализом больших данных → теперь анализ входящих ссылок, внутреннего PageRank и других сложных параметров запускается после остановки или окончания сканирования, что делает его максимально точным и позволяет сэкономить уйму времени на real-time расчётах.
Исходя из тестов, в рамках которых мы сравнивали скорость пробивки Netpeak Spider 3.0 и предыдущей версии Netpeak Spider 2.1 с одинаковыми условиями, новая версия показывает увеличение скорости где-то в 30 раз.
Кстати, чтобы наблюдать за скоростью сканирования, мы добавили в статус-панель соответствующую метрику — теперь вы будете знать среднюю скорость сканирования, например 10 URL/с.
III. Продвинутая SEO-аналитика
5. Дашборд
Сводные данные о настройках и ходе сканирования, круговые и столбчатые диаграммы, SEO-инсайты, удобные преднастроенные фильтры — всё это вы найдёте на нашей новой вкладке «Дашборд».
Мы реализовали два состояния этой вкладки:
5.1. Во время сканирования
К нам часто обращаются клиенты с просьбой разобраться, почему тот или иной сайт не сканируется или сканируется не так, как ожидалось. Оказывается, подавляющая часть подобных проблем кроется в выбранных настройках сканирования. Потому мы решили в едином месте показать удобную сводку по ходу сканирования и всем важным настройкам:
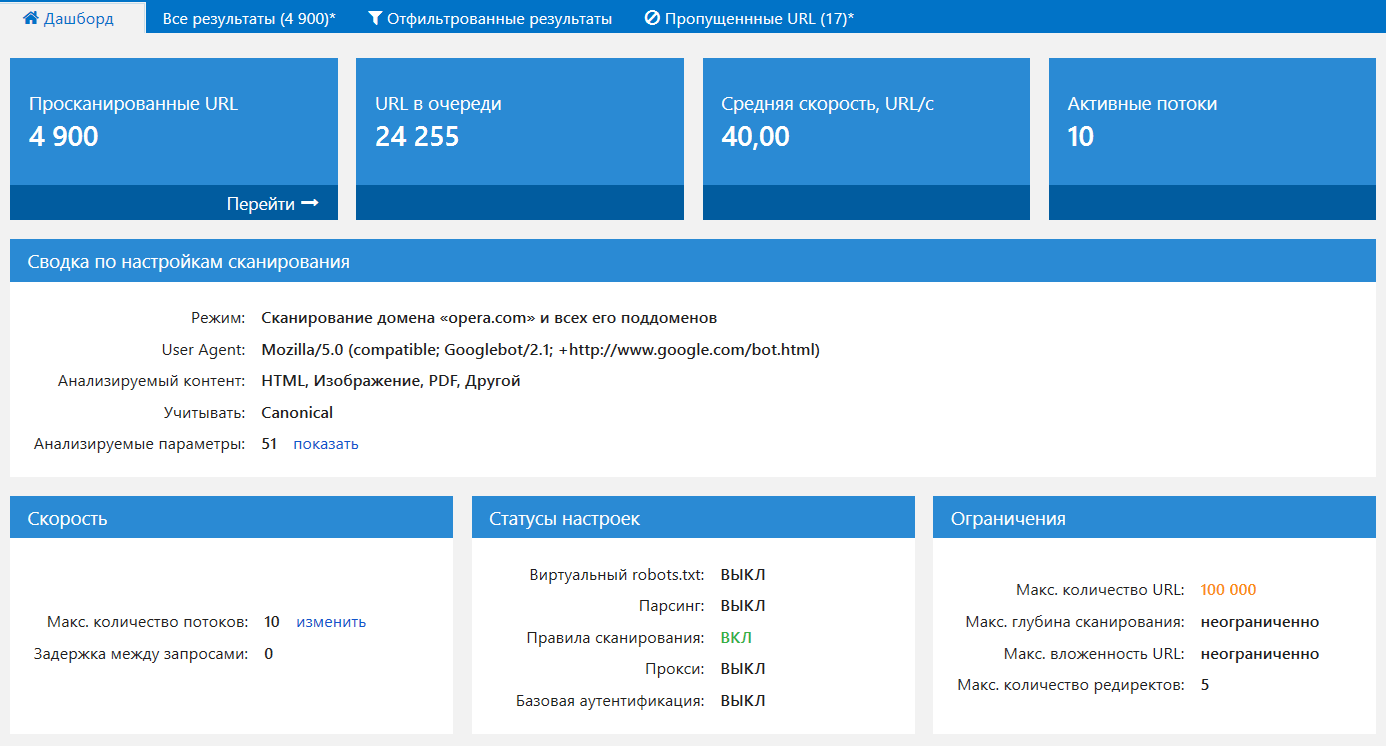
Если необходимо, вы можете выгрузить полный скриншот этой панели с помощью кнопки «Экспорт...»: например, чтобы отправить его нам, когда у вас возникнет проблема со сканированием сайта.
5.2. После остановки или окончания сканирования
Когда сканирование завершено, или вы его специально остановили, то настройки уже не так важны — в ход идут графики и диаграммы с полезными инсайтами о просканированных страницах:
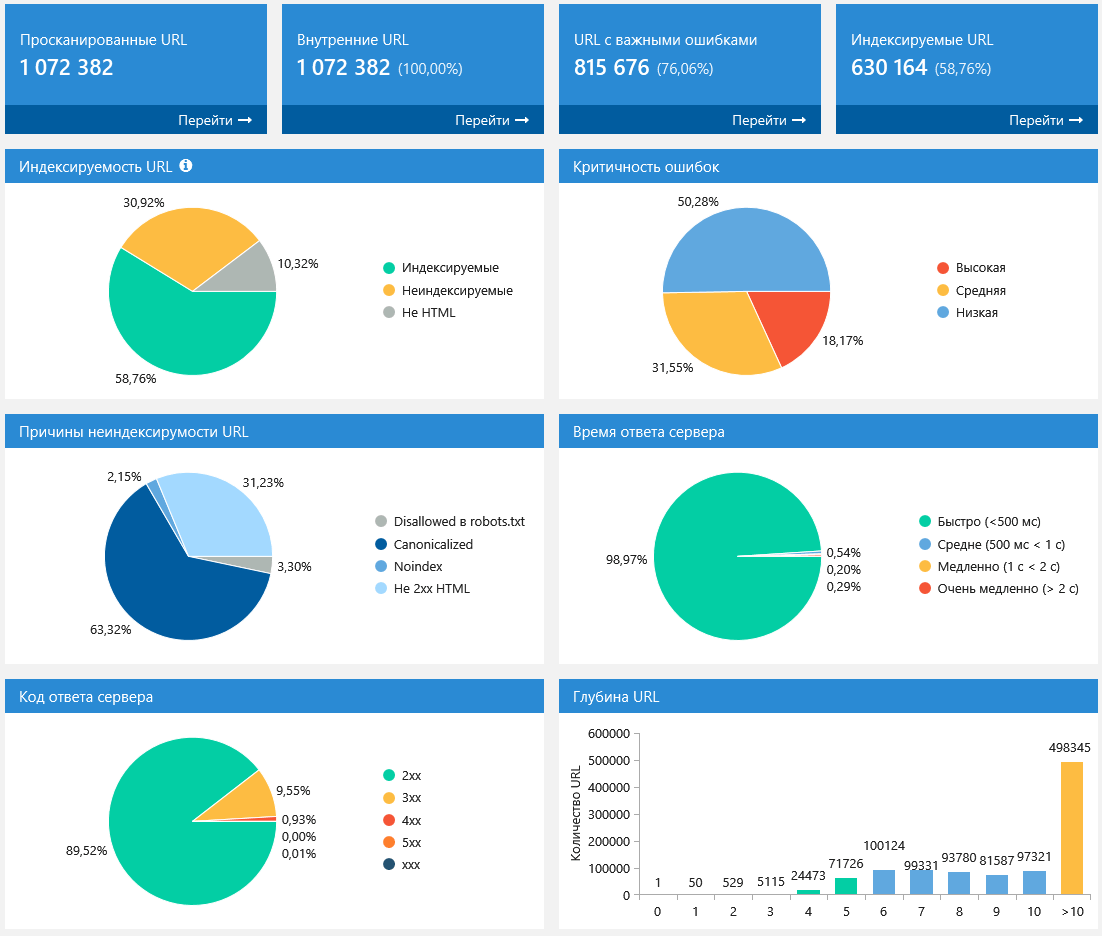
Обратите внимание, что все графики интерактивные: вы можете нажать на любую часть диаграммы или на любое значение рядом с ней и перейти на отфильтрованные результаты по этому значению.
