Как найти дубликаты с помощью Netpeak Spider
Кейсы

Дублирование контента — довольно распространённая проблема не только сайтов электронной коммерции, но и других типов веб-ресурсов. И хотя из-за одних лишь дублей сайт не будет наказан поисковыми системами, их основная угроза для оптимизатора в том, что они препятствуют продвижению отдельных страниц.
В рамках этого поста я расскажу, что такое дубли, и какой ещё вред они могут нанести, как их найти и устранить.
1. Что такое дубликаты, и в чём их опасность
Дубли — это страницы с одинаковым или частично одинаковым содержимым. Когда по разным адресам доступны страницы с идентичным контентом, поисковые системы попросту не могут отличить одну страницу от другой и считают их равноценными. Поэтому в результатах выдачи может оказаться URL, который там быть не должен.
Для больших сайтов наличие дубликатов может представлять ещё одну опасность — из-за ограничений краулингового бюджета поисковые роботы могут не просканировать приоритетные URL, потратив основные ресурсы на обход дублей страниц.
2. Причины возникновения дубликатов
К самым распространённым причинам появления дублей страниц можно отнести следующие:
- Отсутствует склейка страниц с и без www, со слешем и без него, с протоколами http и https.
- Добавление get-параметров и utm-меток в URL.
- Неправильно выполнена смена структуры сайта.
- Автоматическая генерация дублей в различных CMS.
Причиной появления дубликатов title, description и H1 чаще всего является неправильная оптимизация (или её отсутствие) страниц, на которых содержание этих элементов генерируется автоматически по неверно настроенным шаблонам.
3. Типы дубликатов и способы их устранения
В пределах одного сайта могут встречаться следующие типы дубликатов:
- дубликаты страниц;
- дубликаты текста;
- дубликаты тегов title;
- дубликаты meta description;
- дубликаты заголовков H1.
Ниже я рассмотрю все типы дубликатов и расскажу, чем они грозят.
2.1. Дубликаты страниц
Дубли страниц — это идентичное содержимое всего HTML-кода на разных страницах. В незначительном количестве дубликаты страниц не станут причиной санкций со стороны поисковых систем, но если их на сайте много, это чревато растратой краулингового бюджета.
Как устранить дубликаты страниц: настройте 301 редирект с дубликатов на основной адрес страницы. Если страницу нужно удалить, настройте корректный 404 код ответа сервера и удалите все ссылки, которые вели на эту страницу.
Если дубликаты основной страницы необходимо оставить доступными к просмотру и сканированию, укажите приоритетную страницу с помощью тега <link rel="canonical" /> или HTTP-заголовка «Link: rel="canonical"».
2.2. Дубликаты текста
Страницы с одинаковым текстом могут отличаться названием, заголовком и метаописанием, но тем не менее поисковые роботы также расценивают их как дубликаты.
Как устранить дубли текста: заменить дублированный текст на уникальный. С не приоритетных для продвижения страниц можно настроить 301 редирект на основной URL страницы или же просто их удалить, выставив 404 код ответа сервера.
2.3. Дубликаты title
Тег title играет значительную роль в продвижении сайта, так как служит заголовком сниппета в поисковой выдаче. Его дублирование может привести к появлению в выдаче страниц, названия которых не соответствуют содержимому. В таких случаях поисковая система может сама составить заголовок сниппета, который с большой вероятностью будет совсем не кликабельным с точки зрения пользователей. Итог — потеря трафика из выдачи.
Как устранить дублированные title: для каждой страницы сайта необходимо прописать уникальный тег title, который будет сообщать пользователям и поисковым системам о содержимом страницы и содержать релевантный поисковой запрос. Рекомендованная поисковиками длина тега title составляет от 40 до 140 символов.
2.4. Дубликаты description
Метаописание влияет на формирование сниппета и непосредственно на CTR.
Потому важно, чтобы метаописание каждой отдельной страницы соответствовало её содержимому и побуждало пользователей перейти на сайт.
Как устранить дублированные description: оформить уникальные метаописания с содержанием релевантных ключевых слов для каждой целевой страницы. Рекомендуемая длина — от 100 до 260 символов.
2.5. Дубликаты H1
Если на страницах с разным контентом содержатся идентичные заголовки H1, поисковые роботы и посетители могут посчитать сайт некачественным.
Как устранить дубликаты заголовков H1: составить для каждой страницы уникальный, краткий и информативный заголовок длиной от трёх до семи слов.
3. Как найти дубли на сайте
Мы уже выяснили, в чём опасность дубликатов, и каких типов они бывают. Пора разобраться с главной задачей — найти их на своём сайте.
Сделать это можно в панелях вебмастеров Google и Яндекс.
В Google Search Console откройте отчёт «Покрытие» и в случае обнаружения ошибок, просмотрите, есть ли среди них дубликаты.
