Классификация и типизация запросов
От экспертов

В рамках потока «SEO для специалистов» на конференции 8P прозвучал доклад о системе кластеризации поисковых запросов. Структура доклада:
- Зачем нужна типизация и классификация?
- Как построить алгоритм для типизации и классификации?
- Как это использовать?
Часть 1. Зачем нужна типизация и классификация?
Казалось бы, что сложного: взять и посмотреть, какие запросы коммерческие, а какие нет? Давайте попробуем на конкретных примерах.

- «Ноутбуки цены характеристики» — коммерческий запрос.
- «iPhone 7 plus» — запрос, который зависит от времени. То есть когда новый iPhone только появляется, этот запрос является информационным, а когда девайс выходит в продажу, запрос меняет свою структуру и становится коммерческим. Затем, когда этот iPhone становится менее популярным, запрос вновь становится информационным.
- «Шампунь Apivita propoline» — информационный запрос. Шампунь покупают, но по этому запросу и в Яндексе, и в Google вы найдете в основном информационные ответы, а коммерческие будут с уточнениями.
- «ue32k5500au» — запрос смешанного типа.
Коммерческий запрос или нет — это вопрос с подвохом: «коммерческость» даже в самом поиске не измеряется как единица или ноль. Это всегда какое-то число, то есть запрос может быть немножко коммерческим или сильно коммерческим. Собственно, вот зачем нужна классификация запросов — чтобы понять, действительно ли они относятся к вашей тематике.
Например, вы работаете в тематике банковских карт, и у вас есть запрос «сбербанк виза» или «выписка из банка для визы». Из них к картам относится только первый. И классификатор, который автоматически заглядывает в топ, легко это проверяет, причем сразу на большом поле запросов. Человек способен в этом разобраться, если запросов 10-20. Если же их 1000 или 10 000, то это огромное количество работы.
Два основных метода классификации, о которых рассказал Алексей, это тематика запроса и коммерческость.

Всего методов, разумеется, намного больше: можно смотреть ещё и на геозависимость, количество «морд» (главных страниц сайта) и наличие навигационных ответов, которые очень важны для дальнейшего продвижения. Например, количество «морд» влияет на то, какую страницу вам лучше продвигать — главную или внутреннюю.
