Netpeak Spider 3.2: рендеринг JavaScript та аудит у PDF
Оновлення

Друзі, із цього поста ви дізнаєтеся, що ми приготували для вас в рамках довгоочікуваного релізу Netpeak Spider 3.2 :) Нам просто не терпиться поділитися подробицями.
Тож розпочнемо з деталей. Якщо ви хочете перейти до конкретного розділу, побережіть коліщатка на ваших мишках і скористайтеся змістом:
- 1. Рендеринг JavaScript
- 2. Технічний SEO-аудит (PDF)
- 3. Розширений опис помилок
- 4. Інші зміни
- 5. Коротко про головне
1. Рендеринг JavaScript
Перш ніж розповісти про особливості цієї довгоочікуваної функції у нашому краулері, згадаймо, як Google індексує контент, який додається на сторінку скриптами.
Кортить швидше спробувати рендеринг JavaScript? Приховати подробиці та перейти до особливостей налаштування функції Netpeak Spider.
1.1. Що таке рендеринг JavaScript
Виконання або рендеринг JavaScript — це формування остаточного зліпка HTML-коду сторінки з огляду на зміни, внесені JS-скриптами.
Спочатку пошукові роботи сканували та індексували лише контент, який передавався у статичному вихідному коді HTML. Однак зараз при розробці сайтів все частіше використовують JS-фреймворки, коли контент частково або повністю додається за допомогою JavaScript. Ось наочний приклад HTML-коду до та після виконання JavaScript з нашого сайту:
- відображення ціни Netpeak Spider на одній із наших сторінок — до виконання JavaScript:
- відображення цього ж блоку після виконання JS-скриптів:
Google довелося підлаштуватися під розвиток вебтехнологій, і зараз він вже обробляє та рендерить контент, який додається на сторінку за допомогою JavaScript. Їх сервіс вебрендерингу (WRS) базується на браузері Chrome.
Пошуковий робот Google сканує сайти у дві стадії:
- Під час першої він (як і раніше) працює тільки з HTML: запитує вихідний код, сканує та індексує контент, а також додає знайдені посилання в чергу сканування.
- На другій стадії виконується рендеринг (відображення) контенту. На цьому етапі йому потрібні ресурси для виконання JavaScript. Тому якщо ресурсів сканування недостатньо, між першою та другою стадією можливий часовий інтервал.
Розділення індексації та рендерингу дозволяє Google максимально швидко проіндексувати контент, доступний без JavaScript, а потім повернутися і додати контент, для якого він потрібен.
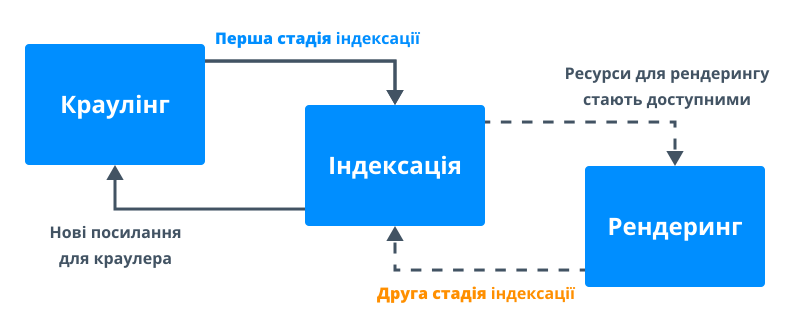
Якщо на першому етапі Google не отримав важливий контент сторінки, додавання цього контенту до індексу відбуватиметься на другому етапі, де можливі затримки.
Є два способи передачі контенту, які використовують сучасні вебдодатки:
- Рендеринг на стороні клієнта (client-side rendering, CSR) — пошукова система отримує порожню HTML-сторінку (практично без контенту), а основний контент додається на сторінку за допомогою скриптів JavaScript. У такому разі необхідно чекати другої стадії сканування, і контент може потрапити до індексу із затримкою.
- Рендеринг на стороні сервера (server-side rendering, SSR) — пошукова система отримує зліпок HTML вже з усім важливим контентом сторінки. Тому він додається до індексу на першій стадії сканування, і можна не переживати через можливі затримки другої стадії.
Просунутий SEO-фахівець повинен розумітися на цих аспектах. По суті JavaScript SEO — це забезпечення того, що контент, який додається на сторінку за допомогою JavaScript, успішно обробляється пошуковим роботом, потрапляє до індексу та враховується в ранжируванні.
Далі ми пояснимо, навіщо обробка JavaScript потрібна в сучасних SEO-інструментах і як її використовувати.
1.2. Для чого рендеринг JavaScript потрібен у краулері
Якщо ви спробуєте просканувати сайт, на якому використовується CSR, традиційним способом (аналізуючи тільки HTML), краулер не зможе виявити дані, які додаються за допомогою JavaScript (посилання, описи, зображення тощо), а відтак і знайти помилки на такому сайті.
Тому, щоб обробити подібні сайти як Googlebot, краулеру потрібен браузер для виконання JavaScript → щоб завантажити весь контент з урахуванням змін, внесених скриптами, і тільки потім аналізувати його.
1.3. Як налаштувати рендеринг JavaScript у Netpeak Spider
У Netpeak Spider рендеринг JavaScript реалізований за допомогою вбудованого браузера Chromium, на основі якого створено найпопулярніший у світі браузер Chrome. Ми використовуємо одну з останніх версій Chromium, що робить сканування в Netpeak Spider максимально просунутим і наближеним до поведінки Googlebot, але не ідентичним, оскільки Google використовує стару версію браузера Chrome 41, яка не підтримує деякі сучасні JavaScript.
Щоб почати сканування сторінок із виконанням скриптів JS, зайдіть в налаштування → вкладка «Основні» → позначте галочкою пункт «Увімкнути рендеринг JavaScript та встановити AJAX timeout, c»:
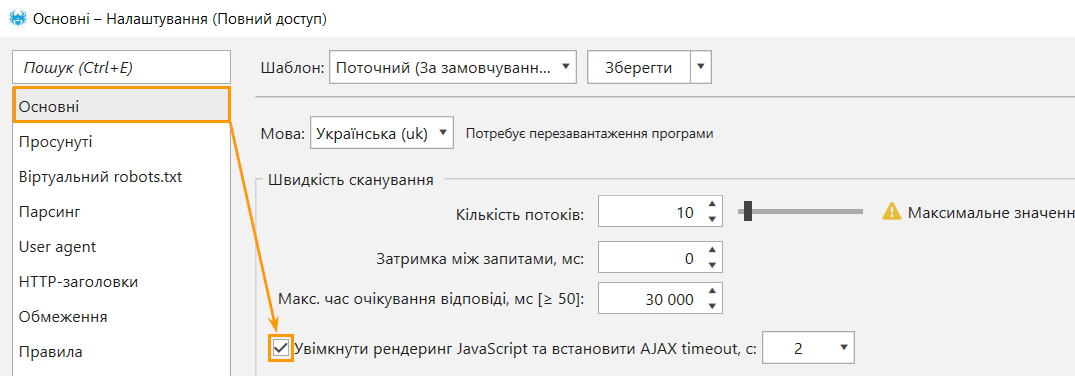
Налаштування "AJAX timeout" встановлює час очікування виконання JavaScript після завантаження сторінки та файлів ресурсів (JS/CSS). Це потрібно, щоб усі скрипти встигли відпрацювати.