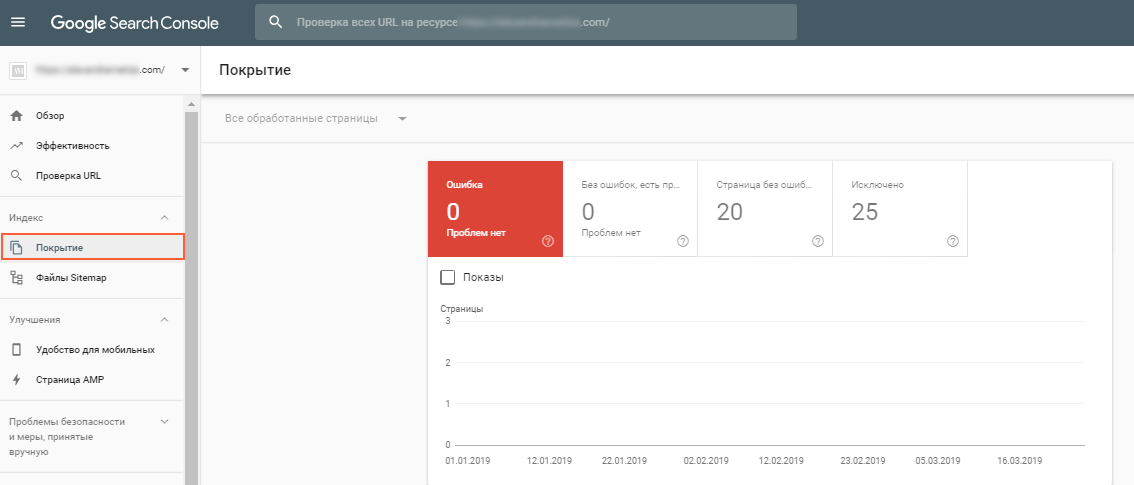
Чтобы найти дубли в Яндекс.Вебмастер, перейдите в раздел «Информация о сайте».
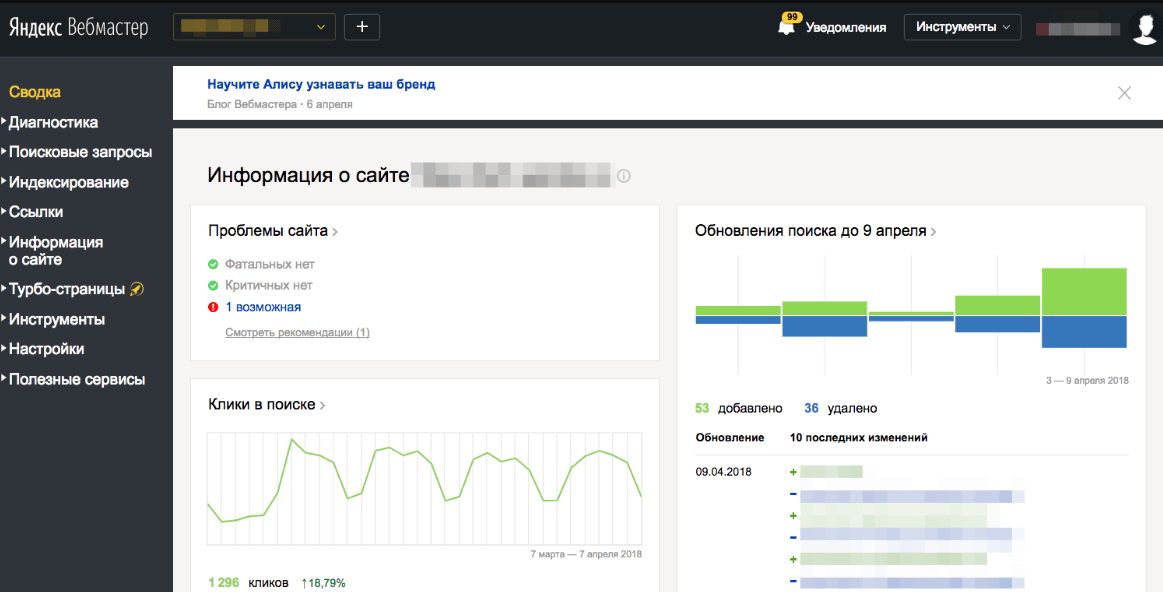
Существует также ручной способ поиска дублей с помощью оператора site:.
В поисковую строку введите фрагмент текста, затем добавьте поисковый оператор и домен сайта.
