Как искать домены с истёкшим сроком регистрации с помощью Netpeak Spider и Checker
Кейсы

Привет! Дропы — это домены с истёкшим сроком регистрации, которые никому не принадлежат в данный момент. И в этом посте я расскажу, как настроить поиск дроп-доменов с регистрацией, СМС и двумя неделями бесплатного триала наших продуктов. Пошагово пройдём по каждому этапу, чтобы найти заветные домены с истёкшей датой регистрации.
Также я поделюсь таблицей, где собрал все доступные к покупке дропы, на которые есть ссылки с трастовых ресурсов. Потому не отвлекайтесь на ваши любимые чаты и успейте выхватить нужные домены, которые разлетаются как горячие пирожки 😜
- 1. Площадки для поиска дропов
- 2. Проверка доменов на доступность к покупке
- 3. Дроп-домены бесплатно
- 4. То, что обычно пишут мелким шрифтом
1. Площадки для поиска дропов
С чего всё началось? В моём арсенале были:
- подписка на Netpeak Spider Pro и Checker,
- не самый мощный сервер на 24 ГБ оперативки,
- огонь в глазах.
Этого было достаточно, чтобы найти 12 246 дроп-доменов, хотя качество многих сомнительное. Я поделюсь полным списком, потому что цель поиска дропов не всегда ограничивается ссылками, вдруг вам дизайн или контент понравится 😃
Работал я по такому принципу: нужно спарсить как можно больше страниц трастовых ресурсов, достать из них внешние ссылки и найти доступные домены. Метод называется «дёшево и работает», делюсь пошаговым алгоритмом.
1.1. Выбор площадок для поиска дроп-доменов
Я отбирал самые крутые информационные ресурсы согласно рейтингу сайтов в SimilarWeb и Ahrefs.
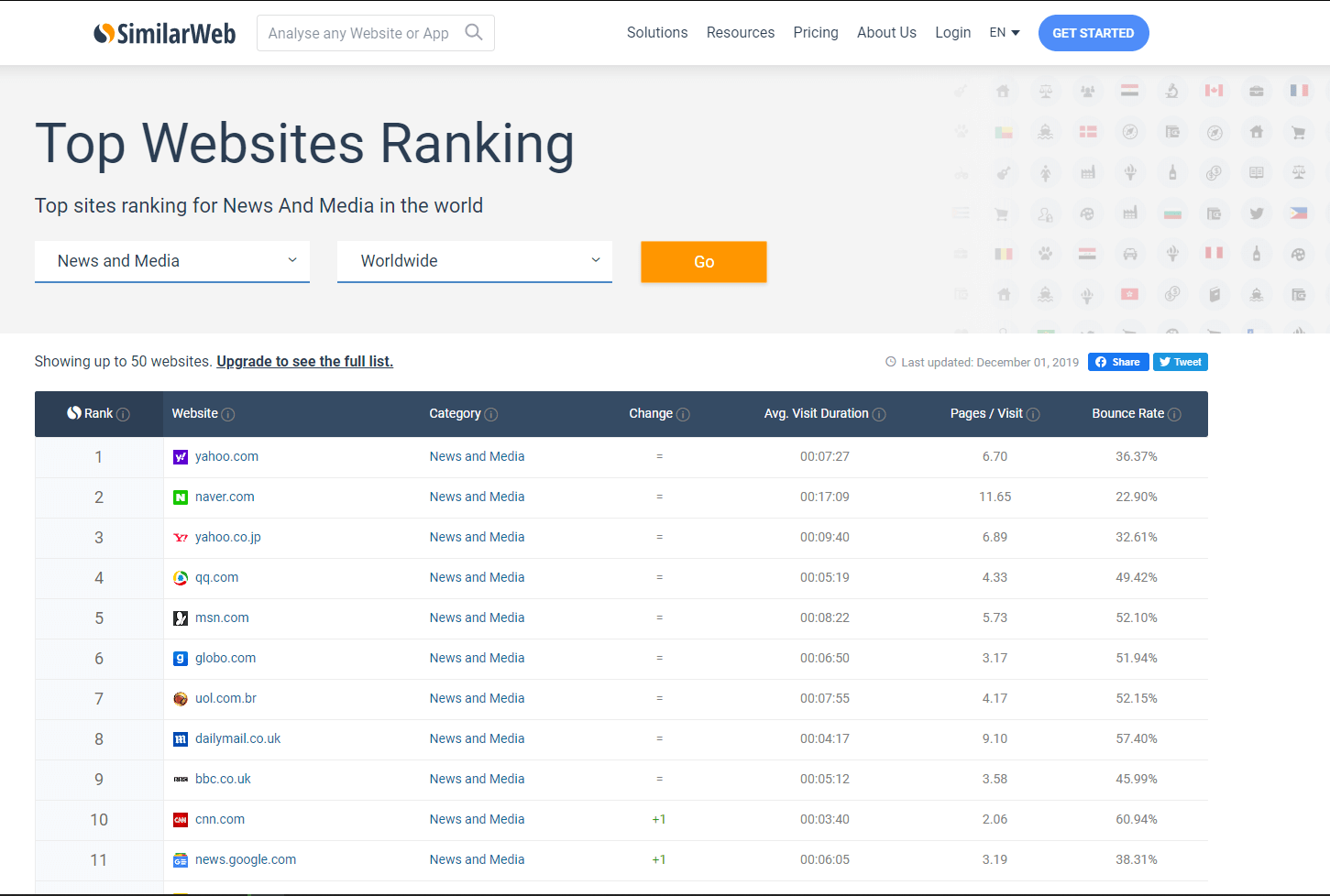
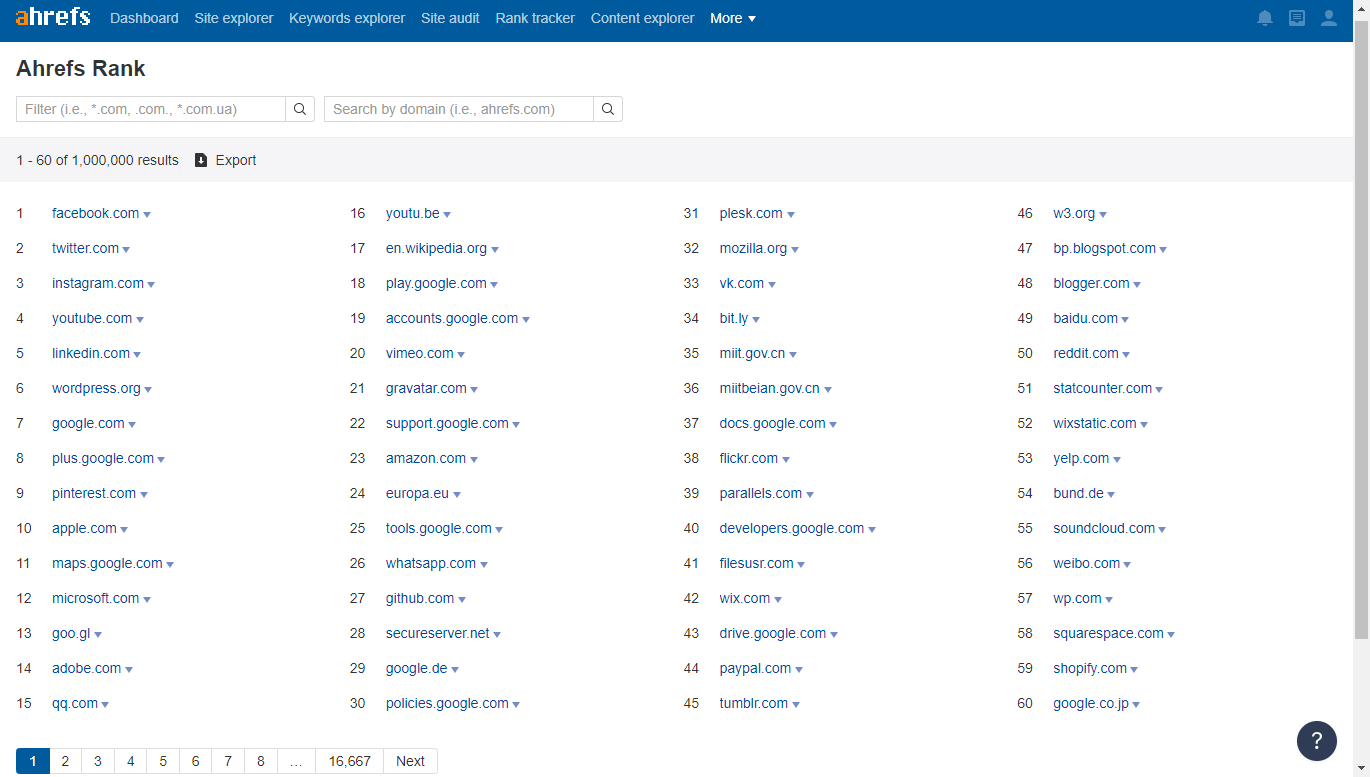
Необходимо вручную пройтись по списку сайтов, чтобы отобрать те, на которых может быть много внешних ссылок. К таким относятся: wikipedia, wikihow, bbc.co.uk, foxnews.com и другие подобные.
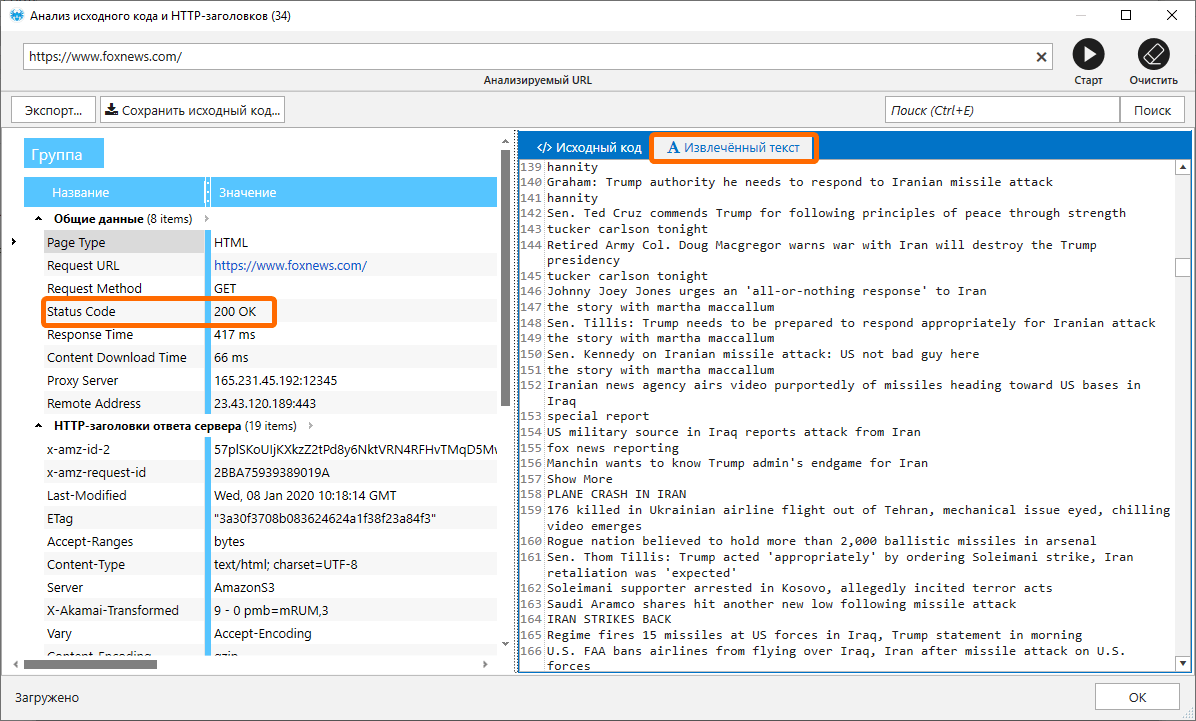
Дополнительно с помощью Netpeak Spider нужно проверить содержание ответа сервера на такие показатели:
- код ответа = 200 ОК,
- наличие полезного контента в исходном коде, а не только заглушка от роботов.
