What Is a Web Crawler? | How Web Spiders Work
Site Audit Issues

Content:
- A Web Crawler Definition
- Search Indexing in a Nutshell
- How Does Web Crawling Work
- Why Do They Call Web Crawlers 'Spiders'?
- Should Web Crawlers Always Be Able to Access Web Properties?
- Web Scraping vs. Web Crawling: What's the Difference?
- How Do Web Crawlers Help Improve SEO Stats?
- How Does Netpeak Spider Work as a Website Crawler?
- Takeaway
Web crawling is an essential part of SEO as it helps you see which issues on your website need fixing. In this post, we'll dig deeper into the meaning and importance of web crawlers and show you why Netpeak Spider is one of the most powerful tools you can use for that purpose.
A Web Crawler Definition
A web crawler, spider, or search engine bot is a tool that retrieves and indexes content from the Internet. These bots learn about the content and purpose of most pages to use it when necessary.
They use crawler bots to gather data. Afterward, a search algorithm is applied to the collected data. This enables search engines like Google to provide relevant responses to users' search queries. The responses come in the form of a webpage list that users see after entering a search query into Google, Bing, or similar search engines. To properly categorize and sort these links by relevance and topics, the site crawling tool detects the page's title, description, and some of the on-page content.
However, with the huge number of online websites and pages, it can be complicated to tell if all the relevant information has been properly indexed. To figure this out, a crawler bot starts its research with a set of known pages, follows hyperlinks from those to other pages, and repeats the same on the newer pages it visits.
Search Indexing in a Nutshell
What is indexing, then? It’s a process that focuses mainly on the text (especially keywords) that appears on a page as well as the metadata of that page. When search engines index a page, they add most words from the page to the index (except for "a," "an," and "the" in Google's case, for instance).
As you enter a particular query using those words, Google or another search engine goes through its index of all the pages where it can find these words and picks the most relevant ones. Those pages will show up in your search results.
How Does Web Crawling Work
Since it's impossible to know how many pages there are on the web, crawler bots start their checkups from a seed, i.e., a list of known URLs. As they crawl those pages, they will stumble upon hyperlinks to other websites or pages, which they will add to their crawling list afterward.
And, instead of crawling every single page on the internet (which will supposedly take forever to complete), a web crawler follows specific policies and algorithms to be more selective about the target pages, the crawling order, and the frequency of future crawls and double-checks.
Let's look at the main ones:
- The relative importance of each webpage. Web crawlers usually don't check the entire list of publicly available pages; instead, they select which pages to crawl first based on the number of other pages linking to that URL, the number of page visitors, etc. The main reason for that is that if a page gets cited by plenty of other sources and has a lot of visitors on a regular basis, it is more likely to contain high-quality, reliable information. Hence, it's crucial to get that page indexed in the first place.
- Revisiting webpages. The content you see online can get updated, deleted, or moved to a new location. Hence, crawler tools will need to revisit pages from time to time to make sure the search engine has indexed the latest version of that content.
- Robots.txt requirements. Another way web crawlers decide which pages to analyze is based on the robots.txt protocol. Before crawling a page, the search engine bots check the robots.txt file hosted by the page's server. A robots.txt file specifies the rules for any bots accessing the hosted app or website, which define the pages the bots can crawl and which links to follow.
Although web crawlers within various search engines will behave slightly differently from one another, the final goal remains the same, which is to download and index content from the pages.
Why Do They Call Web Crawlers 'Spiders'?
Since some people still call the Internet the World Wide Web, it was natural to start calling search engine bots "spiders" as they crawl all over the Internet — just like a real spider in the web.
Should Web Crawlers Always Be Able to Access Web Properties?

In a nutshell, it's a decision to be made by a web property, which depends on several factors: the desire to keep all the pages accessible, the number of pages and the amount of content they store, whether any auto-generated pages are only helpful to a limited number of users, etc.
Web Scraping vs. Web Crawling: What's the Difference?