Собственно, почему отдельного упоминания удостоилась геозависимость? Вроде бы достаточно простая штука, которая элементарно определяется в Яндексе и Google. Дело в том, что коммерческость запроса и его геозависмость тесно между собой связаны. То есть если запрос геозависимый и содержит топоним, то он, как правило, является коммерческим (с большой вероятностью).
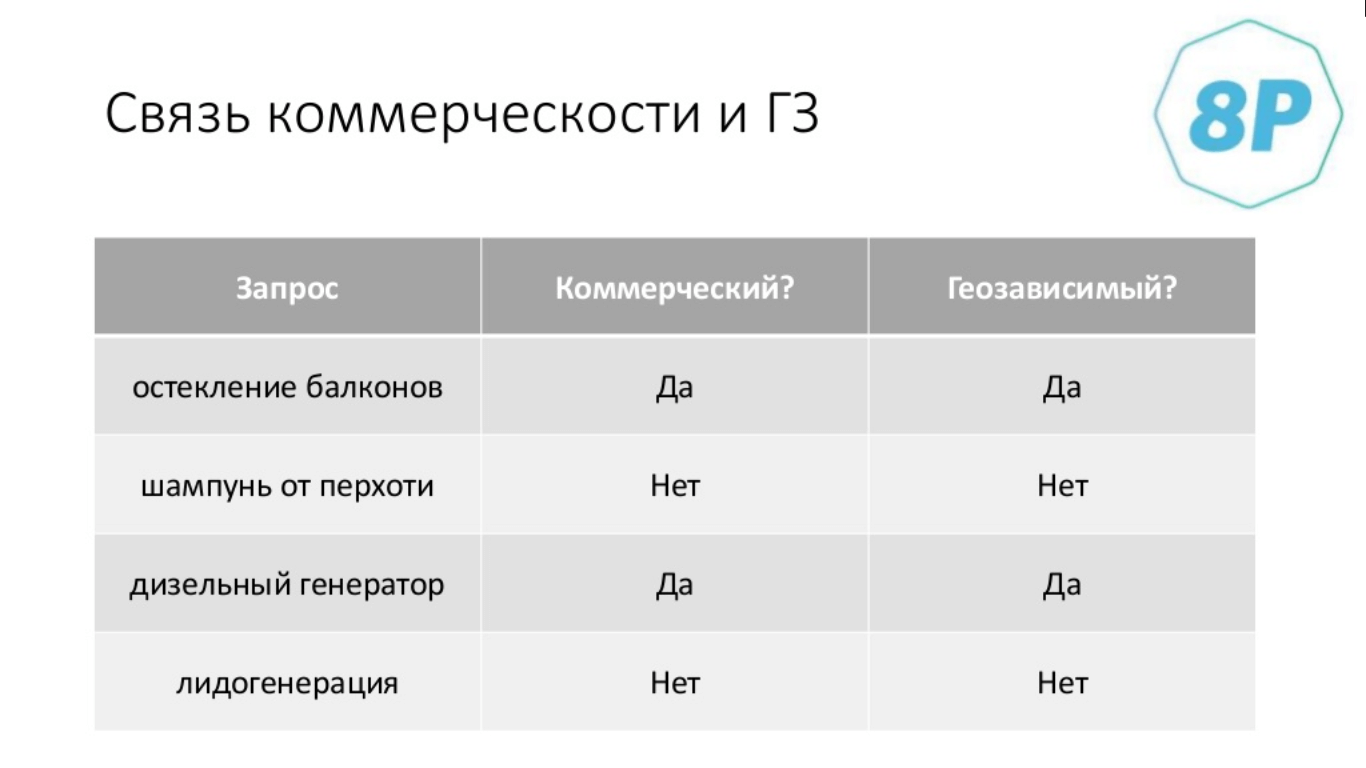
К примеру, запросы «остекление балконов» и «дизельный генератор» — одновременно коммерческие и геозависмые, а «шампунь от перхоти» и «лидогенерация» — ни то, ни другое.
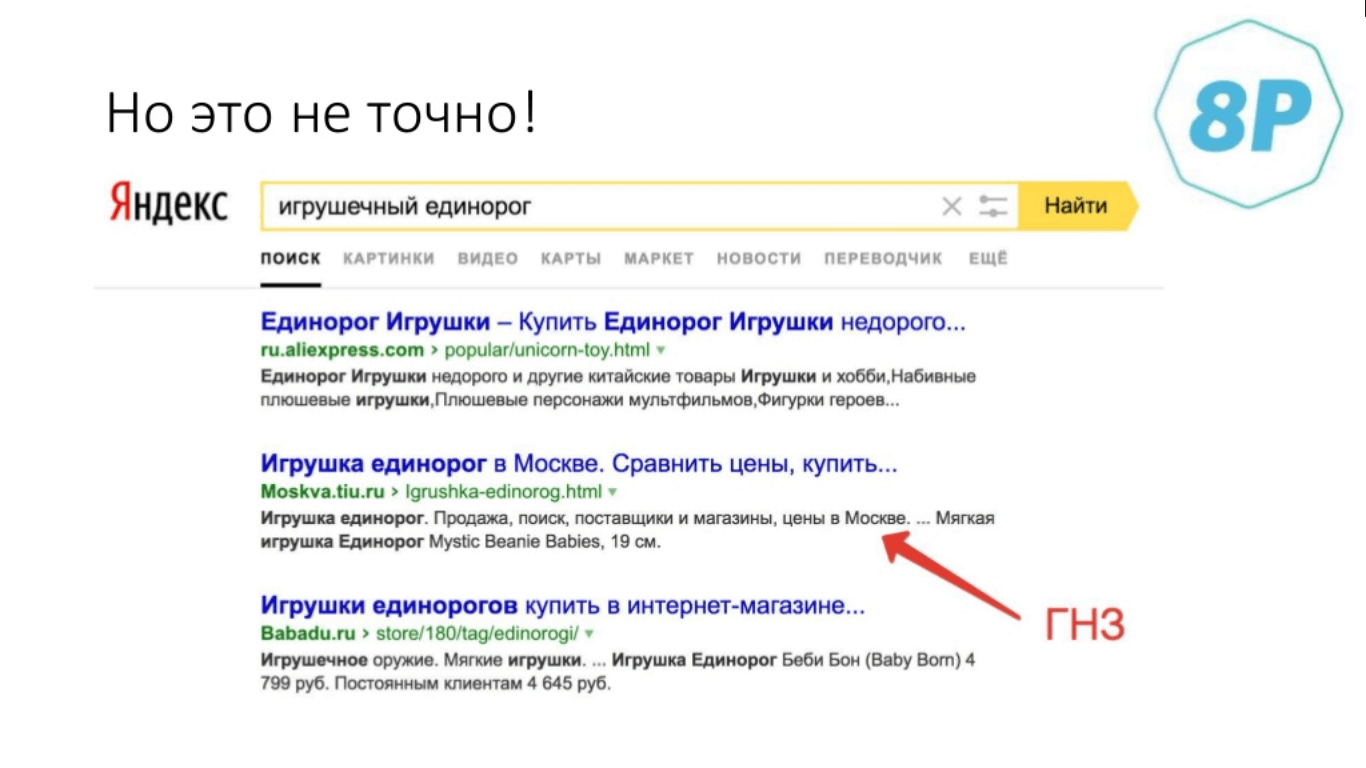
Хороший пример запроса, который является геонезависимым как в Яндексе, так и в Google, — это «игрушечный единорог». Но он является коммерческим, так как игрушечных единорогов любят покупать :)
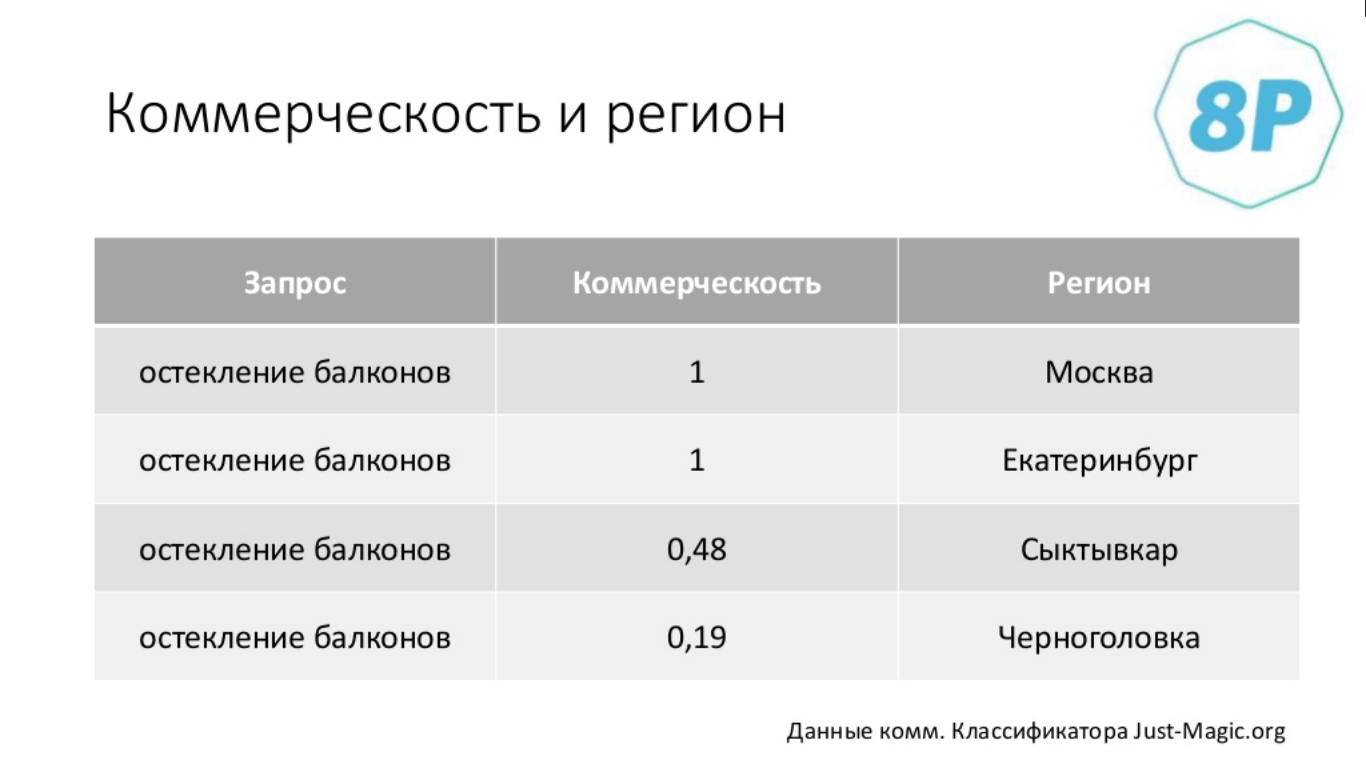
Еще одна особенность связана с регионами. Дело в том, что коммерческость — это не просто функция запроса, это еще и функция региона.
«Остекление балконов» в Москве — абсолютно коммерческий результат, в Екатеринбурге — абсолютно коммерческий, в Сыктывкаре — уже 50 на 50, а в Черноголовка — это уже практически некоммерческий. Цифры, приведённые в таблице ниже, — это данные коммерческого классификатора, о котором пойдёт речь позже.
