"Blocked by robots.txt” vs. “Indexed, though blocked by robots.txt”: How to Fix These Issues
Site Audit Issues
.png)
Content:
- What’s the Difference Between “Indexed, though blocked by robots.txt” and “Blocked by robots.txt?”
- What Causes “Indexed, though blocked by robots.txt?”
- How To Fix “Indexed, though blocked by robots.txt?”
- How To Fix “Blocked by robots.txt”
- How Netpeak Spider Helps Fix “Blocked by robots.txt” and “Indexed, though blocked by robots.txt”
- Bottom Line
Proper website crawling and indexing are essential for an effective SEO strategy. However, sometimes Google may index an irrelevant or blank URL, or you may have issues regarding the links blocked by the robots.txt file.
In this post, we'll cover the indexed though blocked by robots txt and blocked by robots.txt meaning, how you can fix those issues and prevent such problems using Netpeak Spider.
What’s the Difference Between “Indexed, though blocked by robots.txt” and “Blocked by robots.txt?
“Indexed though blocked by robots.txt” and “Blocked by robots.txt” are special statuses in Google Search Console. If you see any one of those while analyzing your website, this means that Google didn't crawl the affected pages since you've blocked them within the robots txt file.
What’s the difference between the two? If you see “Blocked by robots.txt,” this means the affected links won’t appear on Google. But with “Indexed though blocked by robots.txt,” you will find an affected URL in the search results, even though a Disallow directive in your robots.txt file has blocked them. So, in the case of an “Indexed though blocked by robots txt” status, Google indexed your link but didn’t crawl it.
What Causes “Indexed, though blocked by robots.txt?”
Sometimes, Google chooses to index a page it just found even though it can’t crawl it or understand its content. That happens when the main motivation for Google search is finding the numerous links that forward it to the page blocked by robots.txt.
These links (both internal and external) and their number impact the PageRank score that helps Google decide whether a given page is essential. If there's an issue with your links, and Google sees a disallowed page with a high PageRank score, it may consider this page quite important and will add it to the index. Yet, it'll be an empty link with no content since the page hasn’t been crawled.
How To Fix “Indexed, though blocked by robots.txt?”
Let's see how you can fix issues with blocked internal resources in robots.txt. There are several major case scenarios and possible solutions to them.
When you want to index the page

If you mistakenly disallowed a page in robots.txt, you'll have to modify the file. Once you've removed the Disallow directive that was blocking the URL crawling, Googlebot will most likely crawl it the next time it checks your website.
When you want to deindex the page

If there's any information you don’t want to reveal to your website visitors in the search engine, you have to indicate to Google that you don’t want it to index a particular page. In that case, you shouldn't use robots.txt to manage the indexing process as the file blocks Googlebot from crawling. Instead, try using the noindex tag.
Don't forget to let Google crawl your page and detect this tag. If you add it but still have a page blocked in the robots.txt file, Google won’t be able to locate the noindex tag, leaving the page indexed though blocked by robots.txt.
To keep any URL away from Google and its users, implement the server HTTP authentication so that the users can only access the page after logging in. This will be the best option if you want to protect any sensitive data, for instance.
When there's a need for a long-term solution

