Углубленный SEO-анализ вашего вебсайта
Избавьтесь от хлопот SEO-аудита - с Netpeak Spider вы можете детально проанализировать любой сайт всего за несколько минут.
Для Windows & macOS



💡 Как начать использовать Netpeak Spider
 Ключевые преимущества нашего приложения для SEO-анализа
Ключевые преимущества нашего приложения для SEO-анализа
Главные преимущества Netpeak Spider
1. Совместимость с Windows и macOS
Откройте для себя возможности Netpeak Spider, разработанного как для пользователей Windows, так и для macOS.

2. Находит более 100 типов ошибок и правильно их приоритезирует
Netpeak Spider производит углубленный технический аудит сайта и обнаруживает нерабочие ссылки, дубликаты страниц, неисправные мета теги и другие ошибки. Он также предоставит вам подробное описание каждой проблемы: тип угрозы, которую она несет, советы по ее устранению и даже список полезных ссылок с дополнительной информацией. Кроме того, наш сканер классифицирует проблемы по степени опасности и выделяет их подходящим цветом.

3. Рендеринг JavaScript
Наше приложение умеет сканировать URL, использующие JavaScript (JS), с помощью новейшей версии Chromium. Это делает сканирование веб-страниц максимально похожим на проверки через Googlebot.

4. Многооконный режим
Являясь профессиональным инструментом для SEO-аудита, Netpeak Spider позволяет работать над несколькими проектами одновременно. Запускайте приложение сразу в двух и более окнах и работайте над нужными задачами в каждом.
Откройте для себя Netpeak Spider на macOS
Создайте аккаунт и установите Netpeak Spider для мгновенного сканирования вашего проекта. Получите результаты аудита в течение нескольких минут и раскройте возможности инструмента для SEO-анализа на macOS.
Пробуйте в течение 3 дней · Далее $20 в месяц · Отмена подписки в любое время
Функциональность и удобство использования
1. Фильтры и сегментация данных
Фильтр данных удобно использовать для сканирования больших веб-страниц. Получайте подробную сегментированную информацию о любом сайте. Просматривайте данные по желаемым сегментам, фильтруйте результаты и отбирайте параметры, доступные на панели управления. Задайте собственные условия фильтрации и изменяйте обзор данных, установив соответствующие ограничения для конкретных сегментов.