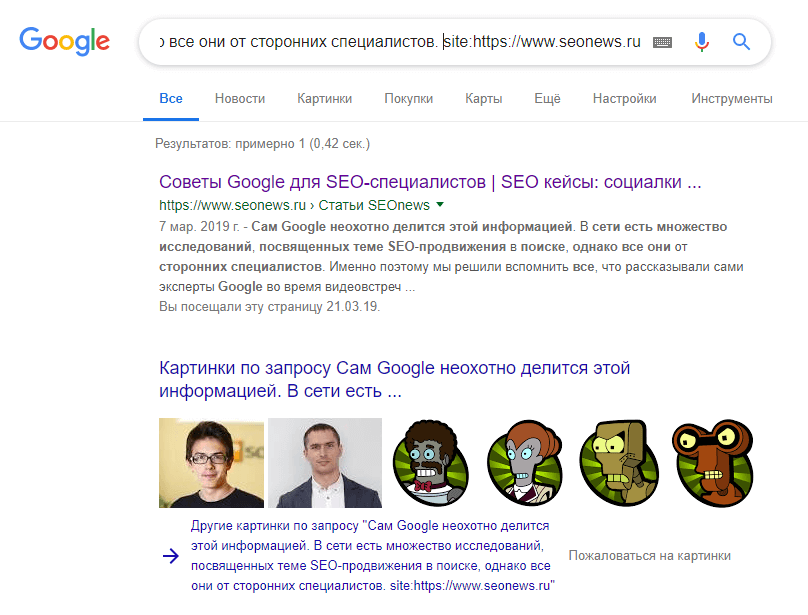
Чтобы не искать дубликаты вручную, советуем провести быстрый поиск каждого из типов дублей на сайте в Netpeak Spider.
- Запустите программу.
- Перейдите в меню «Настройки» и на вкладке «Продвинутые» отметьте каждый из пунктов в разделе «Учитывать инструкции по индексации», а также пункт «Next / Prev». Это нужно, чтобы краулер не определил как ошибку дубли, скрытые с помощью инструкций по индексации и атрибута canonical. Если скрытые дубли всё же попадут в результаты сканирования, это может говорить о проблемах с настройками инструкций или атрибута.
- Введите домен сайта в адресную строку и нажмите «Старт».
- По итогу сканирования на вкладке «Ошибки» посмотрите, нет ли найденных ошибок, связанных с дублированием контента.
- В случае обнаружения кликните по названию конкретной ошибки, чтобы ознакомиться с перечнем URL, на которых она присутствует.
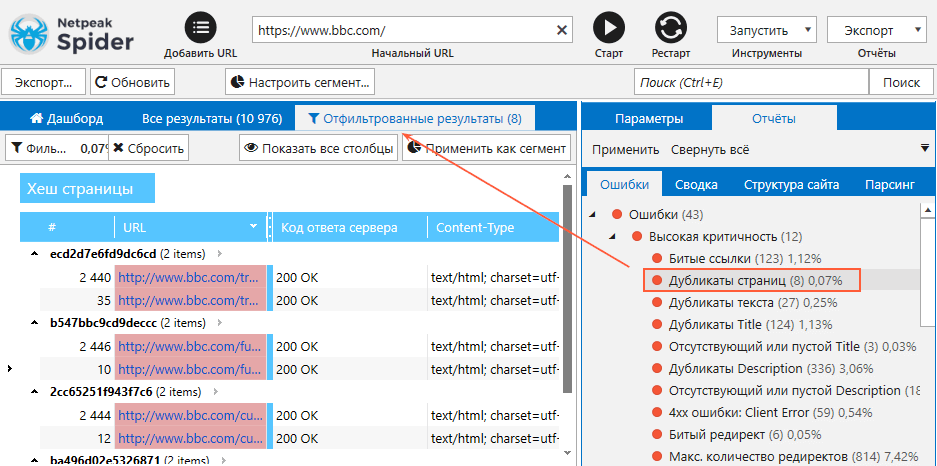
Выгрузите отчёт по дубликатам с помощью кнопки «Экспорт» и приступайте к внедрению исправлений.
Мы подготовили короткое и наглядное видео о том, как проверить дубликаты страниц и контента на сайте:
Чтобы начать пользоваться Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить программу
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.Подводим итоги
Дубликаты вредят продвижению страниц в органической выдаче — из-за них ваше время и ресурсы, вложенные в оптимизацию, тратятся впустую. Опасность заключается также в том, что дубликаты могут появляться и не по вашей вине. Регулярный анализ сайта на наличие дублей и своевременное их устранение — лучший способ не дать им шанса негативно повлиять на продвижение.
Искать дубли можно в панели вебмастеров, с помощью поискового оператора и краулера Netpeak Spider.
Самые действенные способы избавления от дублей страниц:
- настройка редиректа 301 на важную для продвижения страницу,
- реализация тега <link rel="canonical" /> или HTTP-заголовка «Link: rel="canonical"»,
- удаление страницы с правильной настройкой 404 кода ответа сервера.
Для устранения дубликатов title, description и H1 необходимо на каждой странице заполнить эти элементы контента уникальным текстом и желательно оформить согласно рекомендациям поисковых систем.
Поделитесь вашими методами поиска и борьбы с дублями в комментариях :)
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider



