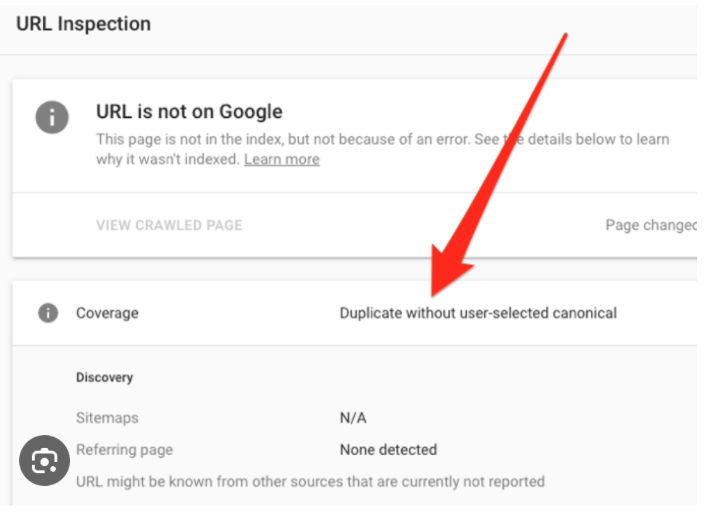
How To Fix “Technically Duplicate Pages” to improve your rankings
Site Audit Issues
.png)
Content:
- What Does “Technically Duplicate Pages” Mean?
- Most Common Things That Cause “Technically Duplicate Pages”
- How To Fix “Technically Duplicate Pages”
- How to Fix the “Technically Duplicate Pages” with Netpeak Spider?
- Conclusion
Website optimization plays a huge role in your user experience, search engine optimization, and rankings. Technically duplicate content is often difficult to spot, but it can become a real threat to your website's performance and SEO. In this article, we will delve into the reasons for technically duplicate pages, exploring what they are, what causes them, and the most effective strategies to fix them.
What Does “Technically Duplicate Pages” Mean?
What is duplicate content? Technically duplicate pages are pages with similar or identical content, even though the content itself may not be identical in substance. This can happen due to various reasons, such as URL variations, tracking parameters, or content duplication caused by dynamic page generation.
While these pages might seem harmless at first glance, they can lead to a decrease in rankings, create confusion for search engines, and ruin a user experience. Technically duplicate content issues usually result in the following:
- SEO Dilution
Why is having duplicate content an issue for SEO? Search engines aim to provide users with the most relevant results. When a website has multiple URLs displaying Google duplicate content, it becomes difficult to determine the most authoritative and relevant page. This can lead to SEO dilution, where the ranking power of the content is spread across various URLs, diminishing the overall visibility of the website in search results.
- Crawl Budget Wastage
Search engines allocate a crawl budget to each website, determining the frequency and depth at which they crawl it. Duplicate content Google consumes this crawl budget inefficiently, diverting resources away from more critical pages. This can result in search engines not indexing new or updated content promptly.
- Bad User Experience
When users land on different URLs with the same content, it leads to confusion and frustration. This not only ruins the user experience but can also impact user trust and lead to a higher bounce rate, as well as duplicate content penalty.
Most Common Things That Cause “Technically Duplicate Pages”
Here are the main factors that cause technically duplicate pages:
- URL Variations and Parameters
One of the primary reasons for technically duplicate pages is the existence of multiple URLs that lead to similar or identical content. This often happens when tracking parameters, session IDs, or sorting parameters are added to the URL. When it comes to duplicate content and SEO, search engines may treat each URL with parameters as a separate page, even though the content remains the same.
For example, a product page URL like “example.com/product” may have variations like “example.com/product?utm_source=google.” Despite the differences in the parameters, the core content on these pages may remain unchanged, creating technically duplicate content.
- Dynamic Generation
Content management systems (CMS) and dynamic websites may generate multiple URLs for the same content based on how the page is navigated. For instance, a blog post may have different URLs for the full article, a paginated version, and a version for print. These variations can result in technically duplicate pages.
Additionally, URL structures that dynamically generate pages based on user preferences or filters can also become the cause for technically duplicate pages. This often happens on eCommerce websites, where users filter products by various criteria.
How To Fix “Technically Duplicate Pages”
As the reasons for technically duplicate pages may be different, fixing them requires a comprehensive approach. Here is how you can fix technically duplicate pages and avoid Google duplicate content penalty.
- Canonicalization
Canonical tags are HTML elements that inform search engines about the preferred version of a page if there are multiple versions of it. Implementing canonical tags on technically duplicate pages helps consolidate ranking signals and directs search engines to index the preferred URL. This is particularly useful when dealing with URL variations and parameters.
