In-Depth SEO Audit with Website Spider Tool
No more SEO audit hassle — with our website spider tool, get spot-on crawling results for any target website in a few minutes.
For Windows & macOS



💡 How to Get Started with Netpeak Spider
 The Key Perks of Our SEO Audit Tool
The Key Perks of Our SEO Audit Tool
TOP Netpeak Spider Site Crawler Features
1. Windows & macOS compatibility
Discover the possibilities of Netpeak Spider, designed for both Windows and macOS users.

2. Overview of 100+ issues with proper prioritization
Netpeak Spider runs an in-depth technical site audit and detects broken links, duplicate pages, faulty meta tags, and other issues. With this tool, you also get a detailed description of every visible issue: the kind of threat it carries, tips on fixing it, and even a list of helpful links with extra information. Apart from that, our site crawler categorizes issues by severity and color-codes them for your convenience.

3. JavaScript rendering
Our website crawler tool lets you crawl URLs with JavaScript (or JS) scripts. To execute that, Netpeak Spider uses one of the latest versions of Chromium. Using this version makes web page crawling as similar to Googlebot as possible.

4. Multi-window mode
As a professional SEO audit tool, Netpeak Spider lets you work on numerous projects simultaneously. Launch the app in separate windows and work in each one of them at the same time.
Experience Netpeak Spider on macOS
Get actionable audit results within minutes and unleash the power of a Mac-compatible SEO analysis tool.
