Как парсить цены из интернет-магазинов с помощью Netpeak Spider
Кейсы

Парсинг данных — процедура длительная и трудозатратная, но без неё не обходится ни один масштабный конкурентный анализ. С помощью Netpeak Spider вы можете упростить и автоматизировать этот процесс, извлекая и экспортируя всю необходимую информацию при помощи функции «Пользовательский поиск».
В рамках данной статьи мы на примере парсинга цен из интернет-магазина skay.ua покажем, как можно собрать, отфильтровать и экспортировать цены конкурентов.
На деле возможности пользовательского поиска не ограничены исключительно ценами: вы можете парсить множество других данных, за исключением тех, которые защищены или закрыты в коде сайта.
1. Механика пользовательского поиска
Пользовательский поиск — это функция Netpeak Spider, которая позволяет производить поиск по сайту и извлекать необходимые данные из веб-страниц. Всего в программе доступны 4 вида поиска:
- Содержит («только поиск»);
- RegExp («поиск и извлечение»);
- CSS-селектор («поиск и извлечение»);
- XPath («поиск и извлечение»).
Мы будем использовать XPath, который в большинстве случаев подходит для парсинга данных из интернет-магазинов. Однако отдельно отметим, что в зависимости от строения сайта могут использоваться и другие виды поиска.
Детальную информацию о каждом из них можно найти в обзоре функции.
2. Определение необходимого элемента для поиска
Для старта парсинга следует сперва определить код элемента искомых данных (в нашем случае — цены).
Чтобы получить код элемента, необходимо:
- Открыть страницу товара;
- Выделить цену;
- Кликнуть по ней правой кнопкой мыши и нажать «Показать код элемента» (или «Inspect», если вы используете англоязычный интерфейс);
- В открывшемся окне найти элемент, отвечающий за цену (он будет подсвечен);
- Кликнуть по нему правой кнопкой мыши и выбрать «Копировать» → «Копировать XPath».
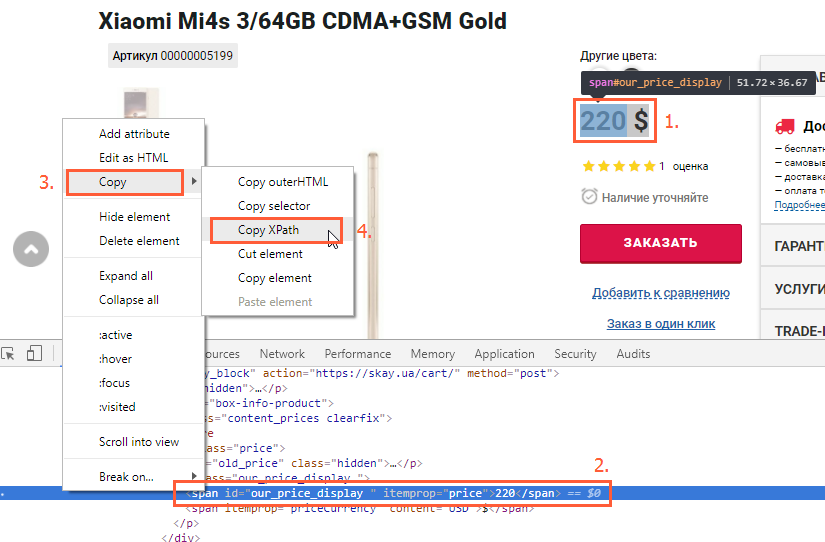
Обычно достаточно скопировать XPath из кода одной страницы товара, чтобы спарсить цены всего магазина или определённой категории, но только в том случае, если все карточки имеют одинаковый шаблон.
3. Настройка и запуск сканирования
3.1. Настройка пользовательского поиска
Пользовательский поиск можно осуществить в несколько простых шагов:
- В быстрых настройках слева от адресной строки выбираем режим сканирования «По всему сайту».