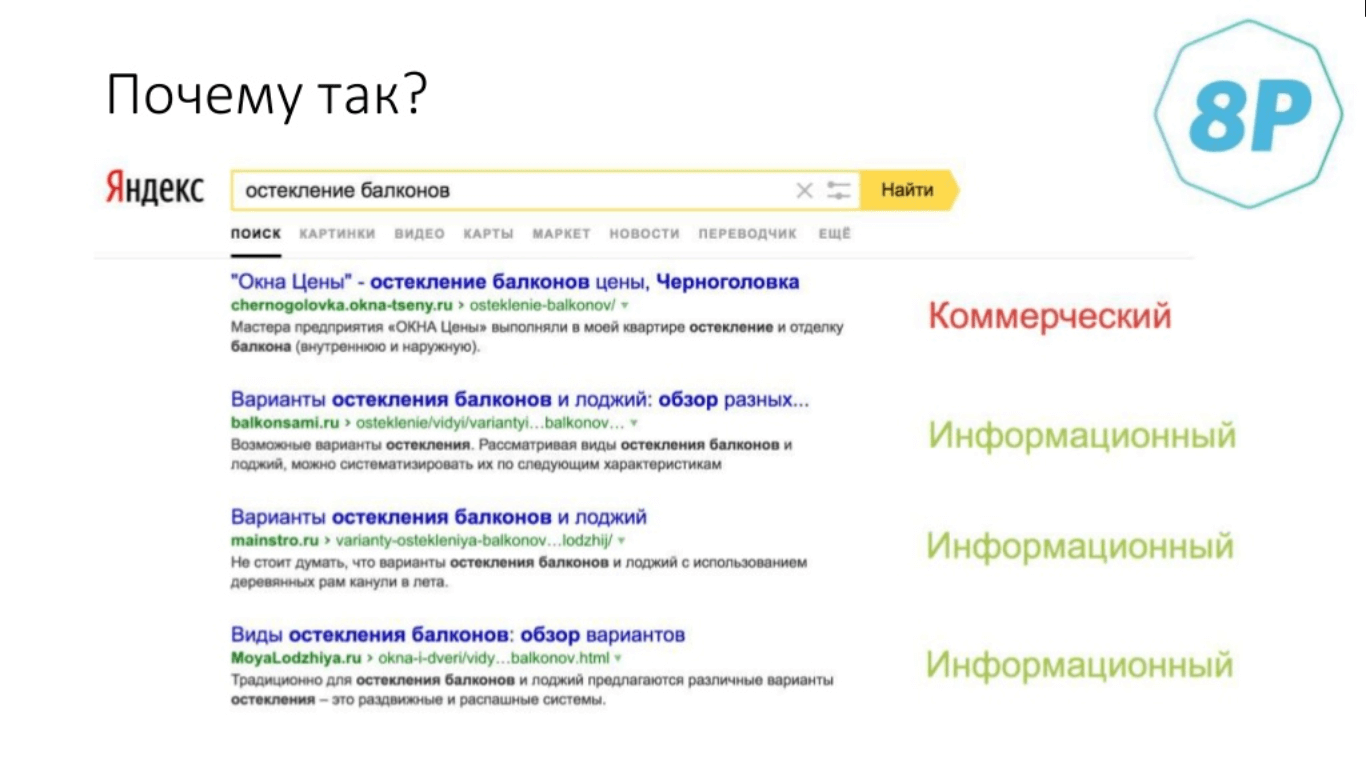
Так происходит по очень простой причине: в Черноголовке мало кто занимается остеклением балконов, а потому в поиске преобладает информационный контент. Он, соответственно, переворачивает структуру запроса в поиске — как в Яндексе, так и в Google.
Ну и немного про Яндекс и Google: почему эти методы работают и там, и там.
С тематикой все достаточно понятно: тематика запроса может хорошо определяться в контексте выдачи. Что касается коммерческости, она имеет различное влияние на ранжирование: в Яндексе — сильное, в Google — меньшее, но все-таки тоже весомое. Геозависимость важнее: в Яндексе сильно развит бинарный признак, в Google — значительно меньше. К примеру, московский сайт можно сделать достаточно популярным в украинской выдаче и наоборот.
Часть 2: Как построить алгоритм для типизации и классификации
Начнём с простого — с определения коммерческости. Речь пойдёт о простом эвристическом методе. Что делает человек, когда смотрит в топ для определения, запрос коммерческий или нет? Смотрит в сниппеты. Если человек может это сделать, то почему компьютер не может?