Try for 3 days · Then $20 per month · Cancel anytime
Functionality and Usability
1. Data filters and segmentation
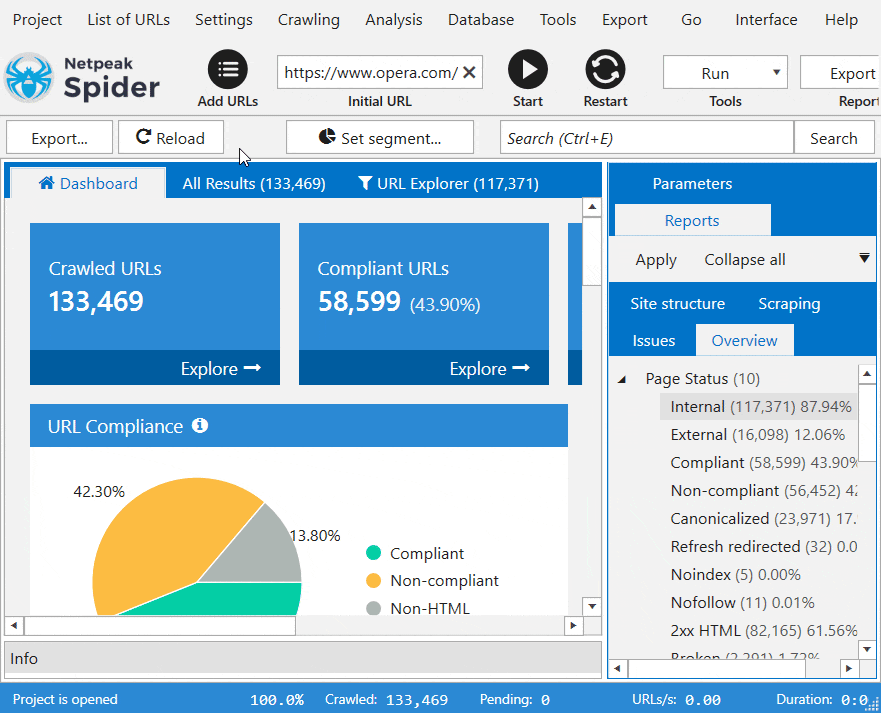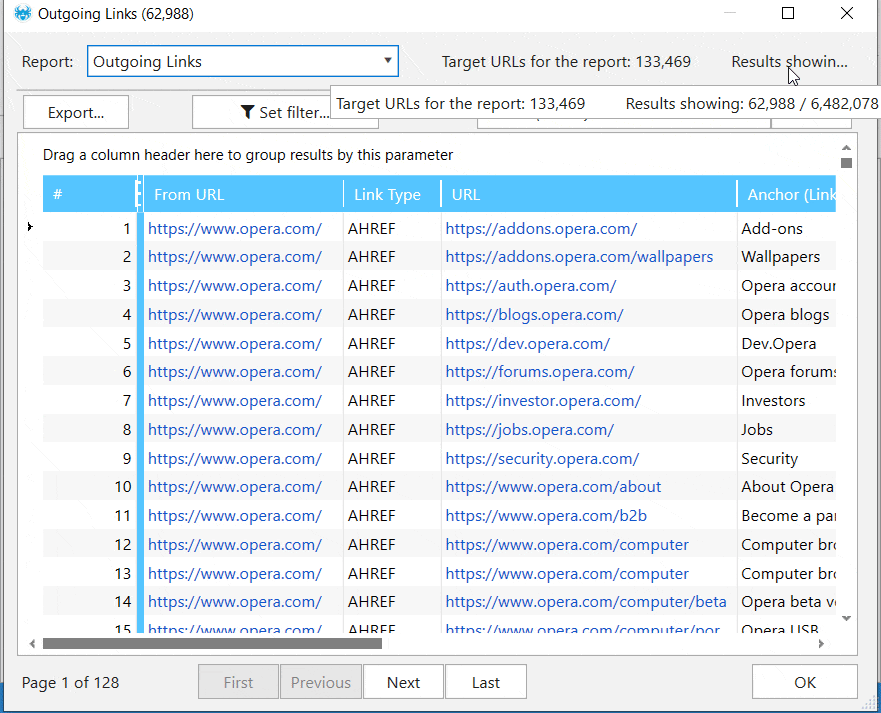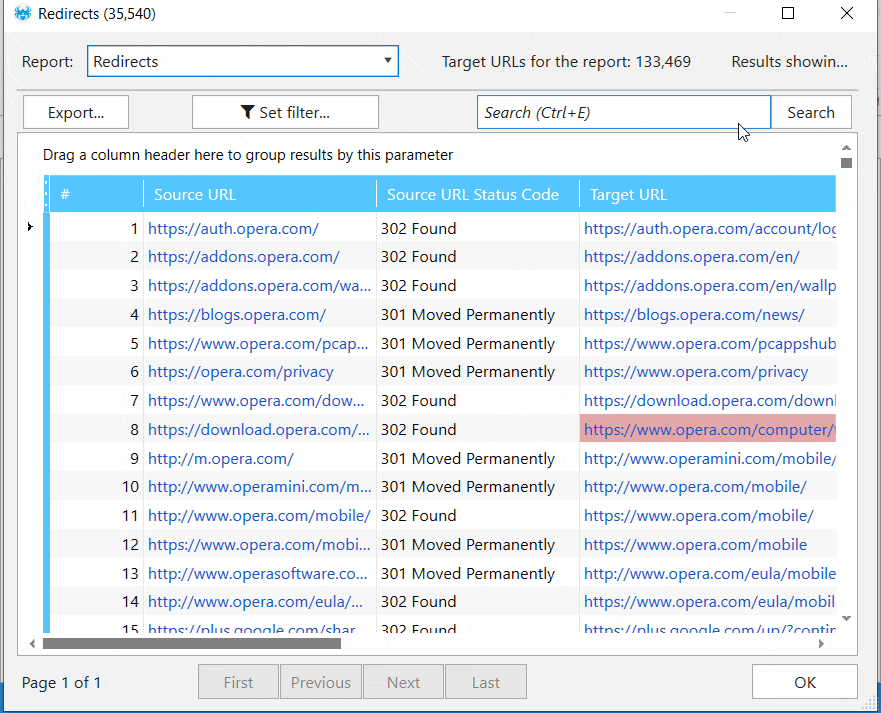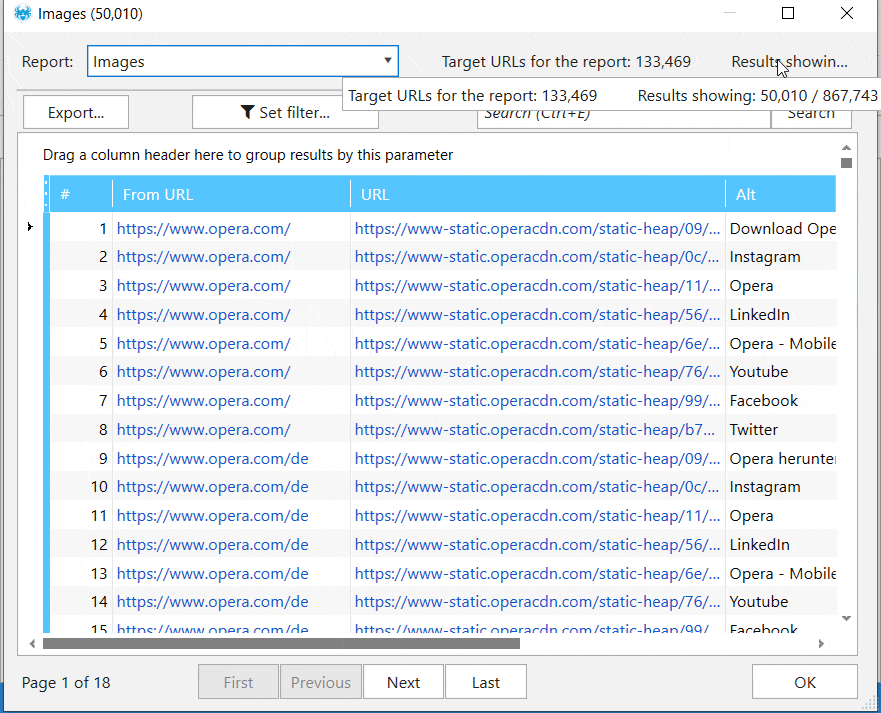
Data filtering will come in handy while crawling large websites. Retrieve in-depth insights on your site data segment by segment or focus on particular ones for more impactful website crawling results. Filter the results and overview the parameters available on the dashboard. Enable custom filtering conditions or change the data overview in the program by setting up relevant limits for a particular segment.

2. Real-time interactive dashboard
The smart dashboard changes its state depending on the stage of spidering a website. You see the current settings (and can change them should you notice any mistakes). Once the crawling process is paused or complete, our tool shows you live charts with the required insights on the project.
3. Crawling settings management
For the most efficient SEO site audit, Netpeak Spider lets you choose, change, or disable specific crawling parameters and focus on the essential stats. This way, you speed up the crawling process and lower the RAM and processor resource consumption. Enjoy a handy search by parameters and quickly analyze the most needed ones. Even if you've requested crawling of all the available parameters, removing the unnecessary ones is possible. Simply sync the results table with the stats you need.