Аналогично, вы можете выгрузить полный скриншот этой панели с помощью кнопки «Экспорт...»: эти данные вместе с отчётом по ошибкам позволяют очень быстро понять, в каком состоянии находится анализируемый сайт.
6. Структура сайта
Мы реализовали новый отчёт с полной структурой сайта в виде дерева и возможностью отфильтровать страницы на любом уровне:
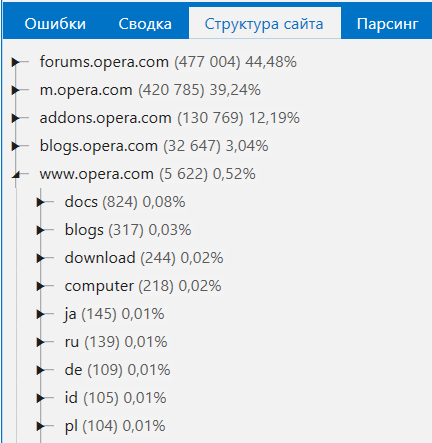
А ещё попробуйте выделить категорию и нажать кнопку «Расширенное копирование» — в буфер обмена скопируются интересные результаты, которые можно вставить в любую внешнюю таблицу (например, Google Таблицы или Microsoft Excel). Я покажу этот функционал на видео ниже.
7. Сегменты
Эта фича является уникальной на рынке десктопных продуктов и открывает бесконечные возможности для аналитики.
Сегменты — это функция, позволяющая изменить представление данных, ограничивая их определённым фильтром. Применение сегментов влияет на все отчёты в программе, включая ошибки, сводку, структуру сайта, дашборд и т.д.
Приведу два показательных кейса:
Задача 1
Понять, в каких разделах сайта больше всего критических ошибок.
Алгоритм действий:
- открываем отчёт по ошибкам в боковой панели;
- фильтруем ошибки с высокой критичностью;
- применяем этот фильтр как сегмент;
- переходим в отчёт по структуре сайта;
- (для примера) выгружаем отчёт с помощью расширенного копирования;
- задача выполнена:
Задача 2
Понять, какие ошибки в принципе находятся в определённой категории сайта.
Алгоритм действий:
- открываем отчёт по структуре сайта в боковой панели;
- фильтруем по определённому разделу;
- применяем этот фильтр как сегмент;
- переходим в отчёт по ошибкам;
- (для примера) выгружаем отчёт с помощью функции экспорта;
- задача выполнена:
Очень скоро мы выпустим отдельную статью с самыми животрепещущими примерами сегментации данных :)
8. Экспорт
Представьте себе ещё одну ситуацию: вы просканировали сайт и нашли на нём 40 ошибок. Чтобы их исправить, нужно выгрузить эту информацию, обработать её и передать разработчику.
Раньше необходимо было переходить в каждый отчёт по ошибке, экспортировать его отдельно, а потом ещё чистить таблицу, так как для ошибки «Дубликаты Title» не очень важно значение скорости загрузки страницы. Мы раз и навсегда исправили эту неприятную ситуацию, разработав преднастроенные шаблоны экспорта, с помощью которых можно выгрузить необходимые отчёты (или вообще все отчёты) в два клика:
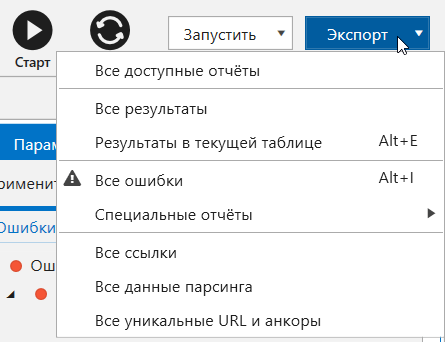
Дополнительно мы реализовали возможность выгружать такие данные:
- Все ошибки → выгружаем все отчёты по ошибкам в одну папку;
- Специальные отчёты по ошибкам → здесь собраны отчёты с удобным представлением данных по определённым ошибкам:
- Битые ссылки,
- Изображения без атрибута ALT,
- Цепочки редиректов,
- Редиректы, заблокированные в robots.txt,
- Редиректы с неправильным форматом URL,
- Цепочки Canonical,
- Canonical, заблокированный в robots.txt,
- Ссылки с неправильным форматом URL.
- Все ссылки → выгружаем отдельно все внешние и все внутренние ссылки, которые присутствуют на просканированных страницах;
- Все уникальные URL и анкоры → аналогично, выгружаем отдельно все внешние и внутренние ссылки: данные в первом отчёте группируются по URL, а во втором — сразу по URL и анкору.
Так как в новой версии можно без проблем сканировать достаточно большие сайты, мы подготовили также автоматическую разбивку .xlsx файлов, если в отчёте больше 1 млн результатов.
Помните про светлую и тёмную сторону Силы? Перед вами стоит тяжёлый выбор:
IV. Подробнее об обновлении
9. Определение индексируемых URL
Теперь Netpeak Spider разделяет страницы по степени индексируемости на 3 типа:
- Индексируемые — это HTML-документы с 2xx кодом ответа сервера, не закрытые от индексации с помощью различных инструкций (robots.txt, Canonical, Meta Robots и т.д.). Это самые важные страницы на сайте, так как они потенциально могут приносить органический трафик.
- Неиндексируемые — это HTML-документы с отличным от 2xx кодом ответа сервера или закрытые от индексации. Такие страницы зачастую не приносят трафик из поисковых систем и даже, напротив, тратят краулинговый бюджет.
- Не HTML — это остальные документы, которые имеют меньший потенциал для ранжирования в выдаче поисковых систем.
Индексируемость станет единым унифицированным понятием для инструментов и аналитики внутри программы, а большинство ошибок теперь будет определяться исключительно среди индексируемых URL (например, раньше дубликатами считались даже закрытые от индексации страницы, а теперь поиск дубликатов будет проводиться только среди индексируемых страниц).
10. Ошибки
Панель ошибок
Раньше вы могли отфильтровать только страницы с определённой ошибкой. Теперь же ошибки отображаются в виде дерева, и вы можете отфильтровать как все страницы, где есть ошибки, так и страницы с ошибками определённой критичности.
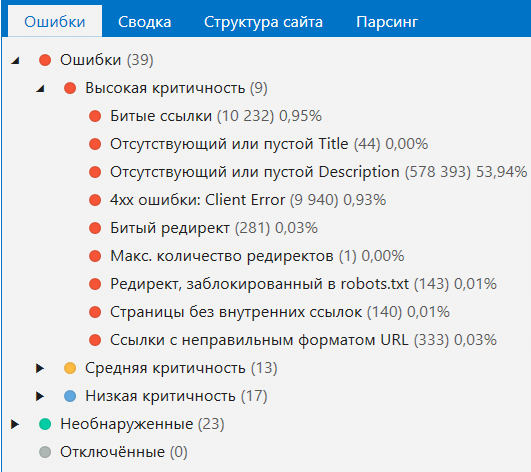
Теперь при клике на ошибку по умолчанию показываются только те колонки, которые относятся к данной ошибке. Однако, если необходимо, вы можете нажать «Показать все столбцы», чтобы получить полный отчёт по отфильтрованным URL.
Также мы реализовали описание ошибок, которое показывается при выборе определённой ошибки в нижней панели «Информация». Очень скоро мы дополним описания полезной информацией о том, чем эта ошибка грозит и как её исправить.
Кастомизация каждой ошибки
В настройках сканирования на вкладке «Ограничения» теперь можно настроить множество ошибок под себя. Например, если вы считаете, что максимальный размер изображения в 100 Кбайт — это мало, то можете увеличить это число, и при запуске нового сканирования ошибка уже будет определяться иначе.