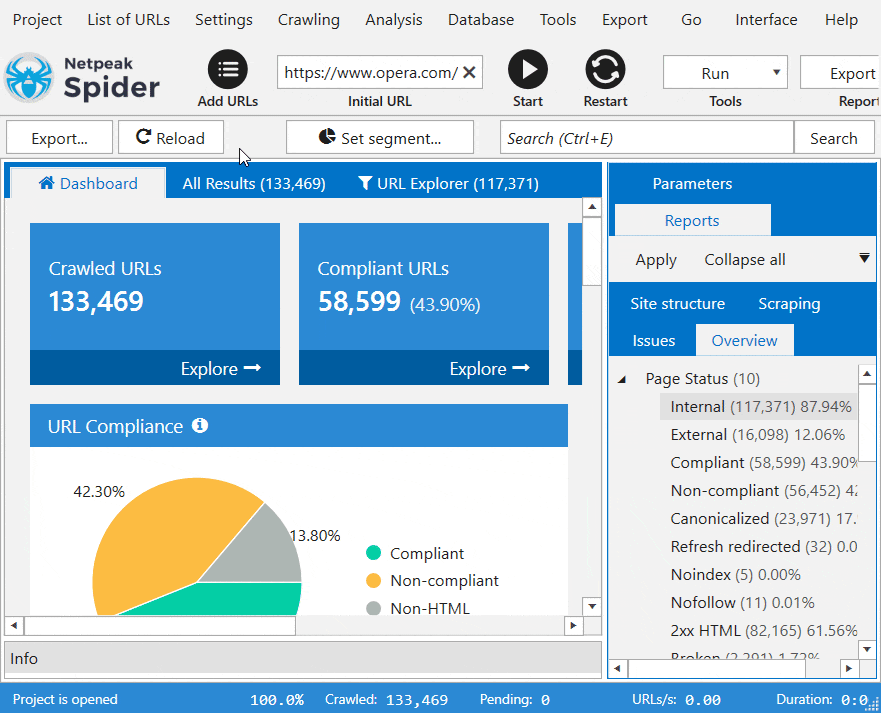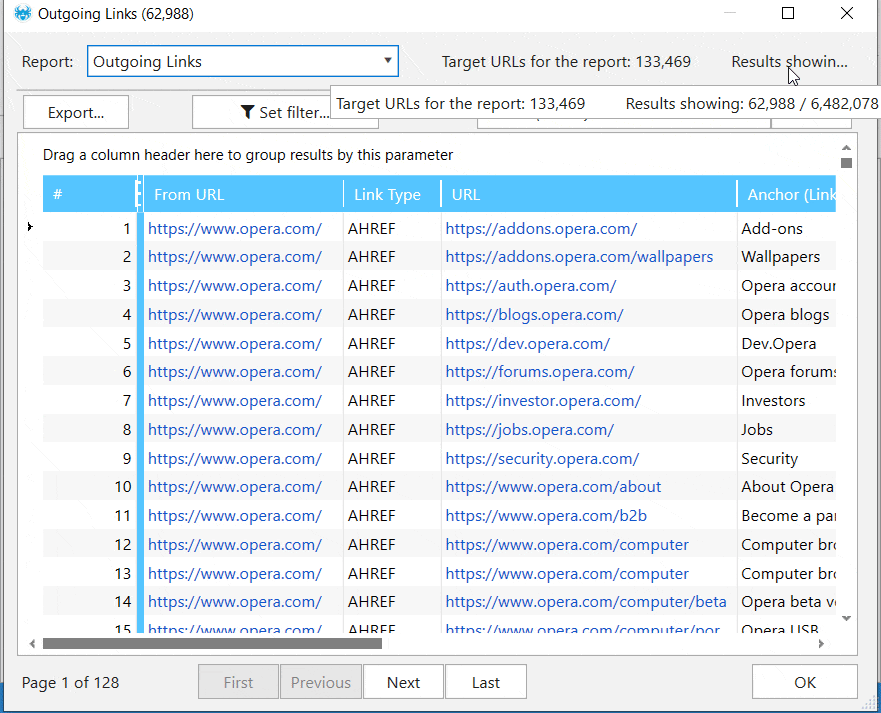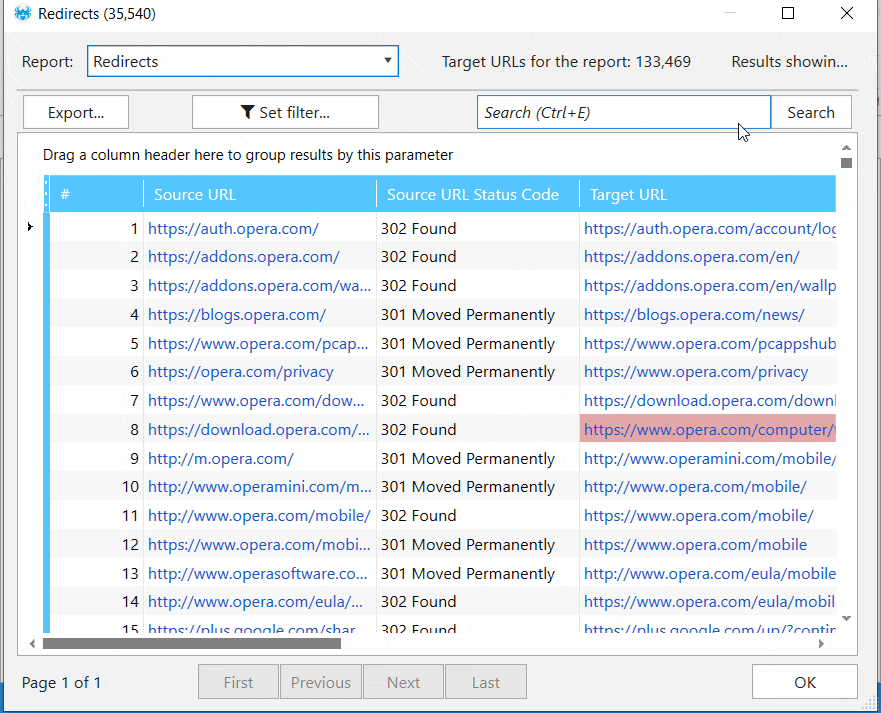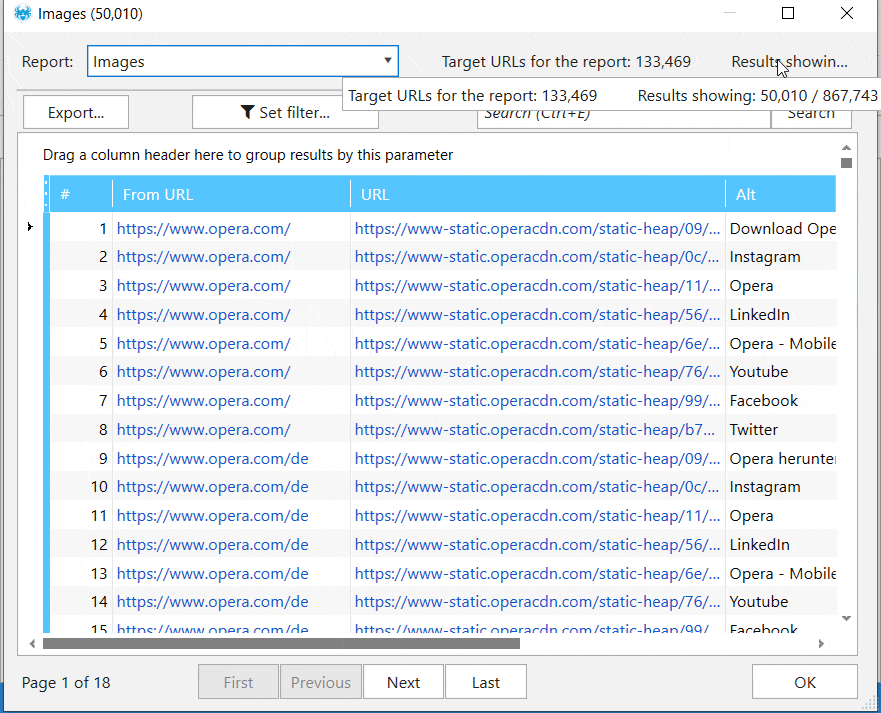
2. Интерактивная информационная панель
Наша интерактивная панель данных обновляет показатели вживую – в зависимости от этапа сканирования веб сайта. Как только процесс сканирования приостанавливается или завершается, наше приложение покажет готовые графики с аналитикой по целевой странице.
3. Управление настройками анализа
Чтобы сделать SEO-аудит наиболее эффективным, Netpeak Spider позволяет выбирать, изменять или отключать некоторые параметры сканирования и сосредоточиться на важнейших показателях. Таким образом вы ускоряете сканирование сайта и уменьшаете потребление оперативной памяти и ресурсов процессора. Используйте удобный поиск по параметрам и быстро анализируйте самые необходимые из них. Даже если вы запустили сканирование по всем доступным параметрам, вы можете в любой момент удалить ненужные. Просто синхронизируйте текущую таблицу результатов с нужными вам метриками.