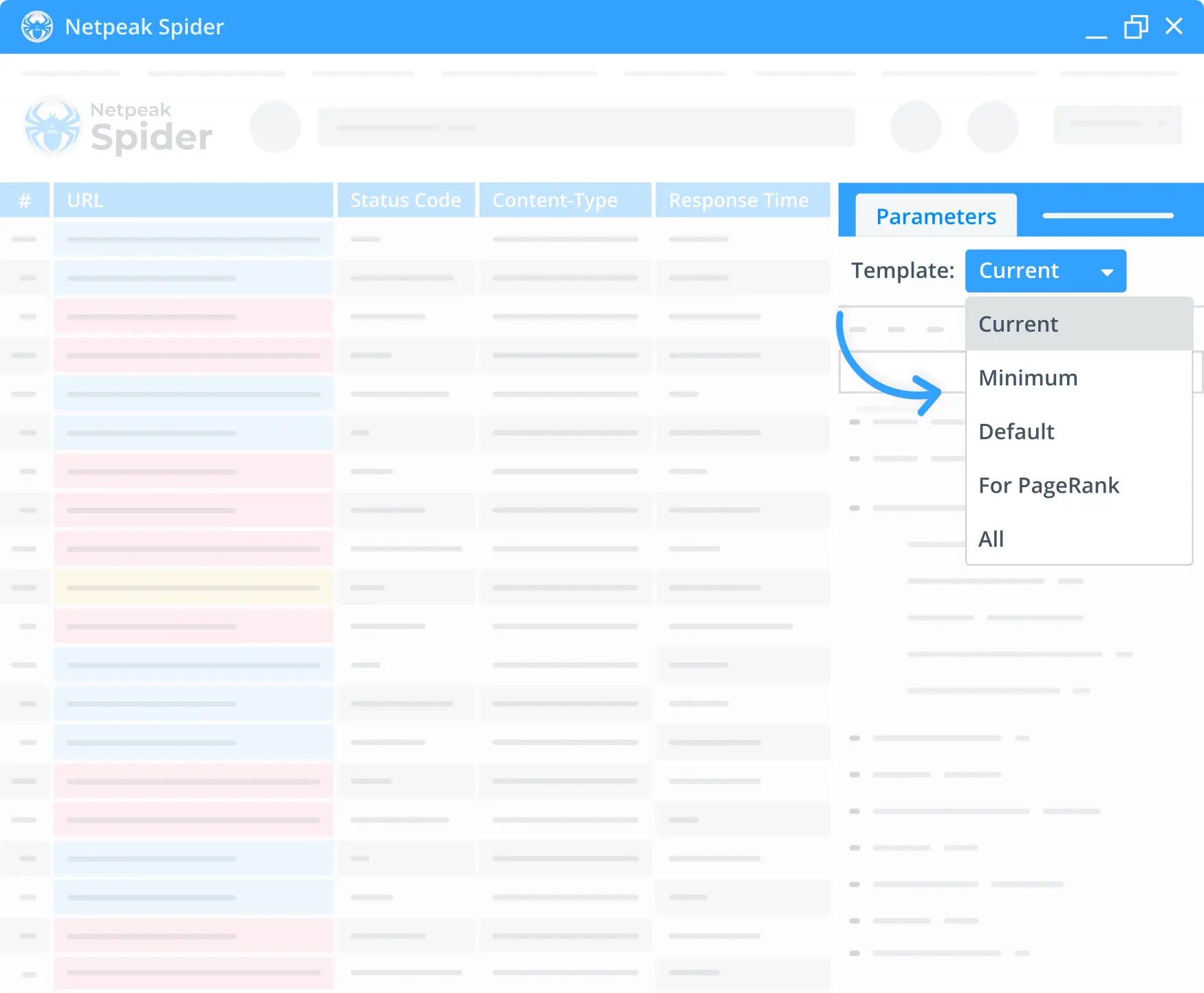
4. Templates for filters, parameters, and segments
Easily create and save your own templates with the desired parameters, segments, or settings you'd like to check and avoid extra manual work. Netpeak Spider also provides pre-made default templates to facilitate the SEO website audit.
Available Built-in Tools
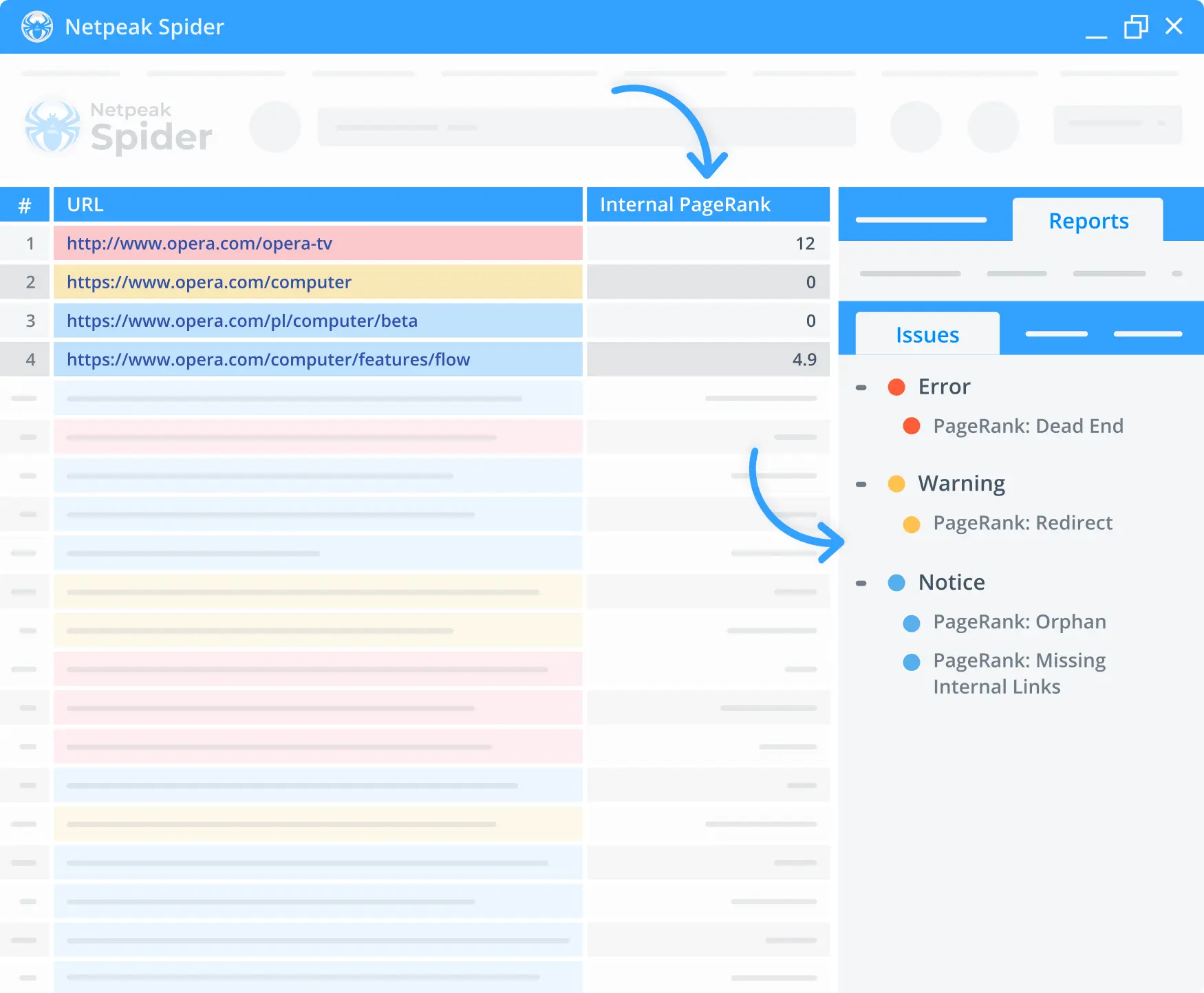