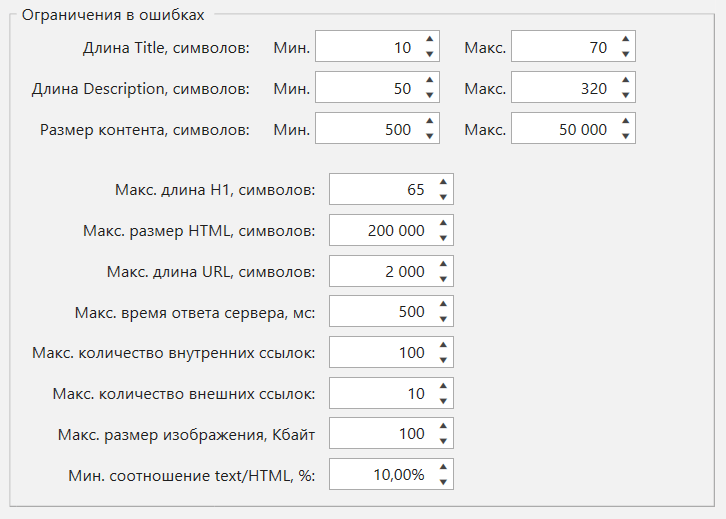
Изменения в ошибках
Добавили новые ошибки:
- Битые ссылки → показывает недоступные страницы или страницы, которые возвращают код ответа сервера 4xx и выше.
- Кодированные URL → показывает страницы, которые содержат кодированные (не ASCII) символы в URL.
Изменили некоторые старые:
- Битые изображения → теперь показывает все битые картинки, а не только те, которые отдают код ответа 4xx-5xx.
- Битый редирект → аналогично, учитывает перенаправление не только на 4xx, а на все недоступные страницы.
И, конечно же, удалили несколько устаревших ошибок:
- «Ошибка подключения» и «Другие ошибки кода ответа сервера» → теперь это учитывается в рамках ошибки «Битые ссылки».
- Отсутствующий или пустой Canonical → больше не будет предупреждать об этом опциональном теге.
Спецкнопка «Отчёт по ошибке»
В Netpeak Spider есть ошибки, по которым нужна дополнительная информация. Например, при выборе ошибки «Изображения без атрибута ALT» отфильтровываются страницы, которые содержат такие картинки, но оптимизаторам зачастую нужен отчёт именно по самим изображениям.
Потому мы сделали быстрый доступ к специальным отчётам для таких ошибок:
- Битые ссылки,
- Ссылки с неправильным форматом URL,
- Редирект, заблокированный в robots.txt,
- Canonical, заблокированный в robots.txt,
- Изображения без атрибута ALT,
- Внутренние nofollow ссылки,
- Внешние nofollow ссылки.
11. Инструменты
В версии 3.0 мы улучшили абсолютно все инструменты — давайте пройдёмся по каждому.
Расчёт внутреннего PageRank
В инструменте был полностью переработан интерфейс для более удобной работы со следующими нововведениями:
- Добавлен отдельный параметр «Внутренний PR» для каждой ссылки → изменения в инструменте базировались в основном на этой статье. Netpeak Spider считает внутренний PageRank и показывает детали расчётов по «второй формуле»:
- N – общее количество активных узлов (страниц), участвующих в расчёте;
- d – коэффициент затухания (обычно используется значение 0,85);
- L – количество исходящих ссылок.
- если PR > 1,0 → страница получает вес;
- если PR = 1,0 → страница отдаёт столько же веса, сколько и получает;
- если PR < 1,0 → страница отдаёт вес.
- Также теперь расчёт внутреннего PageRank происходит только для индексируемых URL. Таким образом, в нём больше не принимают участие изображения и другие типы файлов, отличные от HTML.
- Появился новый параметр «Вес ссылки», который показывает — вы никогда не догадаетесь! — сколько веса передаётся по каждой конкретной ссылке. Напомню, что в инструменте расчёта внутреннего PageRank вы можете удалять целые узлы, тем самым моделируя ситуацию, что было бы с PR каждой страницы, если бы ссылок на эти узлы не было. Это помогает оптимизировать внутренний ссылочный вес, если вы после моделирования перенесёте созданную структуру на сайт.
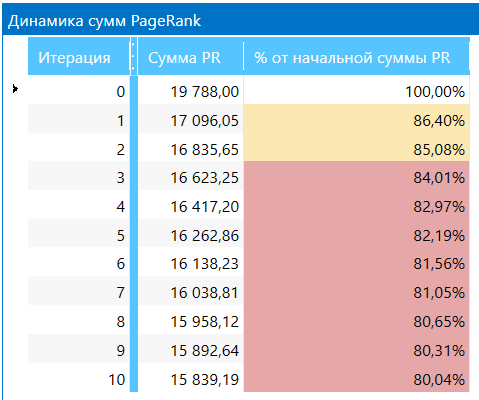
- Добавлена таблица «Динамика сумм PageRank» — на каждой итерации производится подсчёт отношения суммы внутреннего PageRank на текущей итерации к сумме на нулевой итерации. Если сумма уменьшается, значит на сайте нарушено естественное распределение ссылочного веса и присутствуют «висячие узлы», от которых неплохо было бы избавиться.
PR (A) = (1 - d) / N + d * (PR(B) / L(B) + PR(C) / L(C) + ...)
Где:
Однако сам результат (новый параметр «Внутренний PR») теперь для наглядности приводится к «первой формуле» простым умножением:
PR (первая формула) = PR (вторая формула) * N (количество страниц в расчёте)
И как результат:
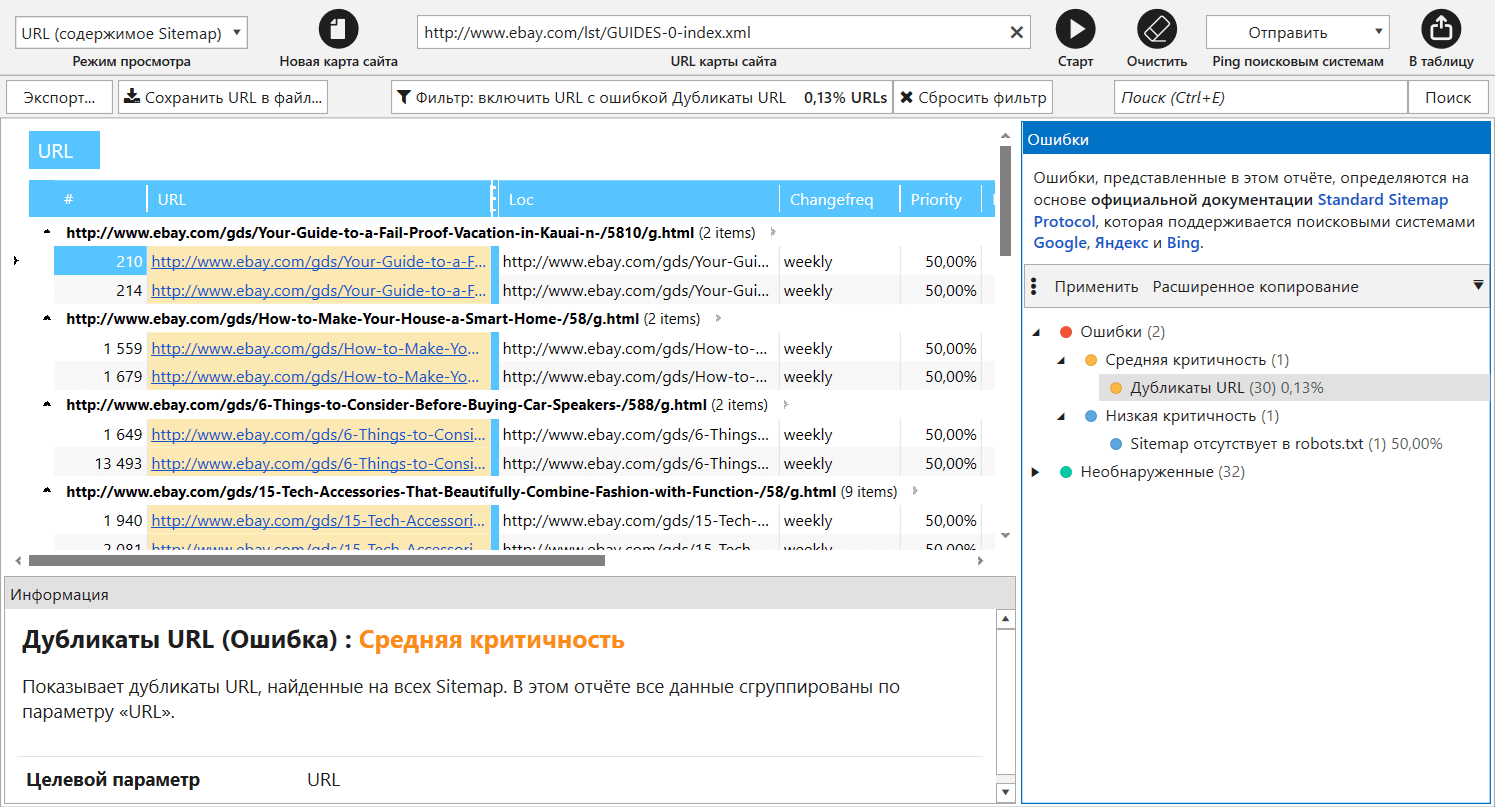
Валидатор XML Sitemap
В предыдущей версии валидатор XML-карт сайта был режимом сканирования, однако теперь мы вынесли его в отдельный инструмент для решения следующих задач:
- Парсинг ссылок из XML Sitemap с возможностью передачи их в основную таблицу для дальнейшего сканирования;
- Валидация карты сайта → здесь мы полностью переработали все ошибки (теперь их 34 штуки) и учли основные рекомендации Google и Яндекса;
- Отправка ping в поисковые системы для того, чтобы обратить их внимание на изменения в ваших файлах XML Sitemap.