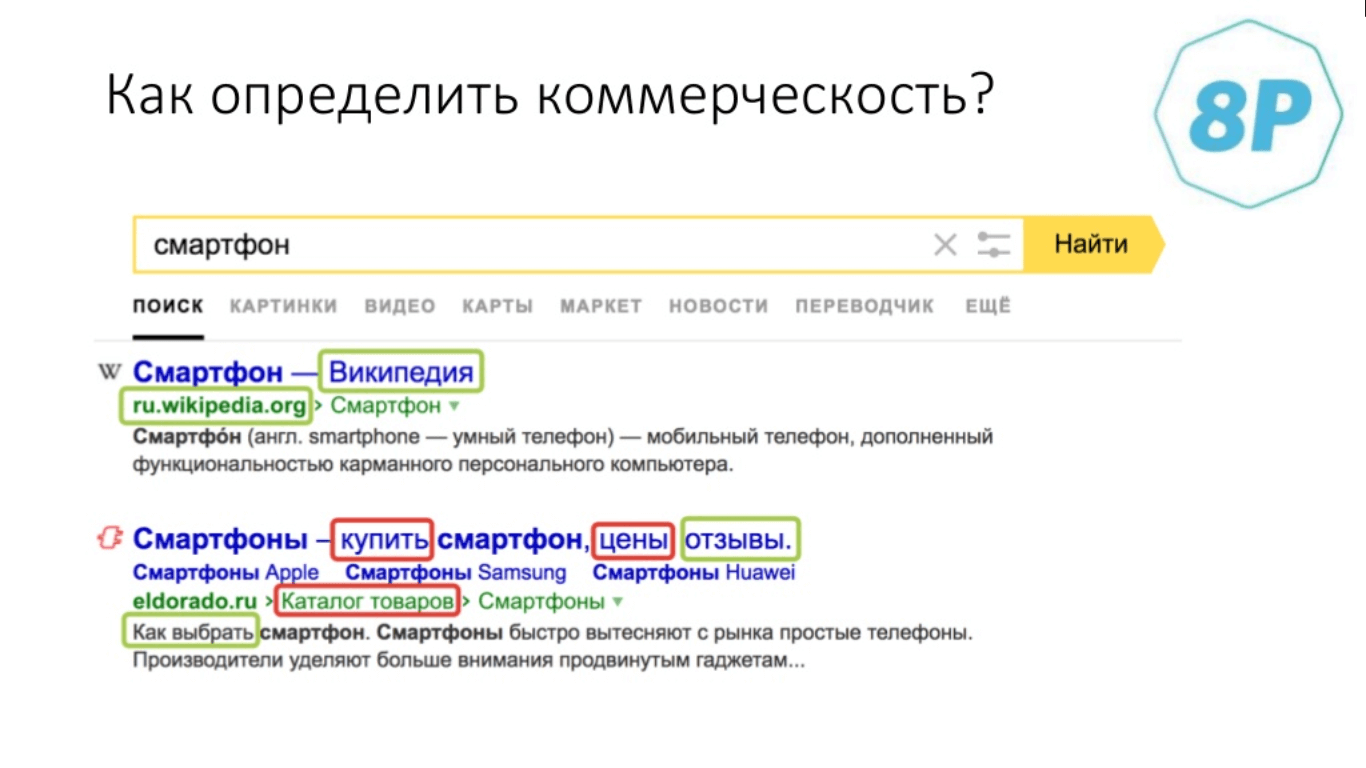
Идея лежит на поверхности: мы рассматриваем, какие в топе стоят сайты и какими признаками они обладают, затем составляем на основе этого классификатор по сниппетам.
