Что такое поисковый робот, и как он работает
Мануалы

Чтобы знать и понимать принципы сканирования и индексации, стоит ознакомиться с особенностями работы поисковых роботов. Они принимают непосредственное участие в этих процессах, собирают и обновляют всю информацию о страницах сайта. Подробнее о том, что такое поисковый робот, и как он работает, поговорим в этом посте.
1. Что такое поисковый робот
Поисковый робот — это программа для сканирования и индексации сайтов. Он позволяет поисковой системе получить сведения о веб-страницах и внести их в базу для последующей выдачи пользователям при запросе. Боты не анализируют собранные данные, а только передают их на сервера поисковых систем. Для эффективной индексации сайта необходимо учитывать особенности обработки веб-страниц ботами.
Поисковых роботов называют по-разному: краулеры, боты, веб-пауки. Во всех этих случаях речь идёт об одинаковых программах. Они заходят на сайт, заносят содержимое в индекс и находят ссылки, по которым переходят на другие страницы. Для ускорения индексации создаются файлы robots.txt и XML Sitemap.
Чтобы узнать, есть ли URL в индексе Google, выполните проверку в сервисе Google Search Console.
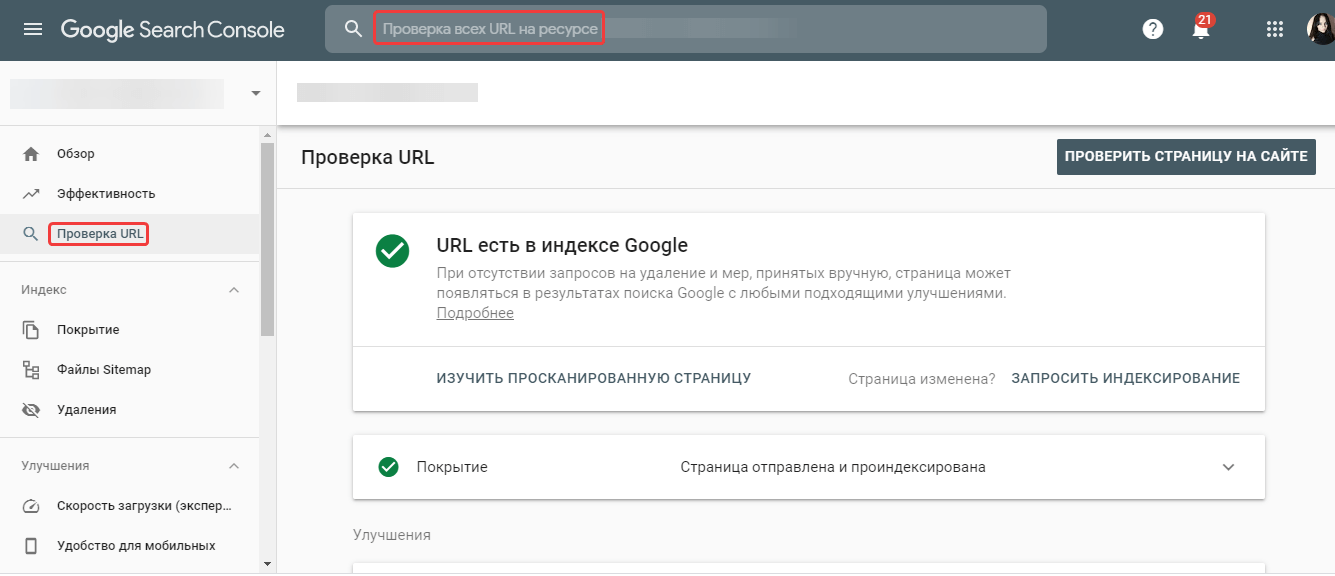
Читайте также: «Как массово узнать количество страниц в индексе поисковых систем с помощью Netpeak Checker».
2. Принцип работы поисковых роботов и их функции
Поисковая выдача формируется в три этапа:
- Сканирование — сбор всех данных с веб-страниц ботами, включая тексты, картинки и видеоматериалы. Данный процесс происходит регулярно с учётом частоты обновлений ресурса.
