Как закрыть сайт от индексации
Мануалы

Закрывать сайт от индексации нужно, например, при проведении технических работ. Это можно сделать несколькими способами: через robots.txt, метатег robots или заголовок X-Robots-Tag. Вебмастера иногда сталкиваются с ситуацией, когда запрет не срабатывает, и страницы сайта все равно индексируются поисковиками. В посте расскажем о том, как запретить индексацию сайта и убедиться в корректности этого запрета.
1. Зачем закрывать сайт или страницу от индексации
После релиза сайта его страницы сканируются роботами при первом обходе. Однако если дизайн и контент страниц пока ещё не оптимизированы для продвижения, рекомендуется на время доработок закрыть сайт от поисковиков. В каких ещё ситуациях нужен запрет на индексацию:
- Создание мобильной версии на отдельном домене. В этом случае появляются дубли страниц, которые поисковики могут зафиксировать.
- Тестирование сайта на другом домене. Если вы создали аналог основного сайта и проводите на нём тестовые работы, поисковые роботы могут воспринять страницы сайтов как дубликаты. В результате основной сайт может потерять позиции.
- Смена дизайна, параметров, контента. На время работ по улучшению интерфейса и юзабилити закройте страницы сайта от индексации полностью или частично.
Читайте также: «Как сделать редизайн сайта без вреда для SEO».
Запрет на сканирование — часто временное явление. После окончания технических работ вы сможете вернуть сайт в прежнее состояние. Такой шаг помогает сохранить позиции в выдаче.
2. Как закрыть сайт от индексации
Я уже упомянула, что полностью запретить индексацию сайта можно тремя способами. Теперь предлагаю рассмотреть каждый из них отдельно.
2.1. Robots.txt
Файл robots.txt позволяет запретить индексацию страниц, разделов или всего сайта. Используйте директиву Disallow в качестве команды для поисковых роботов. Если нужно закрыть весь сайт от всех роботов, пропишите в файле robots.txt:
Для обращения к конкретному роботу вместо «*» используйте его название. Например, если нужно закрыть сайт от Яндекс, впишите в robots.txt:
Если требуется закрыть от индексации всеми роботами определённые разделы, укажите их после директивы Disallow. Для каждого типа контента используйте отдельную директиву. Пример:
Многие SEO-оптимизаторы отмечают, что Google часто игнорирует директиву Disallow и продолжает индексировать все страницы сайта. Проверить это можно в Google Search Console.
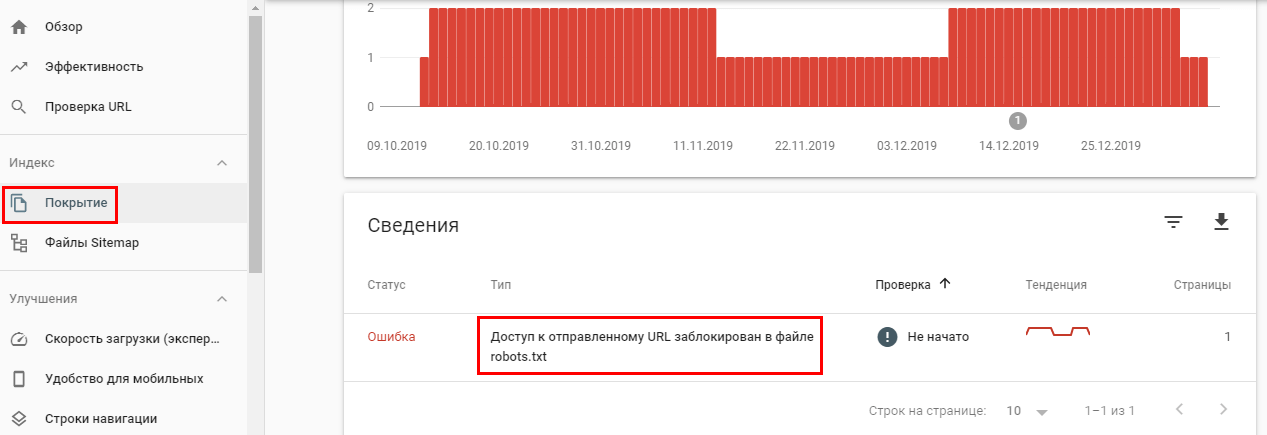
Если страница закрыта от индекса в robots.txt, но это не указано в панели вебмастеров, скорее всего, Google-бот продолжит индексировать эту страницу.
Для проверки в Яндекс.Вебмастер перейдите в раздел «Индексирование».
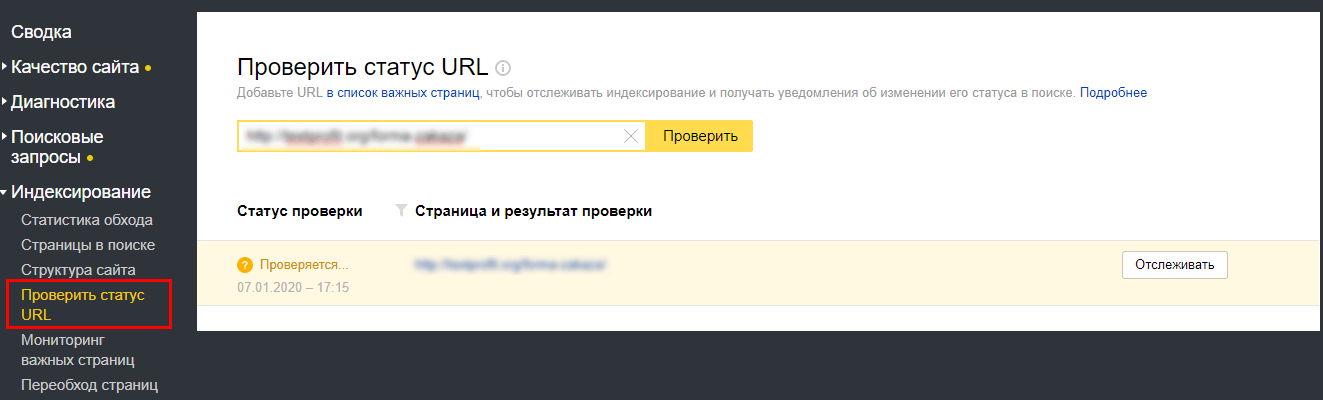
Если директива Disallow в robots.txt не помогает закрыть страницу от индексации, используйте следующий метод.
2.2. Метатег Robots
Этим способом можно предотвратить сканирование роботами контента. С его помощью можно также закрыть текст от индексации. Это необходимо, когда страницу нужно проиндексировать за исключением отрывка текста. Для этого добавьте в раздел <head> страницы строку кода:
Чтобы скрыть ссылку от поисковиков, используйте nofollow:
или:
Использование метатега не гарантирует полное закрытие сайта от индексации. После редактирования кода проверьте количество проиндексированных страниц через панели вебмастеров. Если ничего не изменилось — попробуйте дополнительно закрыть сайт от всех роботов в файле .htaccess. Он доступен через админ-панель на хостинге. В открытом файле последними строками пропишите команды:
Если и этот вариант не помогает, используйте метод серверного заголовка, описанный в следующем пункте.
2.3. X-Robots-Tag
Использование HTTP-заголовка на уровне сервера также является хорошим способом запретить поисковикам индексировать определённый контент на сайте. Реализовать это можно двумя способами: через PHP и .htaccess. Второй вариант более удобный, так как не нужно вносить правки в код PHP. Откройте файл .htaccess и пропишите строки в конец документа:
Так вы закроете от индексации все файлы в формате html через директиву FilesMatch. Таким же образом можно закрыть от индексации, например, картинки в форматах .png, .jpeg, .jpg, .gif.