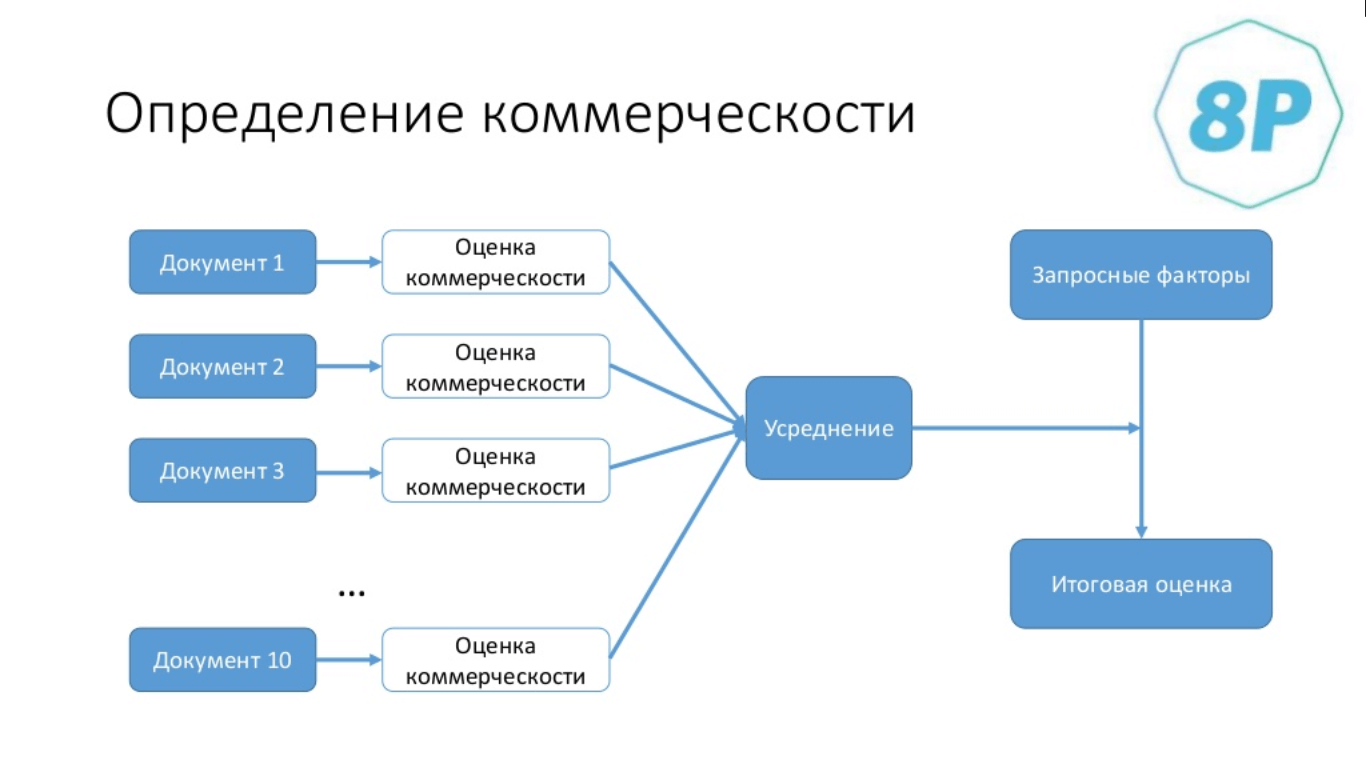
Что мы для этого делаем? Мы берём каждый документ из выдачи и для его сниппета делаем отдельную оценку коммерческости — на основании разметки и слов, которые в нём присутствуют. Затем мы считаем сводную оценку и к ней применяем запросный фактор:
- Если запрос является геозависимым, это увеличивает вероятность того, что он будет коммерческим.
- Если же в топе есть Википедия, то больше вероятность, что запрос некоммерческий.
- Если в запросе есть какое-то маркерное слово (например, «купить», «цена», «отзывы» и т.д), то это также позволит определить, коммерческий это запрос или информационный.
Все эти данные сводятся в единую оценку коммерческости — всего используется порядка 15 факторов: около 10 — для каждого документа, 5 — для самого запроса.
При этом подобный алгоритм может различать запросы лучше, чем человек. Например, в случае с запросом «ограждение спортивной площадки» человек не может разобраться, коммерческий это вопрос или информационный: казалось бы, явных признаков коммерции нет, но вроде как речь должна идти о продаже ограждений. Классификатор, даже не залезая в контент сайта, оценивает запрос. Результат: коммерческость — 0,92.

Теперь определяем тематику. Во-первых, нужно понять, о чём запрос. На что вы смотрите? На сниппеты — например, на характерные маркерные слова. То есть нужно учить робота находить и смотреть на них. Сделать это можно с помощью так называемого «векторного» представления.
В качестве примера сделаем векторное представление фразы «мама мыла раму». Итак, есть три измерения. По каждому из них отложено количество слов, которое присутствует в тексте. То есть «рама» — одно слово, «окно» — одно слово, «мыть» — одно слово. Таким образом, получился тематический вектор. Например, если у нас будет фраза «мама мама мыла раму», значит, измерение по слову «мама» будет чуть больше. Вектор тематики будет определяться именно таким способом. Дальше всё очень просто: мы делаем вектор тематики не для трёх слов, а для всей коллекции.