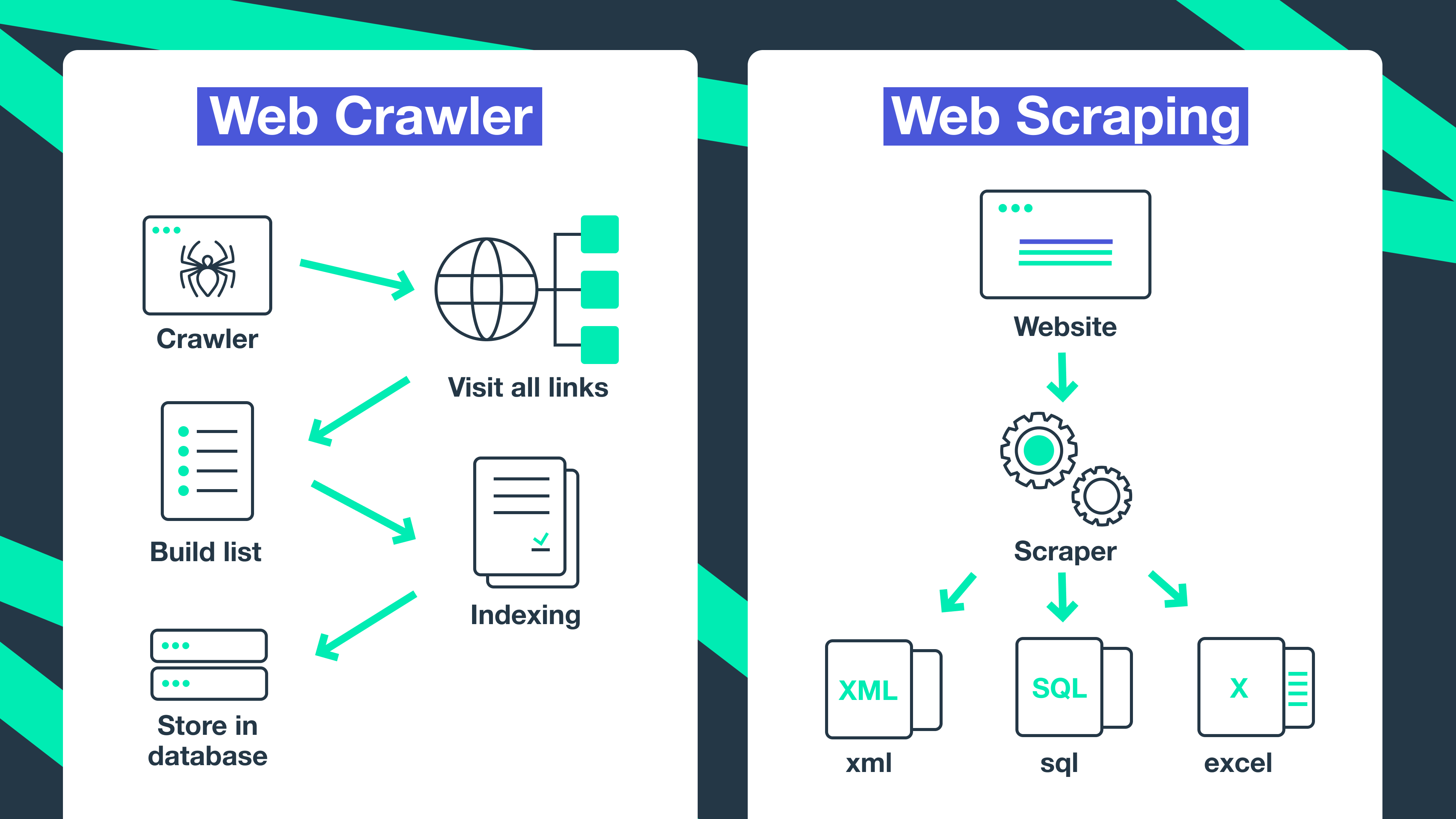
Another term you may stumble upon while working with page crawling is web/data/content scraping. This is the process when a bot downloads the website's content without permission, usually with a malicious purpose.
Data scraping is usually much more targeted compared to crawling. Web scrapers may "hunt" specific pages or websites, while crawler tools keep following links and crawling pages continuously.
Another thing is that web scraper bots can disregard the strain put by them on web servers, while web crawlers always follow the robots.txt file and limit their requests in order not to overtax the server.
How Do Web Crawlers Help Improve SEO Stats?

Without page crawling bots, you can't index a website, so it won't appear in search results. Hence, you'll not get enough organic reach, which will negatively impact your overall website performance, result in a sales decrease (if you're a product or service provider), and generally won't let your website or business grow the way you want it to.