Зверніть увагу: чим більше AJAX timeout, то довше відбуватиметься сканування. У більшості випадків значення за умовчанням (2 секунди) буде достатньо для виконання JavaScript, проте ви можете налаштувати його самостійно, якщо на сайті, що аналізується, є AJAX-запити, які виконуються довше. Також не радимо занижувати це значення, оскільки код може не встигнути повністю обробитись.
Розгляньмо приклад сканування сайту, де контент повністю виводиться за допомогою JavaScript. У цьому випадку ви не зможете просканувати такий сайт без увімкненого рендерингу JS.
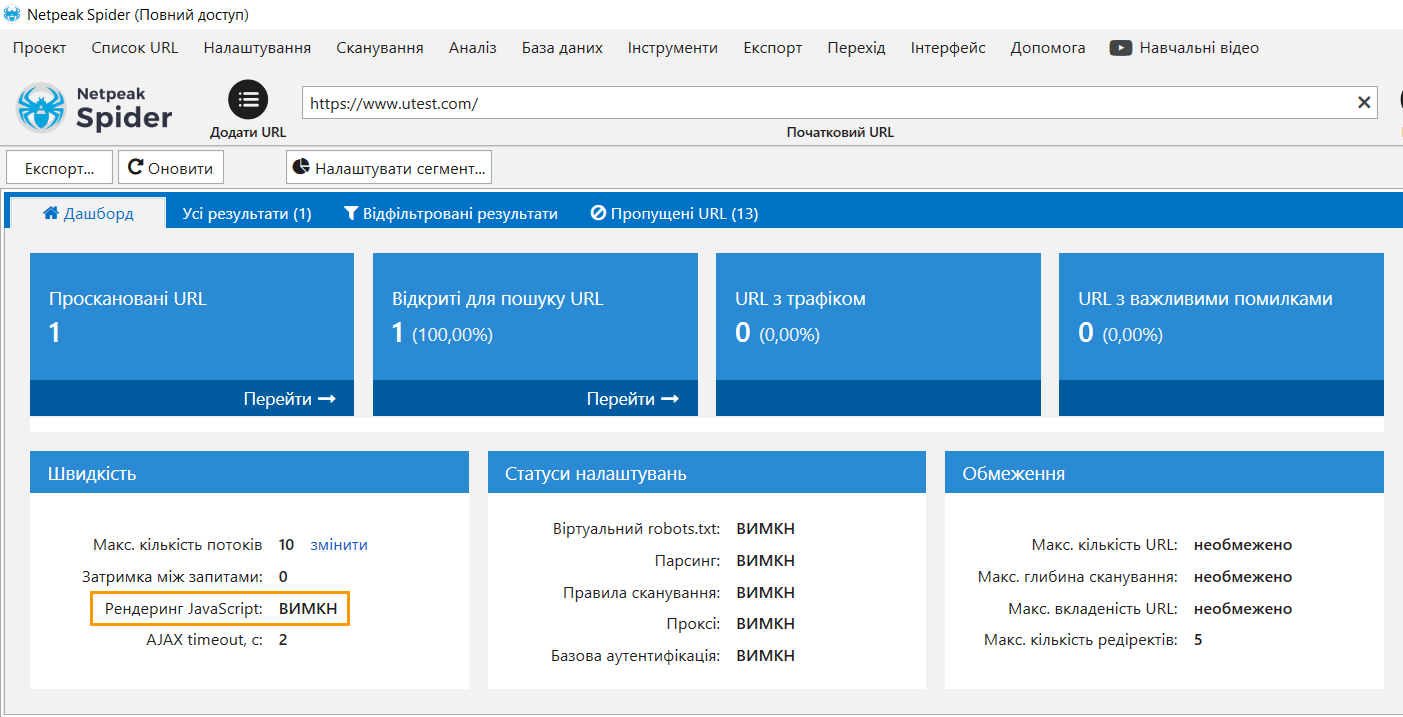
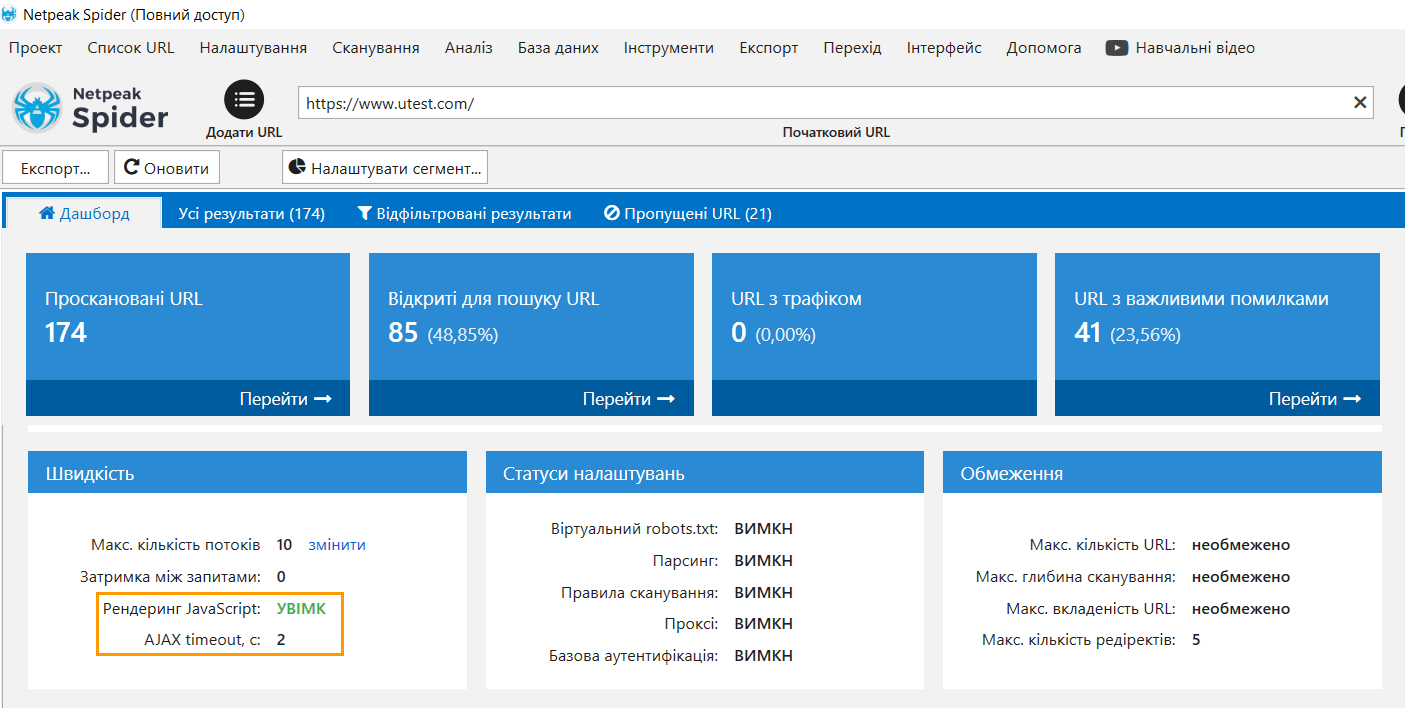
1.4. Особливості JS-рендерингу в Netpeak Spider
Netpeak Spider використовує рендеринг із виконанням JS-скриптів тільки для HTML-сторінок з кодом відповіді 200 OK. Це прискорює роботу програми та дозволяє не витрачати ресурси на сторінки, для обробки яких не потрібно використовувати браузер.