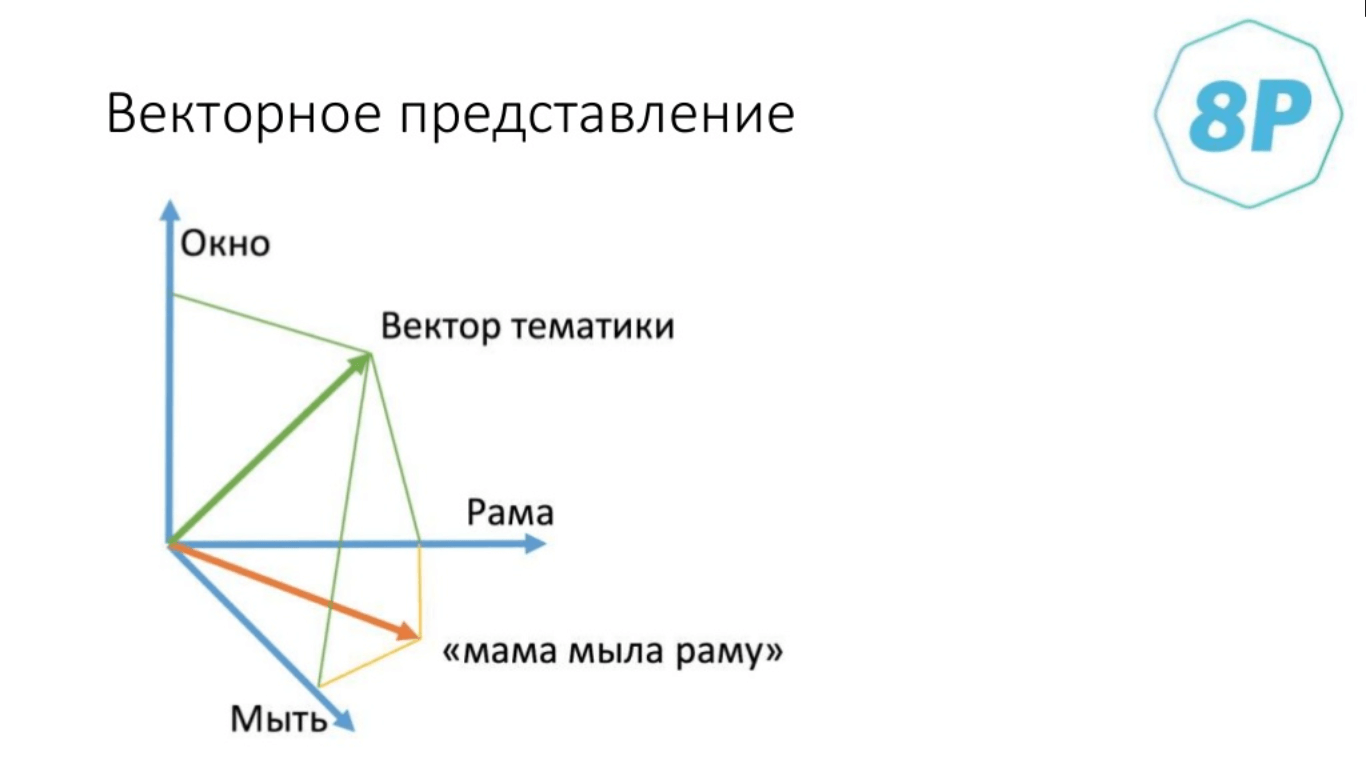
Необходим каталог тематик, для которых мы построим тематический условный вектор и векторное представление на основании результатов выдачи. Затем мы просто измеряем расстояние между векторами (вспоминаем косинусное произведение).

Часть 3: Как это использовать
Самое сложное уже осталось позади, так как же теперь использовать описанную методику? В какую часть процесса её внедрить?
Есть стандартная потребность в работе с семантическим ядром, куда встраиваются вот эти классификации. К примеру, мы набрали некое объёмное семантическое ядро. Мы его предварительно почистили и дальше выполняем два действия:
- Прогоняем его через тематический классификатор, чтобы понять, что относится к нашей тематике, а что — нет.
- Запросы, которые относятся к нашей тематике, прогоняем через коммерческий классификатор, чтобы поделить их на коммерческие и информационные.