Я использую для этого инструмент «Анализ исходного кода и HTTP-заголовков», в котором проверяю код ответа и смотрю данные на вкладке «Извлечённый текст» → помогает быстро понять, корректный ли исходный код получил краулер.
1.2. Оптимальные настройки сканирования и параметры для поиска нужных ссылок
После добавления списка доменов в таблицу нужно правильно настроить работу краулера. Мы будем использовать два элемента управления: настройки сканирования и анализируемые параметры. Сначала покажу, как выставить настройки сканирования.
Первые важные настройки находятся на вкладке «Основные». Отмечаем «галочками» пункты:
- Включить мультидоменное сканирование. Мы используем эту фичу, чтобы краулер ходил вглубь сразу нескольких сайтов. Она входит в тариф Pro, который доступен новым пользователям во время тестового периода и клиентам с приобретенной лицензией на этот тариф 💓 Если у вас Standart, нужно сканировать каждый сайт отдельно, указав его в поле начального URL, и потом соединять все отчёты вручную. Сложнее, дольше, но выполнимо 👌
- Сканировать все поддомены. Когда мы закончим сканирование и экспортируем отчёт по внешним ссылкам, все поддомены сканируемых сайтов будут считаться внутренними, поэтому они не будут занимать лишнее место.
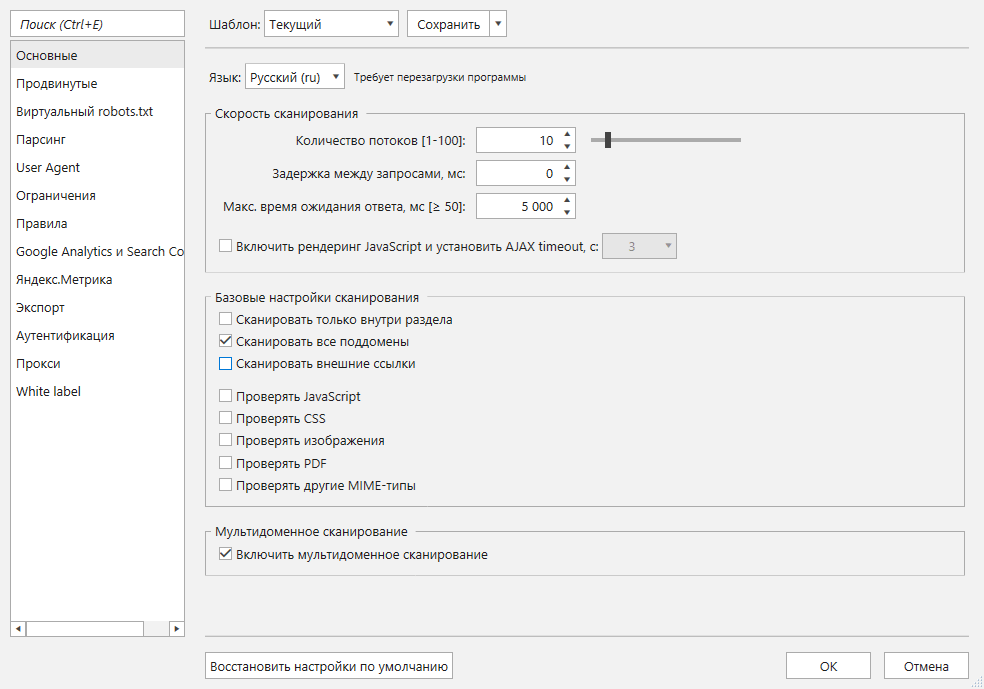
- В таблицу не обязательно добавлять закрытые от сканирования и / или индексации страницы. Чтобы не получать в отчётах ссылки с таких страниц, на вкладке настроек «Продвинутые» отметьте пункты, как показано на скриншоте ниже.