Якщо ви хочете просканувати сайт із включеним рендерингом JavaScript, пам'ятайте, що це збільшує час сканування. Коли краулер працює без рендерингу, відбувається лише один запит для отримання HTML-коду сторінки. Коли ви включаєте рендеринг, додатково відбувається запит у Chromium для отримання HTML-коду, завантаження JS та CSS-файлів та саме виконання JavaScript за час, вказаний у налаштуванні AJAX timeout. Відповідно, сканування займе більше часу.
Порада: ми рекомендуємо включати JavaScript, тільки якщо вам необхідно просканувати сайт з CSR, і не радимо включати його для сканування всіх сайтів за умовчанням (особливо при скануванні сайтів з тисячами й більше сторінок, що може викликати велике навантаження на комп'ютер).
Також під час рендерингу JavaScript Netpeak Spider:
- використовує User Agent, вибраний користувачем у налаштуваннях сканування;
- підтримує базову автентифікацію;
- підтримує список проксі;
- блокує запити до аналітичних сервісів (Google Analytics, Яндекс.Метрика тощо), щоб не спотворювати аналітику сайту;
- враховує cookies незалежно від налаштувань, виставлених на вкладці "Просунуті";
- не завантажує iframe та зображення;
- обмежений 25 потоками. Таким чином, якщо ви виставите в налаштуваннях сканування 100 потоків, Netpeak Spider одночасно скануватиме 100 документів звичайним способом, проте рендерити буде лише 25 доступних HTML-сторінок.
А тепер перейдемо до другої нової функції нашого краулера. Підозрюємо, що візуалам вона особливо сподобається ;)
2. Технічний SEO-аудит (PDF)
У новій версії Netpeak Spider ми додали можливість в один клік експортувати звіт у форматі PDF із SEO-аудитом на підставі результатів проведеного сканування.
Завдяки цій функції ви зможете отримати в Netpeak Spider найкраще з «двох світів»: глибину аналізу і кастомізацію десктопного інструменту та візуалізацію результатів на рівні найсучасніших онлайн-продуктів.
Звіт доступний у меню «Експорт»:
PDF — універсальний формат, який підходить для друку і легко відкривається майже на будь-якому пристрої.
Ми поставили собі за мету досягти максимально якісної візуалізації даних, додавши в логіку програми абсолютно нові показники, а також врахували такі нюанси:
- У звіті буде показано лише ті дані, які були знайдені на сайті під час сканування. Розділи та діаграми, для яких немає даних, не виводяться — а значить, ви не побачите порожні аркуші та таблиці, просто, тому що під час сканування не було знайдено ту чи іншу помилку/параметр.
- У звіті відображаються показові приклади для аналізу даних, а не повний перелік відповідних URL-адрес. А значить при аналізі середніх і великих сайтів не доведеться перегортати десятки сторінок звіту з сотнями посилань, що важко читати.
2.1. Кому це буде корисно?
PDF-звіти знадобляться насамперед SEO-фахівцям. Це покращена та розширена (на 20 сторінок) версія дашборду програми, якою зручно користуватися для оцінки якості оптимізації проекту або списку URL. Тут наочно показана ключова інформація для аудиту сайту — достатньо доповнити її власними рекомендаціями й можна відправляти клієнту або колегам на використання.
Якщо ж ви фахівець із продажу, то у звіті є дані про стан сайту, за допомогою якого ви зможете швидко оцінити проект та обговорити фронт робіт із клієнтом.
2.2. Структура та особливості PDF-звітів
Звіт будується за даними з таблиці «Всі результати», на які безпосередньо впливають налаштування, параметри та сегментація (спробуйте протестувати різні види звітів, змінюючи їх).
Кожен розділ звіту присвячений певному аспекту оптимізації. Пройдімося докладніше по кожному з них.
2.2.1. Головна сторінка + зміст
Якщо під час аналізу в Netpeak Spider використовувався режим сканування сайту, то на першій сторінці буде показаний скріншот початкової сторінки та домен ресурсу, що сканується, щоб було зручно візуально розрізнити звіти для різних сайтів.

Якщо проскановано просто список URL без початкової сторінки, то замість скріншота буде показано спеціальне зображення:
На кожен розділ зі змісту стоїть якірне посилання, щоб було зручно переміщатися документом.
2.2.2. Зведення
У цьому розділі зібрано коротке зведення за результатами сканування. Це найбільший звіт: він дозволяє швидко зрозуміти, які дані аналізуються та які помилки були знайдені.
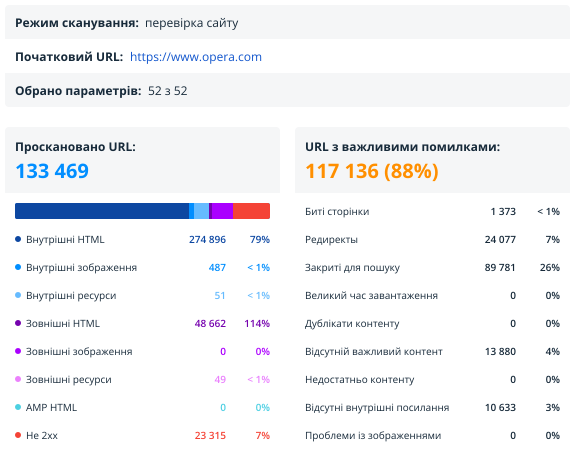
Тут відображаються такі дані:
- Режим сканування → перевірка сайту або перевірка списку URL-адрес.
- Початковий URL сканування. Якщо проскановано список URL, то тут з'явиться перший URL зі списку.
- Кількість параметрів, які були вибрані під час створення звіту.
- Кількість та типи URL, за якими побудовано поточний звіт.
- Кількість URL з важливими помилками (високої та середньої критичності).
- Основні типи помилок → свіже групування для ще швидшого розуміння результатів аудиту.
- Тип контенту → окремі діаграми для зовнішніх та внутрішніх сторінок.
- Основні хости.
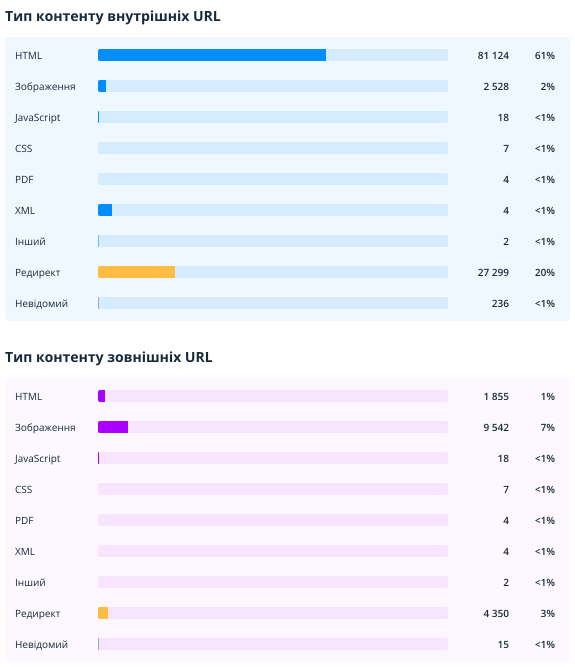
2.2.2.1. Тип контенту (внутрішніх та зовнішніх URL)
Ці звіти допомагають оцінити та порівняти кількість різних типів документів, знайдених під час сканування. Окремо показані діаграми для внутрішніх та зовнішніх URL (тут і в інших розділах звіту вони будуть позначені синім та фіолетовим кольором відповідно).
2.2.2.2. Основні хости
У цій таблиці відображаються основні хости, які аналізуються в даному аудиті — може бути корисно, якщо на вашому сайті багато хостів або під час перевірки списку URL.
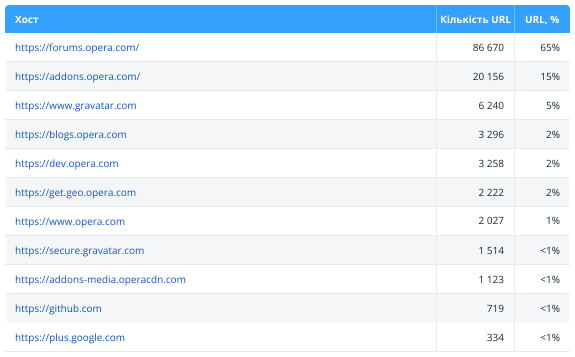
2.2.3. Структура URL
Цей звіт допоможе візуально оцінити структуру просканованих URL-адрес. Тут показані найбільш популярні хости та сегменти другого рівня (наприклад, site.com/category/).
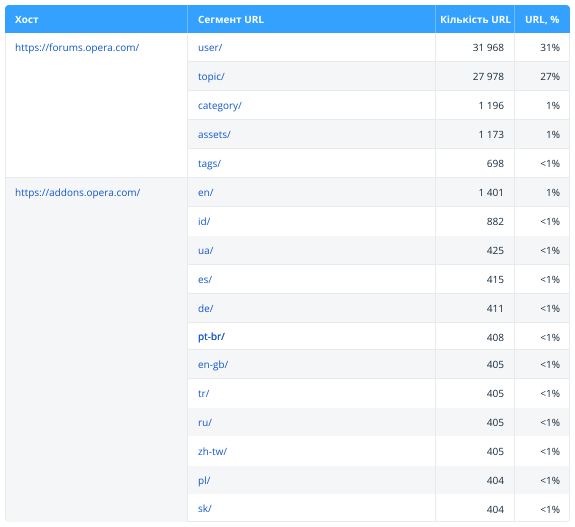
Зверніть увагу: у таблиці представлено максимум 40 сегментів, а повну структуру сайту можна отримати у Netpeak Spider у звіті «Структура сайту». Також зі звіту виключені URL з редиректами, оскільки вони є кінцевими адресами сторінок, і немає сенсу аналізувати їх сегменти.
Ще ми додали до звіту дані щодо [документів в корінні] — кількість документів, що знаходяться в корені сайту, тобто не містять сегментів.
2.2.4. Коди відповідей сервера
У цьому розділі відображаються коди відповідей сервера внутрішніх та зовнішніх URL-адрес.
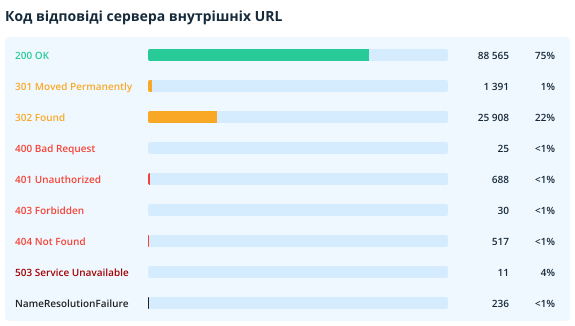
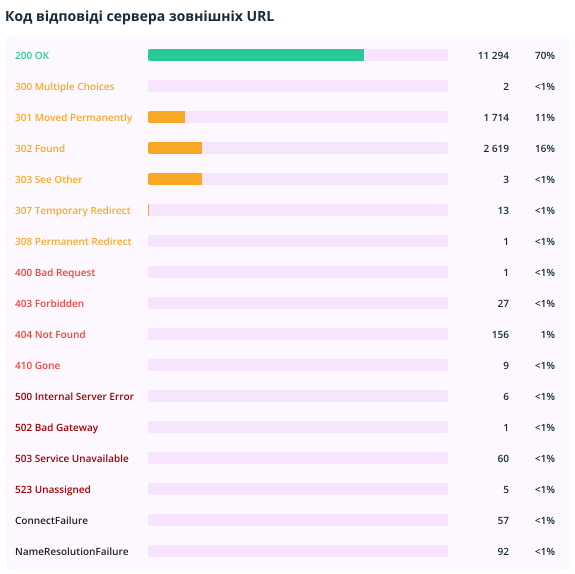
Зверніть увагу на недоступні документи, редиректи та сторінки, які повертають код відповіді сервера 4xx і вище. Щоб отримати список посилань на них, експортуйте звіти «Биті посилання» та «Редиректи: вхідні посилання та кінцеві URL» у Netpeak Spider.