С помощью X-Robots-Tag можно закрыть от индексации медиа-контент, скрипты и другие файлы. Для этого нужно указать их формат после директивы FilesMatch в первой строке заголовка.
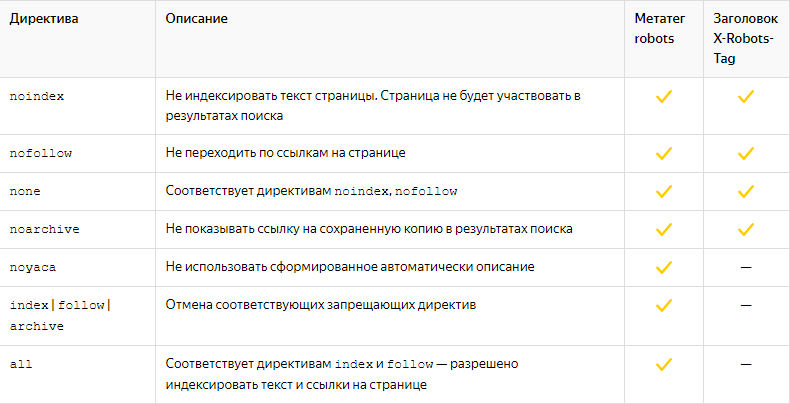
Большинство директив, которые можно использовать в X-Robots-Tag, совпадают с директивами Robots.
Файл .htaccess позволяет закрыть от индексации статические страницы. Запрет индексации динамически формируемого контента возможен только через PHP. Для этого необходимо редактировать файл index.php, который находится в корне сайта. Откройте код и добавьте в любое место раздела <head> строку:
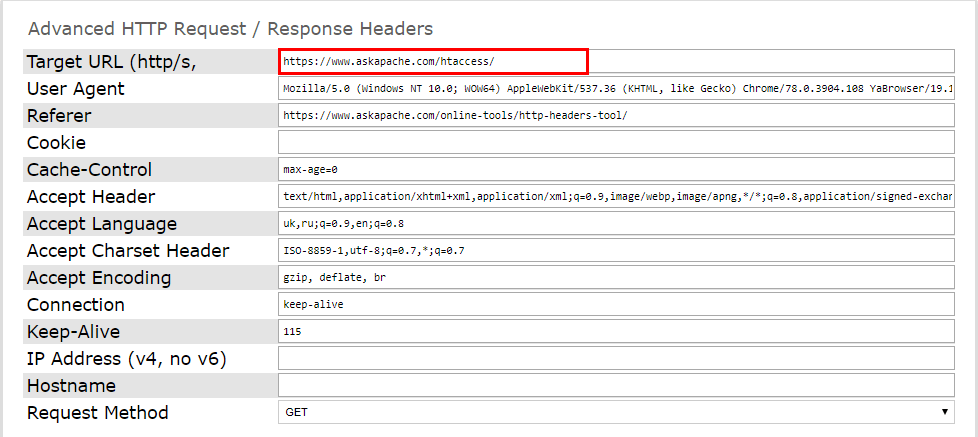
И проверьте работоспособность серверного заголовка. Это можно сделать при помощи онлайн-инструментов. Например, Askapache. Введите нужную страницу и запустите проверку.
Подключённый заголовок выглядит так:

Проверить код ответа сервера можно и через Яндекс.Вебмастер. Активный X-Robots-Tag отобразится в списке всех заголовков ответа сервера.
Подводим итоги
При проведении технических работ желательно временно закрыть сайт от индексации. Так вы сможете работать над дизайном и юзабилити без ущерба для поисковой оптимизации. Для запрета индексации контента используйте один или несколько методов: директива Disallow в robots.txt, метатег Robots или серверный заголовок X-Robots-Tag. Перед началом работ проверьте работоспособность используемого метода в панелях вебмастеров либо при помощи онлайн-инструментов.