- Индексация — внесение собранной информации в базу данных поисковых систем с присвоением определённого индекса для быстрого поиска. На крупных новостных порталах контент индексируется практически сразу после публикации.
- Выдача результатов — поиск информации по индексу и ранжирование страниц с учётом релевантности запросу.
Иногда процесс индексации страниц происходит даже без их предварительного сканирования. В файле robots.txt указываются правила для сканирования, но не индексирования страниц. Поэтому если поисковый робот обнаружит страницу другим способом, например, если на неё ссылаются сторонние ресурсы, то может добавить её в базу.
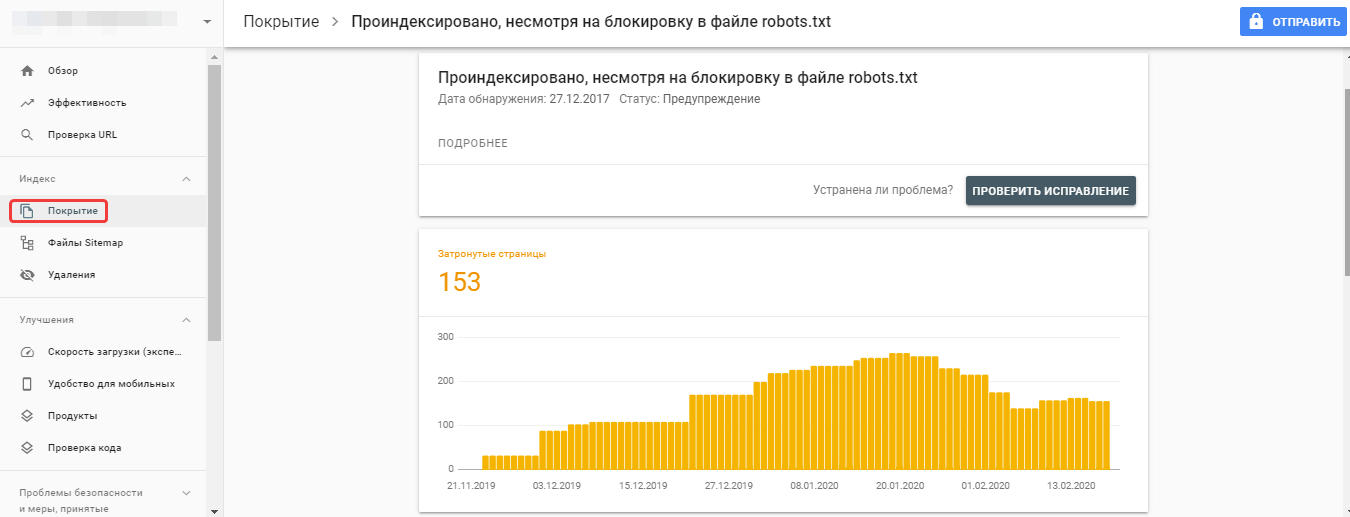
В данном случае необходимо убрать запрет на сканирование этих служебных страниц из файла robots.txt, используя только запрет индексации на страницах:
2.1. Рекомендации роботам по доступу к контенту сайта
Рекомендации по индексации материалов на сайте можно задавать с помощью файлов sitemap.xml и robots.txt:
- В sitemap.xml можно указать частоту обновления и приоритет каждой страницы, используя теги <changefreq> и <priority>. Частоту обновления задают в зависимости от типа ресурса и страницы — от
новостных ресурсов до статичных страниц, например, раздела с контактами компании. Приоритет страницы устанавливается в зависимости от её важности для продвижения — от 0,0 до 1,0. - В robots.txt указываются правила сканирования страниц. Для SEO-продвижения важно, чтобы в индекс не попадали служебные страницы, дубли и другой малополезный контент. Однако вопреки указанным директивам, краулеры могут всё равно проиндексировать закрытые страницы. Если на сайте необходимо гарантированно запретить индексацию каких-либо материалов, лучше использовать метатег robots или делать их доступными для пользователей после аутентификации.