Обратите внимание, что теперь правила сканирования учитываются при парсинге ссылок из XML-карт сайта. Также инструмент хранит все ваши запросы: начните вводить URL, и он подскажет, какие XML Sitemap вы анализировали ранее.
Анализ исходного кода и HTTP-заголовков
Аналогично, был полностью переработан интерфейс и добавлена вкладка «Извлечённый текст», на которой отображается весь контент страницы без HTML-тегов. Эта функция не заменяет, например, просмотр текстовой копии в Google (это более надёжный источник данных), однако это показывает, как именно Netpeak Spider анализирует текст при расчётах количества слов или символов на странице.
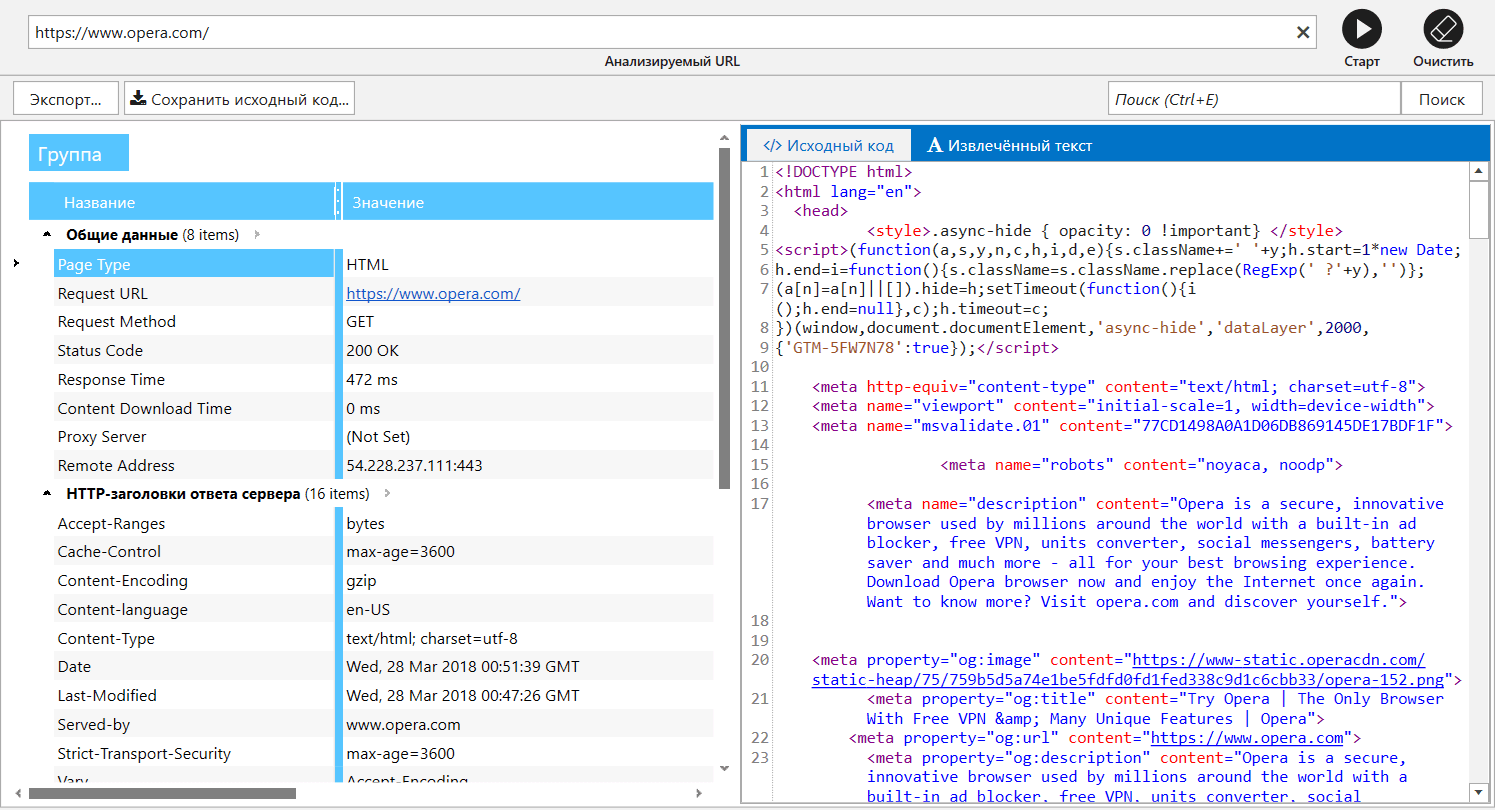
В этом инструменте также хранятся все ваши запросы, чтобы вы в будущем смогли без проблем проанализировать определённую страницу ещё раз.
Генератор Sitemap
Кроме переработки интерфейса, инструмент теперь создаёт карты сайта исключительно для индексируемых URL. Потому вы можете не волноваться, что в карту сайта попадут, например, страницы, закрытые от индексации.