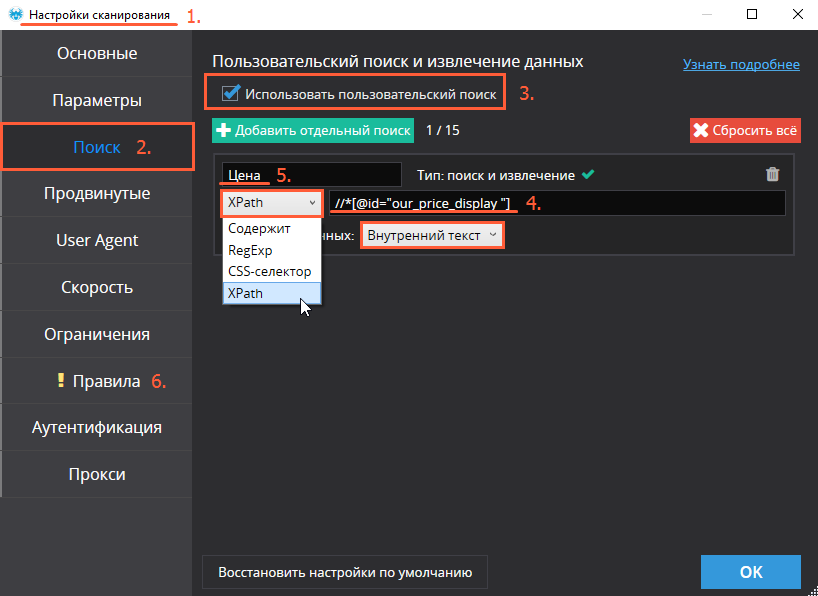
- В «Настройках сканирования» переходим к разделу «Поиск».
- Включаем «Использовать пользовательский поиск».
- Выбираем режим поиска «XPath» и в строку рядом вставляем код элемента, который мы нашли ранее. Режим извлечения данных — «Внутренний текст». В случае, если вам нужно спарсить несколько различных типов данных помимо основной цены (старая цена, объём скидки, артикул, количество и так далее), вы можете добавить ещё один параллельный поток поиска. Максимальное количество одновременных потоков поиска — 15.
- Даём имя каждому из поисков, чтобы не запутаться в финальных результатах парсинга. У нас поток поиска всего один, и он отвечает за извлечение ценовых данных.
- Переходим в раздел «Правила».
3.2. Настройка правил и запуск краулинга
В том случае, когда нам нужны все товары на данном сайте, либо же мы просто не можем выделить из них какую-то определённую категорию (адреса нужных нам товарных страниц не отличаются некой характерной особенностью и не включают единый для всех элемент), мы выставляем параметры пользовательского поиска, описанные в п.3.1, и запускаем сканирование всего сайта с настройками, которые выставлены в программе по умолчанию.
Если на сканируемом сайте URL построены по схеме site.com/категория/товар или site.com/категория-товар, мы можем воспользоваться набором пользовательских правил.
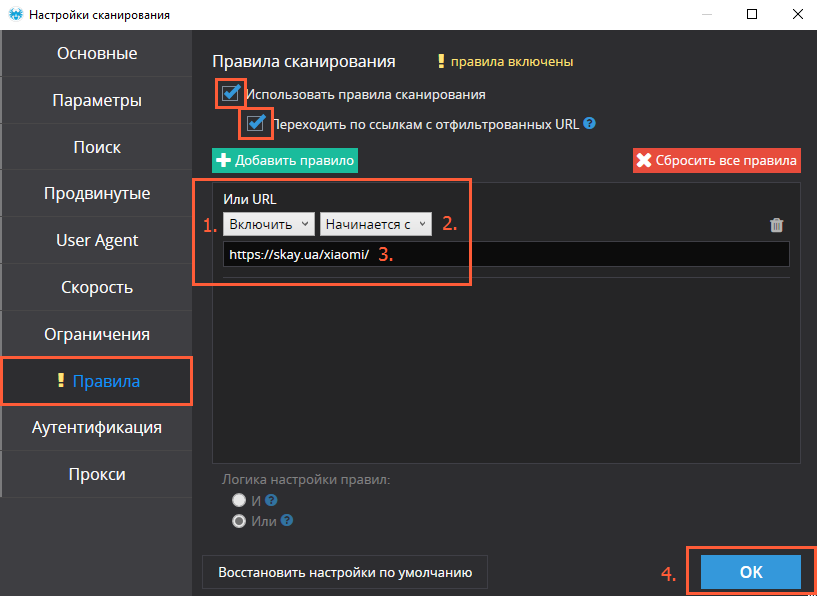
В рамках текущего поиска нас интересуют товары Xiaomi, все адреса которых начинаются со skay.ua/xiaomi/.

«Правила» в «Настройках сканирования» позволяют нам добавлять в таблицу результатов сканирования только те страницы, которые соответствуют заданным условиям (в нашем случае — определённому формату: skay.ua/xiaomi/артикул-товара).
Это можно сделать двумя способами: включая только страницы определенного вида либо же, наоборот, исключая какой-то определенный тип товаров, который нас не интересует. Вот как это настроить:
- Выбираем опцию «Включить» или «Исключить».