2.2.5. Сканування та індексація
У розділі показано дані про інструкції та серверні налаштування, які впливають на сканування та індексацію контенту (тут аналізуються лише внутрішні URL). Нагадаємо, що документи, що не індексуються, часто не приносять трафік з пошукових систем і навіть, навпаки, витрачають краулінговий бюджет.
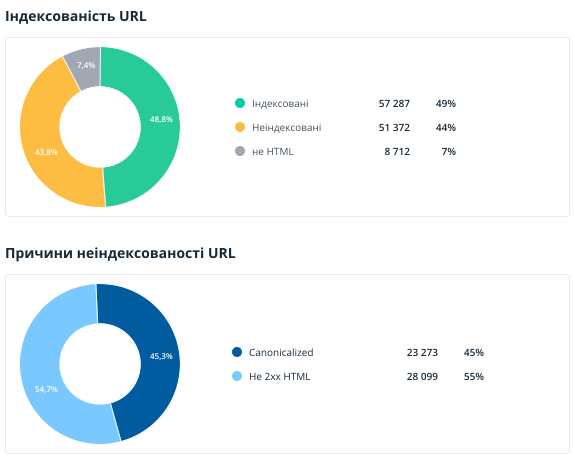
Можливо, діаграми з індексації та причин неіндексованості URL вам вже знайомі (вони також доступні на дашборді Netpeak Spider). А зведення за значеннями Meta Robots і X-Robots-Tag, а також використання canonical — це нові звіти, доступні поки що тільки в аудиті.
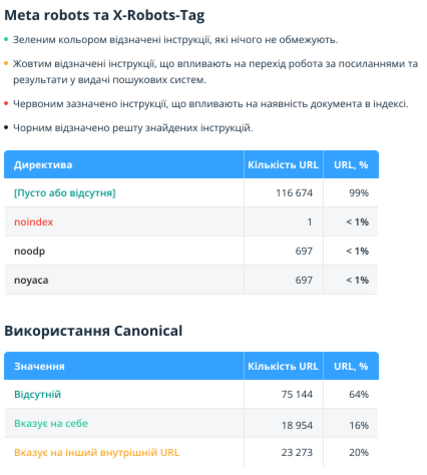
2.2.6. Глибина та вкладеність URL
У цьому розділі показано глибину (кількість кліків від початкової сканованої сторінки до поточної) та вкладеність URL (кількість сегментів на адресу документа).
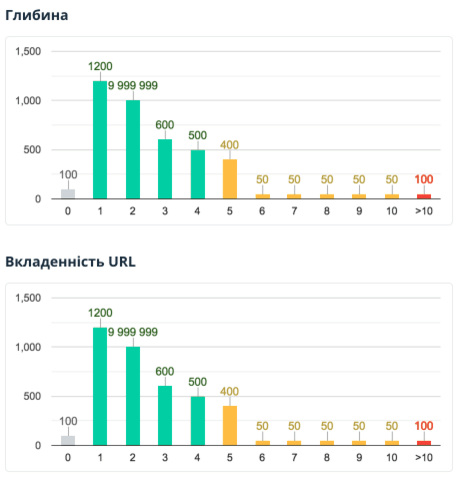
Зверніть увагу: у звіті аналізуються лише внутрішні індексовані HTML-сторінки, а значення глибини «0» присвоюється URL, з якого починалося сканування або які були додані списком.
Детальніше про можливі проблеми:
- Сторінки з глибиною більше «4» потенційно можуть гірше індексуватись і, як наслідок, не приносити органічний трафік.
- URL сторінок із вкладеністю більше «4» та/або надто довгою адресою можуть складніше сприйматися відвідувачами сайту.
2.2.7. Швидкість завантаження
Цей звіт допомагає оцінити швидкість відповіді сервера внутрішніх та зовнішніх документів. Цей параметр є важливим фактором ранжирування — швидкі сайти часто отримують більше трафіку, менше відмов і показують вищі результати конверсії. У звіті аналізуються лише URL із 2xx кодом відповіді сервера.
Найчастіше для генерації та обробки HTML-сторінок сервер витрачає більше часу, а статичні файли зазвичай кешуються та повертаються швидше. Тому ми розділили звіти для HTML і не HTML сторінок, щоб аналізувати сторінки схожих типів.
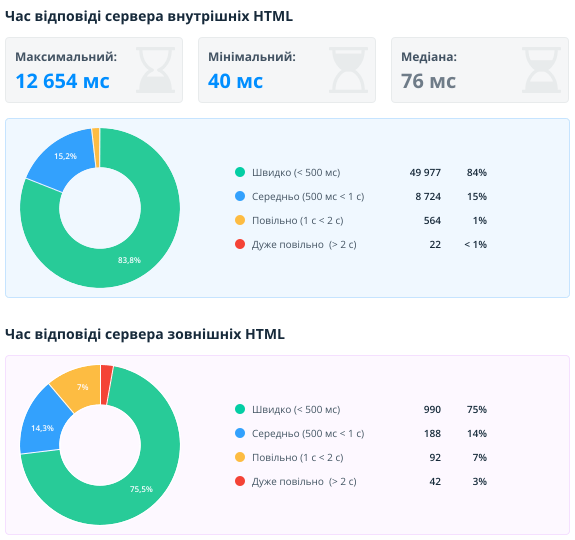
Також окремо показані внутрішні та зовнішні документи. Насамперед потрібно звертати увагу на внутрішні та зробити все можливе, щоб вони завантажувалися швидко. Але не варто забувати й про зовнішні. Якщо сайт посилається на зовнішній документ, який довго відкривається, то це погіршує досвід користувача. Якщо на HTML-сторінку завантажуються зовнішні ресурси (JS, CSS, зображення, шрифти), швидкість їх завантаження безпосередньо впливає на швидкість завантаження всієї сторінки.
Для внутрішніх документів виводяться додатково максимальне, мінімальне значення та медіана. Це допомагає швидко оцінити розподіл швидкості завантаження. Якщо сервер працює стабільно, то розподіл має бути невеликим.
2.2.8. Протоколи HTTP/HTTPS
У цьому розділі показано протоколи документів: захищений (HTTPS) та незахищений (HTTP). Ми показуємо цей звіт, оскільки якщо на сайтах з протоколом HTTPS є HTML-сторінки, зображення або ресурси з протоколом HTTP, це може призвести до помилки «Змішаний вміст». У цьому випадку користувачі можуть побачити у браузері попередження, а пошукові системи вважатимуть сайт небезпечним.
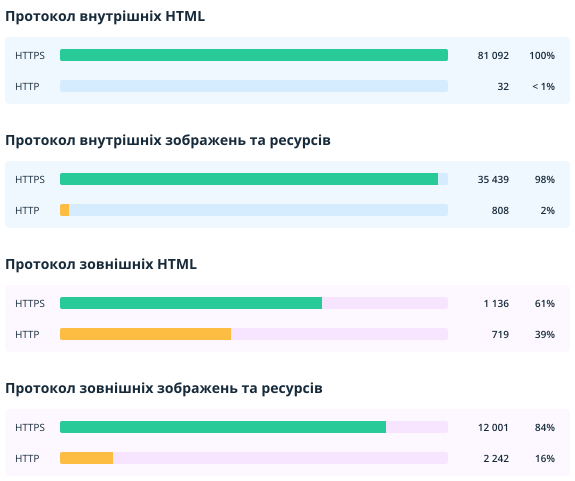
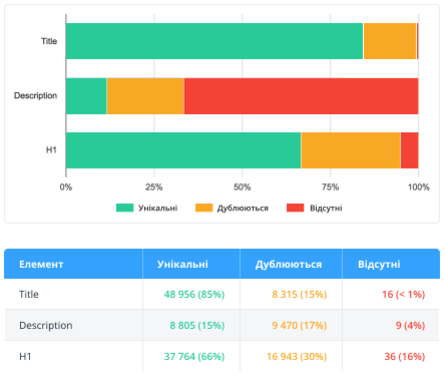
2.2.9. Оптимізація контенту
У цьому розділі аналізуються лише внутрішні індексовані сторінки, тому що SEO-помилки , пов'язані з контентом, необхідно усувати в першу чергу для внутрішніх сторінок сайту, які потенційно отримують трафік.
Ми зосередилися на даних, які можуть бути сигналом про втрачені можливості оптимізації та негативно вплинути на ранжування та відображення сайту у видачі пошукових систем:
- Title, description, H1: унікальність, наявність на сторінках, довжина → як для користувачів, так і для пошукових систем помилки в цих параметрах можуть говорити про неякісність сайту.
- Кількість символів і слів на сторінці → часто сторінки з більшою кількістю тексту перебувають у пошуку, оскільки краще розкривають тему.
- Розмір зображень → зображення з великою вагою завантажуються повільніше і тим самим знижують швидкість завантаження сторінки. Якщо ж сторінка завантажується довго (особливо на мобільних пристроях, де швидкість інтернету нижча), користувач може вважати сайт неякісним і залишити його.
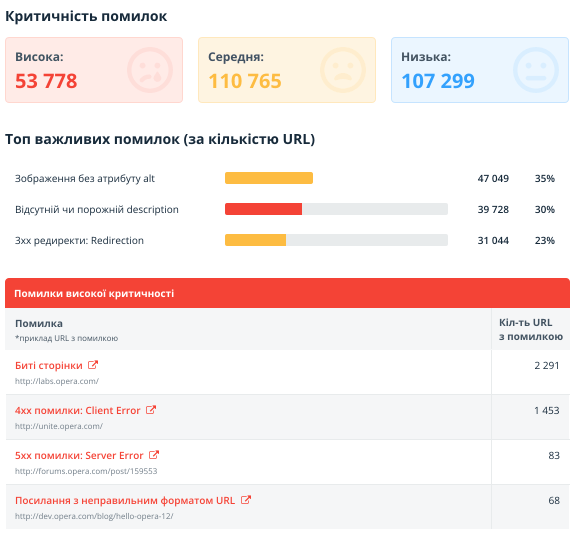
2.2.10. Помилки
У цьому розділі наведено звіти про помилки, виявлені під час сканування:
- Кількість URL з помилками різного ступеня критичності.
- Найважливіших помилок, виправлення яких може дати найбільш відчутний результат при просуванні.
- Список самих помилок з посиланнями на документацію та прикладами URL, де вони були виявлені.
2.2.11. Терміни
Наприкінці аудиту описано значення деяких важливих термінів.
- Проскановані URL — документи, за якими є хоча б якісь дані в таблиці з усіма результатами. Зверніть увагу, що застосування сегментації впливає на цей показник.
- Важливі помилки — помилки лише високої та середньої критичності.
- Внутрішні URL-адреси — це документи з доменом, таким як початкова URL або перша URL-адреса у списку: зазвичай це внутрішні сторінки сканованого сайту. У всіх розділах вони позначені синім кольором.
- Зовнішні URL-адреси — документи з адресою, що не містить домен початкової URL-адреси: щоб увімкнути їх аналіз, виберіть «Сканувати зовнішні посилання» на вкладці «Основні» налаштувань сканування. У всіх розділах вони відзначені фіолетовим кольором.
- Ресурси — документи, які не є HTML або зображеннями та повертають 2xx код відповіді сервера. У тому числі: файли JavaScript, CSS, PDF, XML, JSON, PlainText, GZIP та інші.
- Неіндексовані — HTML-документи з відмінним від 2xx кодом відповіді сервера або закриті від сканування та індексації.
2.2.12. Налаштування
У цьому розділі показано параметри та налаштування сканування, які використовувалися під час створення аудиту. Ми заздалегідь продумали можливі ситуації та вивели інформацію, яка дозволить визначити, яким чином відбувалося сканування, і чому не відображаються деякі звіти.

