Что такое robots.txt, и зачем он нужен сайту
Мануалы

Файл robots.txt хранится в формате текста на сервере. Он состоит из латинских символов и знаков, с помощью которых создаются команды для роботов о том, какие страницы нужно индексировать, а какие нельзя. Robots.txt создаётся по стандартному синтаксису, его директивы понимают роботы всех поисковых систем. Если не использовать этот файл, все страницы сайта будут просканированы без разбора. Это может негативно сказаться на результатах поисковой выдачи.
1. Что такое robots.txt
Это файл, в котором находится обычный текст, состоящий минимум из двух строк. Точное количество слов определяется в индивидуальной потребности запретить или разрешить обход конкретных страниц. Каждая строка файла — одна команда в форме директивы. Она описывает конкретный раздел, категорию или страницу. Каждый раздел начинается с новой строки.
Robots.txt редактируется в любое время, если возникает потребность закрыть от индекса дубли, персональные данные, пользовательские соглашения или новые страницы. Для этого он выгружается через файловый менеджер и редактируется на компьютере. После внесения правок обновлённый robots.txt нужно снова загрузить на сервер и проверить его по ссылке yoursite.ua/robots.txt, где yoursite.ua — название сайта.
Файл также можно создать для запрета или разрешения индексации сразу всех страниц сайта. С его помощью также можно скрывать разделы ресурса для разных роботов. Если прописанные директивы относятся ко всем роботам, в конце первой строки ставится знак «*». При обращении к конкретному поисковику необходимо прописать его название в первой строке-директиве User-agent.
Пример robots.txt:
1.1. Для чего нужен robots.txt
- определение списка индексируемых страниц;
- уменьшение нагрузки на сервер при обходе сайта поисковыми роботами;
- указание главного зеркала сайта;
- указание пути к карте сайта (Sitemap);
- определение дополнительных правил обхода страниц через директивы.
Иногда роботы не учитывают директивы из robots.txt. Такое случается из-за ошибок в синтаксисе. Наиболее распространенные:
- размер файла превышает (32 КБ для Яндекс и 512 КБ для Google);
- опечатки в прописанных директивах или ссылках;
- формат файла не является текстовым и / или содержит недопустимые символы;
- файл недоступен при запросе к серверу.
Время от времени следует проверять корректность и доступ к robots.txt, а также исследовать его на ошибки в синтаксисе. Кстати, в некоторых CMS и хостинг-панелях есть возможность редактировать файл из админки.
2. Синтаксис robots.txt
Синтаксис файла состоит из обязательных и необязательных директив. Для правильного считывания роботами их нужно прописывать в определённой последовательности: первая директива в каждом разделе — User Agent, далее Disallow, Allow, в конце — главное зеркало и карта сайта.
Несмотря на стандартные правила создания, поисковые боты по-разному считывают информацию из файла. Например, запрет индексации параметров страницы понимает только Yandex, а Googlebot пропустит эту строку.
Важное правило — не допустить ошибки в директивах. Один неверный символ может привести к некорректной индексации.
Чтобы минимизировать риск ошибок, придерживайтесь основных правил составления синтаксиса:
- в одной строке прописывается максимум одна директива;
- каждая директива — новая строка;
- в начале строк и между строками не должно быть пробелов;
- в описании параметра не должно быть переносов на другую строку;
- в названии robots.txt и параметрах директив не используются символы верхнего регистра;
- присутствует знак «/» перед каждой директорией. Пример: /products;
- в описании директив могут быть символы только латинского алфавита;
- только один параметр в директивах Allow и Disallow;
- Disallow без описания равнозначно Allow/ — разрешить обход всех страниц;
- Allow без описания то же, что и robots.txt disallow/ — означает запрет индексации всех страниц.
2.1. Основные директивы синтаксиса
- User-agent — обязательная директива, указывается в начальной строке и означает обращение к поисковым ботам. Пример:User-agent: * — для всех поисковиков; User-agent: Yandex — только Яндекс; User-agent: Googlebot — только Google.
- Disallow — запрет на обход папок, разделов или отдельных страниц сайта. Пример: User-agent: * Disallow: /page — всем роботам запрещается индексация раздела и всех категорий, которые в него входят.
- Allow — индексация всех страниц и их разделов. Пример:User-agent: * Allow: / — всем роботам разрешается индексация всего сайта.
- Noindex — запрет на индексацию части контента на странице. Отличается от Disallow тем, что Noindex используется непосредственно в коде страницы и выглядит так: <meta name=”robots” content=”noindex” />
- Clean-param — запрет на индексацию параметров в адресе страницы. Эта директива видна только Яндекс-боту. Например, с её помощью можно закрыть от индекса UTM-метки:Clean-param: utm_source&utm_medium&utm_campaign /catalog/
- Crawl-Delay — определение минимального периода времени между обходами страниц. Например:User-agent: Yandex Disallow: /page Crawl-delay: 2 — после индексации одной страницы пройдёт не менее двух секунд до начала индексации следующей страницы.
- Host — указание основного зеркала сайта. Пример:Host: yoursite.com
- Sitemap — расположение карты сайта. Пример:Sitemap: yoursite.com/sitemap
3. Как создать robots.txt
Файл robots.txt создаётся в текстовом редакторе на компьютере либо генерируется автоматически при помощи онлайн-сервисов. Отредактировать его можно в обычном блокноте. Пример robots.txt:
В директивах иногда добавляют комментарии для веб-мастеров, которые вставляют в файл после знака # с новой строки. Роботы не учитывают эти данные. Пример robots.txt с комментарием:
Если вы сомневаетесь или не имеете возможности создать файл самостоятельно, воспользуйтесь виртуальным сервисом. Генераторы robots.txt создают файлы по заданным параметрам, которые нужно сразу прописать.