- Выбираем тип соответствия (в нашем случае — «начинается с»).
- Вставляем ту часть URL, которая повторяется у всех товаров интересующей нас (или наоборот, нежелательной) категории.
Если вы задаёте сразу несколько правил, то можете выбрать логику «и»/«или», чтобы краулер фильтровал страницы по одному из правил или по всем одновременно.
- Применяем настройки и запускаем сканирование.
Если вы выставили ряд правил для краулинга, Netpeak Spider в результатах поиска отобразит только те страницы, которые отвечают заданным условиям.
В крайнем правом столбце результатов сканирования (по умолчанию он называется XPath, но мы назвали его «Цена») вы найдёте данные о поиске указанных данных. В этом столбце будет отображаться количество значений искомого элемента на каждом отдельном URL (1 товар = 1 значение). Общее количество найденных цен вы сможете найти на боковой панели → вкладка «Поиск».
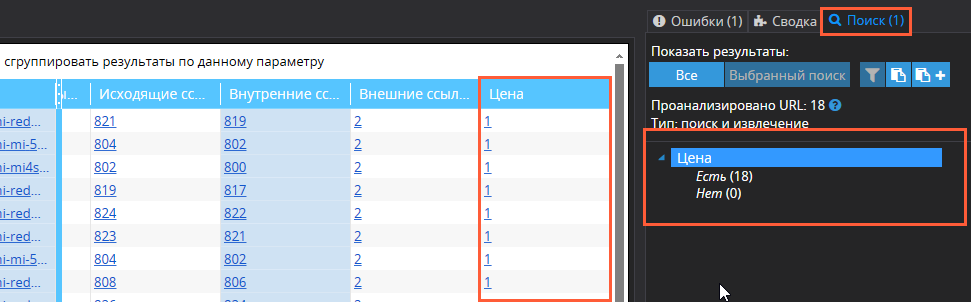
Отдельно обратим ваше внимание, что в основных настройках сканирования будет лучше отключить анализ изображений. Иногда адреса и имена изображений совпадают с адресами товаров, а потому могут попасть в ваш фильтр, и список страниц придётся чистить.
У Netpeak Spider есть бесплатная версия без ограничений по времени, в которой у вас будет возможность парсить сайты, используя до 100 условий парсинга! Во Freemium-версии также доступны и многие другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.4. Экспорт полученных данных
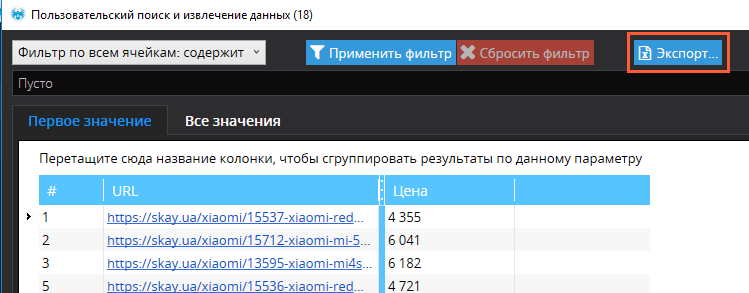
Для того, чтобы получить таблицу, содержащую исключительно адреса страниц и данные о ценах, выполните следующие действия:
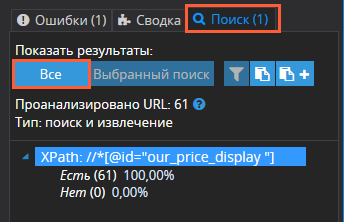
- Откройте вкладку «Поиск» на панели справа.
- Под строкой «Показать результаты» выберите «Все».
- Отфильтруйте полученные данные при необходимости.
- Нажмите «Экспорт» для сохранения таблицы.
Подводим итоги
Для того, чтобы спарсить данные с сайтов-конкурентов, необходимо совершить ряд последовательных действий:
- Определите элемент для парсинга (в нашем случае, цену).
- Скопируйте XPath.
- Задайте настройки пользовательского поиска.
- Выставьте правила для выборочного сканирования.
- Запустите сканирование.
- Экспортируйте полученные данные.
Описанным выше способом можно извлекать и экспортировать не только цены, но и многие другие типы данных. За счёт этого подобный функционал может быть полезен интернет-маркетологами, специалистам по контенту, SEO-специалистам, вебмастерам, менеджерам по продажам, а также ряду других специалистов.
А вы используете этот функционал в своей работе? Если да, то с какой целью?
Делитесь своим опытом в комментариях, а также задавайте вопросы, связанные с пользовательским поиском: мы с радостью на них ответим :)
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider



