What Is TF-IDF, and Why Does It Matter for SEO?
How to

The human mind is a wonderful thing. When your colleague tells you to ‘run the topic by me’ first before going to your boss, you know that they mean explaining the topic to them first and not literally jogging. You determined what your friend meant by looking at the context in which they gave the statement.
In a way, this is how search engines determine whether or not a post is relevant to a search query. Gone are the days you would have to sift through a long list of posts that are irrelevant to your search, thanks to Natural Language Processing algorithm that does this.
In this article, Owen Baker, Senior Communications Manager at Voila Norbert is going to discuss exactly what the term Frequency-Inverse Document Frequency algorithm is all about and how it applies to SEO. But first, let’s get our definitions in order.
- 1. What is TF-IDF?
- 2. How Does TF-IDF Work For SEO?
- 3. The Move From Keyword Density to Semantic Search
- 4. How To Use TF-IDF to Improve SEO Content
- Let’s Recap
1. What is TF-IDF?
To understand what TF-IDF means, you need to get a good grasp of basically two concepts. First is the term frequency, or the TF in the formula. The second part is the inverse document frequency or IDF.
The first concept is fairly easy to understand. If you want to know what the TF is for the word ‘marketing’ in a document, for example, all you’d need to do is count the number of times that word appears in that document. So let’s say it appears 15 times. The TF for ‘marketing’ would then be 15.
The second concept, the IDF, is a bit more complicated. If you look for the word ‘marketing’ in 100 documents and find it in ten, then its IDF is log (10).
To get the TF-IDF score, just multiply the TF value by the IDF value:

When multiplied by the IDF, the TF gets lower for commonly used words and higher for unique topic-identifying terms. A bit confused? Let me explain.
2. How Does TF-IDF Work For SEO?
I mentioned earlier that search engines use the TF-IDF formula to determine the relevance of a post with respect to a search query. Let’s take a look at how exactly it does it. Let’s say we have an article where these are the ten most commonly used terms: email marketing, business, Internet, online, profit, sales, money, products, leads, and conversions.
The search engine then checks a list of predetermined articles, called the corpora, to determine what the article is about. In this case, the corpora could be business-related articles since many of the terms above sound ‘business-like.’
From this process, the engine sees the terms business, profit, sales, money, and products are present in many of the documents. So now, it’s left with the terms email marketing, Internet, online, leads, and conversions. These are the unique topic-identifying terms.
By knowing these terms, the engine now knows what the article is about: email marketing to drive leads, and conversions. If this article is useful to a particular search query, it will appear in search results.
3. The Move From Keyword Density to Semantic Search
It wasn’t always like this. Before counting co-occurrences, or using context to understand the meaning of keywords, Google matched query keywords to determine which pages should appear in search engine results.
So for instance, if you search for the term ‘dog’, Google would rank your page based on the number of times the term appears in your content. The keyword density can be calculated by dividing the number of times the keyword appears by the page’s total word count. The result is then multiplied by 100.
So for example, if a blog post has 1,000 words, and a keyword appears ten times, the article has a keyword density of 1%.
The idea is if you took that blog and another one with a keyword density score of 2%, the second page would outrank the other on Google search results based on their keyword density. It’s either that or you needed to score a specific keyword percentage to get higher Google rankings. That number you needed to score a bullseye on, however, was unknown until Google itself confirmed it actually doesn’t exist.
The result, however, was many SEO specialists believed they could ‘trick’ the search engine just by stuffing keywords in their pages. And for a time they succeeded, until Google, with all its ingenuity, evolved.
Now, keyword density is less important. The hot topic for SEO experts is semantic search, and Google search results changed completely. To illustrate, before Google’s shift to semantic search, everytime you typed in ‘how big is an elephant?’ the search engine would seek to match the specific keywords from the phrase ‘how big is it’, and return webpages with those exact keywords. The result? You’d probably have to sift through too many results before you actually found a link that answered your question.
With semantic search, Google basically discerns searcher intent by looking at user search history, user location, global search history, and spelling variations. So when you type, ‘how big is an elephant?’ Google returns results that directly answer your question.
It’s not hard to imagine why Google would want to pursue semantic search instead. Semantic search, after all, seeks to understand user intent, which means semantic search actually gives users the best search experience possible.
To put it simply, Google’s mission is clear: to organize the world’s information and make it universally accessible and useful. Since that is unlikely to change in the near future, SEO experts had better adapt if they don’t want to be left behind.
4. How To Use TF-IDF to Improve SEO Content
Sure, Google is smart, but, as I said, the human mind is amazing. This means that you, too, can ‘evolve’ (or your strategies at least) by using TF-IDF to your advantage. To improve SEO content with it, here’s what you can do:
- Check the top 10 results for your target keyword(s)
- Identify the terms that frequently occur in those articles, the context in which they usually appear, and relationships between those words
- Think of ways to add all these identified key terms to your article
- Write and publish your content
- Check the relevance of your published content
With Netpeak Checker you can scrape the top pages in the SERP to find missing keywords, and include them in your content. You can also check how you’re doing as the tool can compare the relative presence of these words in top-ranking articles in terms of TF-IDF scores. To do so, follow these steps:
- Launch Netpeak Checker, go to SE Scraper built-in tool.