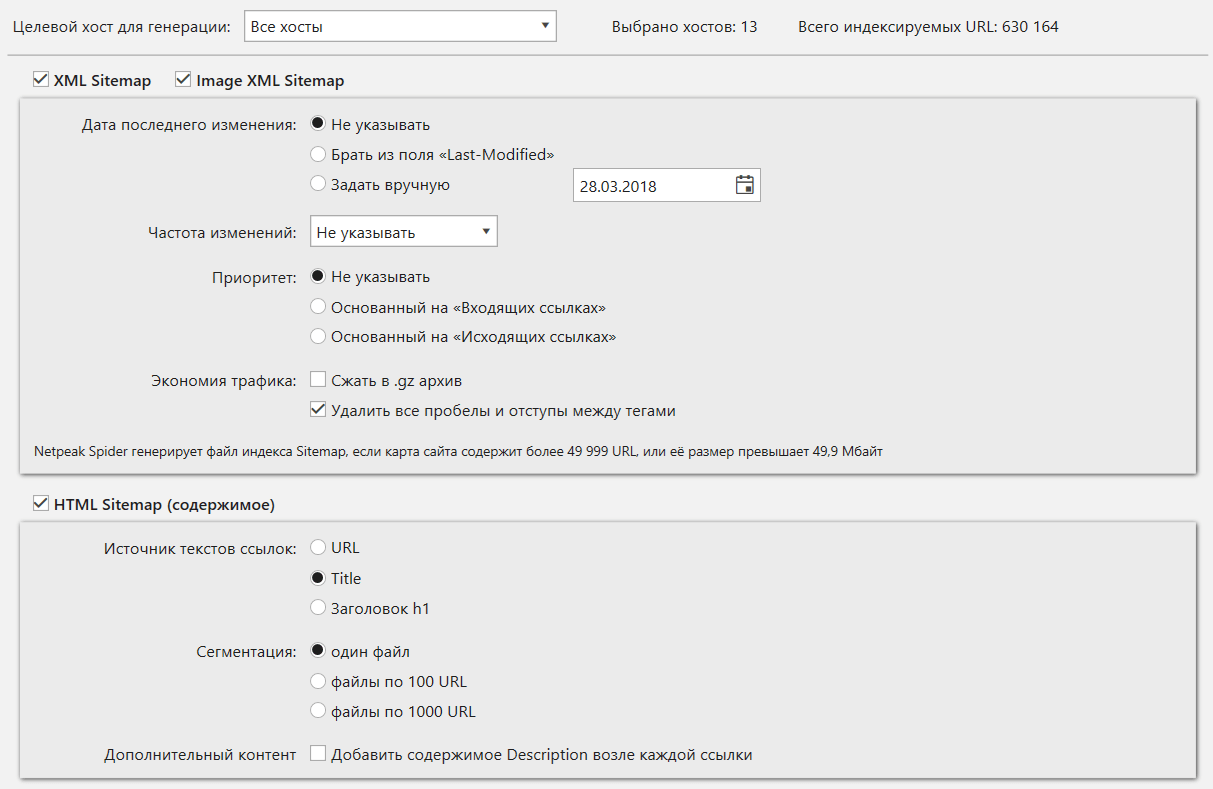
Так как в инструменте валидации XML Sitemap мы учли множество рекомендаций Google и Яндекса, то и карту сайта теперь создаём с учётом всех этих рекомендаций.
12. Кастомные шаблоны
Возможность сохранять свои личные шаблоны в некоторых функциях программы — это фишка, по поводу которой к нам обращались пользователи на протяжении всего времени существования инструмента.
Мы пошли дальше и реализовали преднастроенные шаблоны с возможностью создавать свои собственные шаблоны для:
- Настроек → такие шаблоны хранят информацию на всех вкладках настроек сканирования (кроме «Экспорт», «Аутентификация» и «Прокси») и позволяют переключаться между нужными настройками в два клика. Обратите внимание на преднастроенные шаблоны — здесь всё зависит от вашей задачи: просто просканировать сайт или сделать это «глазами робота поисковых систем».
- Фильтров и сегментов → создавайте свои шаблоны, если часто фильтруете данные по одним и тем же условиям;
- Параметров → доступ к этим шаблонам вы можете получить на вкладке «Параметры» в боковой панели. Также обратите внимание на преднастроенные шаблоны: выбирайте шаблон «Минимум», если вам необходимо в кратчайшие сроки и с минимальным потреблением ресурсов компьютера просканировать сайт и узнать основную информацию о его структуре без углубления в ошибки.
13. Виртуальный robots.txt
Если вам необходимо протестировать новый файл robots.txt и понять, как примерно его воспримут роботы поисковых систем, то вам не обойтись без настройки «Виртуальный robots.txt». При использовании этой функции вместо актуального файла robots.txt в корневой директории вашего сайта (по крайней мере, он должен там находиться) будет использоваться именно составленный вами виртуальный файл.
14. Настройки
Раздел с настройками сканирования претерпел следующие изменения:
- Наконец появилась возможность просматривать настройки прямо во время сканирования. Изменение количества потоков применится сразу же после нажатия кнопки «OK», а все остальные настройки — только после остановки. Обратите внимание: не обязательно сканировать сайт заново, если вам необходимо поменять какие-то настройки. Если для вас это не критично, то вы можете поменять их в середине сканирования, и с этого момента Netpeak Spider начнёт их учитывать — гибкость 110 уровня :)
- Добавлены настройки экспорта → так как отчётов в программе стало в миллион раз больше, то для удобства их генерации были реализованы настройки, с помощью которых можно поменять формат и локаль генерируемых файлов, управлять выгрузкой ошибок и т.д.
- Переделана вкладка «User Agent» → реализовано дерево User Agent, поиск по нему, а также добавлены несколько преднастроенных User Agent, о которых просили наши клиенты.
- Настройки одного прокси превратились в список прокси → здесь, по аналогии с Netpeak Checker, добавлен целый инструмент валидации списка прокси. Если вам нужно использовать одну прокси (например, для доступа к сайту, закрытому по IP), то действуйте по-старому — добавляйте всего одну прокси в список. Если же вам необходимо имитировать работу нескольких пользователей с сайтом или списком URL — добавляйте множество прокси, которые будут сразу же проверены на доступность.
- Реализованы преднастроенные шаблоны настроек для самых популярных случаев: обычного сканирования сайта (получаем максимальное количество URL), сканирования в стиле Googlebot (учитываем максимум инструкций по индексации) или сканирования внутри определённого раздела.
15. Совмещение нескольких режимов сканирования в один
Признаюсь, мы не нашли такого функционала на рынке десктопных краулеров. Раньше для работы с программой вам необходимо было выбирать режим сканирования — например, вы хотите просканировать весь сайт или только какой-то список URL. Теперь же мы снимаем с вас тяжёлый груз этого выбора! :)
В новой версии программы URL для сканирования можно добавлять следующими способами:
- Сканируя сайт → просто добавьте нужный адрес в поле «Начальный URL» и нажмите кнопку «Старт»: страницы будут добавляться по мере продвижения краулера по сайту.
- Вручную → этот способ откроет отдельное окно с текстовым полем для ввода списка страниц, где каждый URL должен быть с новой строки.
- Из файла → мы серьёзно переработали эту функцию и добавили возможность импортировать URL из файлов с расширениями .xlsx (Microsoft Excel), .csv (comma-separated values), .xml (Extensible Markup Language), .nspj (проект Netpeak Spider) и .ncpj (проект Netpeak Checker).
- Из XML Sitemap → этот способ откроет инструмент валидации XML Sitemap, через который уже можно выгрузить URL для сканирования в основной таблице.
- Из буфера обмена → просто нажмите комбинацию Ctrl+V, находясь в главном окне программы, и список URL из буфера обмена добавится в таблицу, а в уведомлении будет приведена краткая информация (что успешно добавилось, что уже есть в таблице, а что не добавилось по причине несоответствия стандартному формату URL).
- Drag and Drop → вы можете просто перенести проект или любой файл с вышеуказанным расширением из папки прямо в основную таблицу: Netpeak Spider проанализирует файлы и загрузит необходимые данные.
Обратите внимание, что теперь все URL, которые вы загружаете в программу, будут идти в том порядке, в каком они были изначально. Это облегчит поиск данных и позволит без проблем сравнивать результаты сканирования за какие-то периоды.
Важно!
Совмещение режимов сканирования в один даёт большую гибкость, однако может запутать в некоторых ситуациях. Потому давайте разберёмся, как будет вести себя программа в таких случаях:
- Нажатие на кнопку «Старт»:
- Если введён адрес в поле «Начальный URL», и таблица пустая → Netpeak Spider будет сканировать весь сайт, начиная с этого URL.
- Если введён адрес в поле «Начальный URL», и таблица уже заполнена URL-ами → программа будет сканировать сайт из поля «Начальный URL» и дополнительно просканирует введённые в таблицу адреса, взяв их исходящие ссылки для дальнейшего краулинга (интересный лайфхак, если хотите начать сканировать сайта из совершенно разных точек).
- Если поле «Начальных URL» пустое, и таблица заполнена URL-ами → просканируются только введённые в таблицу страницы (аналог старого режима сканирования «По списку URL»). Разумеется, данные будут получаться только по тем URL, по которым ещё нет результатов.