1. Internal PageRank calculator
Use the built-in PageRank calculator in our free website audit tool to check your page's internal linking. Check out the link weight distribution, what pages burn incoming link equity, and which ones don't get any at all.
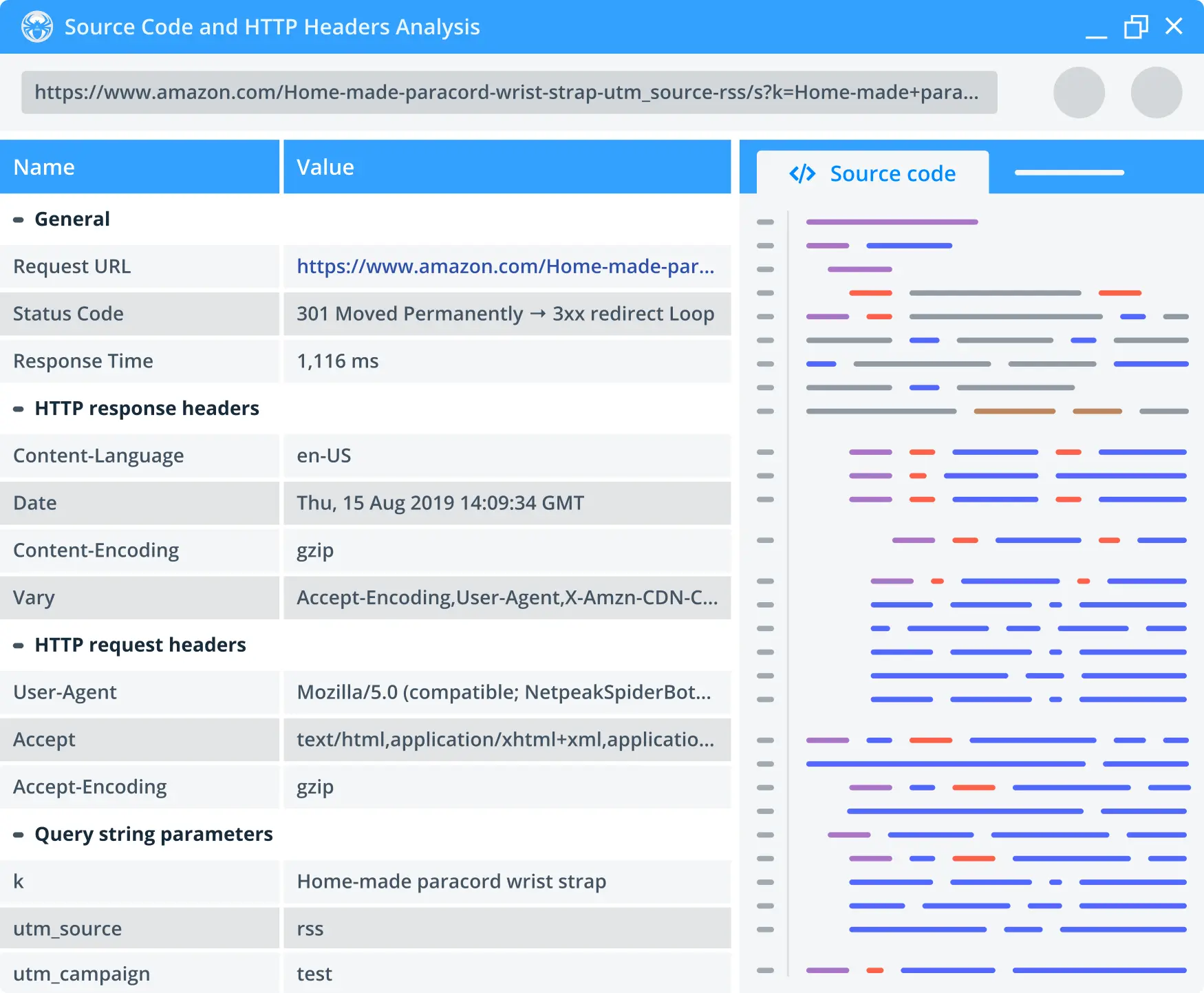
2. Source code and HTTP headers check-up