- Enter the list of queries. Don’t forget to place each new query on a new line.
- If you want to scrape Google search engine, go to the ‘Settings’ tab, and tick the right item.
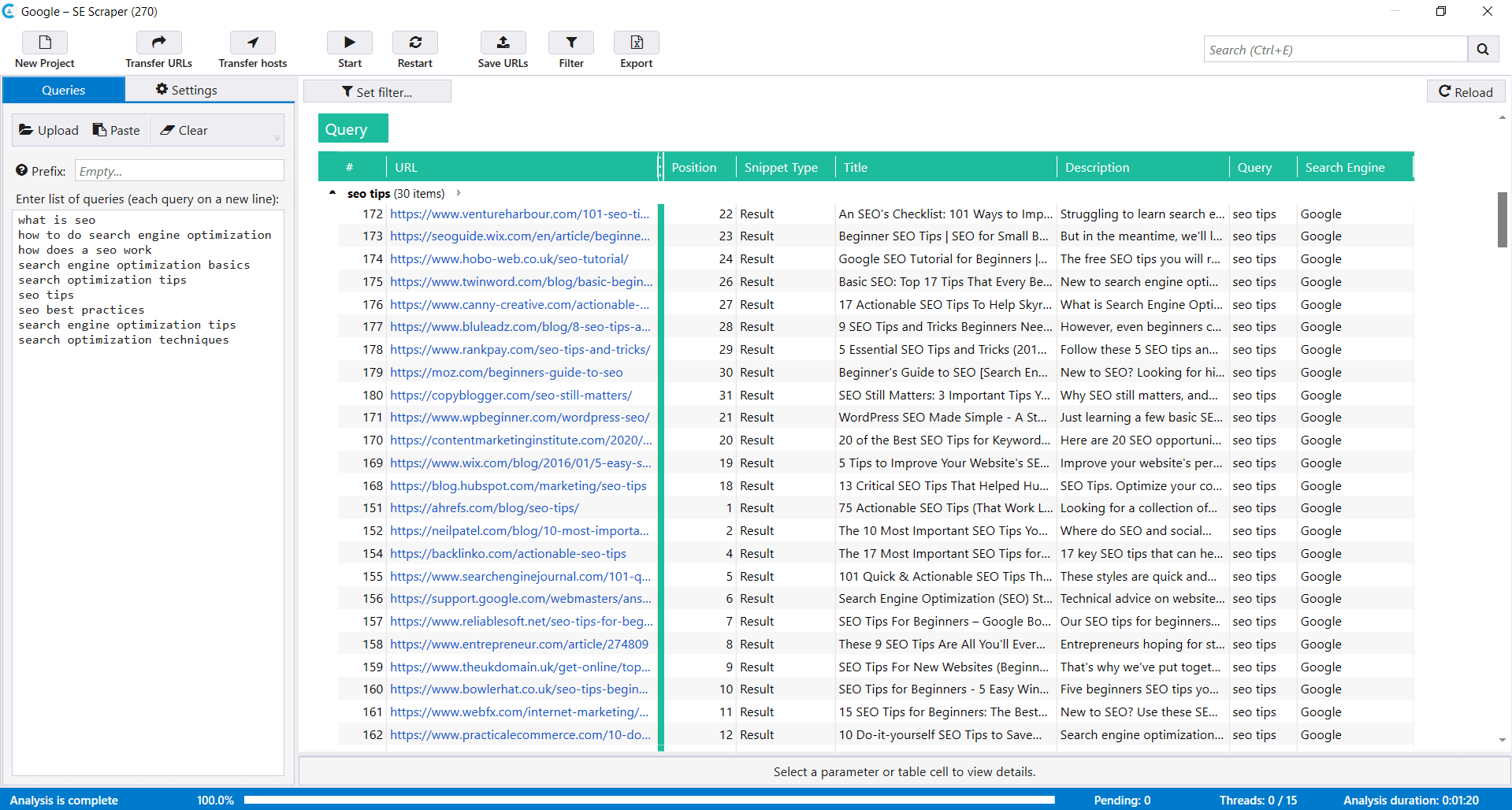
- Hit the ‘Start’ button to start scraping. In a few seconds, you can approach the results.
Let’s Recap
TF-IDF is, for the time being, here to stay. But don’t give up on improving SEO content and just blame Google for your woes. There is, after all, a way to take advantage of TF-IDF to improve SEO content.
The key to succeeding is simple – understand how TF-IDF works and follow the tips I gave you. If you do these things, there’s no reason you can’t see your content perform well in search engine results.