- Нажатие на кнопку «Рестарт»:
- Если введён адрес в поле «Начальный URL»→ программа удалит полностью все результаты сканирования и начнёт сканировать сайт заново, причём не важно, были ли в таблице добавленные вручную URL или нет.
- Если поле «Начальных URL» пустое, и таблица заполнена URL-ами→ будут повторно пересканированы все добавленные URL.
Как вы могли заметить, очень большую роль в поведении программы играет тот факт, есть ли в поле «Начальный URL» какой-то адрес или нет.
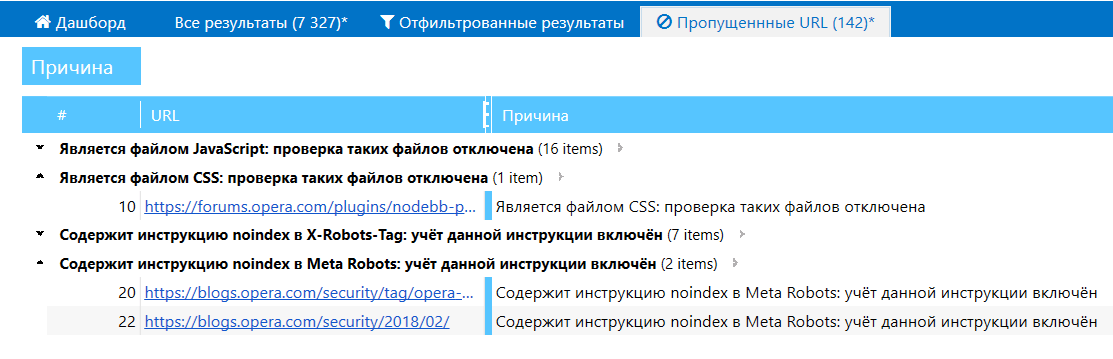
16. Таблица пропущенных при сканировании ссылок
«Почему-то не сканируется сайт», — одна из самых частых проблем у наших клиентов при работе с Netpeak Spider. Теперь мы предлагаем её решать с помощью двух нововведений:
- Адрес, который вы вводите в поле «Начальный URL» всегда будет добавляться в таблицу. Таким образом, вы получите информацию, если этот URL редиректит на какой-то другой сайт или просто недоступен в данный момент.
- Мы реализовали вкладку «Пропущенные URL», которая появляется только в тех случаях, если при сканировании были проигнорированы какие-то страницы. Здесь будут отображаться URL страницы и причина, по которой они были пропущены: например, вы включили учёт инструкций из файла robots.txt, применили правила сканирования или отключили проверку какого-то типа контента.
17. Быстрый поиск по таблице
Во всех интерфейсах программы реализована возможность быстрого поиска по соответствующей таблице — просто нажмите Ctrl+E и введите поисковый запрос:
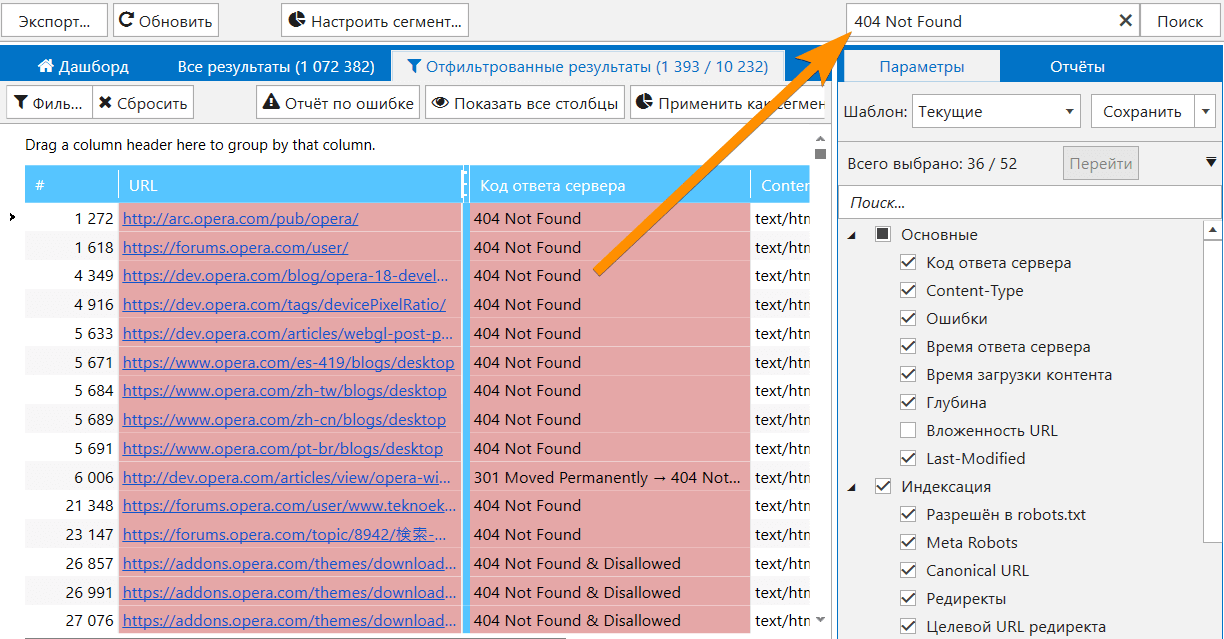
Будьте внимательны, так как эта функция ищет по всем колонкам в таблице. Если вам необходимо отфильтровать данные по какому-то определённому параметру или сегментировать все данные, то воспользуйтесь соответствующими функциями:
- Ctrl+F→ настройка фильтра;
- Ctrl+Shift+F → настройка сегмента.
18. Модуль «Анализ»
Теперь некоторые тяжёлые расчёты делаются после окончания или при остановке сканирования. Если у вас включены соответствующие параметры, то вы увидите окно, в котором сможете отменить анализ данных. Именно с помощью модуля «Анализ» вы сможете проанализировать результаты в любое время: например, после удаления каких-то результатов для пересчёта внутреннего PageRank или количества входящих ссылок.

После окончания/остановки сканирования анализируются следующие данные:
- проверяются все дубликаты;
- подсчитывается количество входящих ссылок у каждого URL;
- проверяются цепочки Canonical;
- рассчитывается внутренний PageRank.
19. Модуль «База данных»
Все массивы тяжёлых данных были вынесены и сведены в единый модуль — это ещё одна уникальная особенность нового Netpeak Spider. С помощью этого модуля вы можете просматривать огромные списки:
- входящих, исходящих, внутренних и внешних ссылок,
- изображений,
- ошибок,
- редиректов,
- Canonical,
- заголовков H1-H6.
В модуле реализовано удобное переключение между целевыми параметрами, а также пагинация (от 50 000 до 1 000 000 результатов на одну страницу в зависимости от количества свободной оперативной памяти), которая позволяет просматривать неограниченное количество данных:
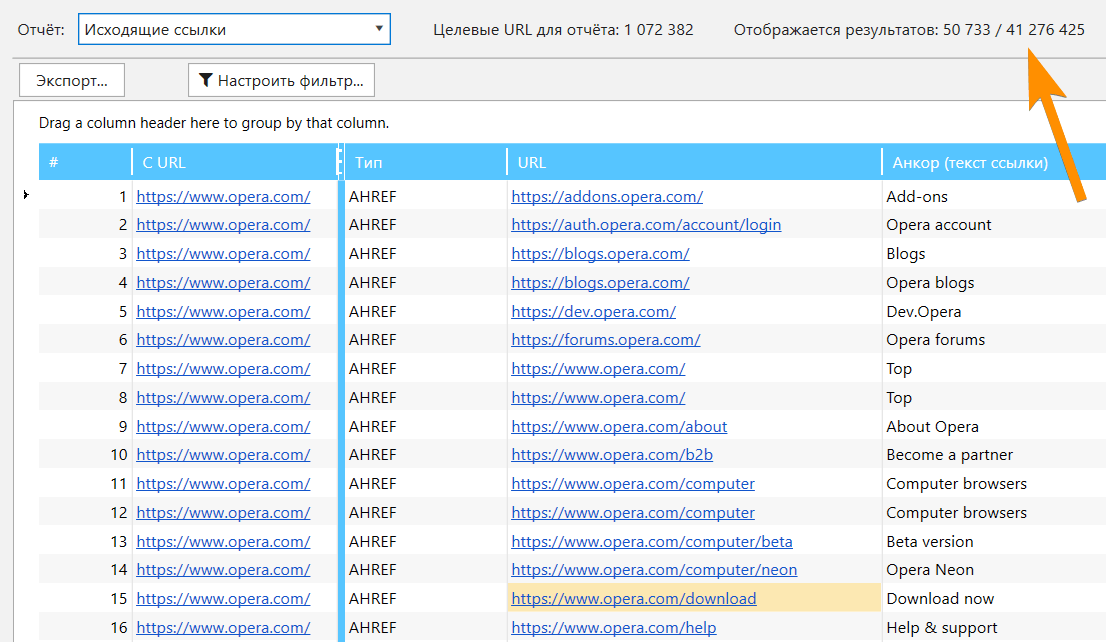
Обратите внимание, что при использовании фильтра модуль будет применяться не только на текущей странице пагинации, а на все данные, потому такая фильтрация может занять много времени.