You no longer need to open a page in a browser to check out its source code. The built-in tool in Netpeak Spider allows checking any link's HTTP request and response headers, redirects, and all the extracted text with no HTML code.
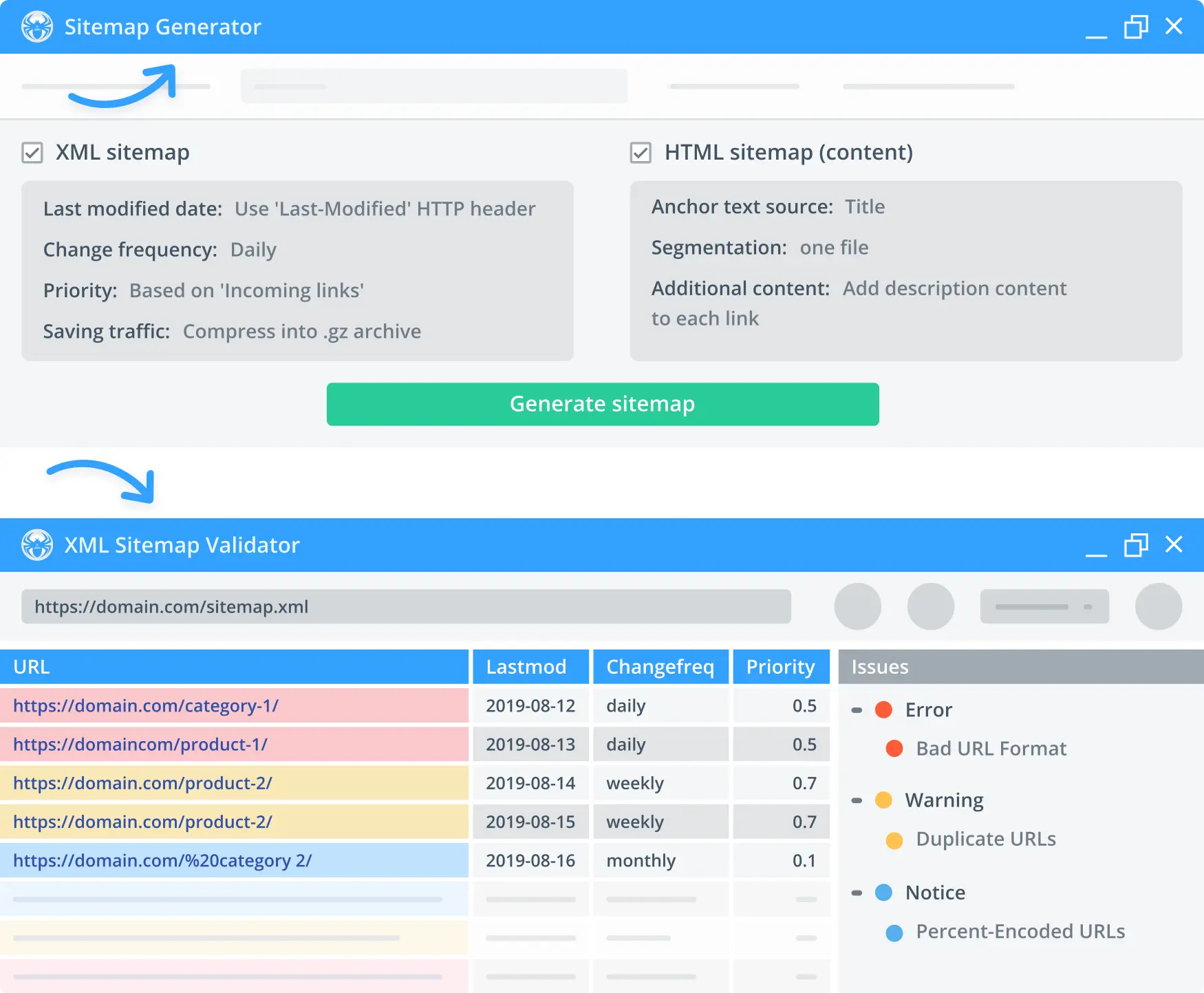
3. Sitemap generation and validation
Crawl site with Netpeak Spider and generate XML, HTML, or image sitemaps afterwards. Our tool also allows you to check for errors within existing sitemaps.