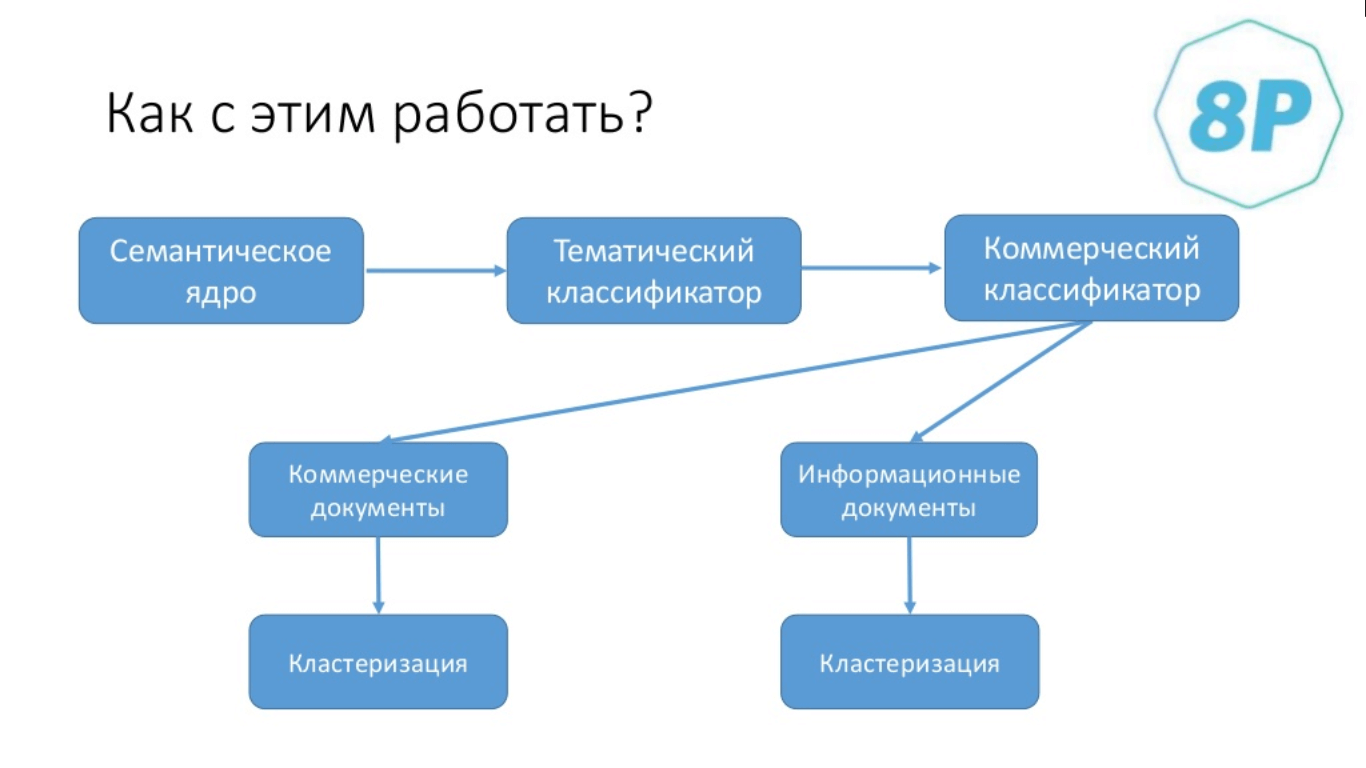
Затем полученные данные отправляются в кластеризатор: отдельно под информационные и коммерческие документы. Многие делают фильтрацию по стоп-словам (минус-словам), но в этой схеме она вам не нужна: если стоп-слово меняет тематику, оно отсюда вылетит, и наоборот.
При такой схеме вы можете работать с ядрами абсолютно любого объема. К примеру, вручную вы можете обработать 100 запросов или, скажем, 1000, но как только количество запросов становится больше в 10 раз, сложность обработки возрастает в 100. Почему так происходит? Потому что вам нужно каждый запрос сравнить со всеми остальными, отнести к его группе, затем заглянуть в каждый топ, а это очень много работы.
И не забываем опять-таки о факторе времени. Хотя проведена первичная работа, топы могут меняться, как и коммерческость запроса. Сегодня запрос является коммерческим, а завтра — информационным.
Соответственно, вам нужно оперативно менять документы, которые будут активно продвигаться по нему: нужно вносить изменения в оптимизацию страницы либо целиком менять контент. Если вы оперативно не сделаете кучу информационного контента, вы потеряете значительную долю трафика и лидов.
![Как улучшить свои метрики в Google PageSpeed / LightHouse [Доклад Demi Murych]](https://static.netpeaksoftware.com/media/ru/image/blog/post/afde3629/285x205/ns-murych-talk-at-8p-mini.png)