20. Параметры
Вкладка в боковой панели
Установка анализируемых параметров была перенесена из настроек сканирования на вкладку «Параметры» в боковой панели. Теперь, аналогично Netpeak Checker, здесь можно осуществить поиск по всем параметрам, а также выбрать параметр и увидеть подробную подсказку о нём в блоке «Информация».
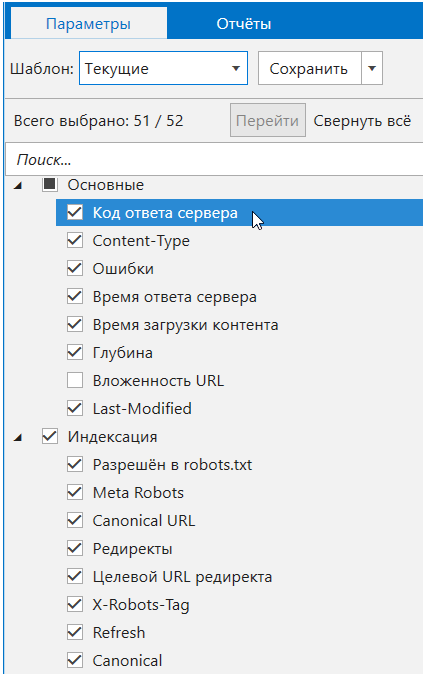
Если у вас уже есть результаты в основной таблице, то можете нажать на параметр (или воспользоваться кнопкой «Перейти» на этой панели), чтобы быстро перейти к соответствующему параметру в текущей таблице.
Также реализованы преднастроенные шаблоны параметров для самых популярных случаев:
- минимальный (для быстрого обхода сайта с целью сбора всех URL);
- рекомендуемый (оптимальный для большинства случаев — позволяет находить максимум типов ошибок);
- для PageRank (тот минимум параметров, который нужен для расчёта);
- все доступные параметры.
Изменения в параметрах
Добавили новый параметр «Вложенность URL», который показывает количество сегментов в URL анализируемой страницы. В отличие от параметра «Глубина», вложенность является статическим показателем и не зависит от начального URL. Например, у страницы https://example.com/category/ вложенность URL равна 1, а у страницы https://example.com/category/product/ — 2 и т.д.
Изменили некоторые старые параметры:
- «Хеш блока Body» стал называться «Хеш текста» и теперь позволяет проводить поиск дубликатов не по всему HTML-коду блока body, а только по его текстовому контенту.
- Цепочки Canonical теперь работают аналогично цепочкам редиректов.
21. Фильтры
Здесь мы переработали интерфейс, добавили поиск по параметрам и реализовали возможность создавать свои шаблоны:
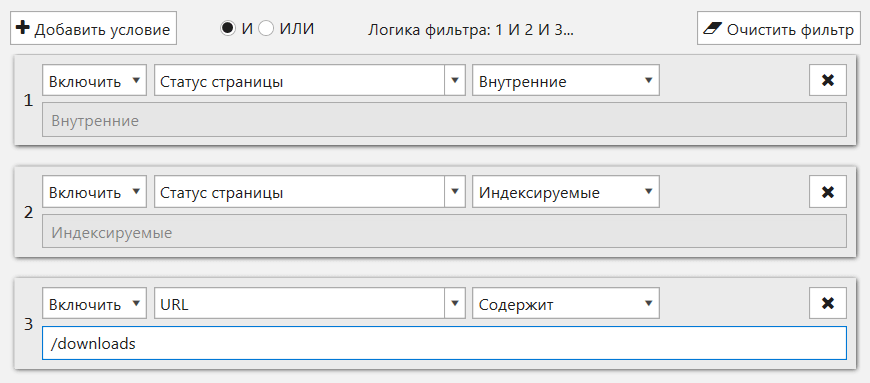
Напомню, что на «Дашборде» и на вкладках «Ошибки», «Сводка», «Структура сайта» и «Парсинг» находятся преднастроенные фильтры, которые ведут на вкладку «Отфильтрованные результаты» с соответствующим применённым фильтром. Именно на ней вы найдёте функцию «Применить как сегмент», которая позволит ограничить текущее представление данных и по-другому взглянуть на отчёты.
Скрыть остальные изменения и перейти к сравнению с конкурентами
V. Остальные изменения
Здесь я кратко опишу другие улучшения, которые произошли в Netpeak Spider 3.0:- Мониторинг лимита памяти → реализована проверка объёма свободной оперативной памяти и места на жёстком диске: и там, и там для работы программы должно быть не менее 128 Мбайт. Если лимит обнаружен, то сканирование останавливается, и данные остаются в сохранности.
- Выбор начального URL → при начале ввода всплывает подсказка (аналогично браузеру Chrome), где содержится список URL, с которых успешно начиналось сканирование.
- Кроме обычной загрузки проекта, добавлено меню «Проект» → «Последние проекты», откуда можно открыть последний проект, с которым вы работали (сочетание клавиш Ctrl+Shift+T).
- В контекстное меню добавлен пункт «Открыть URL в сервисе», который позволяет открыть выбранный URL в сервисах Google, Bing, Yahoo, Яндекс, Serpstat, Majestic, Open Site Explorer (Mozscape), Ahrefs, Google PageSpeed, Mobile Friendly Test, Кеш Google, Wayback Machine (Web Archive), W3C Validator или во всех сразу (очень весёлая для вашего браузера функция). Также в контекстном меню появился пункт «Открыть robots.txt», который (по случайному совпадению) открывает файл robots.txt в корневой папке выбранного хоста.
- При клике на любую ячейку таблицы в панели «Информация» будет развёрнута та же таблица с проанализированными параметрами, только вертикально и конкретно для этого URL.
- Мультиоконность → теперь есть возможность открыть несколько окон Netpeak Spider и запустить отдельные пробивки для каждого окна.
- Специальные статус-коды → это дополнения к коду ответа сервера типа Disallowed / Canonicalized / Refresh Redirected / Noindex / Nofollow: теперь они отображаются всегда, не зависимо от того, хотите ли вы учитывать правила индексации или включили ли соответствующий параметр. Отфильтровать по соответствующему статусу страницы можно на вкладке «Сводка» в боковой панели.
- Функция «Пользовательский поиск и извлечение данных» была переименована в «Парсинг» → теперь она работает аналогично другим внутренним таблицам. Убрано разделение на поиск и извлечение (теперь всегда собираются данные). Также можно включать/выключать парсинг как любой другой параметр в боковой панели на вкладке «Параметры».
- Добавлено сохранение позиций всех окон и панелей → и если что-то пойдёт не так, вы всегда сможете сбросить их позиции с помощью меню «Окно» → «Сбросить все позиции», «Сбросить позиции окон» или «Сбросить позиции панелей».
- Сделана миграция сохранённых проектов в версии Netpeak Spider 2.1 в проекты 3.0.