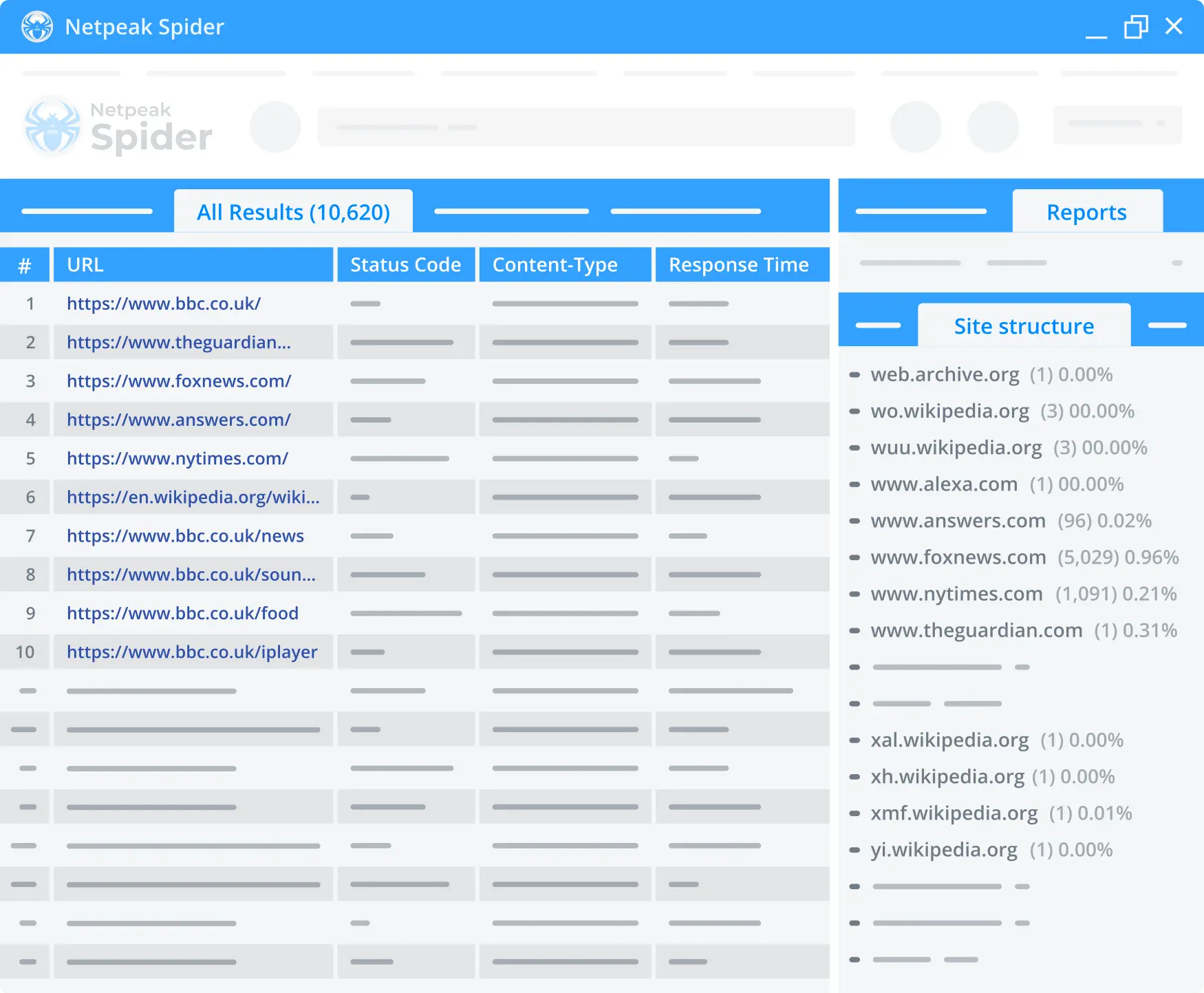
4. Multi-domain crawling
Crawl multiple URLs and retrieve a comprehensive SEO audit report in one convenient table. This option works great while working on projects with regional websites on different domains.
Reports Available in Netpeak Spider
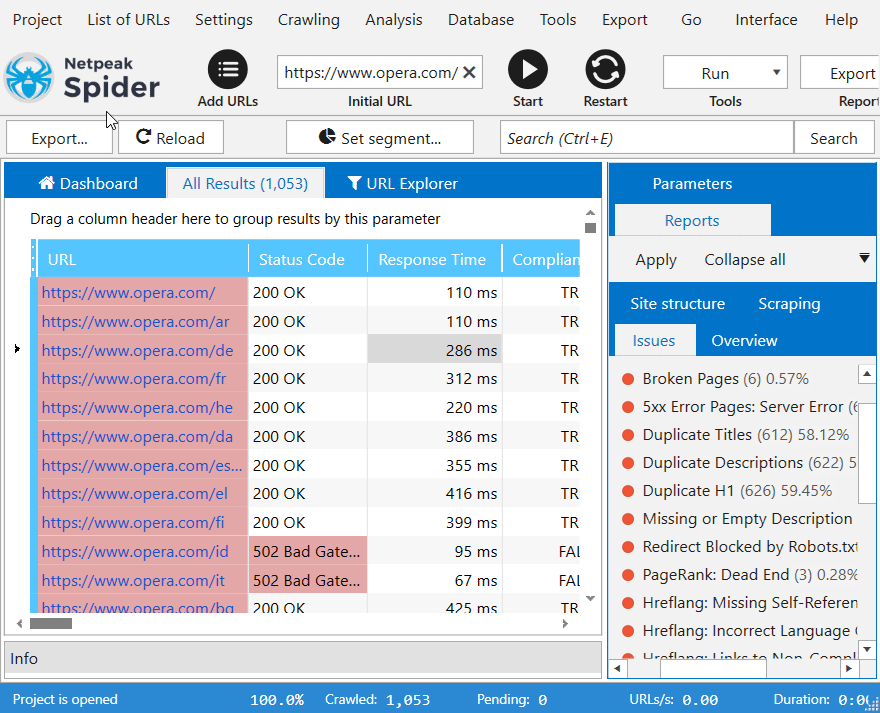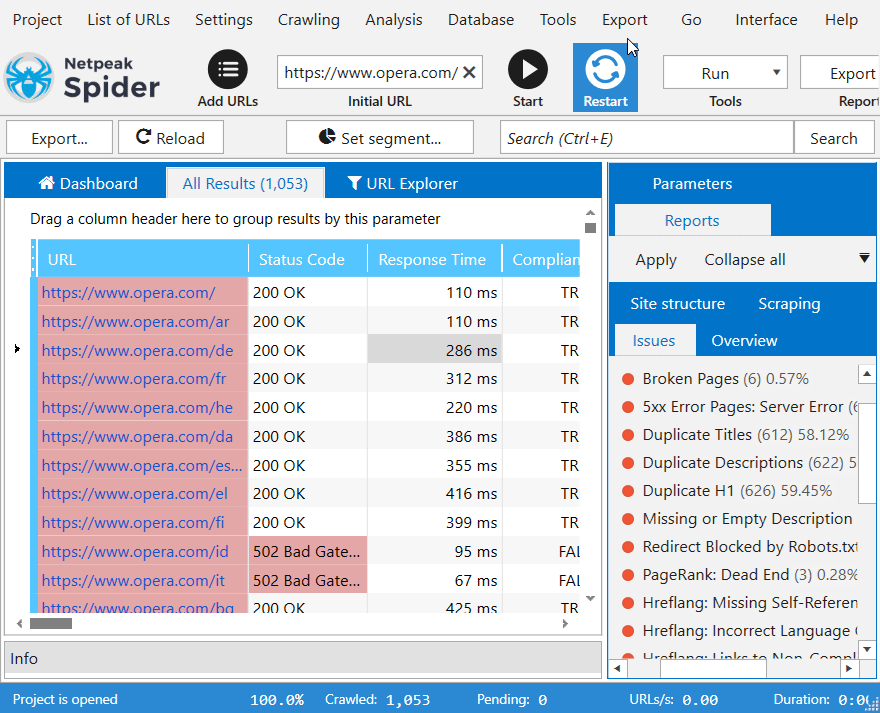