How Does Netpeak Spider Work as a Website Crawler?

If you have yet to use a web crawler or have just launched a website and need to know how to make it work, you may start improving your optimization strategy with Netpeak Spider. It's a multi-functional analytical tool that can crawl as many pages as you need in a few moments and provide a detailed overview of the critical parameters, together with a list of issues detected along the way.

When it comes to analyzing your website, Netpeak Spider, like any other site crawlingtool, may stumble upon a number of problems that will prevent a particular page from indexing. Here's the list of on-page errors and problems that may cause such an inconvenience:
- Indexation instructions (robots.txt, robots meta directives)
- Canonical loops
- Authorization settings
- Blocking by .htaccess file
- Excessive loading time
- Blocking because of too many requests
Fortunately, it's easy to solve them if you're using Netpeak Spider, as it allows you to see a target website just as the search engine bots do and find those issues yourself. Moreover, the tool offers you a list of troubleshooting tips and explains the potential threats each problem may cause in the future. Thanks to this app, you'll always be able to keep track of emerging issues and promptly react to each one of them.
However, it's only a part of things you can do with Netpeak Spider. Here's a brief review of other functions you may find helpful in your SEO needs:
Data filters and segmentation
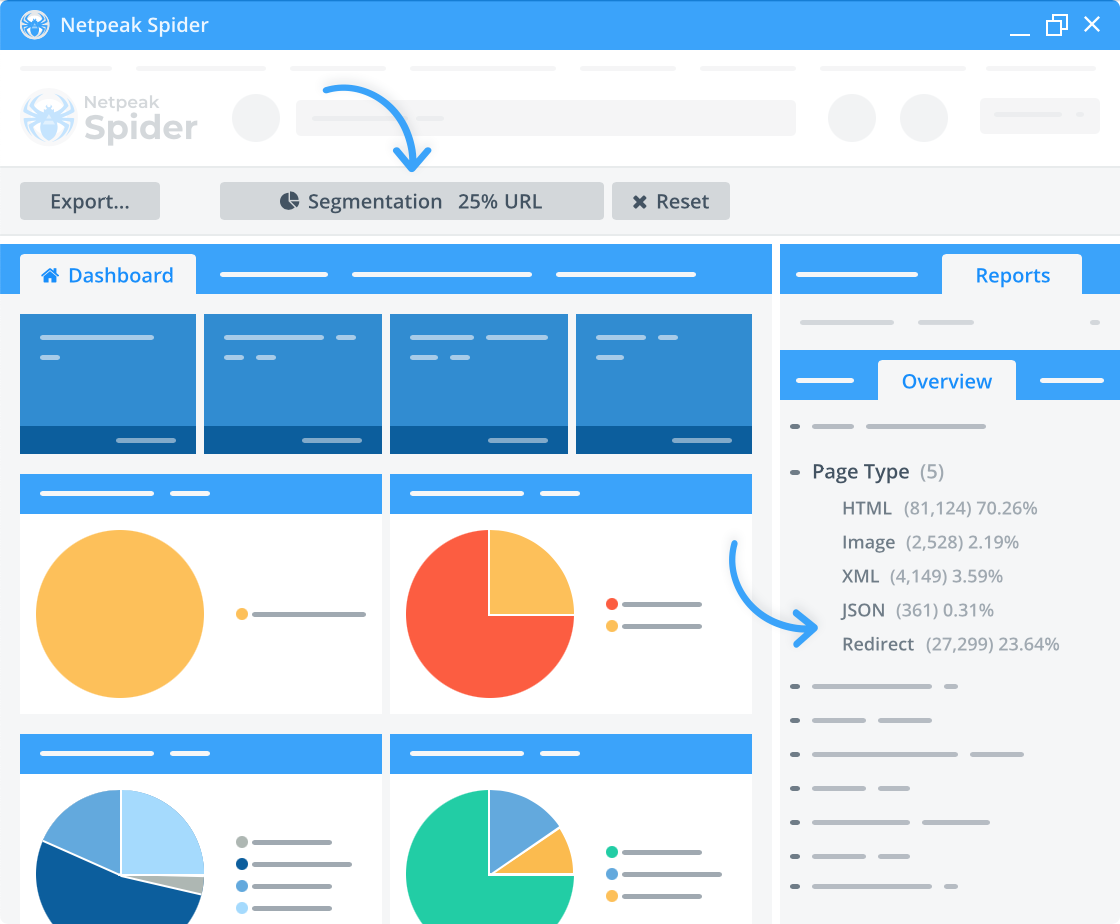
Data filtering is beneficial for crawling large websites. Our crawling SEO tool delivers in-depth research insights segment by segment, allowing you to focus on specific parameters. Divide the data into dedicated segments on a dashboard and enable custom filtering conditions or change the data overview for more convenient reporting and overviewing of the results.
