Как создать фид динамического ремаркетинга Adwords с помощью Netpeak Spider
Кейсы

Этот пост будет полезен в решении рабочих задач PPC-специалистов. Я пошагово расскажу о проведении трёх кейсов, когда нет возможности подключить разработчика к проекту ;)
Кейс №1: На сайте внедрён тег ремаркетинга Adwords с динамическими параметрами. Есть фид, который скачивается по ссылке, но не обновляется автоматически, а значит неактуален.
Кейс №2: На сайте внедрён тег ремаркетинга с динамическими параметрами. Фид обновляется автоматически, но часть данных в фиде некорректна или отсутствует, а значит часть элементов фида не будет одобрена. Некорректными могут быть какие угодно данные: битые ссылки на изображения или товары.
Кейс №3: Нет ни фида, ни тега ремаркетинга Adwords.
1. Кейс №1
В этом случае нам нужно создать фид с нуля. Итак, приступим.
Для фида нам нужны такие столбцы:
- ID
- Item title
- Item subtitle
- Final URL
- Image URL
- Item description
- Price
- Sale price

Помните, что не все столбцы являются обязательными. Вы можете подробнее узнать об особенностях фида в Google Adwords здесь.
Значения для фида мы будем получать с помощью инструмента парсинга в Netpeak Spider.
1.1. Парсинг ID и цен для динамического фида
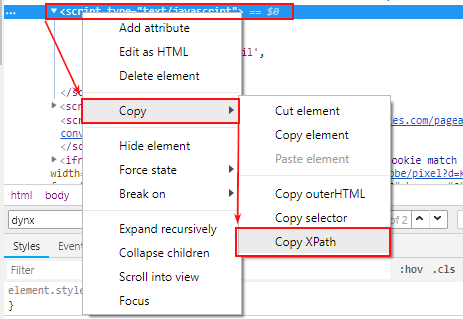
- Заходим на карточку товара и находим в коде сайта (Ctrl+Shift+I) наши динамические параметры для тега ремаркетинга.
- Нажимаем правой кнопкой мыши на тег script и копируем запрос XPath (он нам пригодится для настройки парсинга).
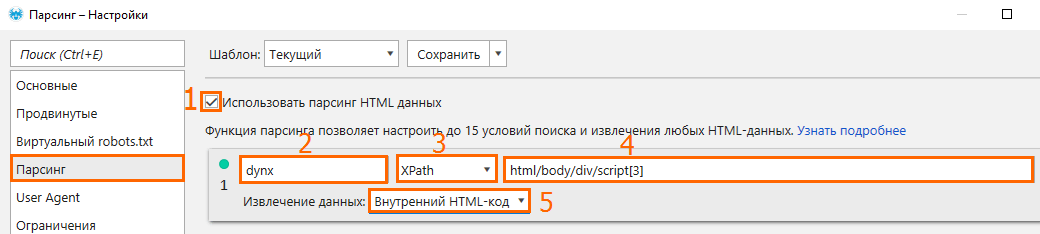
- Заходим в настройки парсинга в Netpeak Spider и указываем следующие настройки:
- в поле №2 задаём произвольное название;
- в поле №3 выбираем XPath;
- в поле №4 вставляем наш XPath запрос из пункта 2;
- в поле №5 выбираем «Внутренний HTML-код».
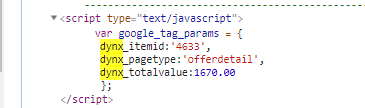
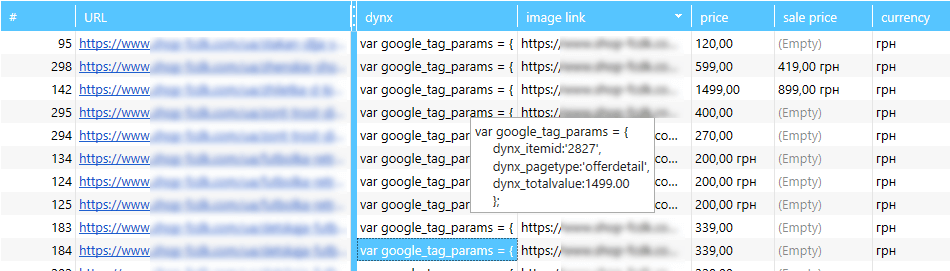
После запуска парсинга с данными настройками мы получим код скрипта по каждой странице сайта, который содержит данные ID и Price для нашего каталога товаров (фида).
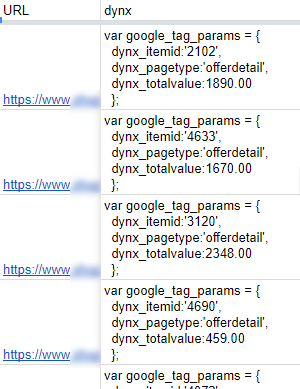
Останется только разделить полученную информацию на 2 столбца.
Вот как это можно сделать с помощью формул в Google Spreadsheets:

По такому же принципу с помощью парсинга (можно использовать как запросы XPath, так и CSS-селекторы) мы можем получить все остальные столбцы. Нужно только правильно задать в настройках парсинга запрос на языке XPath для соответствующих элементов на странице карточки товара. Далее рассмотрим ещё несколько примеров извлечения данных.
1.2. Image URL
Получаем значение XPath:
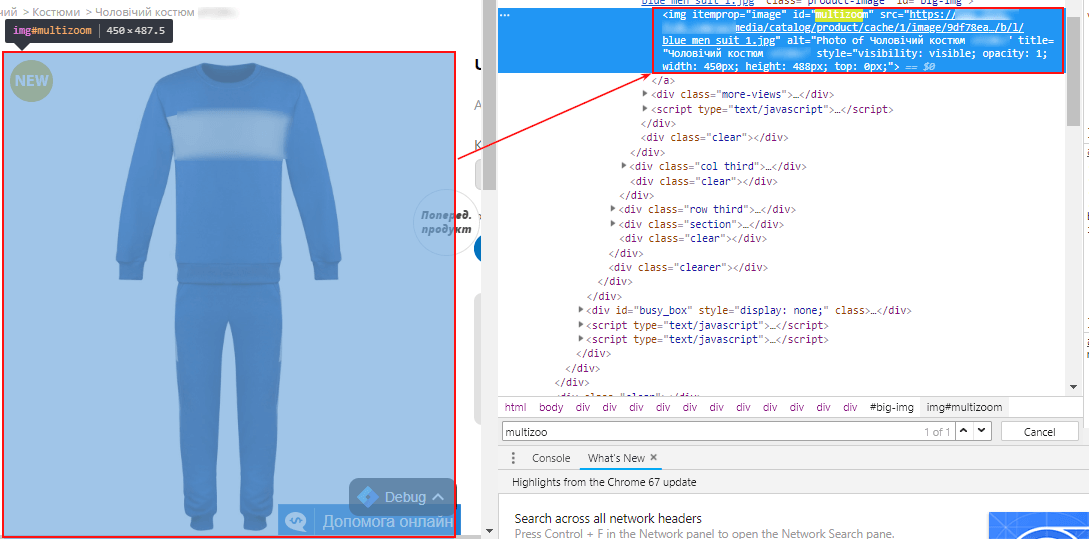
Задаем в настройках парсинга:
- XPath;
- XPath запрос;
- Тип извлечения данных — Значение атрибута;
- Название атрибута — «src» (содержит ссылку на наше изображение):

Результат парсинга:

1.3 Final URL
Это наше поле URL по умолчанию. Ничего настраивать в параметрах парсинга не нужно, значение URL будет в таблице.
1.4. Item title и Item description
Для заполнения Item title и Item description можно использовать значения метатегов Title и Description страницы. Для этого просто отметьте соответствующие параметры на боковой панели.
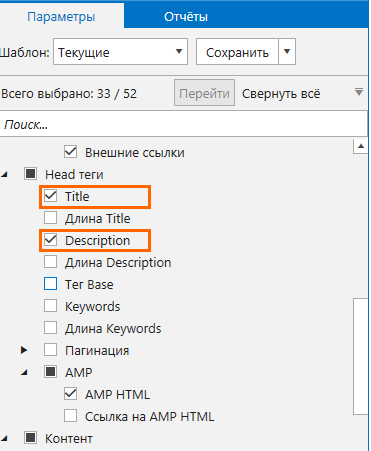
Разумеется, этот способ будет работать при условии, что на сайте правильно заполнены метатеги. В Item subtitle можно указать адрес домена.
1.5. Sale price
Если на сайте есть акционные товары, то можно в настройках задать дополнительное правило для извлечения цены товара со скидкой (параметр Sale price в фиде).
Элемент, значение которого нужно извлечь:
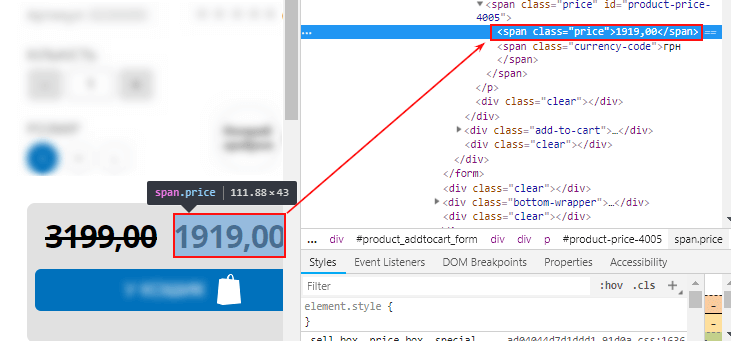
Настройки парсинга:

В нашем случае это запрос XPath, скопированный вот таким способом:
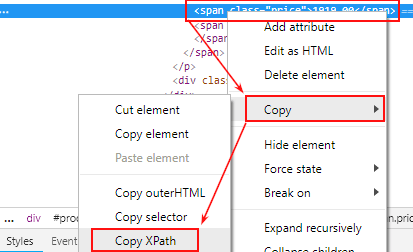
И получили такой результат:
Изначально я не парсил нужное нам значение цены товара со скидкой. Поэтому вручную был написан правильный запрос XPath и указан в настройках:
С таким приходится сталкиваться довольно часто. Рекомендую изучить основы синтаксиса XPath. Парсить станет намного проще ;)
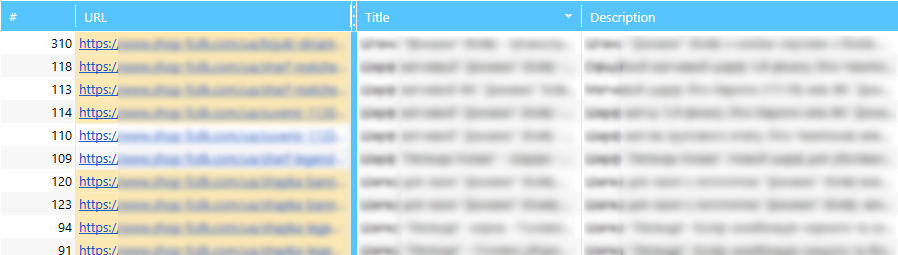
В принципе, это все настройки. В результате парсинга вы получите 2 таблицы:
- Все результаты (здесь нам нужны поля URL, Title, Description):
- Сводка с извлечёнными данными с помощью парсинга:
У Netpeak Spider есть бесплатная версия без ограничений по времени, в которой у вас будет возможность парсить данные для динамического фида и другие данные с сайта, используя до 100 условий парсинга! Также во Freemium-версии доступны и многие другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.Теперь остаётся свести обе эти таблицы в одну. Сделать это можно с помощью функции QUERY в Google Spreadsheets. Рекомендую прочесть подробное руководство по функции QUERY.
Также мы подготовили документ с примером того, как это можно сделать. Перед работой скопируйте его себе. Функция Query находится на вкладке «Feed Adw – step1» в ячейках столбца E:

2. Кейс №2
Ситуация схожа с первым кейсом. Если вы создаёте фид с нуля, то все действия выполняйте по инструкциям выше.
Если же вам не нужно создавать каталог с нуля, а нужно просто дополнить его какими-то данными (к примеру, добавить столбец, которого нет в исходном фиде), либо исправить значения ссылок в столбце Image URL — задача становится проще.
Парсите нужные данные по списку URL из исходного фида и дополняйте его новыми данными (снова используем функцию QUERY, чтобы сопоставить значения из двух таблиц).
3. Кейс №3
Отличие данного кейса в том, что на сайте нет тега ремаркетинга, и данные ID и Price взять из динамических параметров не получится. Решается проблема в 2 этапа:
- Парсим данные по инструкциям выше с единственным отличием: в качестве ID для элементов фида используем артикул/код на карточке товара. Price также вытягиваем из карточки товара.
- Настраиваем тег ремаркетинга Adwords через Google Tag Manager самостоятельно. В переменную dynx_itemid передаем артикул/код на карточке товара. Таким образом основная задача — это добиться совпадения ID элемента в фиде и dynx_itemid на страницах карточек товаров.
Этот вариант самый сложный и надеюсь, что вы в такой ситуации не окажетесь. Его мы рассматривать не будем. Лучше найдите разработчика =)
Подводим итоги
Создание фида для динамического ремаркетинга с нуля может стать трудной задачей для PPC-специалистов. Однако этот процесс может стать гораздо проще с помощью парсинга данных в Netpeak Spider. Следуя инструкциям из этого поста, просто извлеките такие необходимые элементы:
- ID
- Item title
- Item subtitle
- Final URL
- Image URL
- Item description
- Price
- Sale price
И обязательно расскажите в комментариях, какие решения вы используете для представленных мной кейсов ;)