Конечно же, не обошлось и без удаления некоторых функций:
- Режим сканирования «По выдаче Google» → не расстраивайтесь, так как скоро в Netpeak Checker будет добавлен специальный инструмент для решения похожих задач.
- Быстрые настройки → теперь все настройки можно просматривать во время сканирования, потому этот функционал потерял смысл.
- Режим сканирования «По разделу» → он превратился в галочку в настройках сканирования на вкладке «Основные».
VI. Сравнение с конкурентами
Друзья, пришло время изменить баланс Силы, который так долго существовал в Галактике. Сравнивать мы будем не по функционалу (это мы сделаем чуть позже и обязательно вам расскажем), а по трём техническим параметрам:
- Потребление оперативной памяти.
- Потребление памяти на жёстком диске.
- Скорость сканирования.
Чтобы сделать сравнение более показательным, будем делать проверку на примере небольшого сайта (10 000 URL) и большого сайта (100 000 URL). Мы изначально хотели добавить в сравнение ещё 1 млн URL, но, признаемся, не все программы нормально выдержали даже 100 тысяч.
Само сравнение мы сделаем в двух частях — сопоставим две версии нашего продукта, а также Netpeak Spider 3.0 с основными конкурентами на мировом рынке.
Сравнение с версией 2.1
Как и следует юному падавану, ученик (3.0) должен превзойти учителя (2.1) — только так он сможет показать свой истинный потенциал.
Небольшой сайт (10К страниц)
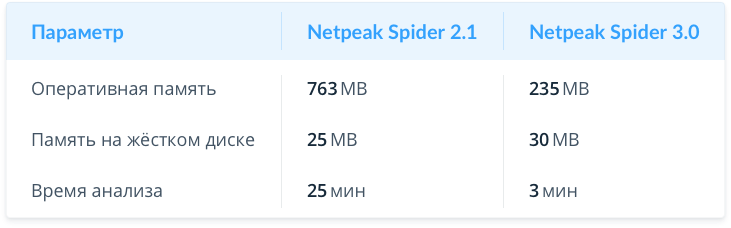
Как видите, при анализе небольших сайтов мы сократили потребление оперативной памяти в 3 раза и ускорили сканирование в 8 раз.
Большой сайт (100K страниц)
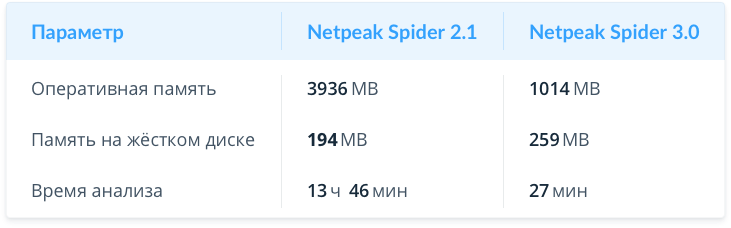
Здесь и раскрываются сильные стороны новой версии — потребление оперативной памяти ещё сильнее уменьшилось (в 4 раза), а сканирование заняло в 30 раз меньше времени: теперь вы знаете, что за число мы используем при сравнении версий :)
Сравнение со Screaming Frog SEO Spider, WebSite Auditor и Sitebulb
Признаюсь, я не хотел бы лишний раз рекламировать конкурентов, однако наши пользователи всегда спрашивают, чем мы от них отличаемся — так давайте же сравним Netpeak Spider 3.0 с известными продуктами (Screaming Frog SEO Spider, WebSite Auditor) и достаточно молодым детищем наших великобританских коллег (Sitebulb)!
Кстати, недавно Screaming Frog SEO Spider выпустил обновление, которое должно было приблизить их продукт к успешному краулингу огромных сайтов. И нам было просто интересно, как же эти новые режимы работают — потому раскроем их секреты тоже.
Сразу оговорюсь, что для сравнения мы приводили настройки программ к максимально похожим и сканировали одинаковые сайты — для нас важно показать реальную ситуацию. Лучшие результаты отмечены зелёной плашкой, а худшие — красной.
Небольшой сайт (10К страниц)

По потреблению оперативной памяти лидер Netpeak Spider (ближайший конкурент потребляет в 2 раза больше), а по скорости сканирования мы идём наравне со Screaming Frog SEO Spider (в режиме Memory).
Большой сайт (100К страниц)
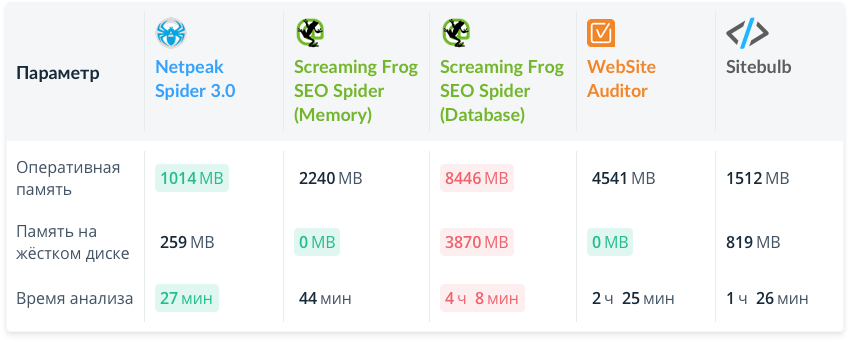
Заметно, что зелёный цвет тяготеет к левой части таблицы :) В этом случае у нас самое быстрое сканирование, которое потребляет меньше всего оперативной памяти.
Хочу заострить внимание на интересный момент — почему-то Screaming Frog SEO Spider при переключении с режима Memory на режим Database начинает потреблять намного больше оперативной памяти (нонсенс какой-то), учитывая, что остальные технические характеристики тоже страдают (что видно по сосредоточению красного цвета в таблице).
Зарегистрируйтесь, если вы ещё не с нами
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд!
VII. Коротко о главном
Netpeak Spider в версии 3.0 превратился в супербыстрый инструмент, позволяющий без проблем работать с большими сайтами и проводить их комплексную SEO-аналитику.
Самые важные улучшения:
- Скорость сканирования до 30 раз выше, чем в 2.1.
- Оптимальное потребление оперативной памяти.
- Возможность продолжения сканирования после загрузки проекта.
- Удаление URL из отчёта.
- Перепробивка URL или списка.
- Изменение параметров в ходе сканирования.
- Сегментация данных.
- Отчёт по структуре сайта.
- Дашборд (информация о ходе сканирования и диаграммы после окончания сканирования).
- Экспорт 10+ новых отчётов и 60+ отчётов об ошибках в два клика.
- Определение индексируемых URL.
- Специальные отчёты по каждой ошибке.
- Полностью переработаны инструменты «Расчёт внутреннего PageRank», «Валидатор XML Sitemap», «Анализ исходного кода и HTTP-заголовков» и «Генератор Sitemap».
- Кастомные шаблоны настроек, фильтров / сегментов и параметров.
- Возможность настроить виртуальный robots.txt.
- Совмещение всех режимов сканирования в один.
- Таблица пропущенных при сканировании ссылок.
- Быстрый поиск по таблице.
- Отложенный анализ тяжёлых данных.
- Новая вкладка «Параметры» с поиском и переходом к параметру в таблице.
- Мониторинг лимита памяти для сохранности данных.
- А также сотни других улучшений…
По сравнению с версией 2.1 мы улучшили потребление оперативной памяти в 4 раза и уменьшили время сканирования в 30 раз (на примере пробивки большого сайта). При сравнении с конкурентами мы во всех случаях выигрываем по количеству потребляемой оперативной памяти и скорости сканирования.
В заключении хотел бы сказать вам искреннее спасибо, что не побоялись и дошли до этого пункта сквозь огонь, воду и медные трубы!
В ответ мы уже работаем над версией Netpeak Spider 3.1, в рамках которой собираемся решить несколько животрепещущих проблем в области SEO-краулинга сайтов. Также в разработке находится Netpeak Checker 2.2 с новым интересным функционалом.
Мы очень много сил вложили в этот релиз, потому ждём от вас комментариев и фидбека ;)
Да пребудет с вами Сила краулинга!