Internal PageRank calculator
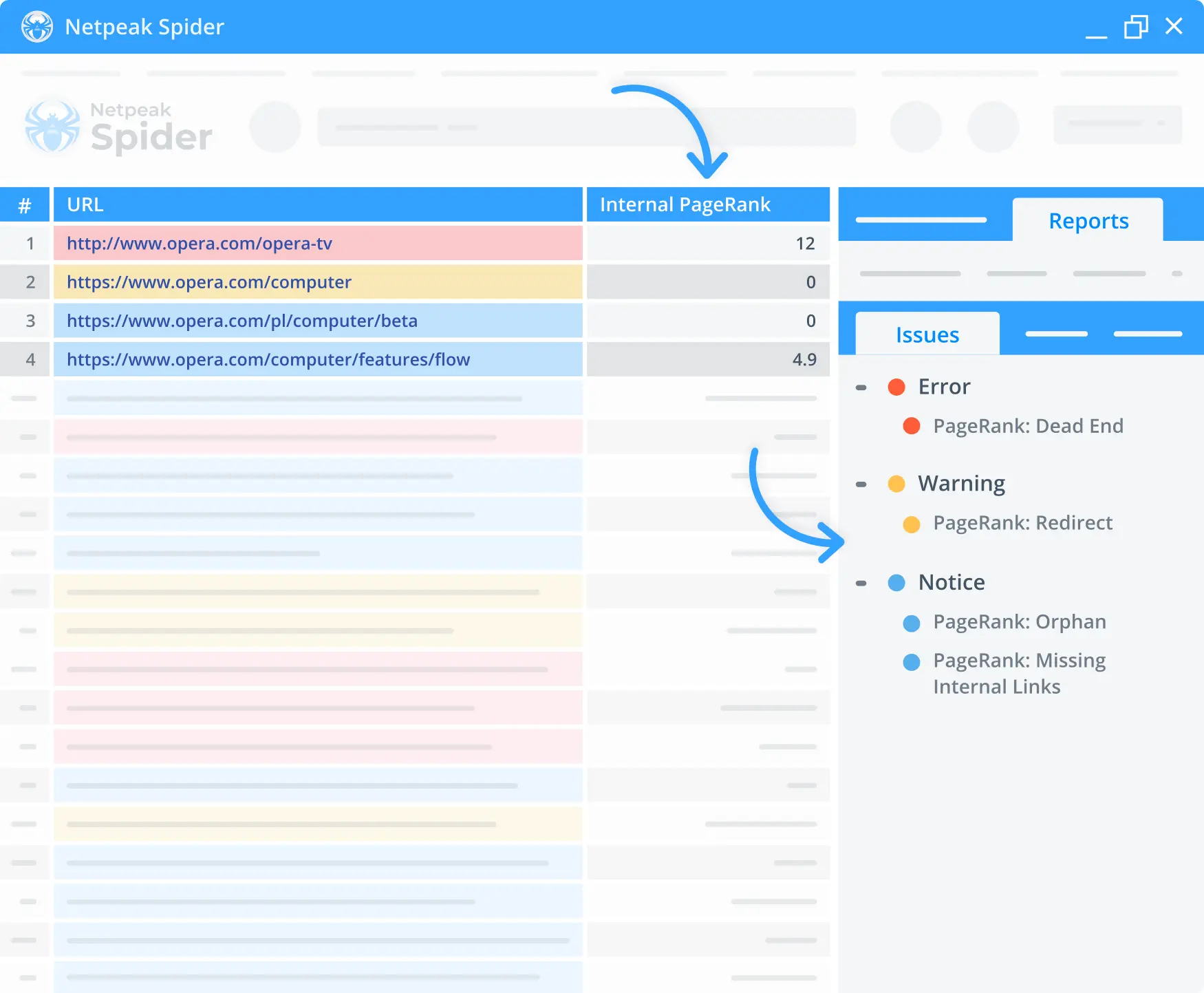
The built-in PageRank calculator lets you check any page's internal linking. Thanks to that, you can monitor the link weight distribution and see whether your pages burn incoming link equity or don't get any of it at all.