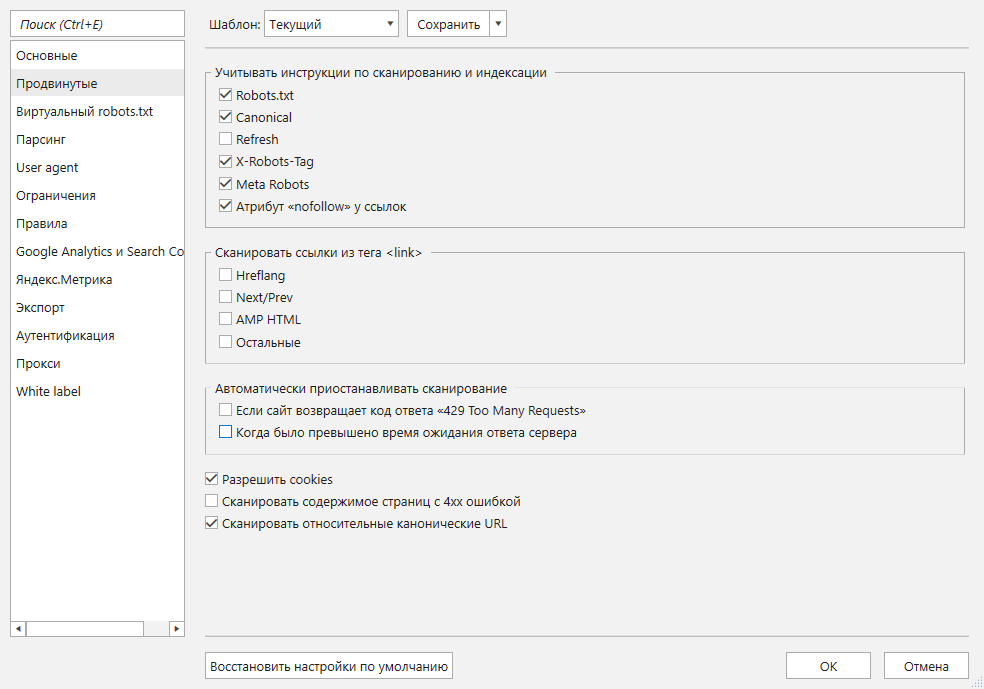
- На некоторых сайтах стоит защита от роботов, поэтому лучше использовать прокси и не больше 10 потоков краулинга → это снизит шанс блокировки.
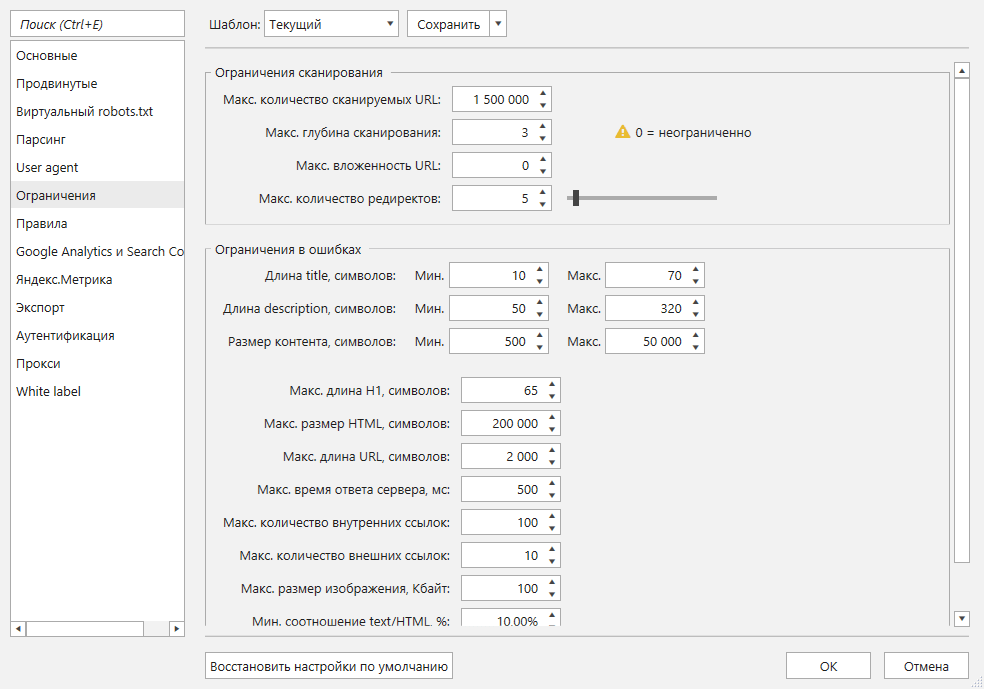
- Советую на вкладке «Ограничения» установить лимит на количество сканируемых страниц. Если у вас компьютер с 16 ГБ свободной оперативной памяти, выставьте значение в один миллион страниц. Когда программа просканирует их, сохраните проект, увеличьте лимит до 1,5 миллиона страниц и нажмите на кнопку «Старт». Это поможет вам не потерять данные, если вдруг случится сбой электричества или другие неполадки.
- Дополнительно можно указать максимальную глубину сканирования каждого сайта. Я выставил значение «3», чтобы Netpeak Spider не уходил глубоко внутрь каждого сайта.