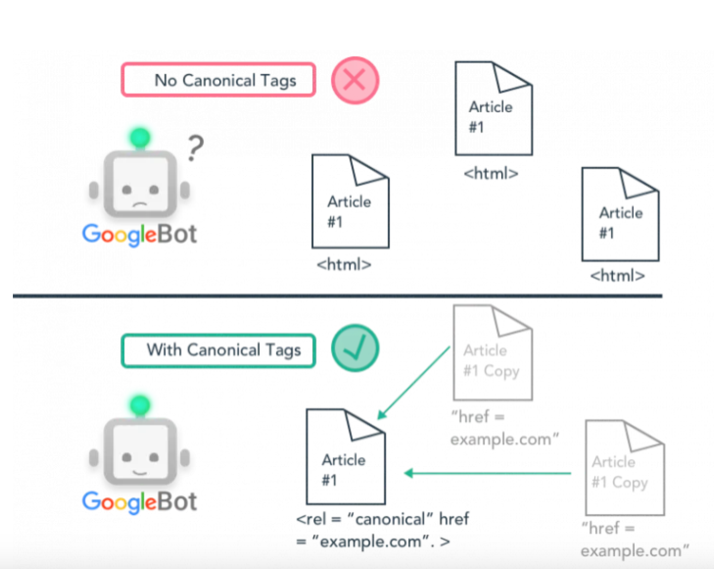
- 301 Redirects
Permanent redirects (301 redirects) are an effective way to consolidate the authority of multiple URLs into a single preferred version. By redirecting all variations of a page to the canonical version, you ensure that search engines and users are directed to the correct and authoritative URL. This method is especially useful for addressing content duplication resulting from URL variations.
- URL Parameter Handling
Use Google Search Console or other webmaster tools to instruct search engines on how to handle URL parameters. This can involve specifying which parameters to ignore or how to identify them. By effectively managing URL parameters, you can decrease the impact of duplicate content caused by variations in tracking parameters.
- Regular Website Audits
Conduct regular website audits to identify and rectify instances of technically duplicate pages. You can use such tools as Screaming Frog and Google Analytics to analyze your website's structure, identify duplicate content issues, and fix them.
- Consistent URL Structure
Maintain a consistent and organized URL structure to decrease duplicate content issues. Avoid unnecessary parameters and ensure that similar content is accessible through a single, canonical URL. Consistency in URL structure simplifies crawling for search engines and improves the overall user experience.
How to Fix the “Technically Duplicate Pages” with Netpeak Spider?
How much duplicate content is acceptable? Technically, there's no limit to how much duplicate content you can have. Netpeak Spider is an easy-to-use and effective tool that will help you detect technically duplicate pages. Here’s how exactly you can find duplicates on your website.

- Finding duplicates by scanning
With the Netpeak Spider scanning feature, you can detect pages with duplicate content: full page duplicates, duplicate pages based on <body> block content, repeated “Title” tags, and “Description” meta tags.
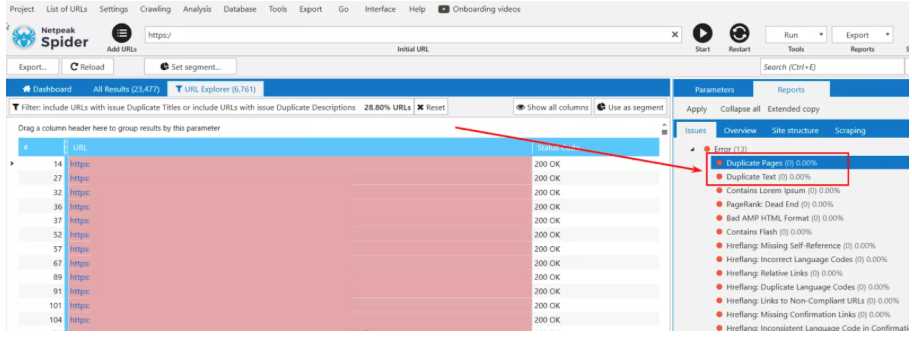
- Find duplicates by using the content checker tool
Use the content checker tool to identify potential plagiarism or duplicates. The duplication checker will highlight pages that share identical text content within the <body> section. Additionally, make use of the “Text Hash” field to categorize URLs within this report.
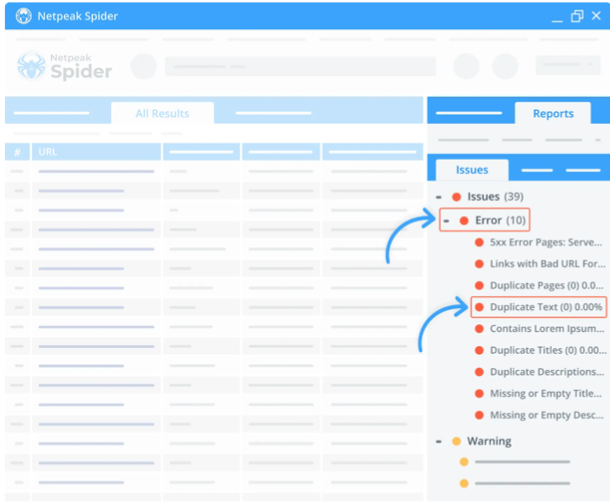
- Find duplicate descriptions and H1s
Use Netpeak Spider content checker to reveal duplicate descriptions on your website. Netpeak Spider identifies all pages with matching content under the <meta name="description" /> tag. In this sample report, the tool organizes URLs based on the “Description” field. Also, you can identify repeated H1 titles on your website. If you have more than one H1 heading per page, the checker will tag any pages with duplicate <H1> heading tag content.
The bonus — you can test all these features for free! The trial version has no time limits, but you can analyze up to 500 URLs.

Conclusion
Technically duplicate pages may be hard to detect, but they may lead to serious consequences. With regular website crawling, you won’t miss any issues that may influence your website user experience and rankings. Remember to make website audits using special tools like Netpeak Spider to quickly detect duplicate content issues and keep your website safe and sound.
.png)