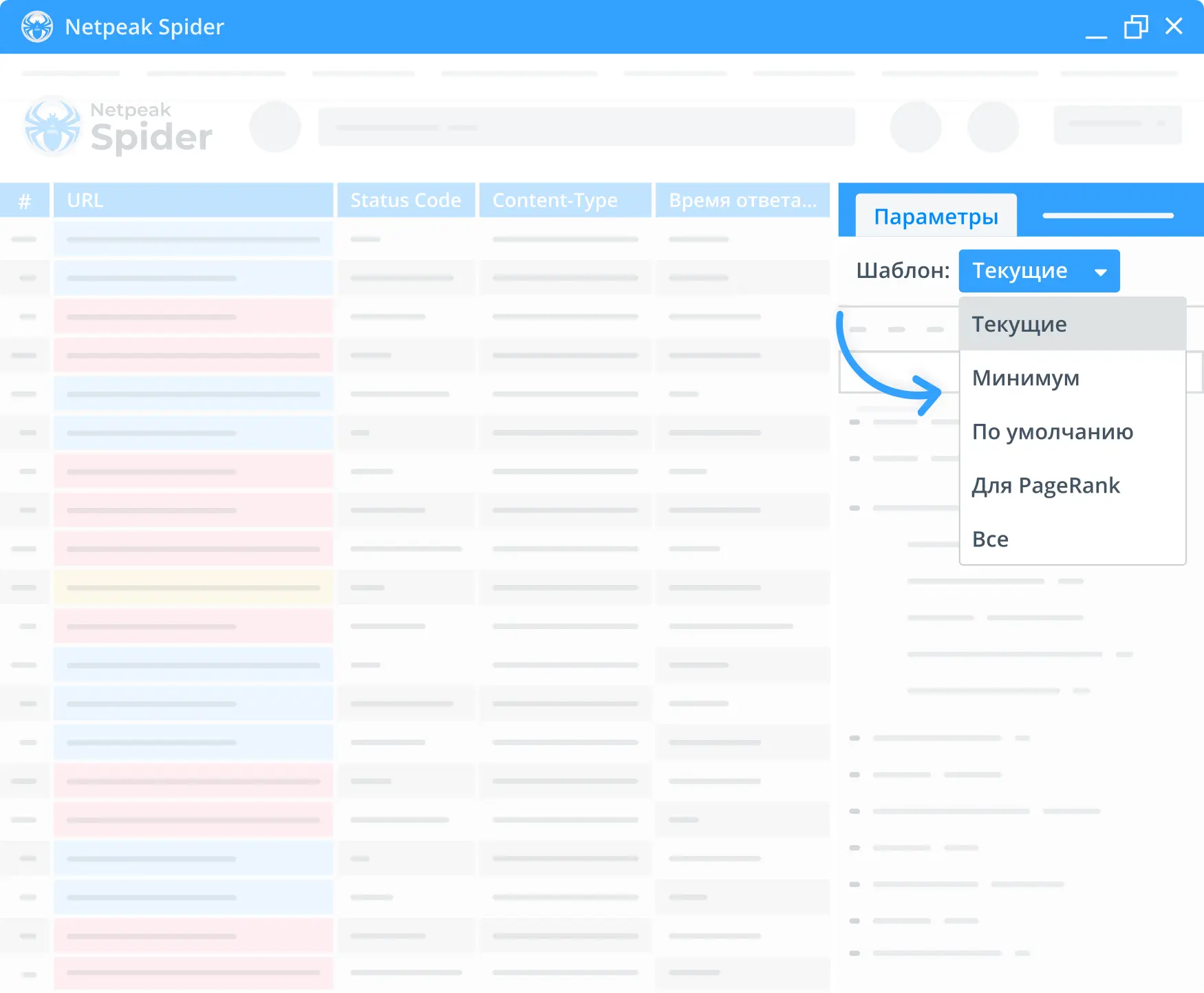
4. Шаблоны настройки фильтров, параметров и сегментов
Легко создавайте и сохраняйте собственные шаблоны с нужными параметрами, сегментами или настройками, которые вы хотите проверить, и избавьтесь от лишней ручной работы. Netpeak Spider предлагает готовые шаблоны для ускорения SEO-аудита.
Доступные встроенные инструменты
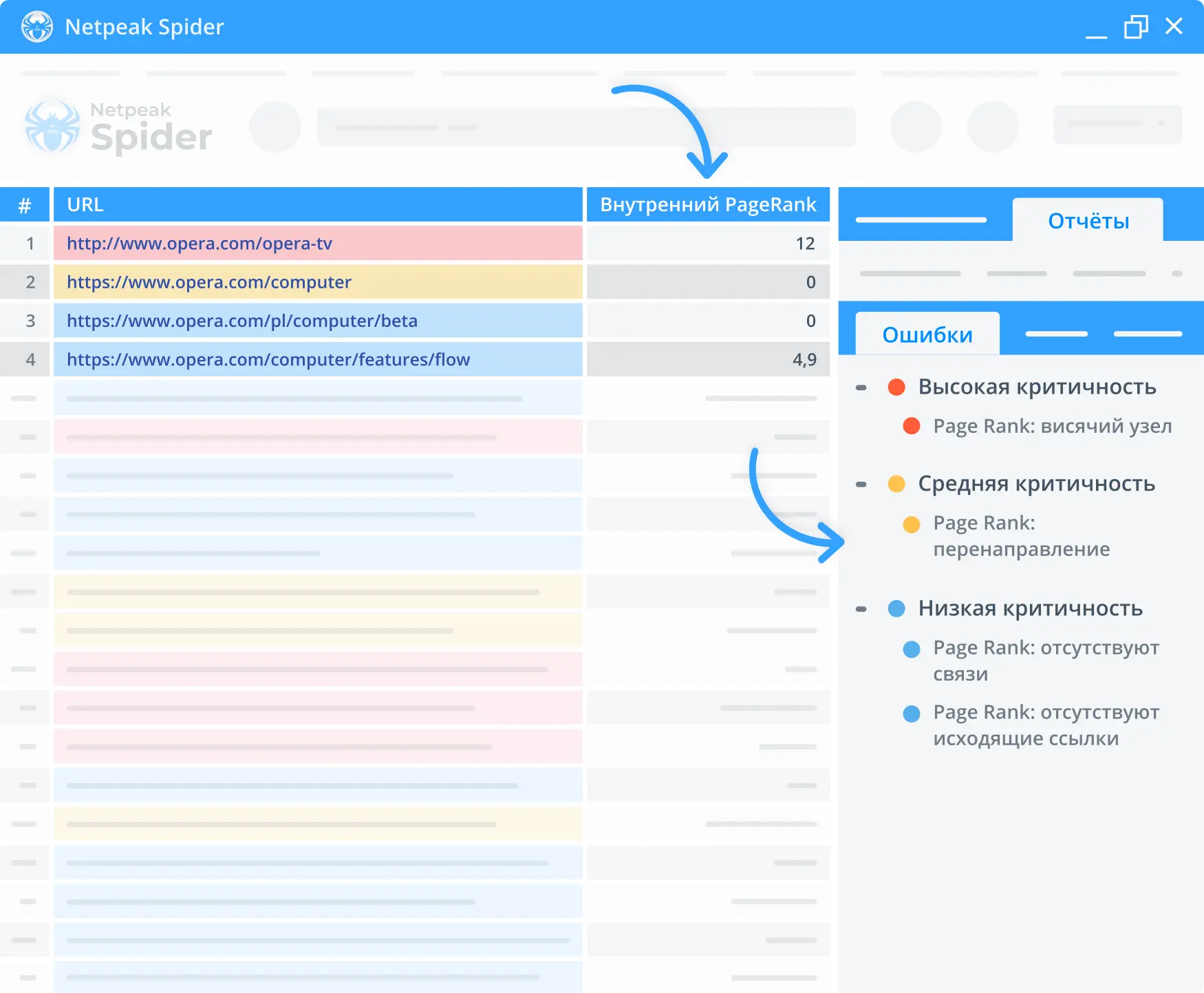
1. Калькулятор PageRank
Используйте встроенный калькулятор PageRank в нашем бесплатном приложении, чтобы проверить внутреннюю перелинковку вашей страницы. Проверяйте, на каких страницах сосредоточен основной массив ссылок, а какие – не имеют ее вообще.
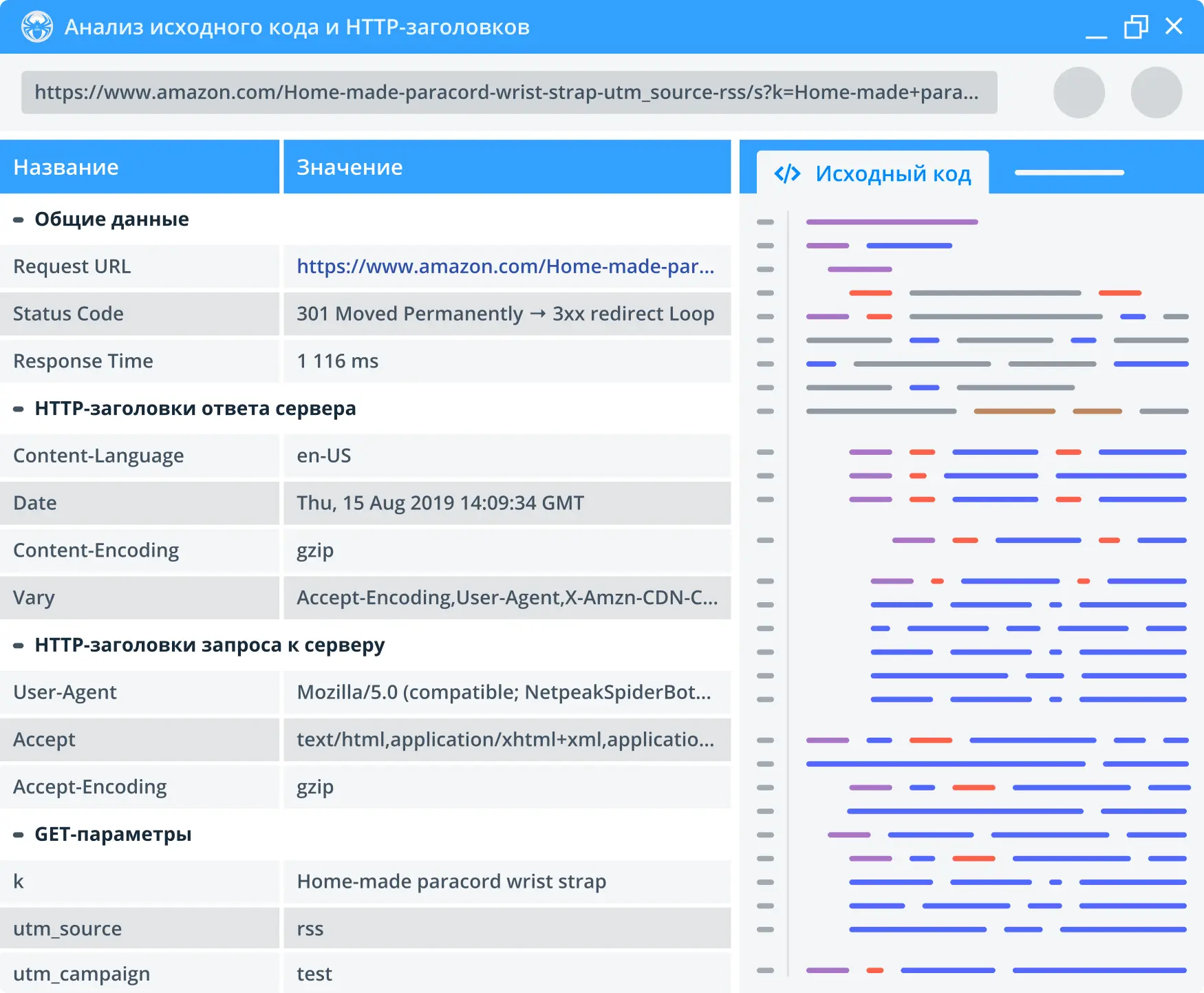
2. Проверка исходного кода и HTTP-заголовков
Встроенный в Netpeak Spider инструмент позволяет проверять заголовки HTTP-запроса и ответы в любой ссылке, переадресации и весь имеющийся текст без HTML-кода.
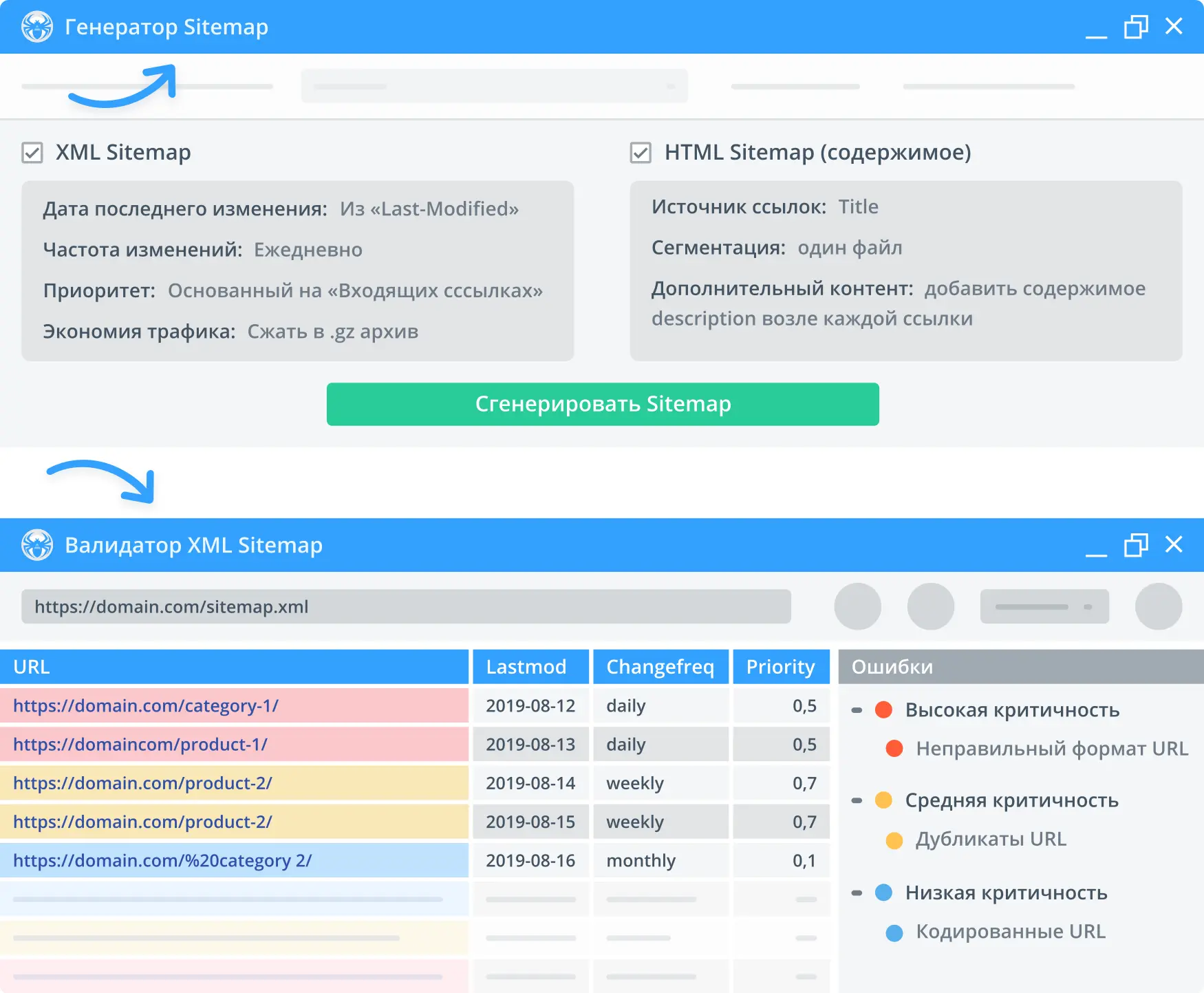
3. Создание и проверка Sitemap
Генерируйте Sitemap в формате XML или HTML, а также анализируйте уже существующие ошибки.
4. Многодоменное сканирование
Проверяйте сразу несколько адресов и получайте исчерпывающий отчет в одной удобной таблице. Эта опция удивительно удобна, чтобы работать над проектами с региональными сайтами на разных доменах.
Отчеты, доступные в Netpeak Spider
1. Аудит качества оптимизации в формате PDF
Наше приложение для SEO-аудита проводит экспресс-анализ качества оптимизации и дает результаты в удобном PDF-формате. Получите последние данные о вашем проекте и углубленную визуализацию результатов в диаграммах и графиках.

2. SEO-аудит с функцией White Label
Функция White Label позволяет создать отчет SEO-аудита в PDF с логотипом вашей компании, контактами и рекомендациями специалиста. Эта функция будет полезна для продвижения и продаж SEO-услуг.

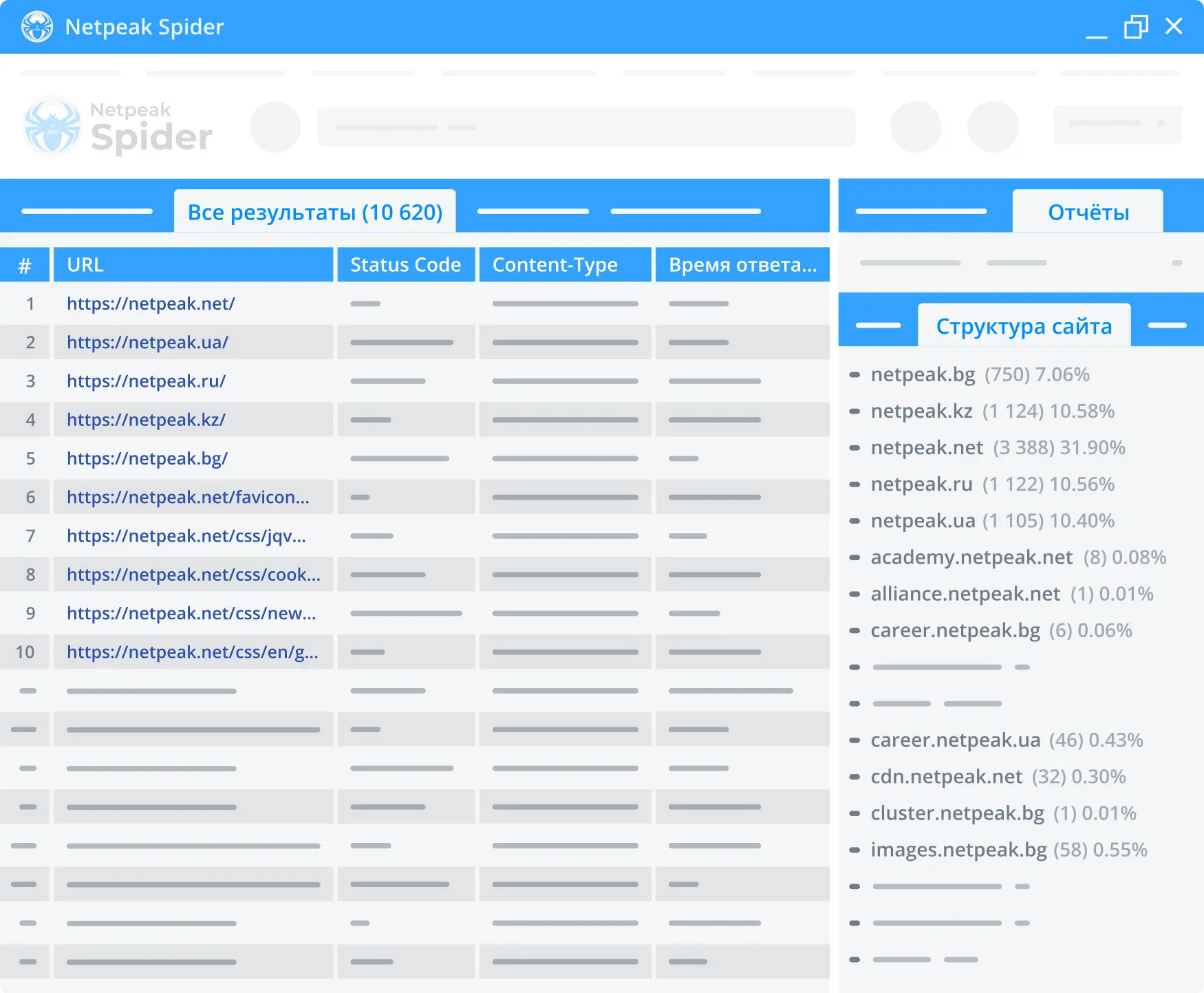
3. Комплексная проверка структуры сайта
Наш инструмент для аудита сайтов отображает структуру сайта на основе сегментов ссылок. Netpeak Spider предоставляет статистику по количеству и процентному соотношению URL-адресов на каждом уровне. В приложении также можно отфильтровать таблицу по страницам сайта для дальнейшего анализа.

4. Персонализированные настройки парсинга данных с веб сайта
Netpeak Spider имеет встроенный парсер веб сайтов. Здесь можно выбрать до 15 условий и четыре типа поиска (Regexp XPath, CSS). Это поможет удалить контакты, разметку, контент, данные из социальных сетей, цены конкурентов и т.д.

Интеграции, поддерживаемые Netpeak Spider
1. Google Analytics и Search Console
Расширяйте и дополняйте данные, полученные Netpeak Spider, собрав статистику по Google Analytics. Получите полезную информацию о трафике, целях, конверсиях и даже параметрах онлайн-продаж для любого целевого вебсайта.
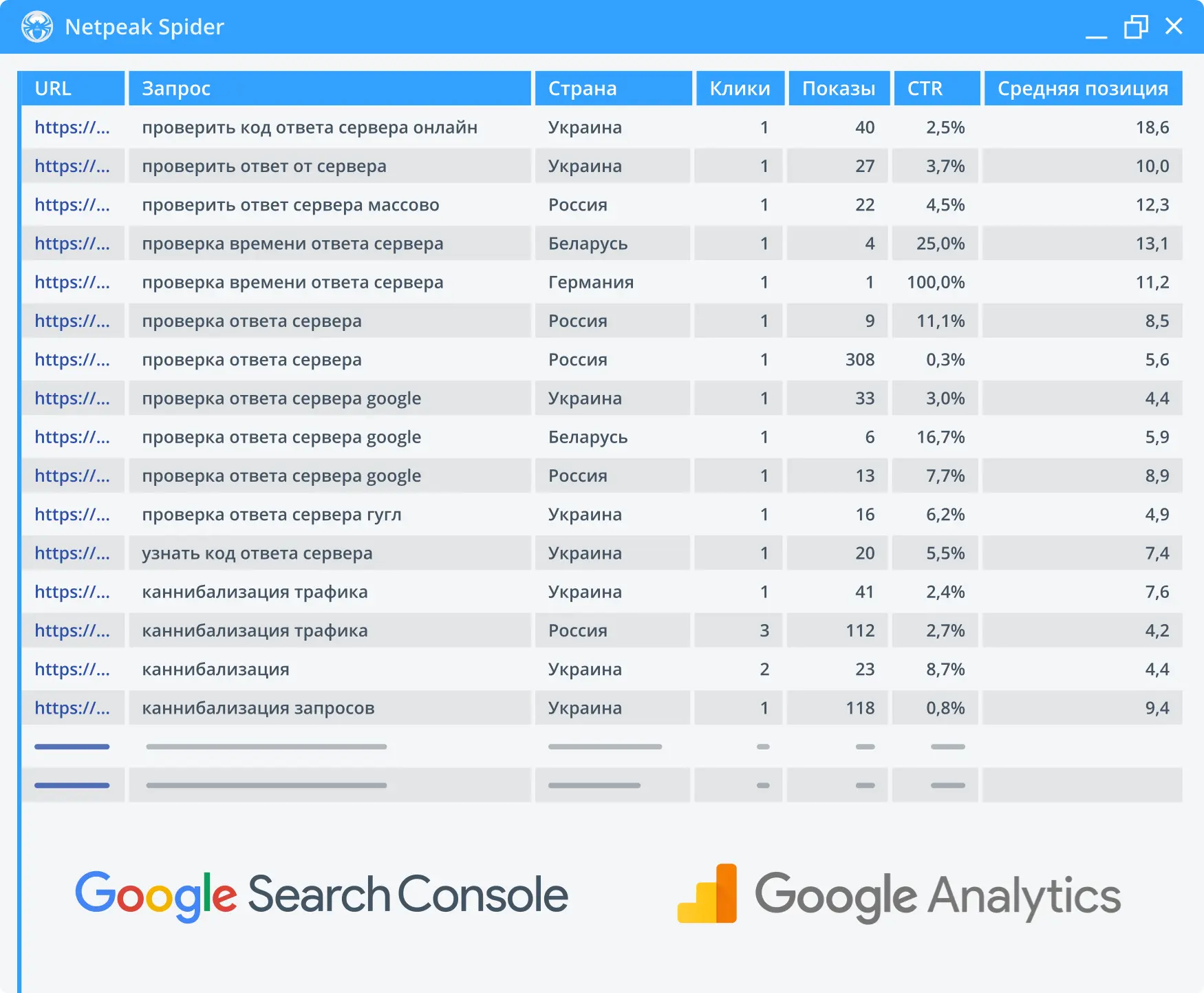
2. Экспорт поисковых запросов из Google Search Console
Анализируйте данные из Google Search Console в формате "URL – поисковый запрос – основные метрики". Собранные данные включают показы, щелчки, CTR и среднюю позицию.

3. Интеграция с Google Drive / Sheets
Экспортируйте отчеты прямо в Google Sheets – быстро и без ограничений – и делитесь ими с коллегами всего в несколько кликов. Наше приложение сразу экспортирует PDF-отчеты на Google Drive, так что вам останется только скопировать ссылки, чтобы отправить его менеджеру проекту или клиенту.

4. Дополнение данных SEO-аудита
Netpeak Spider позволяет загружать собственные данные из CSV-файла в приложение, чтобы более эффективно анализировать, фильтровать и сегментировать целевые URL-адреса.

Работа с большими объемами данных и экспортом
1. Оптимальное потребление оперативной памяти
С включенным рендерингом JavaScript наш сканер использует втрое меньше оперативной памяти, а без рендеринга – в восемь раз меньше. Более того, теперь нет необходимости вручную выбирать режим хранения данных, ведь мы по умолчанию используем собственную внутреннюю базу данных. Благодаря этому работа Netpeak Spider не влияет на скорость сканирования.

2. Массовый экспорт данных
Быстро экспортируйте все доступные отчеты или только самые необходимые сразу после сканирования вебсайта. Среди доступных форматов – CSV, XLSX и PDF.
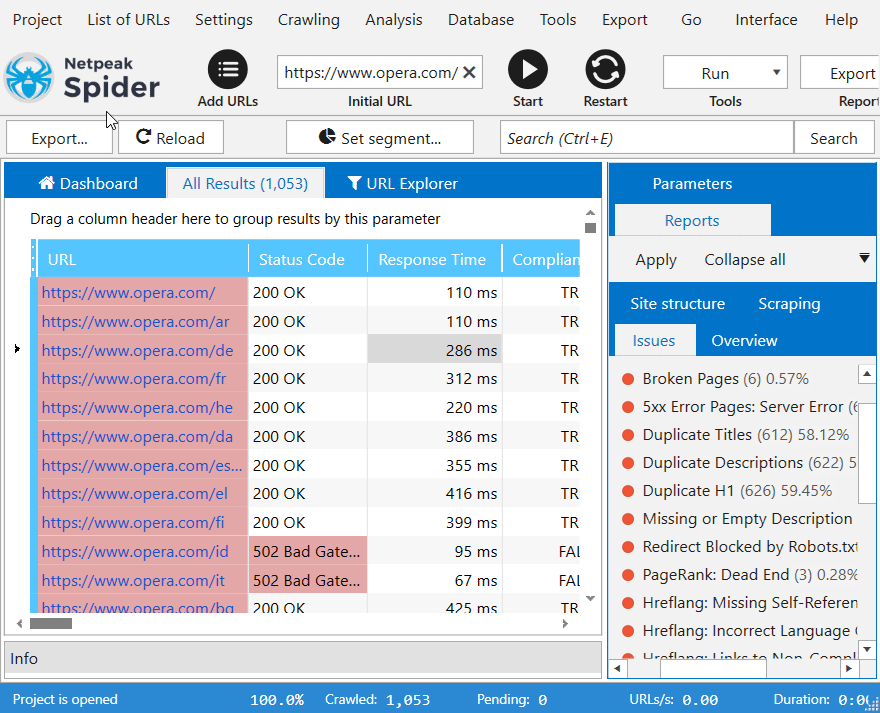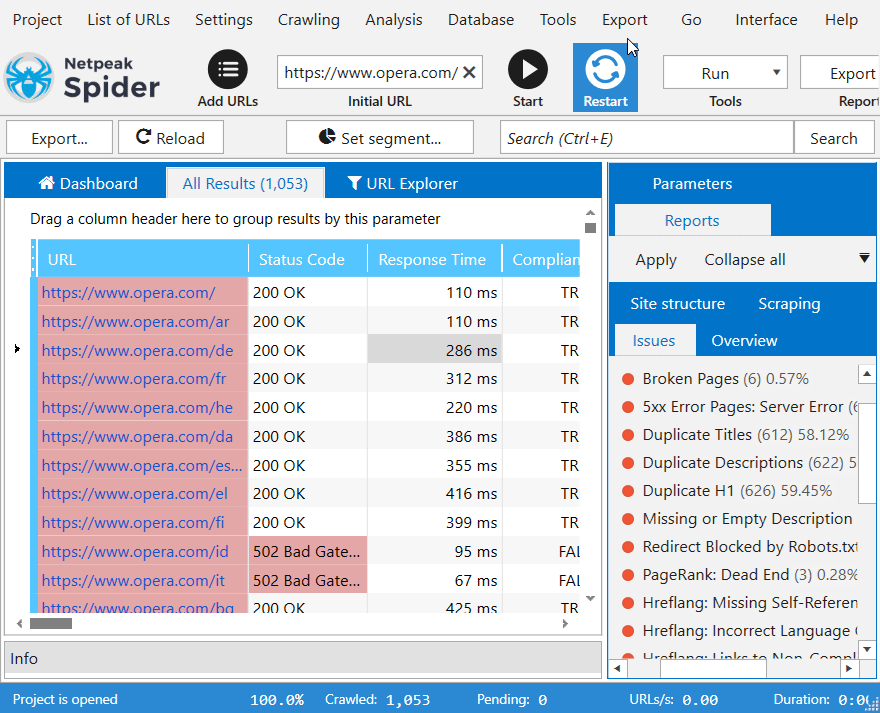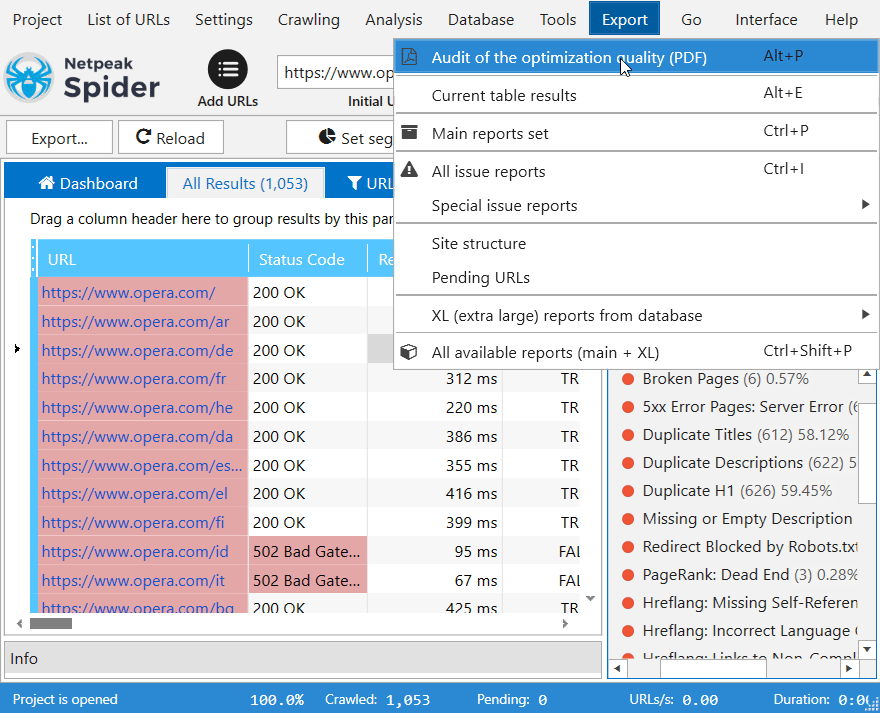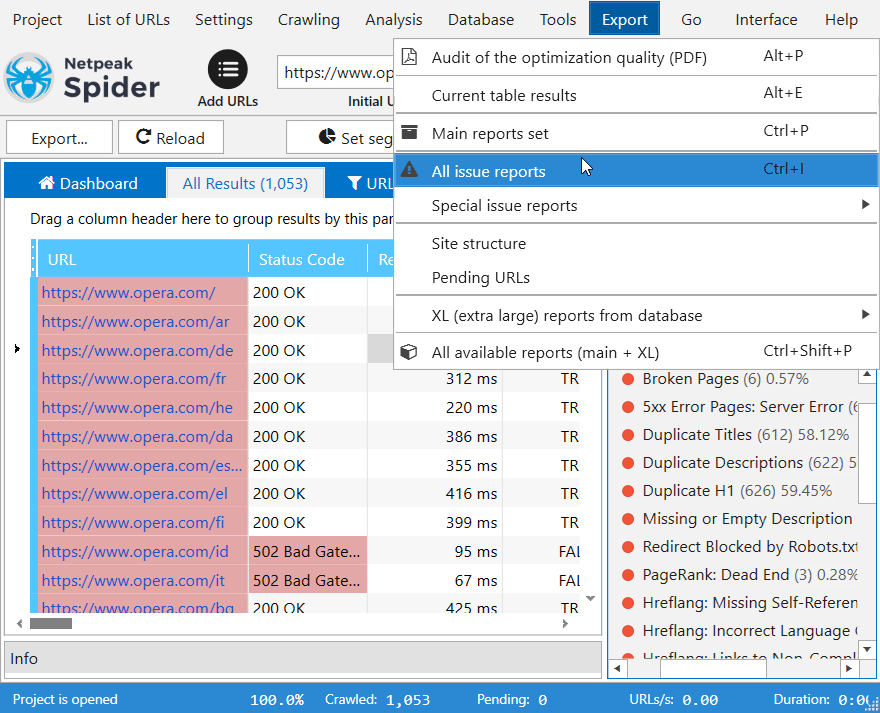
3. Внутренняя база данных
Внутренняя база данных нашего приложения способна работать с огромным количеством URL-адресов – больше не нужно экспортировать результаты в Excel или Google Sheets. Вы можете проанализировать любой параметр (например, ссылку, переадресацию или изображение) для одного или нескольких URL просто в приложении.
Поддержка и Обновления
1. Автоматическое обновление приложения
Мы автоматически обновляем Netpeak Spider до последней версии каждый раз, когда она доступна, чтобы вы могли проводить аудит сайтов без сбоев и зависаний.
2. База знаний
Все ответы на ваши вопросы о Netpeak Spider – в нашей базе знаний.

3. Поддержка клиентов через тикеты
Быстро найдите ответ в Центре поддержки или создайте тикет для дополнительной помощи. Обычно мы отвечаем в течение 24 часов в рабочие дни.

Особенности SEO приложения Netpeak Spider
Ознакомьтесь с другими особенностями SEO продукта от Netpeak Software.

Проверка Alt-тегов
Проверяйте отдельные страницы и целые сайты на наличие Alt-тегов на изображениях, а также выявляйте проблемы с Netpeak Spider.

Проверка количества слов на странице
Определите точное количество слов на странице с помощью Netpeak Spider. Получайте необходимую информацию о контенте вашего сайта для улучшения его оптимизации.

Проверка количества страниц на сайте
Как найти все страницы на сайте? SEO-аудит и повседневные задачи становятся проще с Netpeak Spider, как и создание списка веб-страниц на вашем вебсайте.
Почему наши клиенты выбирают Netpeak Spider
Наши многочисленные награды и отзывы говорят сами за себя. Узнайте, за что нас ценят лидеры индустрии и топовые специалисты


Двойная эффективность вашей SEO-стратегии ⭐️
Запустите 100% эффективную SEO проверку сайта с помощью наших двух мощных инструментов. Загрузите Netpeak Spider и Netpeak Checker и улучшите эффективность вашего сайта.
Для Windows & macOS