There's a chance that the issues with blocked internal resources in robots.txt will reappear in the future — for example, if you add new pages to your website. Both these statuses will indicate that your website might need in-depth internal linking or backlink audit improvement. One of the best ways of preventing this issue in the future is to run SEO page audits regularly.
How To Fix “Blocked by robots.txt”
Now, let's see how you can fix the "blocked by robots.txt" issue in two possible ways.
When you used the Disallow directive on purpose
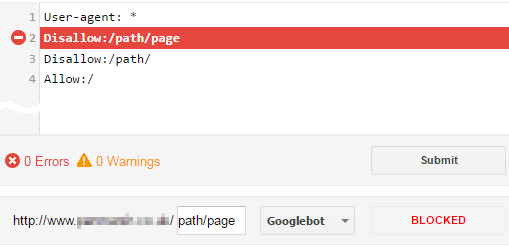
One of the solutions may be ignoring this status in the Search Console. You can do that as long as you don't disallow any important links in robots.txt. Blocking bots from crawling duplicate or low-quality content is not a big deal.
Picking the pages that bots should and shouldn’t crawl is essential to:
- Develop a website crawling strategy
- Optimize and save your crawling budget
When you used the Disallow directive by mistake
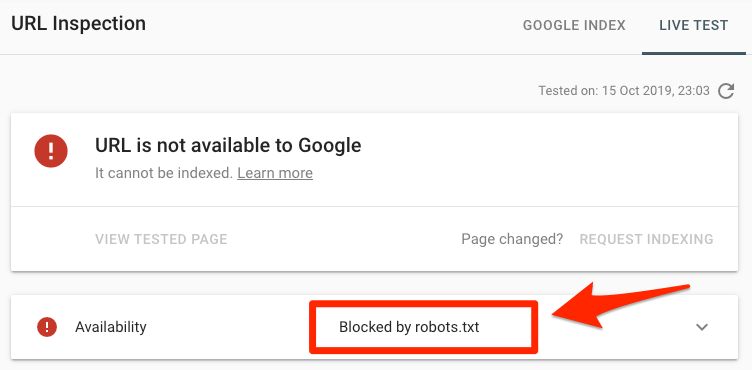
If you want to fix “Blocked by robots.txt,” you should remove the Disallow directive for a target page. Thus, there is a higher chance of Googlebot crawling your page link the next time it reaches your website. Given that there are no other issues, Google will index it as well.
How Netpeak Spider Helps Fix “Blocked by robots.txt” and “Indexed, though blocked by robots.txt”
Just like we've mentioned above, running regular SEO checkups is one of the most effective ways how to fix indexed though blocked by robots.txt and robot txt no index issues, and Netpeak Spider can help you with that. You can test a free trial of Netpeak Spider — it's now available for both macOS and Windows users.

Now, let's take a closer look at how you can make the most use of this tool.
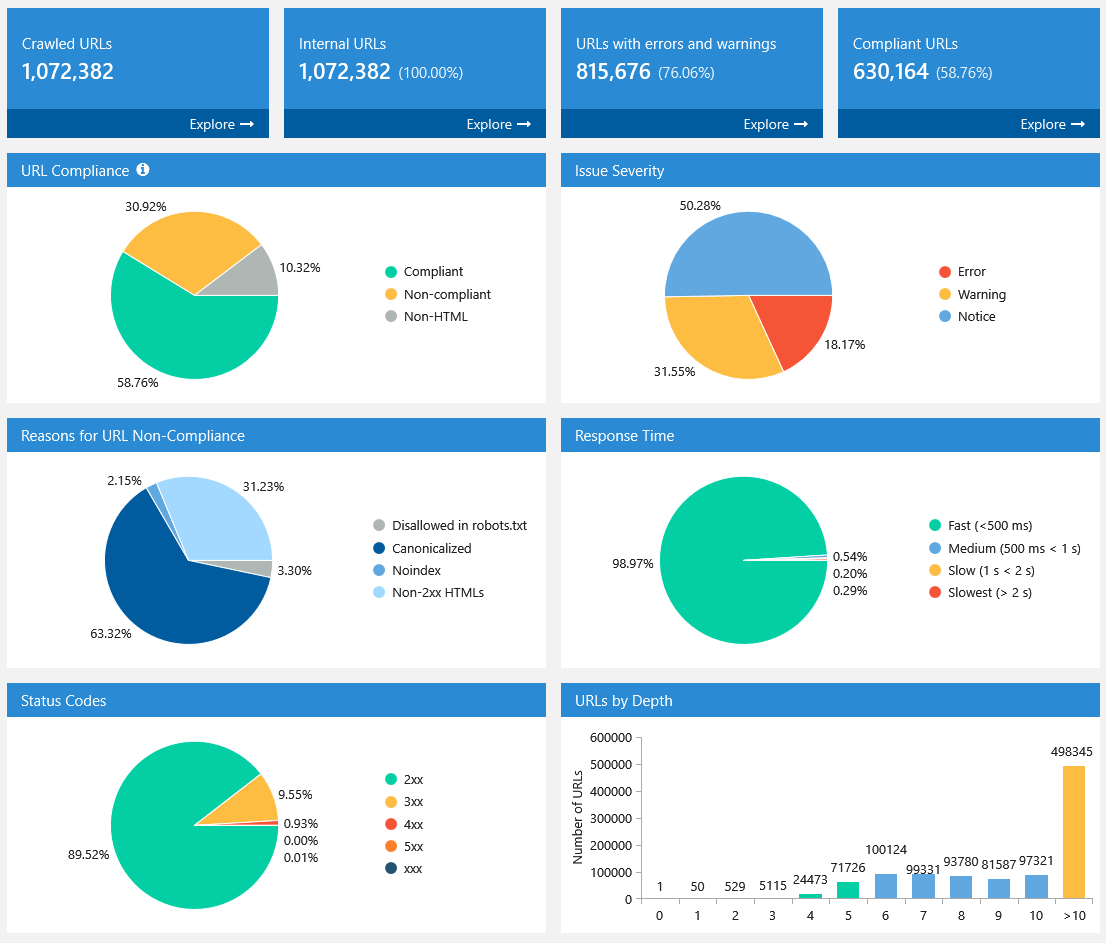
Detecting compliant URLs
Netpeak Spider detects three page compliance types: compliant, non-compliant, and non-HTML. It detects HTML files with the 2xx status code and the ones that are not disallowed in indexation instructions, including robots.txt.
Dashboard and quick reports export from Google Search Console
Thanks to the ability to integrate data from Google Analytics and Search Console, you can see all the necessary SEO-related data on your website in one location. Netpeak Spider provides a convenient and user-friendly dashboard where you can keep track of all the issues and current page stats.
Virtual robots.txt

If you want to test the new robots.txt file and verify that search engine robots will correctly understand it, Netpeak Spider allows you to try the “Virtual robots.txt” setting. The app uses this virtual file instead of the one in your website's root directory.
Skipped URLs
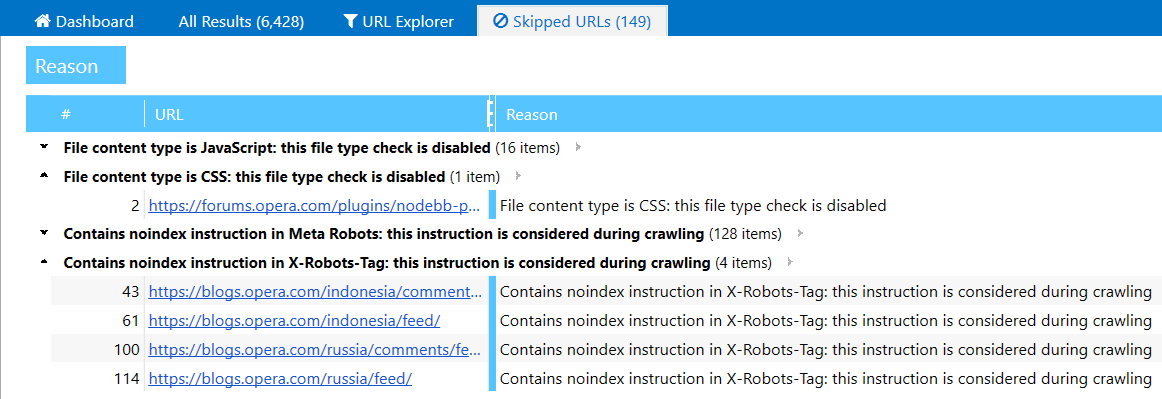
Netpeak Spider also shows you the skipped URLs in a dedicated tab. This tab only appears when the app detects particular pages that are ignored during the crawling process. You'll see the links with an explanation for why they were skipped.

Bottom Line
Having a well-groomed robots.txt file is one of the essential elements of any good SEO strategy. Hence, it's necessary to predict and prevent potential dedicated errors like “Blocked by robots txt” and “Indexed though blocked by robots txt.”
Now that you know the main differences between these two Google Search Console statuses and how to fix them, you'll be able to evaluate potential issues with the new pages on your website.
To help you gather all the problematic pages in one place and get a detailed status report on them, Netpeak Spider will be a perfect option for you. Try this complex website crawling tool and integrate Google's services to get in-depth results and promptly react to existing issues. Try Netpeak Spider now and fix your SEO troubles right away!
.png)