А тепер справа за вами → скоріше спробуйте згенерувати звіт за вже збереженими проектами або запускайте сканування, щоб зібрати дані та розглянути звіт у всіх деталях ;)
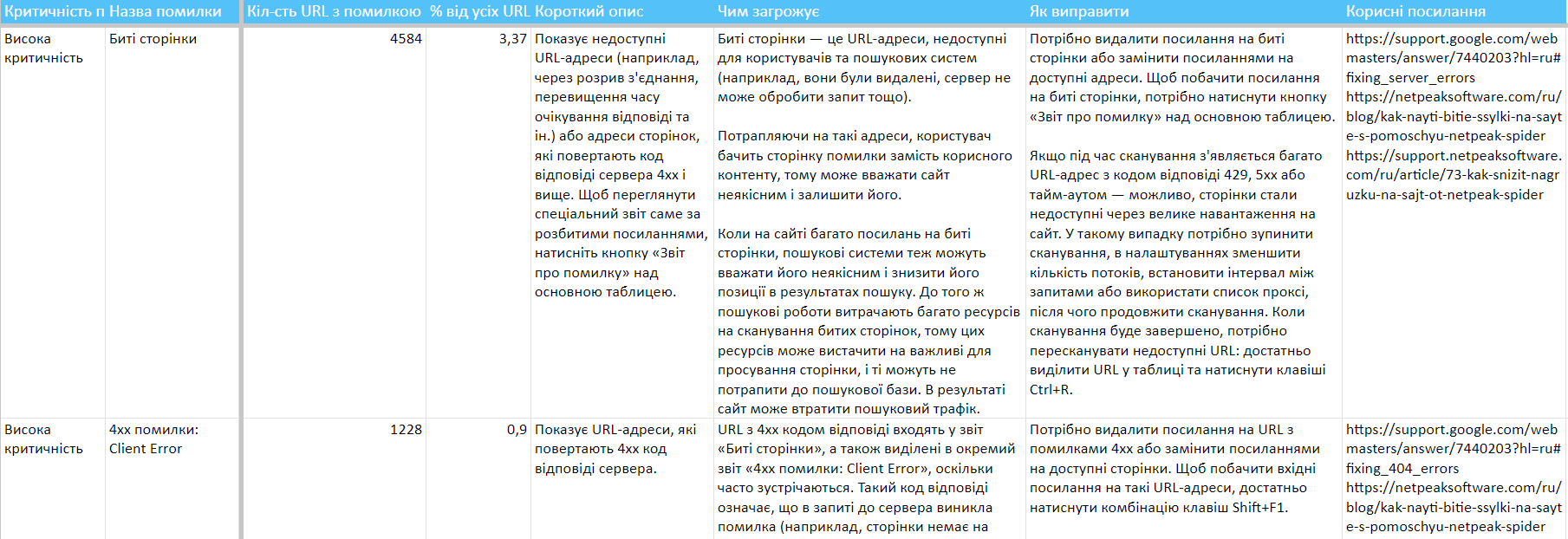
3. Розширений опис помилок
Під час сканування Netpeak Spider показує виявлені, а також невиявлені та вимкнені помилки на сайті. Вони можуть бути високої, середньої та низької критичності, що позначено відповідним кольором.
Якщо ви натиснете будь-яку помилку на бічній панелі на вкладці «Помилки», то в нижній частині інтерфейсу на панелі «Інформація» з'явиться її докладний опис.
Ми значно розширили опис кожної помилки пунктами:
- чим загрожує ця помилка,
- як її виправити,
- добіркою корисних посилань на матеріали, які допоможуть глибше дати раду проблемі.
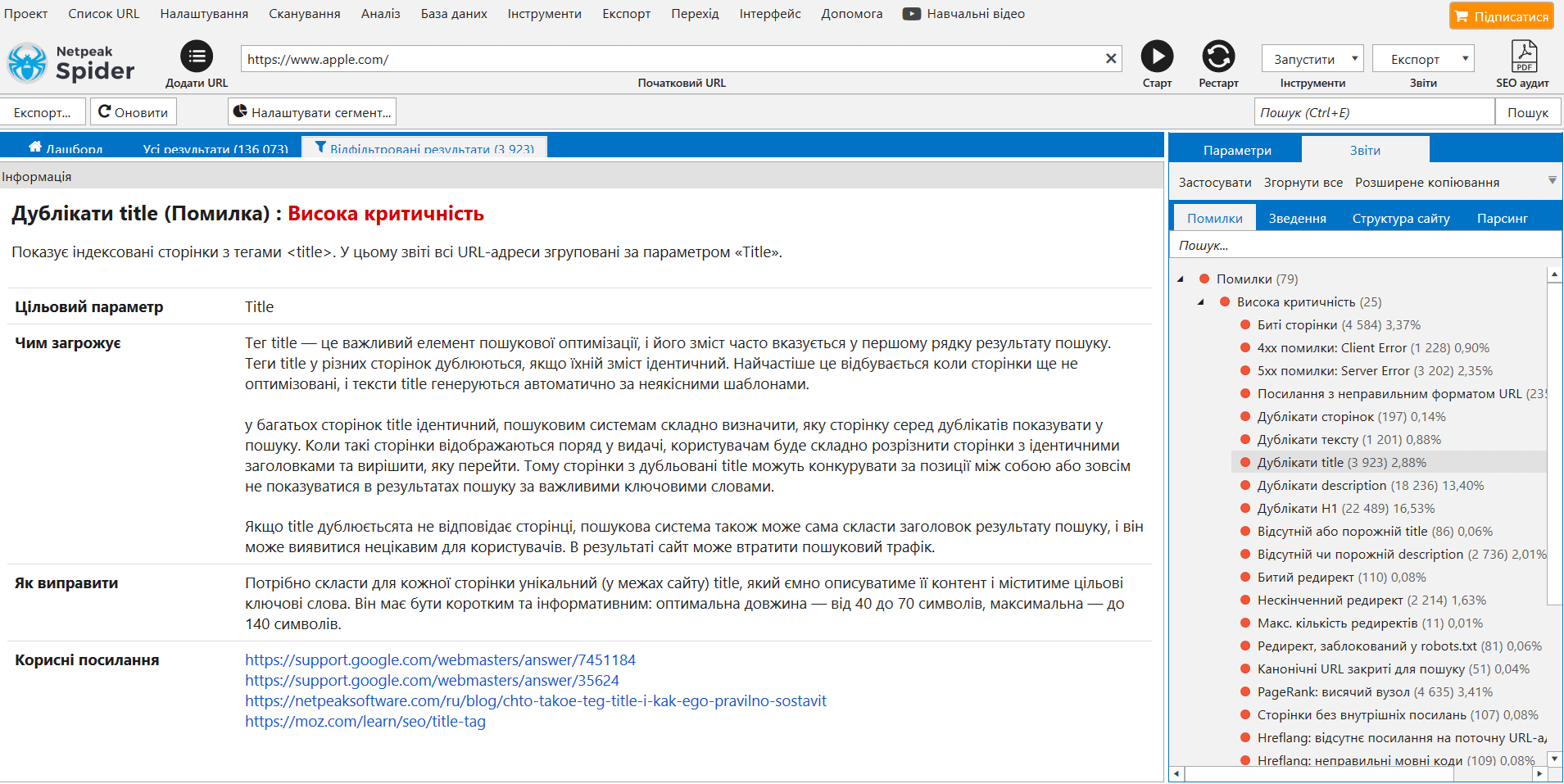
Тепер у разі виникнення будь-яких питань про помилки обов'язково загляньте на панель «Інформація» — ми постаралися відповісти на більшу частину з них саме там. До речі, спробуйте міняти висоту цієї панелі → так зручніше читати детальні описи помилок, де ми особливо захопилися ;)
3.1. Експорт звіту з розширеними описами помилок
Порадуємо ще однією корисною функцією, яка дозволить застосувати наші розширені описи помилок у вашій роботі.