4. Как проверить robots.txt
Протестировать готовый документ можно в сервисах Google и Yandex. Проверка robots.txt возможна лишь после загрузки окончательной версии в корень сайта. Если файл не загружен в корневой каталог, сервис выдаст ошибку.
При обнаружении и успешной проверке файла появляется соответствующее сообщение:
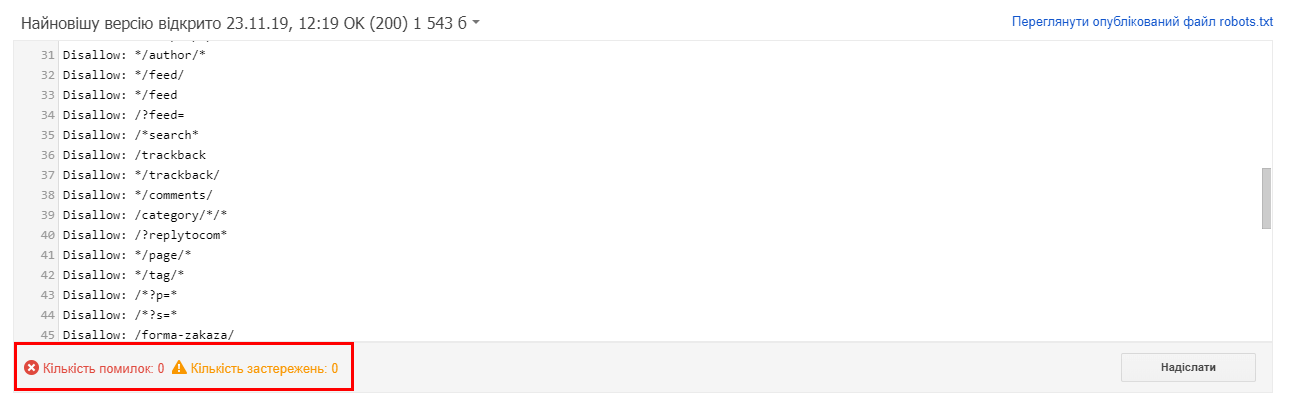
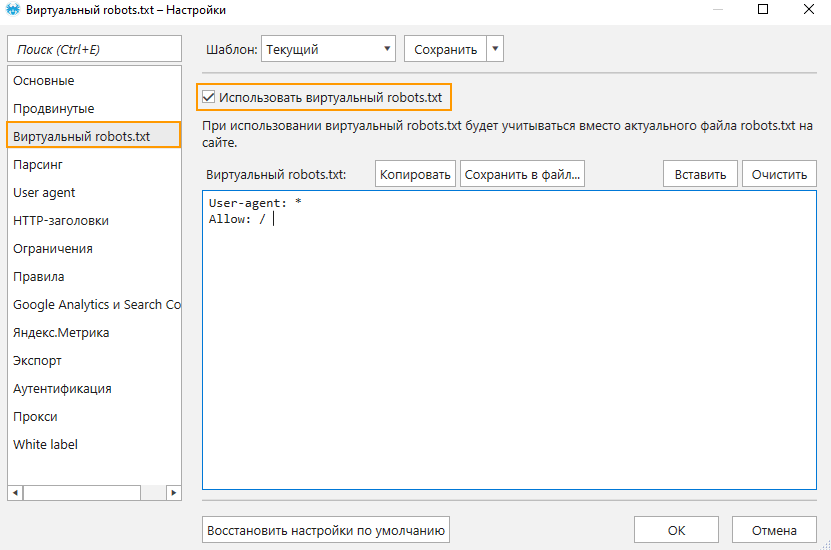
Протестировать robots.txt можно в Netpeak Spider. Для этого:
- Откройте «Настройки» → «Виртуальный robots.txt», отметьте пункт «Использовать виртуальный robots.txt».
- Поместите содержимое файла в окно и сохраните настройки.
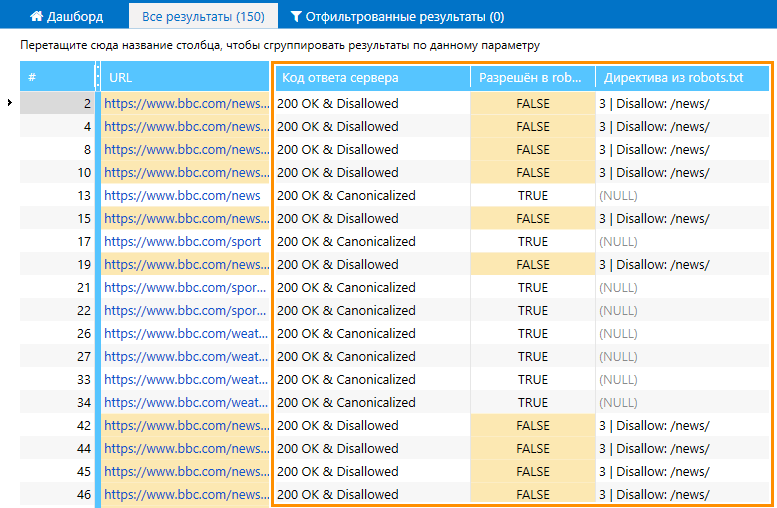
- В поле «Начальный URL» введите домен сайта и начните сканирование.
- Данные, актуальные для прописанного вами виртуального файла, вы увидите в основной таблице.
Наглядно посмотреть, как проверить корректность настройки файла robots.txt, вы можете в этом видео:
Чтобы начать пользоваться Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! 😉
Подводим итоги
Файл robots.txt состоит из текстовых директив и хранится в корне сайта на сервере. Он используется для разрешения и запрета индексации поисковиками страниц, разделов, каталогов и отдельных параметров.
Дополнительно в файле можно прописать главное зеркало и ссылку на карту сайта. Условия индексации могут касаться всех поисков либо каждого по отдельности. Через robots.txt можно задать уникальные условия для каждого поисковика.
При составлении файла важно соблюдать стандартные правила. Создать его можно вручную либо при помощи онлайн-генератора. Для проверки и тестирования готового файла используются онлайн-сервисы либо десктопные программы, например Netpeak Spider.