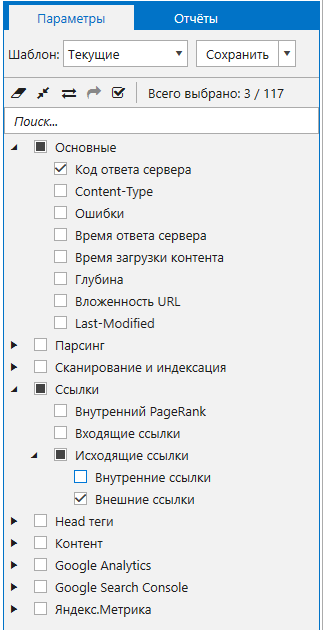
Рассмотрим выбор анализируемых параметров. Эта задача требует много оперативной памяти, поэтому нужно собирать самые необходимые данные. Я выбрал три параметра:
- «Код ответа сервера». Он поможет сэкономить время на выгрузке очень большого отчёта «Все внутренние и внешние ссылки (XL)», так как я применю сегмент только по страницам, которые ответили 200 кодом ответа.
- «Внешние ссылки». Этот параметр будет собирать все нужные ссылки на внешние ресурсы, срок истечения которых я буду проверять.
- «Исходящие ссылки». Параметр выбирается автоматически, когда вы включаете сбор внешних ссылок.
Вот так будет выглядеть набор нужных параметров.
1.3. Поиск доменов для проверки
После настройки программы нажимаем на кнопку «Старт». Так как сканирование миллиона и больше страниц занимает немало времени, можно смело пойти почитать другие статьи в нашем блоге и посмотреть видео про обновления наших программ.
Если вы видите, что осталось мало свободной оперативной памяти, советую во время сканирования не открывать в браузере много вкладок и закрыть ресурсоёмкие процессы. Иначе это может привести к синему экрану, зависанию компьютера, открытию новой чёрной дыры.
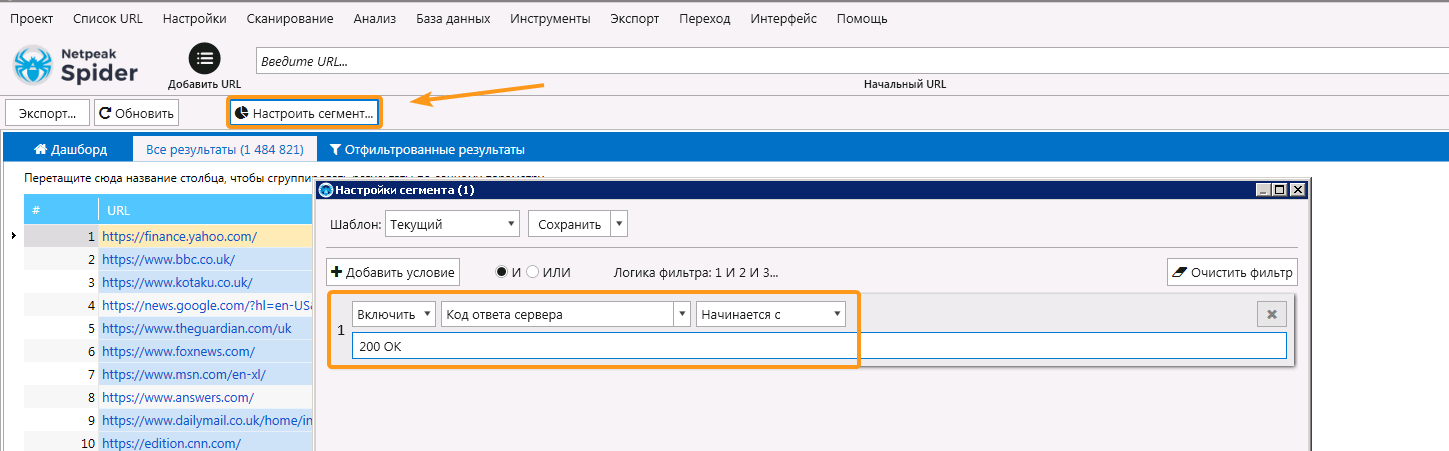
После завершения сканирования я создал сегмент по страницам, которые ответили «200 ОК» кодом ответа, чтобы немного сократить объём выгружаемых ссылок. Так я отсёк 100 тысяч страниц. Для применения сегмента нажмите на кнопку «Настроить сегмент» и укажите условие, как показано на скриншоте ниже.
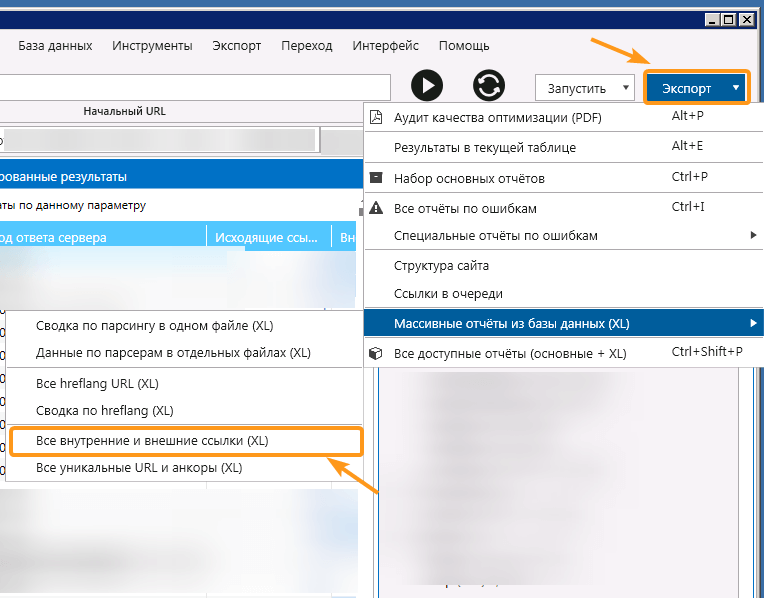
На выгрузку отчётов ушло пять часов, я получил 200 файлов — по миллиону строк каждый. Я сразу удалил все файлы, в которых были данные по внутренним ссылкам и оставил только внешние, их осталось 46. Дальше извлёк все хосты для последующей проверки.
Каждый файл выгрузки содержит данные по источнику ссылки, её анкором и др. Вот так выглядит типичная выгрузка.
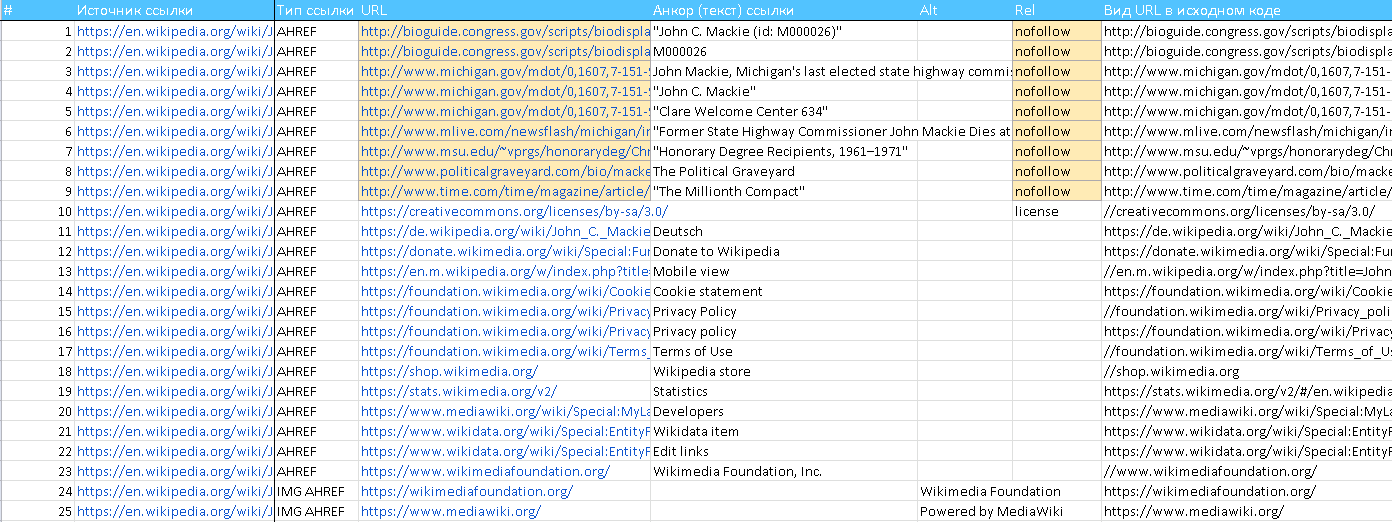
Для проверки необходимо получить уникальные хосты из столбца «URL». Есть два варианта, как их можно извлечь:
- Использовать скрипт, который пройдёт по всем файлам, соберёт уникальные страницы, а потом отсечёт из полного адреса страницы только домены. Это быстрый, но сложный метод. А если вы не знаете, какой скрипт нужен, придётся нанимать человека и платить ему.
- Вручную пройтись по всем документам. Именно этот метод я хочу показать, так как для него не нужны дополнительные затраты денег, но времени он займёт немало, запаситесь терпением.
1.4. Извлечение хостов для проверки
Единого и универсального способа извлечения хостов вручную я не нашёл. Поделюсь тем, который использовал я:
- Открыл 6 окон Netpeak Checker. Да, так можно было, Ctrl+Shift+N 😉
- В каждом окне открывал один из 46 документов и все ссылки фильтровал по длинной регулярке, в которой перечислил через разделительную черту «|» самые популярные домены и список изначально сканированных ресурсов. Конечное условие фильтрации показано на скриншоте.
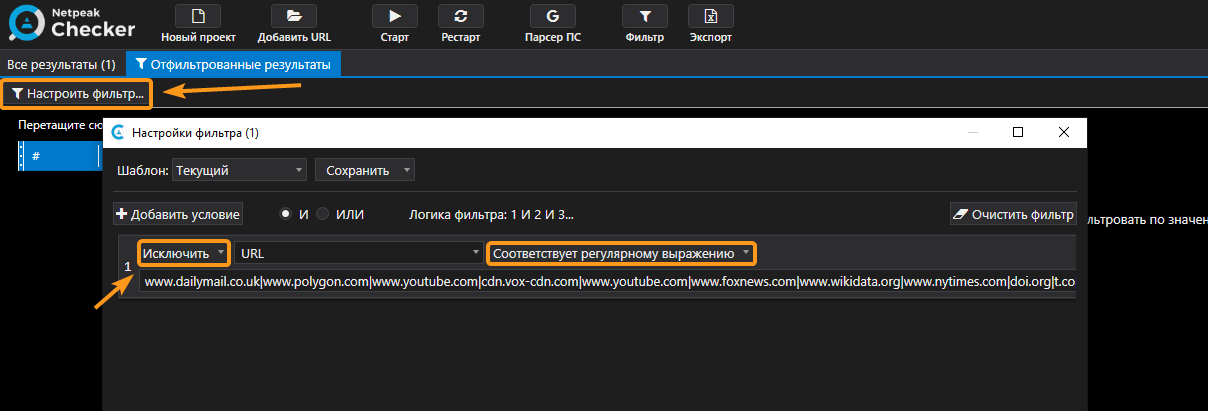
Вот так выглядело регулярное выражение.
www.dailymail.co.uk|www.polygon.com|www.youtube.com|cdn.vox-cdn.com|www.youtube.com|www.foxnews.com|www.wikidata.org|www.nytimes.com|doi.org|t.co|www.bbc.co.uk|tvbythenumbers.zap2it.com|www.msn.com|www.guardian.co.uk|www.awin1.com|www.worldcat.org|www.asos.com|news.bbc.co.uk|archive.org|www.washingtonpost.com|pubmed.ncbi.nlm.nih.gov|deadline.com|www.imdb.com|www.telegraph.co.uk|fave.co|www.hollywoodreporter.com|www.instagram.com|www.jstor.org|amzn.to|variety.com|www.independent.co.uk|www.amazon.co.uk|www.net-a-porter.com|www.farfetch.com|marvel.com|wikipedia|facebook.com|twitter.com|wikimedia|google.com|pinterest.com|amazon.com|linkedin.com|guardian.co|yahoo.com|youtube.com|bbc.co.uk|imdb.com|www.cnn.com|www.kotaku.co.uk|en.wikiquote.org|www.ncbi.nlm.nih.gov|www.microsoft.com|kotaku.com|www.comicbookresources.com|www.guardianbookshop.co.uk|www.cbsnews.com|www.thesun.co.uk|id.loc.gov|www.usatoday.com|www.huffingtonpost.com|viaf.org|tools.wmflabs.org|comicbookdb.com|www.ign.com|www.thefutoncritic.com|www.reuters.com|www.comics.org|www.marvel.com|a.msn.com|people.com|d-nb.info|tvline.com|www.npr.org|isni.org|www.latimes.com|www.bbc.com|es.wikihow.com|articles.latimes.com|www.newsarama.com|www.digitalspy.co.uk|interactive.guim.co.uk|www.tmz.com|www.wsj.com|abcnews.go.com|www.politico.com|www.marvunapp.com|www.nydailynews.com|en.wiktionary.org|www.tvshowsondvd.com|www.forbes.com|de.wikihow.com|www.nbcnews.com|www.cbr.com|www.abc.net.au|edition.cnn.com|pt.wikihow.com|abcmedianet.com|www.smh.com.au|ew.com|www.tvguide.com|www.reddit.com|ui.adsabs.harvard.edu|nypost.com|www.time.com|radio.foxnews.com|fr.wikihow.com|www.bloomberg.com|www.cbc.ca|www.matchesfashion.com|mediawiki.orВ итоге миллион страниц после фильтрации превратился в 200-250 тысяч.
Когда вы примените фильтрацию, программа, скорее всего, уйдёт в состояние «Не отвечает». Не переживайте, просто оставьте её на 3-4 минуты. Netpeak Checker выполнит все нужные операции в фоновом режиме и вернётся в рабочее состояние.
- После фильтрации я экспортировал эти 200-250 тысяч страниц из программы в CSV-файл.
Лайфхак. Чтобы уменьшить размер файла и упростить его загрузку в Google Таблицы, в текущей таблице скройте все столбцы, кроме «URL». Программа выгрузит только те данные, которые отображены в таблице.
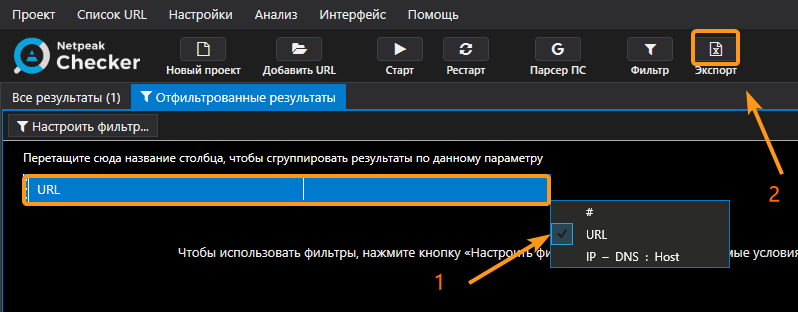
- После монотонного выполнения первых трёх шагов у меня было 46 документов с 200-250 тысячами страниц в каждом. Извлечь из этих страниц только домены — непростая задача, если делать это без скрипта, а вручную. Я использовал возможности Google Таблиц. Загрузил все 46 файлов на Google Диск и работал с 5-6 таблицами одновременно.
- В каждой таблице из полного адреса страницы я извлекал только хост с помощью формулы:
=REGEXEXTRACT(A2,"^(?:.*:\/\/)?([^:\/]*).*$")
- Собрал только уникальные хосты, используя формулу UNIQUE.
- Все полученные хосты добавил в Netpeak Checker. Программа отсекает дубли при добавлении, что очень удобно. В моём случае я получил 1,1 миллион уникальных хостов, которые нужно проверить на доступность.
Понимаю, что это очень долго, монотонно и «обезьяний труд». Если хотите избавить себя от него, советую приобрести базовые навыки программирования, чтобы быстрее решать такого рода задачи.
2. Проверка доменов на доступность к покупке
Вручную сделать миллион проверок у регистратора доменных имён заняло бы пару лет. Я же максимально уменьшил количество проверок и автоматизировал их. Делается это в несколько этапов.
2.1. Проверка IP-адреса хоста
Один из признаков свободного домена — это отсутствие IP-адреса. Этот параметр очень быстро проверяется в Netpeak Checker, именно его я использую в качестве первого фильтра:
- Включаю только параметр «IP» в группе «DNS».