В robots.txt для запрета индексации используется директива Disallow. Например, чтобы полностью запретить доступ всех ботов к сайту, прописываются такие строчки кода:
User-agent: * Disallow:При добавлении директив их порядок не принципиален, после данной команды можно открыть какой-либо раздел сайта для индексации при помощи директивы Allow.
3. Особенности работы с поисковыми ботами
Чтобы индексация сайта поисковыми роботами происходила быстро и эффективно, необходимо:
- Снизить активность роботов, если их посещения вызывают слишком большую нагрузку на сервер. Это делается путём частичного запрета индексации разных разделов сайта в robots.txt. Подобные ситуации могут возникнуть при массовом добавлении контента на сайт, например, обновлении ассортимента интернет-магазина.
- Избегать хакерских атак, завуалированных под посещения ботов. Иногда программы хакеров имитируют поисковых роботов.
- Ознакомиться со списком популярных ботов поисковых систем, доступ которых на сайт не стоит ограничивать.
Кроме ошибок в robots.txt, медленной скорости загрузки сайта и блокировки в .htaccess, причинами плохой индексации могут быть:
3.1. Высокая нагрузка на сервер при посещениях роботов
Индексация ботами поисковых систем крайне важна для продвижения, однако в некоторых ситуациях она может перегружать сервер, либо под видом роботов сайт могут атаковать хакеры. Чтобы знать цели, с которыми боты обращаются к ресурсу, и отслеживать возможные проблемы, проверяйте логи сервера и динамику серверной нагрузки в панели хостинг-провайдера. Критические значения могут свидетельствовать о проблемах, связанных с активным доступом к сайту поисковых роботов.
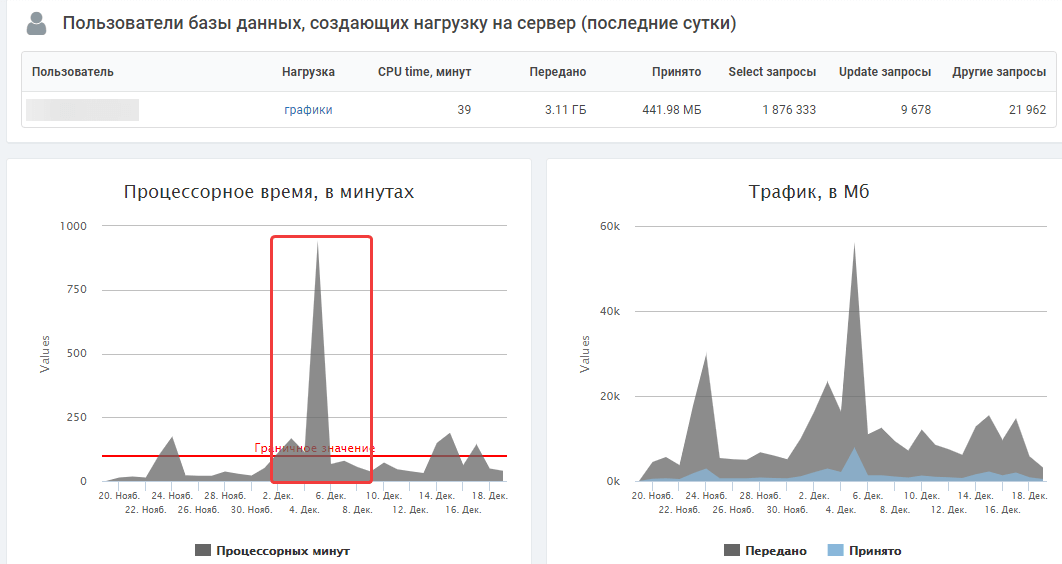
Когда роботы перегружают сервер слишком активными запросами к сайту, можно снизить их скорость обхода. Как это сделать, узнайте из справки Google.