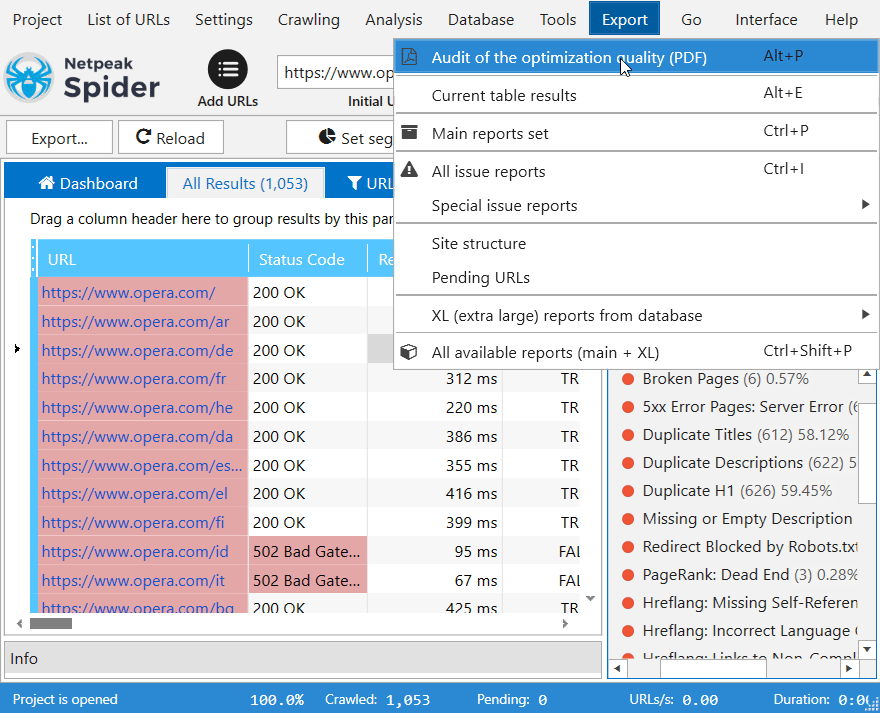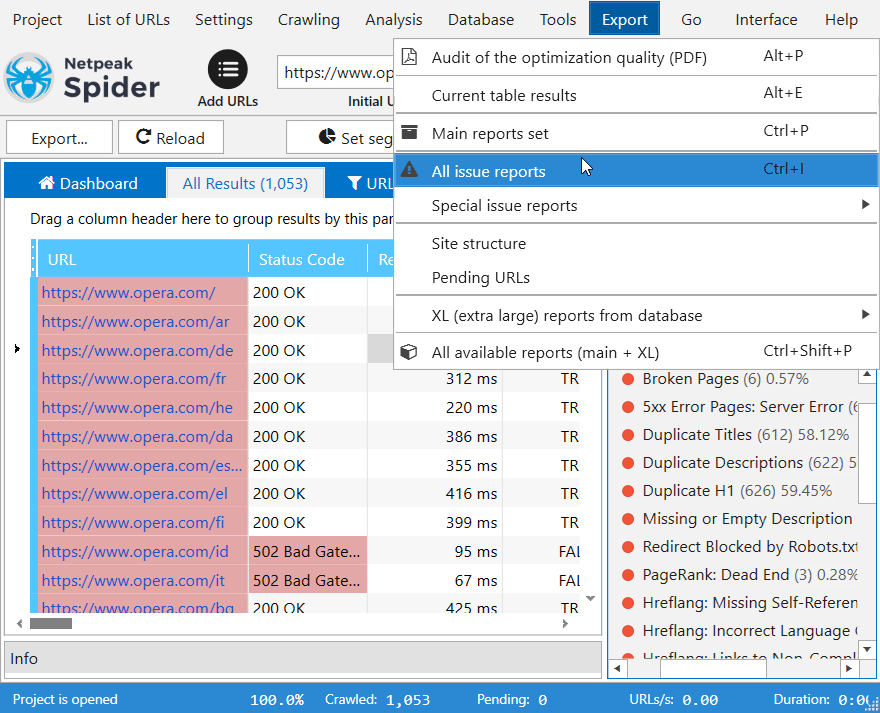
1. Audit of the optimization quality in PDF
Our SEO audit software runs an express analysis of the optimization quality and delivers the results in a convenient PDF format. Quickly access the latest data on your project and get the in-depth result visualization via diagrams and charts.

2. White label reports with SEO audit
The white-label feature lets you generate a website SEO audit report in PDF featuring your company's logo, contacts, and recommendations from the specialist. Use this feature for SEO service pre-sales.
3. Complex site structure check-up
Our site audit tool helps see the site's structure based on link segments. Netpeak Spider provides statistics on the URL's number and percentage at each level. It's also possible to filter the table by a particular website area for further analysis.

4. Custom website scraping and data extraction
Netpeak Spider includes a built-in website scraper. Here, choose up to 15 conditions and four search types (contains, Regexp XPath, CSS). This helps you scrape contacts, markup, content, social media metrics, competitor prices, etc.

Integrations Supported by Netpeak Spider
1. Google Analytics & Search Console
Enrich the data received from our website audit tool by retrieving stats from Google Analytics. Get helpful insights on traffic, goals, conversions, and even e-commerce parameters for any target website.

2. Export of Search Queries from Google Search Console
Analyze the data from Google Search Console in the "URL- search query - major metrics" format. The gathered data includes impressions, clicks, CTR, and average position.

3. Integration with Google Drive / Sheets
Quickly export reports straight to Google Sheets with no limits and share them with your colleagues in just a few clicks. Our website spider tool exports PDF reports to Google Drive right away, so you'll only have to get a shareable link and send it to a project manager or client.

4. SEO Audit Data Enrichment
Netpeak Spider allows you to upload your own data from a CSV file into the app to better analyze, filter, and segment the target URLs.

Working with Heavy Data and Export
1. Optimal RAM Consumption
With JavaScript rendering enabled, our spider crawler tool uses 3x less RAM and 8x less RAM — without rendering. Moreover, there's no need to manually choose the data storage mode since we use our internal database by default. This lets Netpeak Spider not affect the crawling speed at all.

2. Bulk export
Export all the available reports, or just the ones needed, in a few clicks after you spider a website. CSV, XLSX, and PDF formats are available.
3. Internal Database
The internal database of our SEO spider tool is capable of working with massive amounts of URLs. There's no need to export the results to Excel or Google Spreadsheets. It's possible to analyze any parameter, like links, redirects, or images, for one or multiple URLs right in the app.
Support and Updates
1. Automatic software update
We automatically update Netpeak Spider to the latest version once it's live, so you can audit website stats with no glitches or freezes.
2. Knowledge base
Get the answers to all your questions about Netpeak Spider in our Knowledge Base.

3. Support via tickets
Quickly find solutions through our Help Center or request additional assistance by opening a ticket. Usually we respond within 24 hours during working days.

Netpeak Spider SEO Audit Tool Features
Familiarize yourself with the other features of Netpeak Spider Crawler Tool.

Title Tag Checker
Leverage our meta title checker to boost your website’s SEO performance and impress search engines and your audience.

Backlink Checker
Enhance your SEO strategy and online presence using our user-friendly backlink analytics tool.

Link Extractor
With the right tools, you can easily find all links on a website and assess its internal link structure. Link extractor helps to crawl a URL and extract links from the website.
Why our clients choose Netpeak Spider
Our numerous awards and reviews speak for themselves. Learn what industry leaders and top specialists appreciate about our tools


Double the Effectiveness of Your SEO Strategy ⭐️
Run a 100% efficient SEO site checkup with the help of our two powerful tools. Get Netpeak Spider & Checker and boost your website's performance.