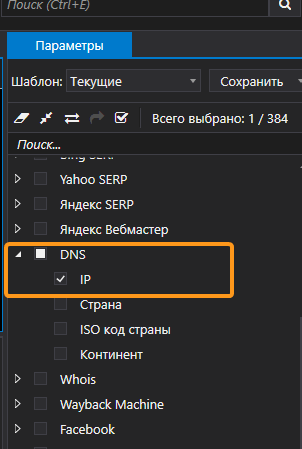
- На вкладке настроек «Общие» выставляю 15 потоков.
- Запускаю анализ.
Примерная скорость анализа 100 тысяч страниц в час, поэтому можно смело переключаться на выполнение других задач, пока программа на фоне выполняет проверку.
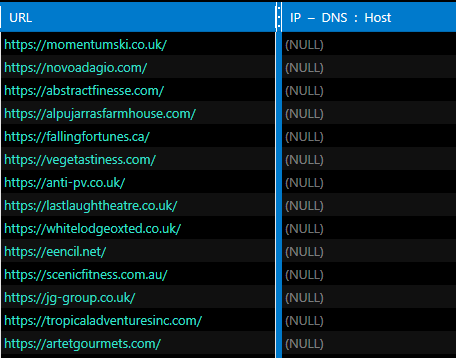
В итоге я получил 85 тысяч хостов, у которых не было IP-адреса:
2.2. Очистка списка от нежелательных хостов
Чтобы сузить круг моего поиска, я отсёк:
- доменные зоны .edu, .gov, .mil, .ua, .jp, .cn, .xxx,
- поддомены. Оставил только основные домены.
Первый пункт выполняется путём использования регулярного выражения в Google Таблицах:
Второй пункт сложнее реализовать ввиду наличия нескольких тысяч доменных зон (TLD). С целью сделать всё максимально точно, нужно потратить много времени. Решением послужит план «минимум» — убираем все результаты, где есть больше двух точек.
В итоге из 85 тысяч осталась 71 тысяча хостов, которые проверяем на доступность к покупке.
2.3. Проверка доступности доменов по данным Whois
Благодаря интеграции Netpeak Checker с сервисом Whois мы можем ещё больше сузить круг поиска. Для этого добавляем 71 тысячу хостов в программу, включаем параметры «Доступность» и «Дата истечения» в чекбоксе «Whois», запускаем анализ и можем снова идти выполнять другие задачи, потому что эта проверка займёт много времени.
Два нюанса в работе с этим сервисом:
- Для разных доменных зон заданы разные лимиты проверки. Например, .pl, .au, .nl ограничивают получение данных уже после первой сотни проверок.
- Данные для некоторых доменных зон могут быть неправдивыми. Чаще всего это наблюдается в доменной зоне .ru.
Чтобы обойти первый нюанс, можно воспользоваться облачными сервисами проверки данных Whois, которые обращаются к сервису из разных мест, обходя блокировку. Оптимально пробить сначала через Netpeak Checker, а потом результаты с ошибками сервиса или достигшие лимита перепроверить в облачных сервисах (например, collaborator.pro).
Проверка 70 тысяч хостов заняла у меня 6 часов. По итогу я получил 12 250 хостов в таблице, у которых значение параметра «Доступность» было TRUE. И хотя всё ещё есть мусорные результаты с поддоменами, их значительно меньше.
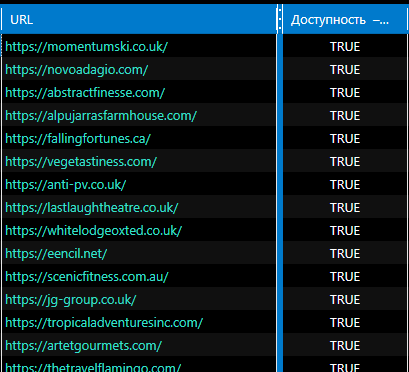
Дополнительно можно сохранить список доменов, у которых скоро истечёт срок регистрации, чтобы перепроверить через 2-3 месяца..
3. Дроп-домены бесплатно
В Netpeak Checker я собрал несколько пузомерок из Ahrefs для полученных дропов, чтобы отделить мух от котлет. И с радостью делюсь результатами с вами. Если нашли себе какой-то дроп или узнали в посте что-то новое, жду лайков и комментов 😊
4. То, что обычно пишут мелким шрифтом
Описанный мною процесс долгий. В нём легко запутаться, и есть недостатки. Но я выбрал именно его, потому что хотел показать все мелкие детали работы с нашими программами, фишки использования Google Таблиц и бесплатные варианты сделать эту проверку.
Если вы себя оцениваете как продвинутого специалиста, для вас алгоритм поиска я бы описал так:
- Использовать функцию мультидоменного сканирования в Netpeak Spider и собрать несколько миллионов страниц с разных ресурсов.
- Выгрузить все внешние ссылки в CSV-файл.
- Использовать скрипт, который из этого гигантского документа достанет только уникальные хосты и отсечёт ненужные TLD и поддомены.
- Загрузить уникальные хосты в Netpeak Checker для пробивки IP-адреса. Можете и свой скрипт написать для этой проверки, но наша программа с этим хорошо справляется 😎
- Все хосты без IP-адреса проверить на доступность с помощью Whois.

Всем трафика и хорошего дня 😊
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider и Checker