3.2. Проблемы из-за доступа фейковых ботов к сайту
Бывает, что под видом ботов Google к сайту пытаются получить доступ спамеры или хакеры. Если возникла такая проблема, проверьте, действительно ли сайт сканирует поисковый робот Google:
- В логах сервера хостинг-провайдера скопируйте IP-адрес, с которого был сделан запрос к сайту.
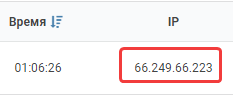
- Проверьте данный IP с помощью сервиса MyIp.
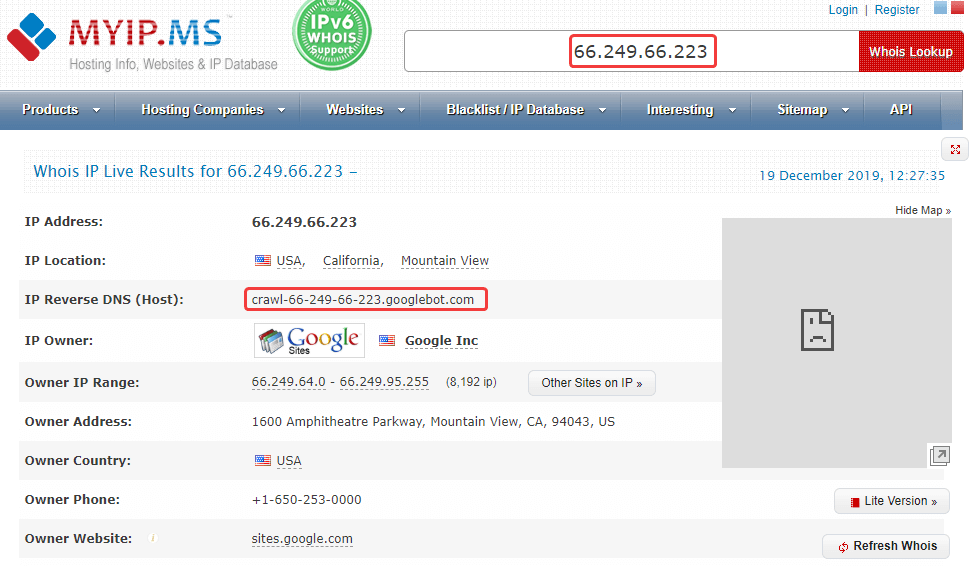
- Затем проверьте адрес, указанный в строке IP Reverse DNS (Host).

Полученный IP-адрес должен совпадать с исходным в логах сервера, иначе это говорит о том, что имя бота поддельное. В данном случае сайт действительно сканировал Googlebot.
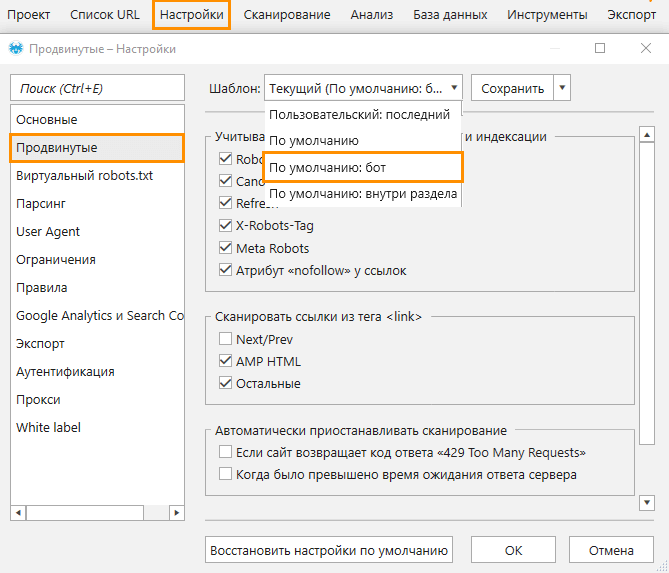
Чтобы узнать, как тот или иной поисковый бот сканирует ваш сайт, воспользуйтесь краулером Netpeak Spider, который позволяет имитировать поведение робота. Для анализа необходимо:
- Открыть настройки «Продвинутые» и выбрать шаблон «По умолчанию: бот» → он предполагает учёт всех инструкций по сканированию и индексации.