Тепер ви можете експортувати комбінацію з короткого зведення за всіма знайденими помилками та розширеними описами до них. Це дозволить швидко поставити технічне завдання для їх усунення.
Цей звіт називається «Зведення помилок + описи». Він доступний у меню «Експорт» → «Звіти про помилки», а також у таких пакетних вивантаженнях:
- «Набір основних звітів»,
- «Всі помилки»,
- «Усі доступні звіти (основні + XL)».
3.2. Зміни у помилках: ступінь критичності, назви, сортування
Ми також зробили «генеральне прибирання» серед наших параметрів та помилок — і ось що змінилося.
3.2.1. Зміни в ступенях критичності помилок
Середня → висока:
- Дублікати H1;
- Ланцюжок канонічних URL;
- 5xx помилки: Server Error;
- Неправильний формат AMP HTML.
Висока → низька:
- Неправильний формат тегу Base;
- Макс. довжина URL-адреси.
Середня → низька:
- Декілька заголовків H1.
3.2.2. Зміни в назвах помилок та параметрів
- Биті посилання → Биті сторінки (оскільки в цьому звіті ви бачите сторінки, а посилання можна переглянути в окремому інтерфейсі або навіть вивантажити через меню «Експорт»);
- Дублікати Canonical URL → Однакові канонічні URL;
- Canonical, заблокований у robots.txt → Канонічний URL, заблокований у robots.txt;
- Ланцюжок Canonical → Ланцюжок канонічних URL;
- Canonical URL → Канонічний URL.
3.2.3. Зміни у логіці визначення помилок та параметрів
- Помилка «Неправильний формат тегу Base»: раніше відносна URL-адреса в цьому тегу вважалася помилкою. Тепер помилка визначається, якщо в атрибуті href вказано URL-адресу з неправильним форматом.
- Параметр «Канонічний URL»: тепер враховується лише абсолютна URL-адреса в інструкції canonical, як вимагає цього Google. Якщо вказано відносне → у таблиці буде вказано значення (NULL).
3.2.4. Зміни у сортуванні помилок
Ми покращили сортування помилок, поставивши на видні місця найважливіші та найпоширеніші з них.
4. Інші зміни
Ми завжди прагнемо реалізувати якнайбільше нових корисних фіч для наших користувачів. Для розробки функції виконання JavaScript ми користувалися версією фреймворку .NET 4.5.2. Тому новий Netpeak Spider може працювати тільки на операційній системі Windows не нижче версії 7 SP1, оскільки старіші версії ОС не підтримують цей фреймворк.
Коротко опишемо інші зміни в Netpeak Spider 3.2:
- Змінено логіку визначення внутрішніх адрес для списку URL. Щоб визначити, чи є посилання зовнішнім або внутрішнім, Netpeak Spider враховує «Початковий URL»: якщо домен збігається, посилання вважається внутрішнім, якщо ні — зовнішнім. Раніше при скануванні списку URL (і за відсутності початкового) усі посилання вважалися зовнішніми. Тепер вони порівнюються один з одним: якщо всі хости адрес належать одному домену, URL підуть у звіт про внутрішні посилання; якщо хоча б один URL відноситься до іншого домену, всі адреси вважатимуться за зовнішні. Ці зміни впливають на відображення результатів у звітах.
- Поліпшили шаблон параметрів «За замовчуванням». Це було необхідно для ефективної роботи нової функції експорту аудиту до PDF.
- Сортування результатів у таблиці зберігається лише на період сесії, тобто до перезавантаження програми. У новій сесії сортування буде стандартним, за порядковим номером URL. Ми змушені були зробити так, щоб не створювати нашим користувачам зайвий привід заплутатися в результатах аналізу.
- На дашборді під час сканування тепер виводяться нові налаштування «Рендеринг JavaScript» та «Ajax Timeout».
- Оптимізована робота з robots.txt. Тепер при запуску / продовженні сканування запит до robots.txt надсилається лише один для кожного хосту (раніше могло відправлятися кілька для одного і того ж robots.txt, якщо було встановлено багато потоків).
- Назва проекту та файлів експорту формується на основі початкового URL сканування. Тепер при збереженні проекту або звіту в назві файлу буде вказуватися хост з початкового URL (якщо сканується певний сайт) або першого URL таблиці (якщо перевіряється кастомний список URL).
- Було покращено оповіщення в правому нижньому кутку: про успішний експорт таблиці або звіту тепер відображається протягом 60 секунд (раніше було 7 секунд), щоб було зручніше натиснути на нього і перейти в папку розташування файлу; про закінчення сканування та інші тепер не забирають фокус з інших програм (раніше при їх виникненні активним ставало вікно Netpeak Spider).
- За замовчуванням увімкнено налаштування «Дозволити cookies» на вкладці просунутих налаштувань. Це є однією з найчастіших причин, чому сайт не сканується або сканується некоректно, тому ми включили облік cookies за умовчанням. Нагадаємо, що це налаштування не впливає на рендеринг у браузері: при скануванні в Chromium cookies завжди враховуються.
- Зроблено безліч змін текстів усередині програми, щоб ще краще пояснити деякі нюанси або підказати, як працює певний функціонал. Якщо ви помічаєте якісь неточності, повідомляйте про це нашу службу підтримки.
Зареєструйтесь, якщо ви ще не з нами
Щоб почати користуватися безкоштовним Netpeak Spider, просто зареєструйтесь, завантажте та встановіть програму — і вперед!
5. Коротко про головне
У версії Netpeak Spider 3.2 ми реалізували довгоочікуваний функціонал, який тепер дозволить користувачам ширше використовувати нашу програму, а саме:
- Рендеринг JavaScript;
- Технічний SEO-аудит у PDF зі звітами: «Зведення», «Структура URL», «Сканування та індексація», «Коди відповідей сервера», «Глибина та вкладеність URL», «Швидкість завантаження», «Протоколи HTTP/HTTPS», «Оптимізація контенту» та «Помилки»;
- Розширений опис помилок: чим загрожує, як виправити та список корисних посилань;
- Експорт нового звіту «Зведення помилок + описи»;
- А також 50+ інших покращень.
Друзі, дякуємо за увагу! Сподіваємося, тепер ваша робота з Netpeak Spider стане ще більш ефективною ;) Ми були б дуже раді дізнатися ваш фідбек, так що не забувайте про можливість залишити коментар з відгуком або пропозицією, а ми поки що попрацюємо над впровадженням нових фіч в Netpeak Checker!