Integrations with Google Analytics and Search Console
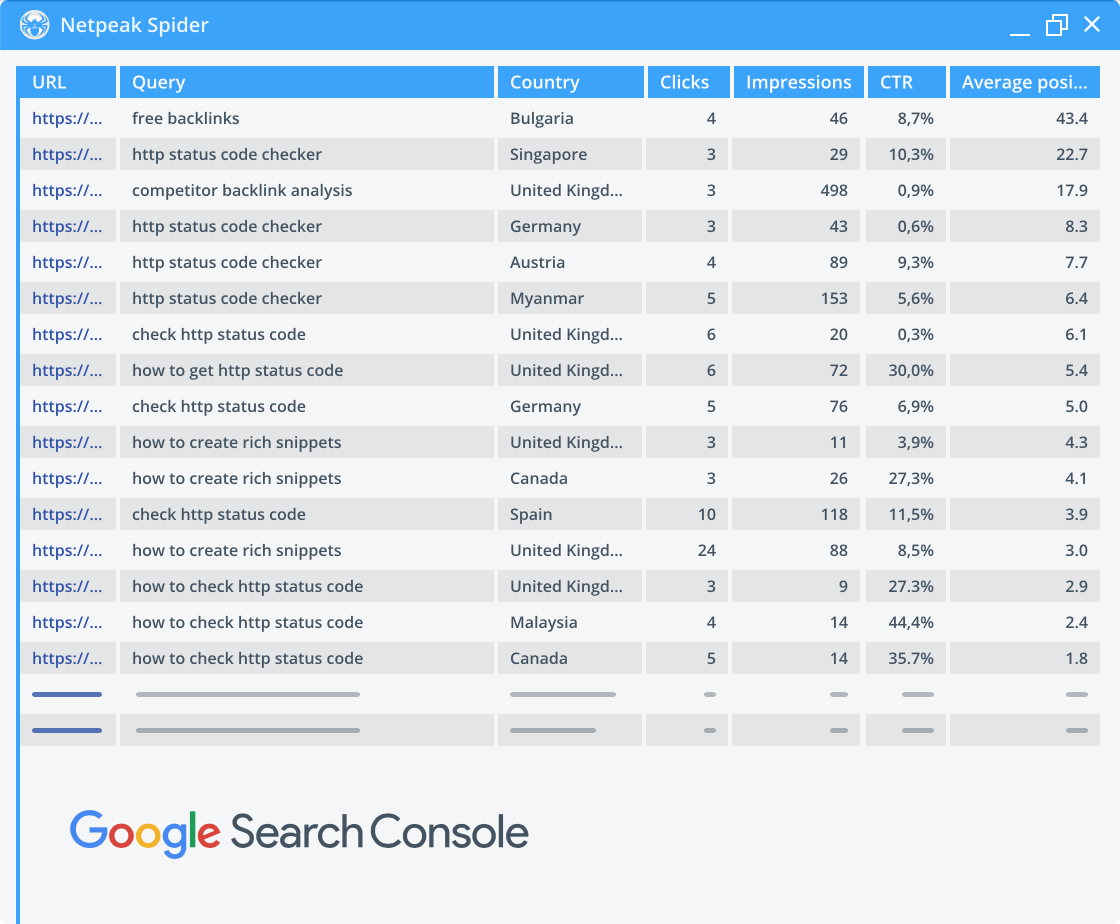
Use the data from Google Analytics and Search Console to enrich the data retrieved from your website. Thanks to this feature, you'll receive essential insights on traffic, goals, conversions, and even eCommerce parameters that impact your website's performance.

Takeaway
Crawling websites should become a regular task for any SEO specialist to ensure high performance for their website and business in general. Site checkups help you detect critical issues and quickly react to the most crucial ones before they start affecting your optimization efficiency and organic traffic flows.
To help you analyze any number of websites and pages, try Netpeak Spider — it's a handy, powerful site crawling tool that helps you not just detect but also solve over 100 known types of issues. Try it for free and start improving your SEO performance right away!
.png)