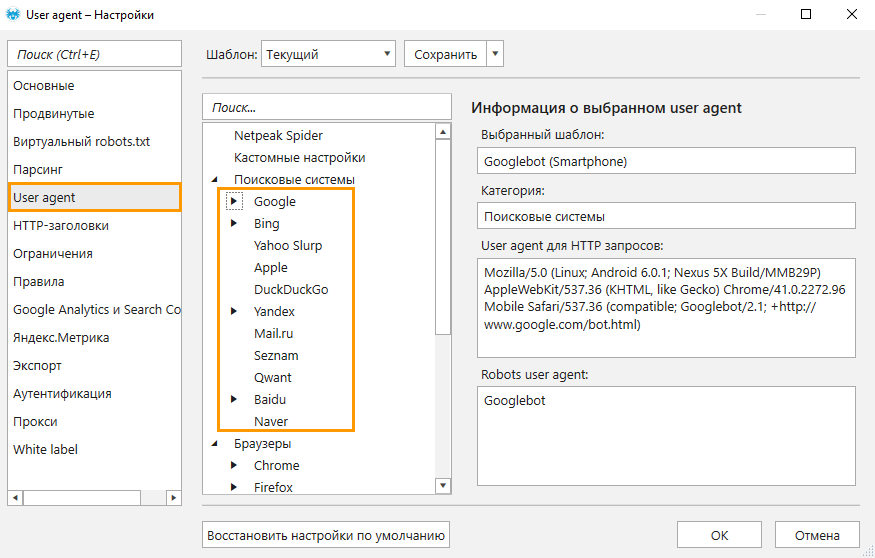
- Перейти на вкладку «User Agent» и из списка ботов выбрать нужного.
- Начать сканирование и по окончании ознакомиться с полученными данными.
Проверять, как сайт отвечает на запросы от разных User agent, вы можете в бесплатной версии Netpeak Spider без ограничений по времени! Во Freemium-версии также доступны и многие другие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифы и выбрать для себя подходящий.
3.3. Список ботов поисковых систем
Поисковые системы используют различные типы роботов: для индексации обычных страниц, новостей, изображений, фавиконов и прочих типов контента. Список IP-адресов, которые используют боты поисковиков, постоянно меняется и не разглашается.
3.2.1. Роботы Google
Полный список роботов Google можно посмотреть в справке. Рассмотрим наиболее популярных ботов:
- Googlebot — к ним относятся краулеры двух типов: для десктопных и мобильных версий стандартных сайтов. С июля 2019 года для новых и адаптированных под мобильные устройства сайтов включено приоритетное сканирование мобильных версий, соответственно большинство запросов будут обрабатывать мобильные боты.
- Googlebot Images — поисковый робот для индексации изображений. При желании можно запретить индексацию всех картинок на сайте с помощью такой директивы в robots.txt:
User-agent: Googlebot-Image Disallow: /
- Googlebot News — бот, добавляющий материалы в Google Новости.
- Googlebot Video — робот, индексирующий видеоконтент.
- Google Favicon — краулер, собирающий фавиконы сайтов.
- APIs-Google — агент пользователя для отправки PUSH-уведомлений. Такие уведомления используются, чтобы веб-разработчики могли быстро получить информацию о каких-либо изменениях на сайтах без излишней нагрузки серверов Google.
- AdsBot Mobile Web Android, AdsBot Mobile Web, AdsBot — краулеры, проверяющие качество рекламы на различных типах устройств.
Подводим итоги
Благодаря поисковым роботам происходит сканирование и индексация ресурсов. Робот сам находит новые веб-страницы, но чтобы ускорить индексацию, можно сообщить о появлении новых URL вручную посредством инструментов поисковых систем (Google Search Console). Для управления индексацией материалов можно задать указания ботам при помощи файлов XML Sitemap и robots.txt.
А как вы «общаетесь» с ботами поисковых систем? Делитесь в комментариях.


